 网硕互联帮助中心
网硕互联帮助中心该代码实现了一种基于 VMD(变分模态分解)- 样本熵 – GRU+Transformer 的混合多变量时间序列预测模型。
一、研究背景
时间序列预测在金融、气象、电力、交通等领域具有重要应用价值。传统单一模型(如ARIMA、LSTM)难以同时捕捉时序中的低频趋势和高频波动。VMD可将原始序列分解为多个本征模态函数(IMF),结合样本熵区分高低频成分,再分别用GRU(门控循环单元) 和Transformer建模,提升预测精度。
二、主要功能
数据导入与预处理
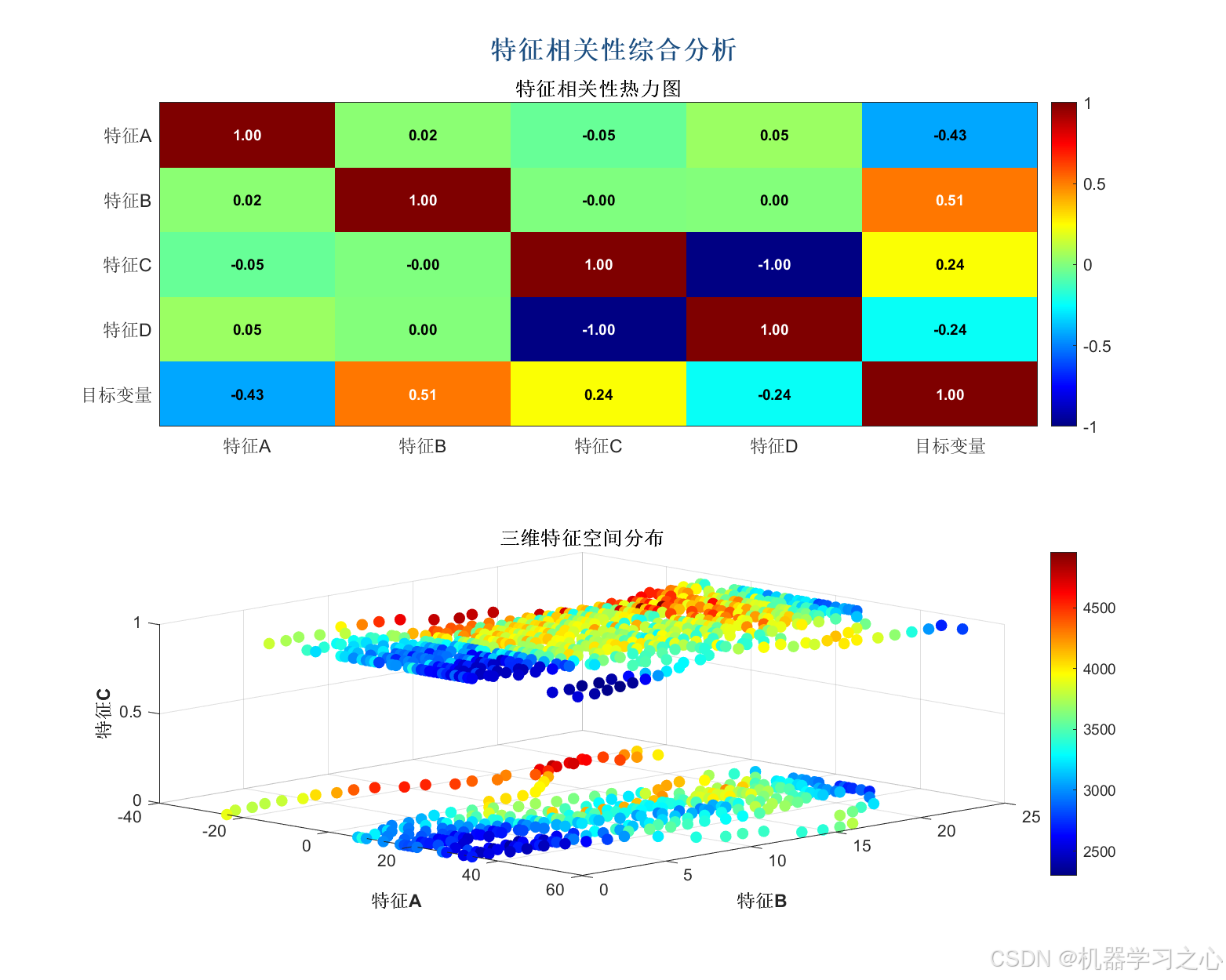
- 从 Excel 中读取多变量数据,提取目标变量和特征变量。
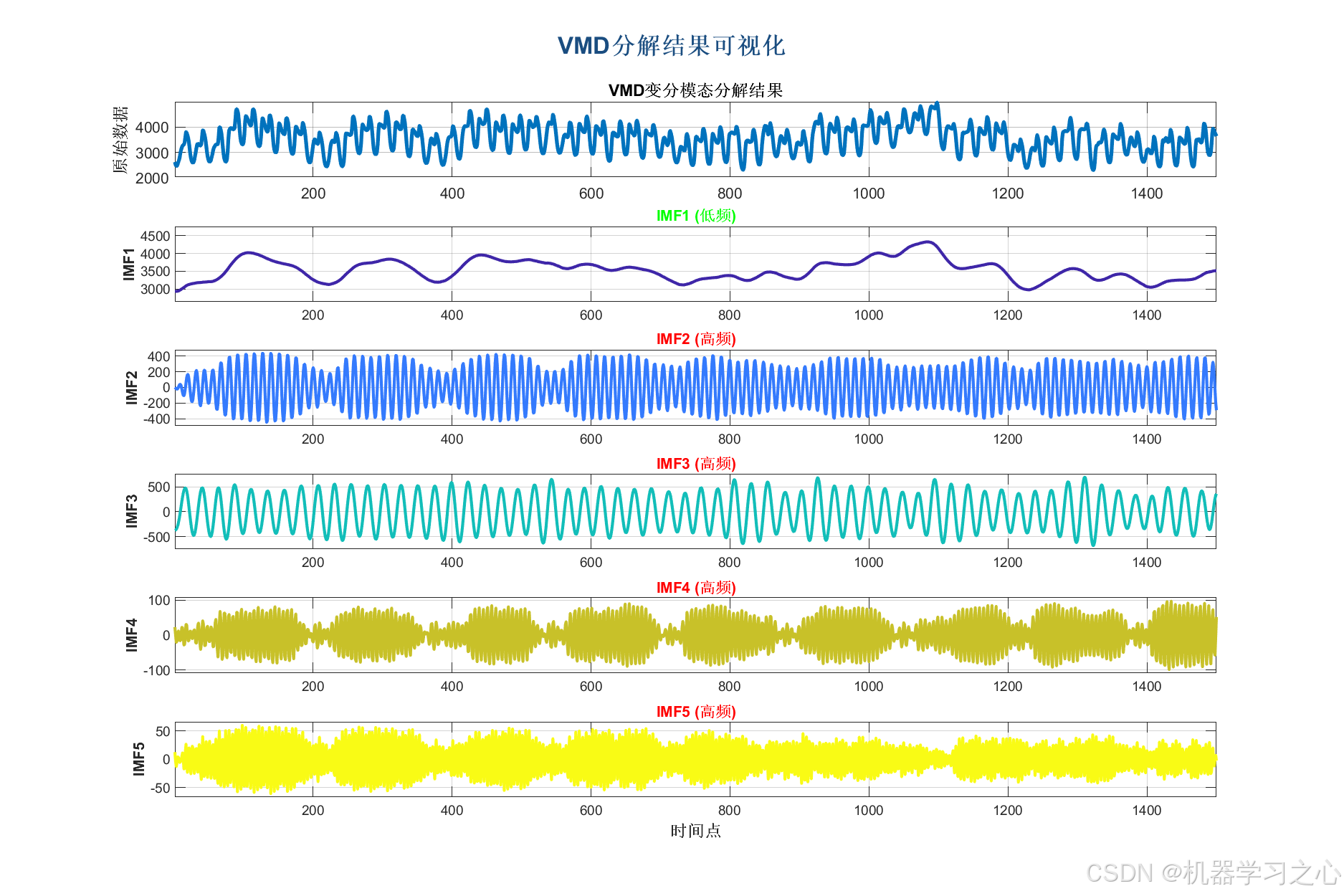
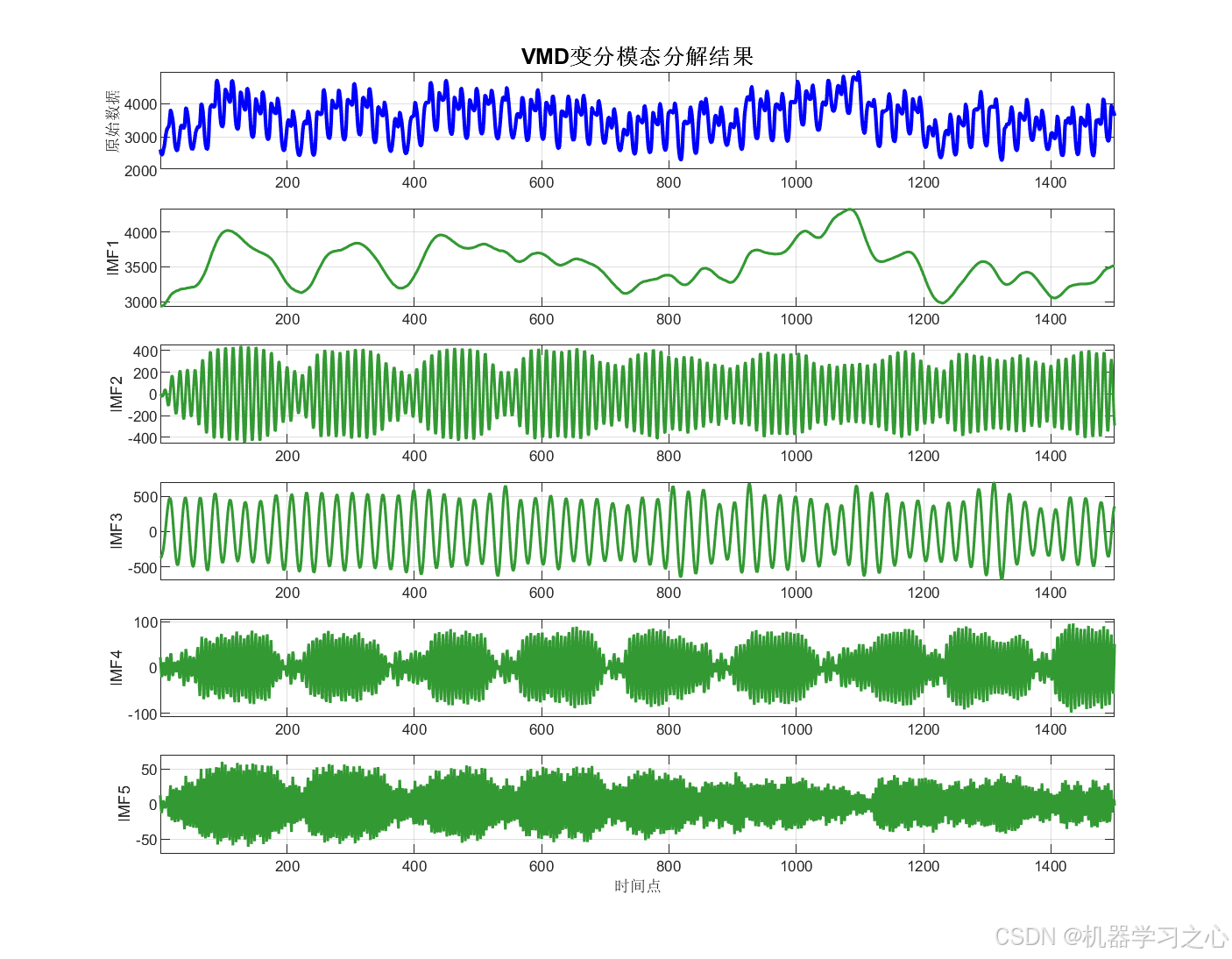
VMD 分解
- 将目标变量分解为多个 IMF 分量。
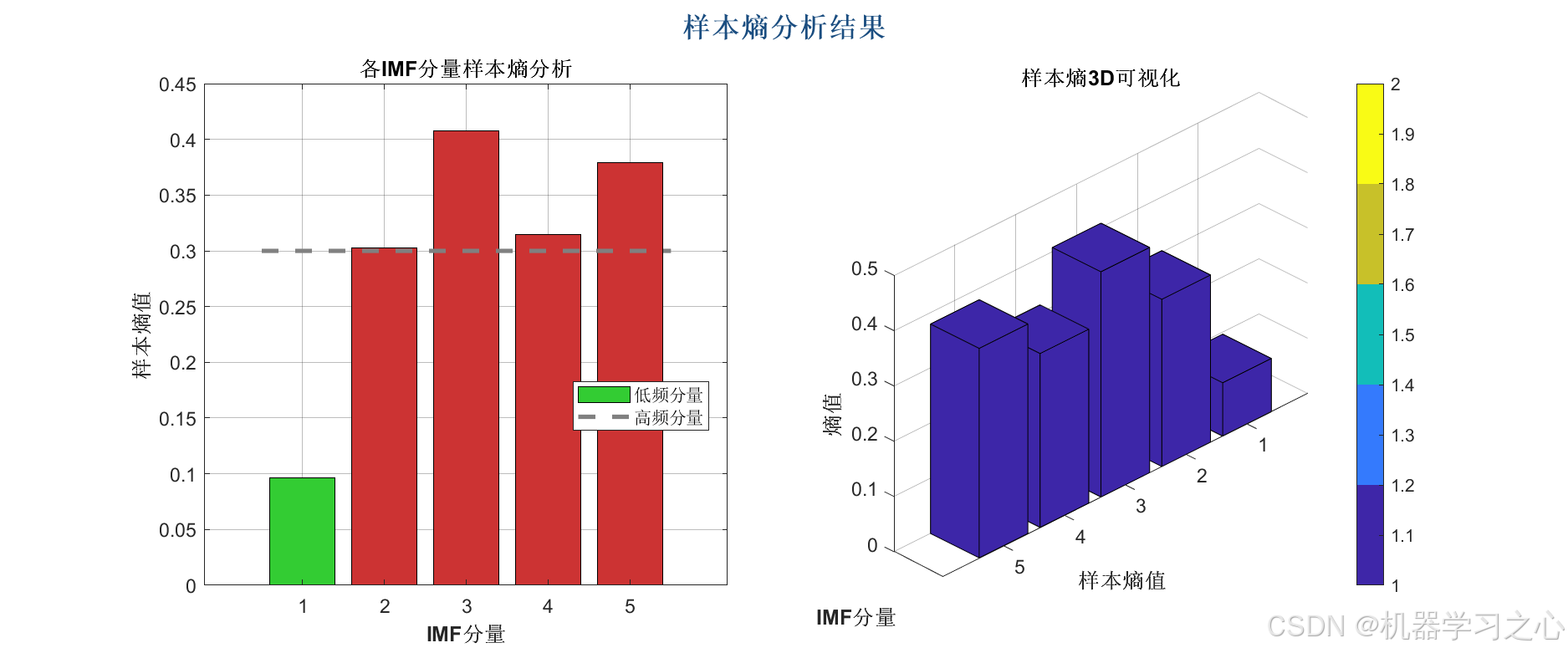
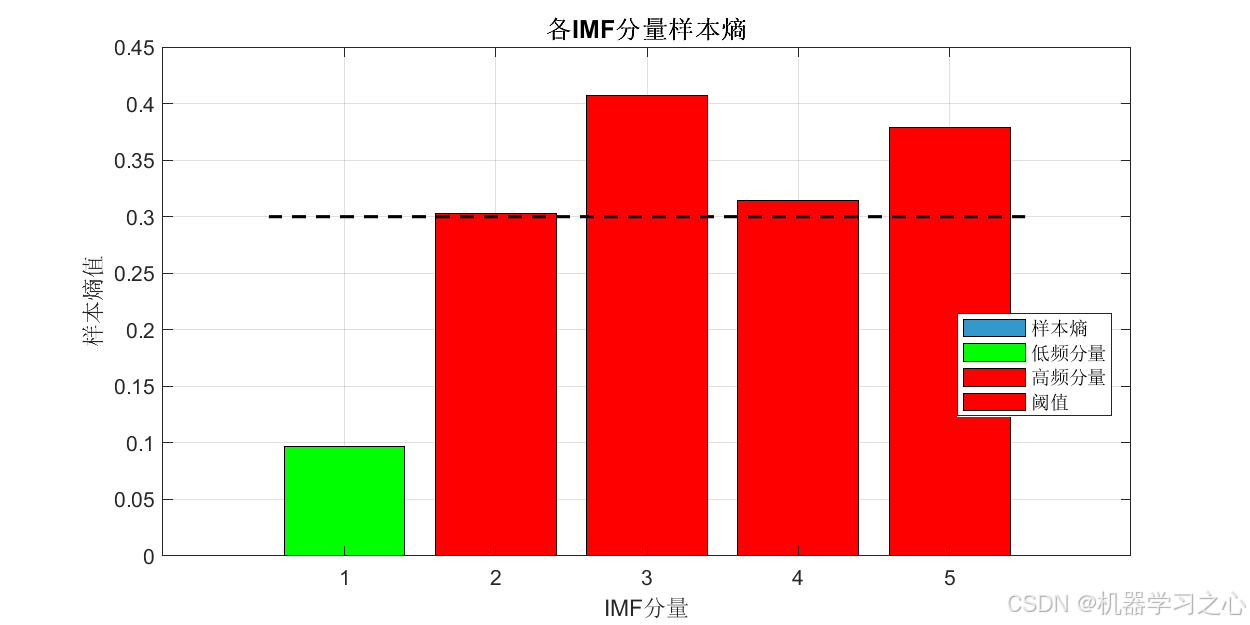
样本熵计算与高低频划分
- 计算各分量的样本熵,根据阈值划分为低频和高频分量。
时间序列重构
- 将特征与目标变量(低频/高频)组合,构建适用于深度学习模型的输入格式。
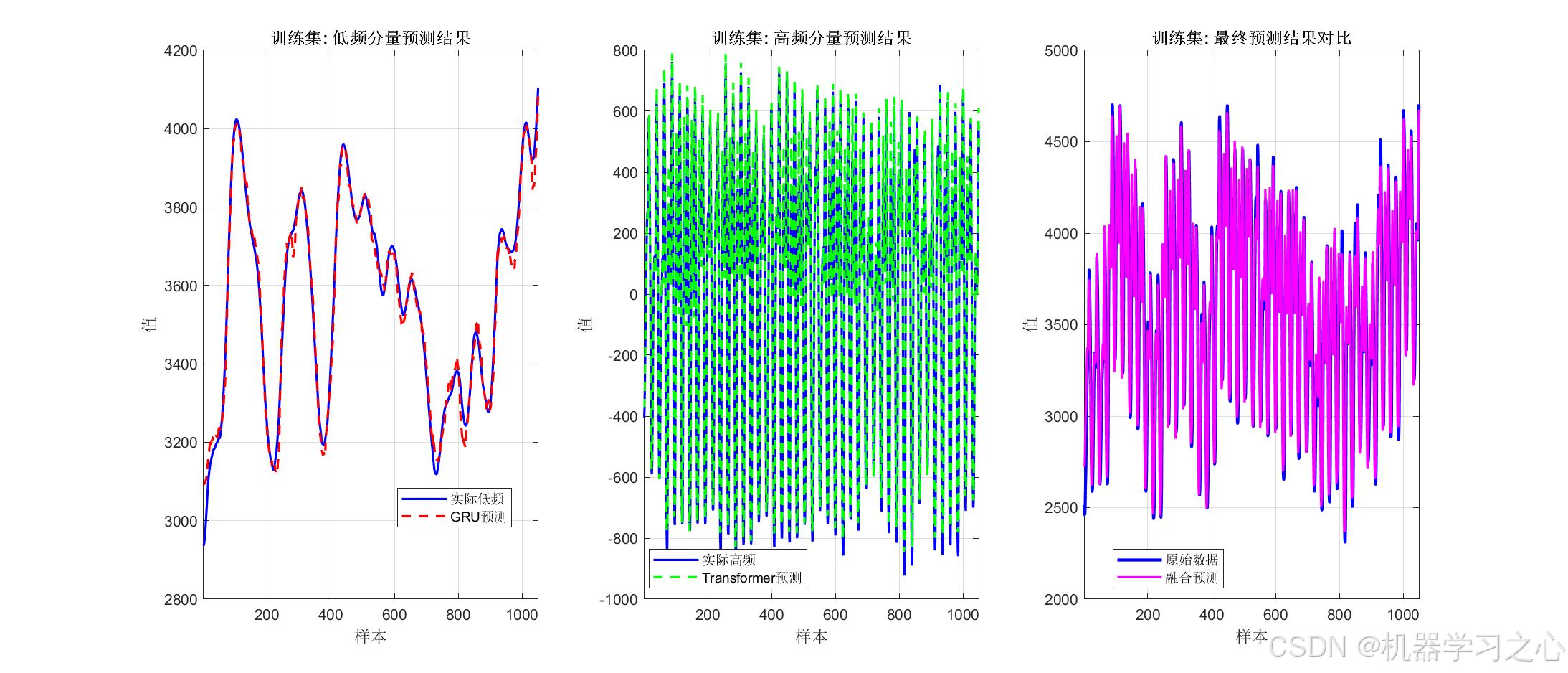
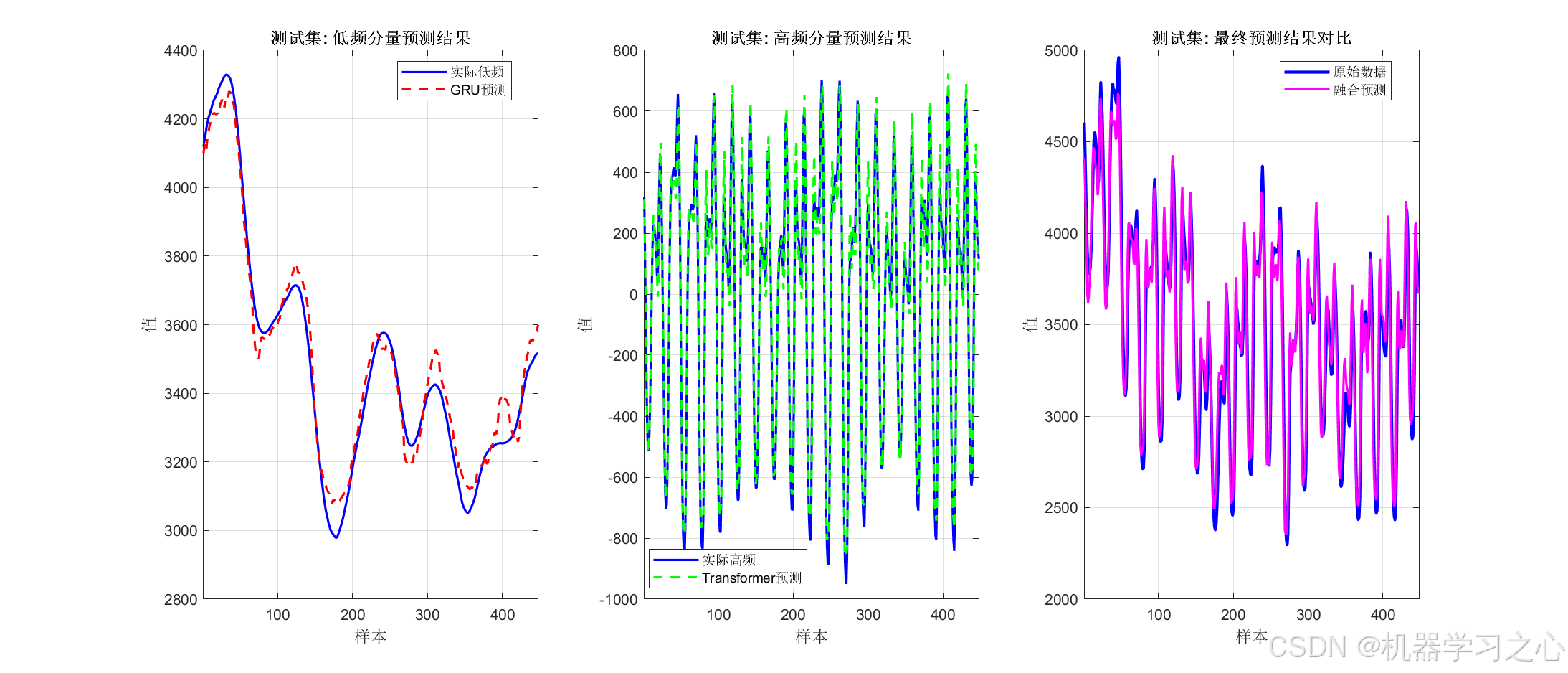
GRU 与 Transformer 建模
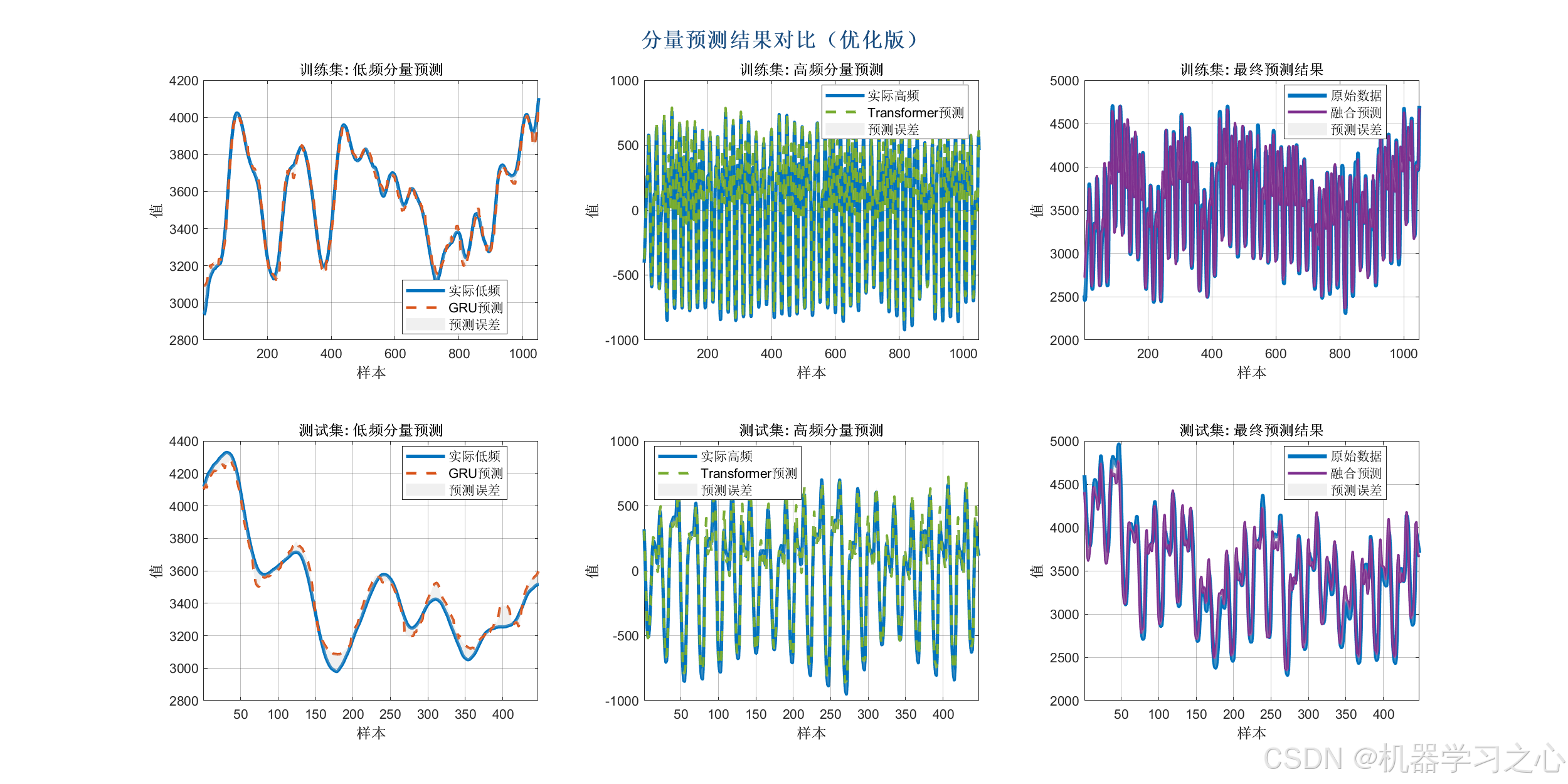
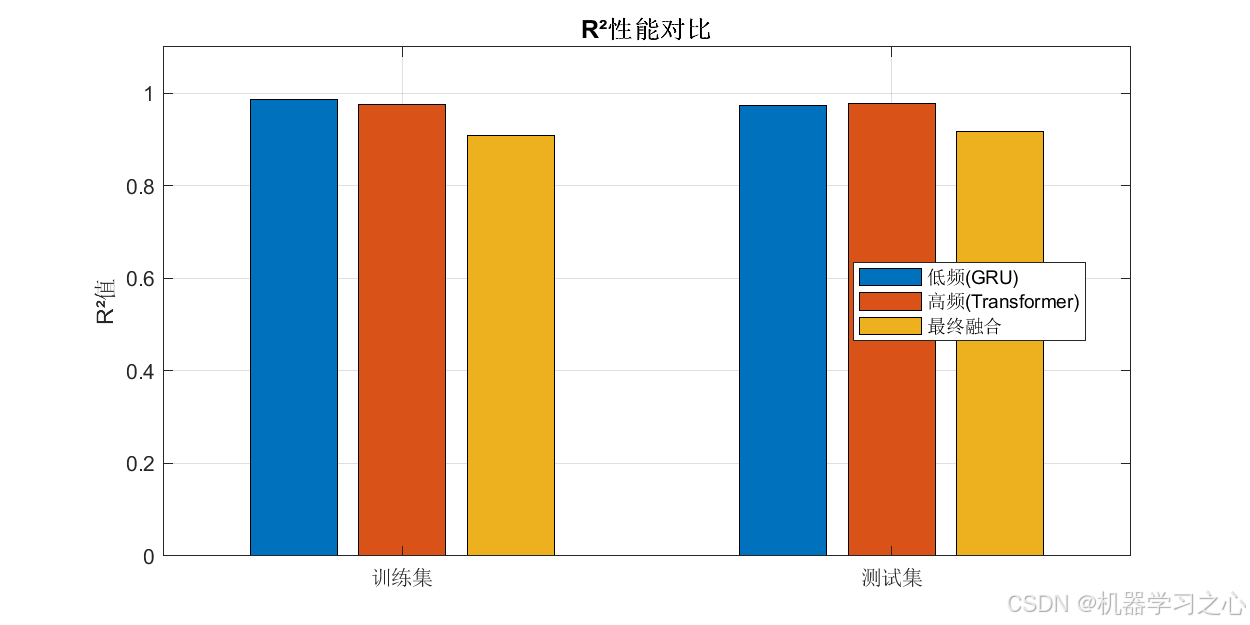
- 用 GRU 预测低频分量,用 Transformer 预测高频分量。
模型融合与反归一化
- 将两部分预测结果相加,反归一化得到最终预测值。
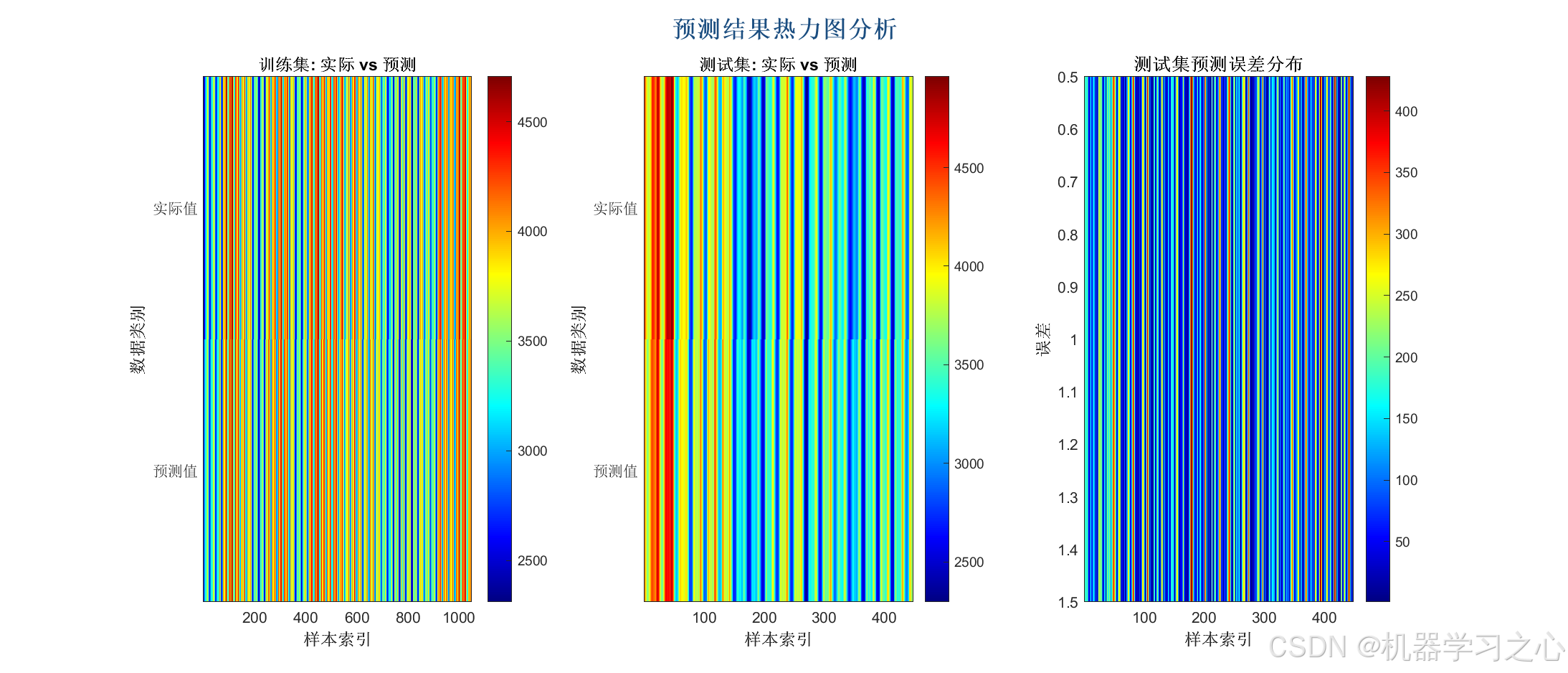
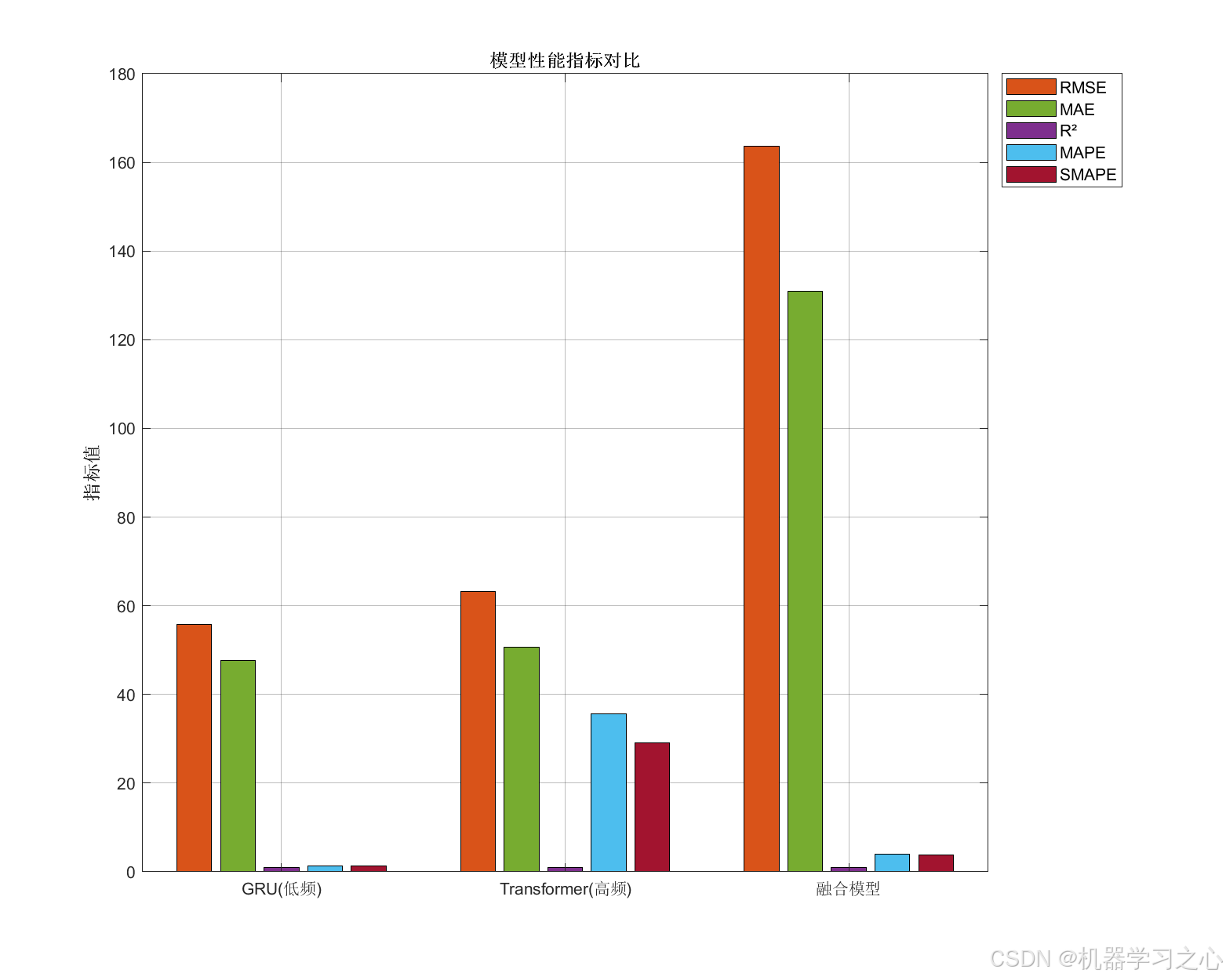
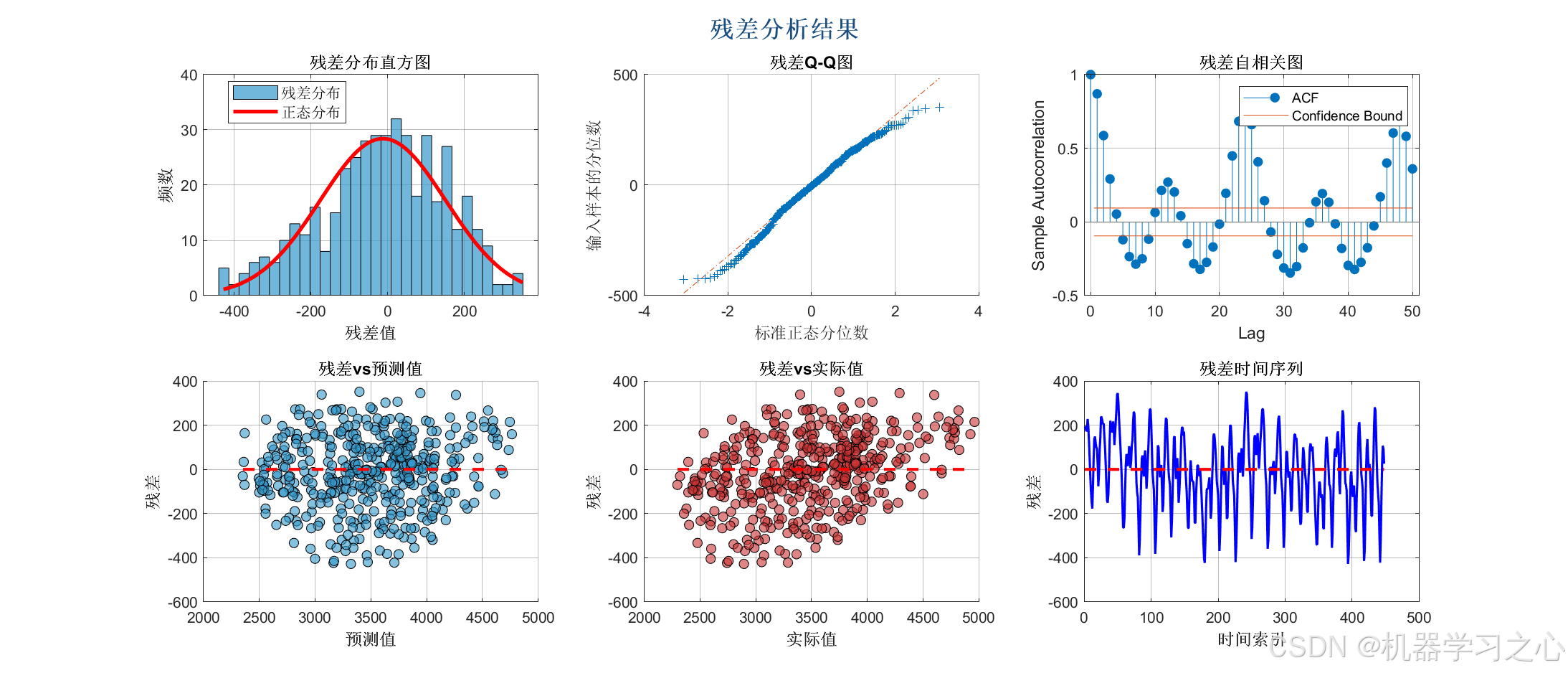
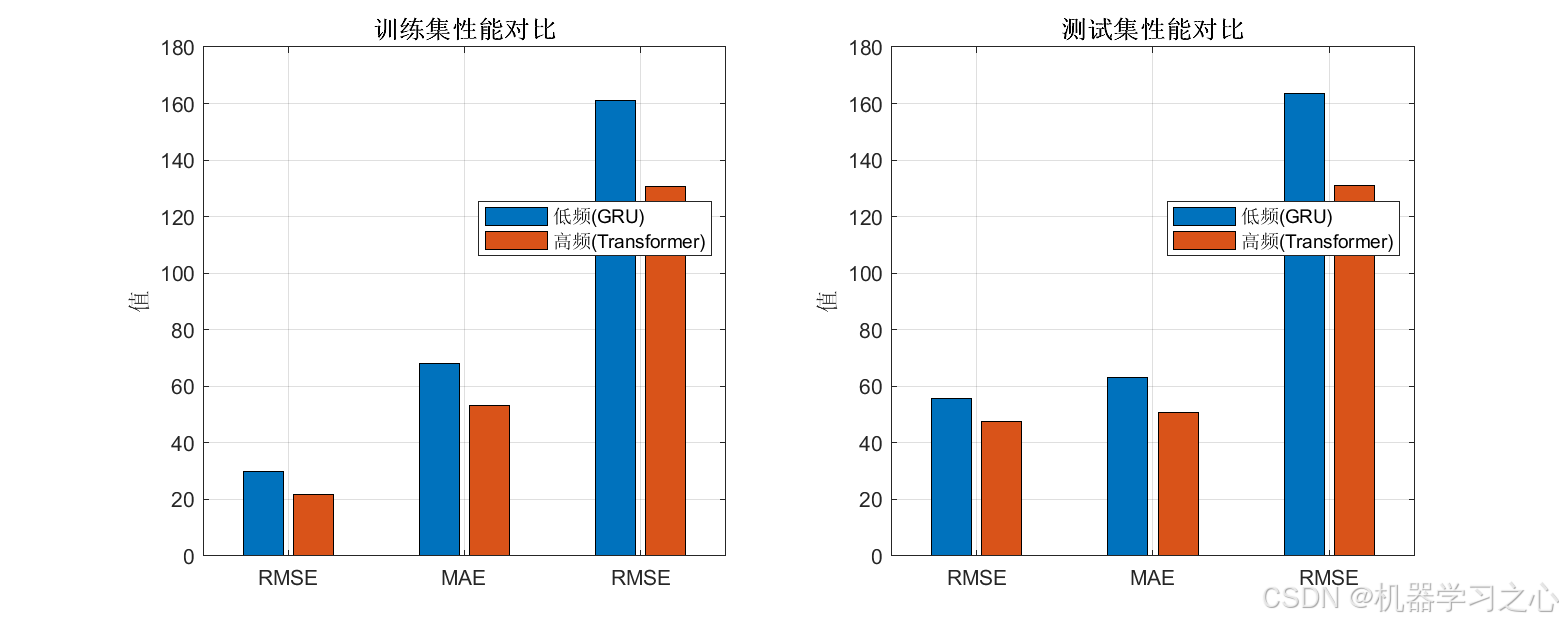
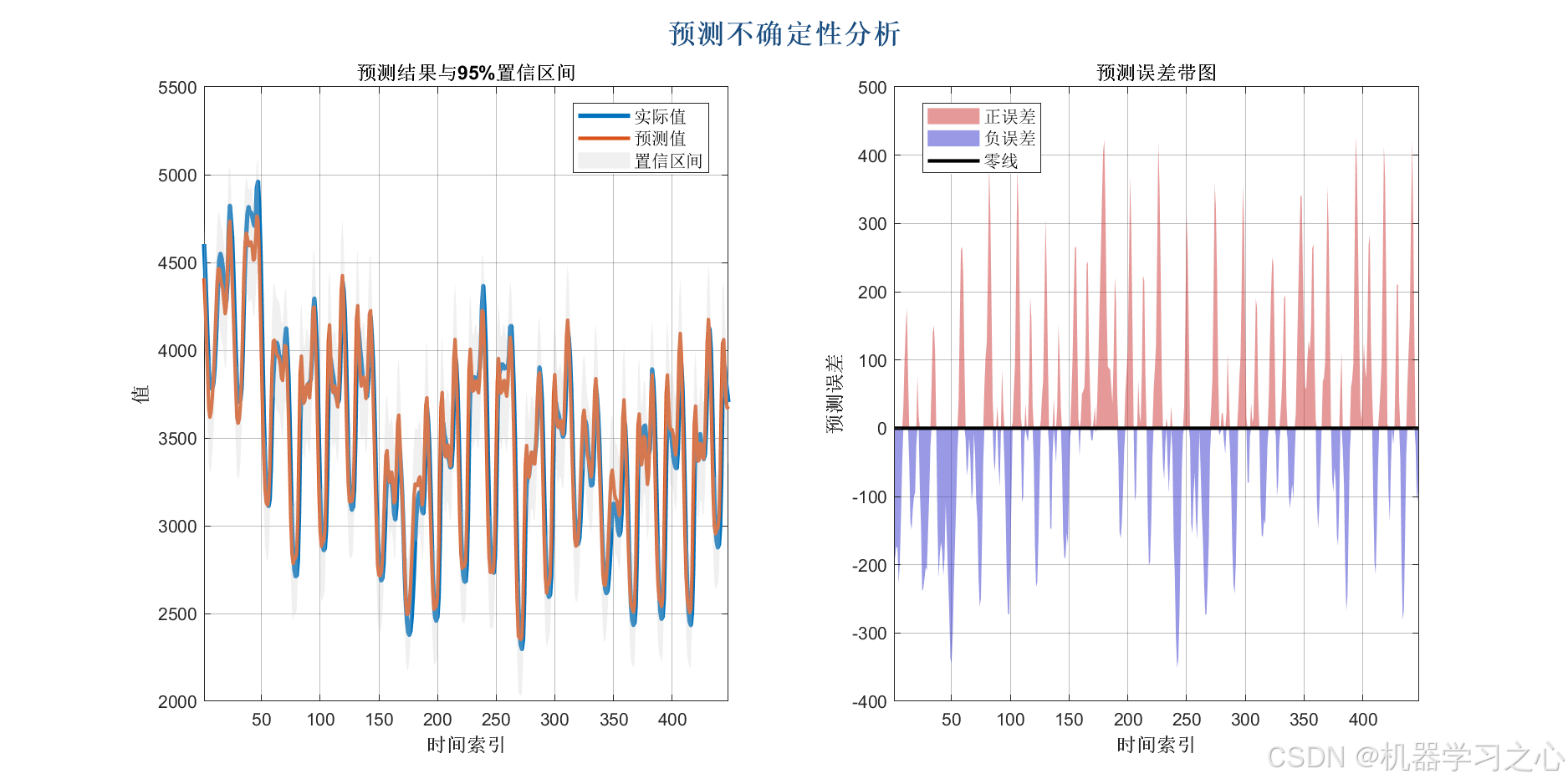
性能评估与可视化
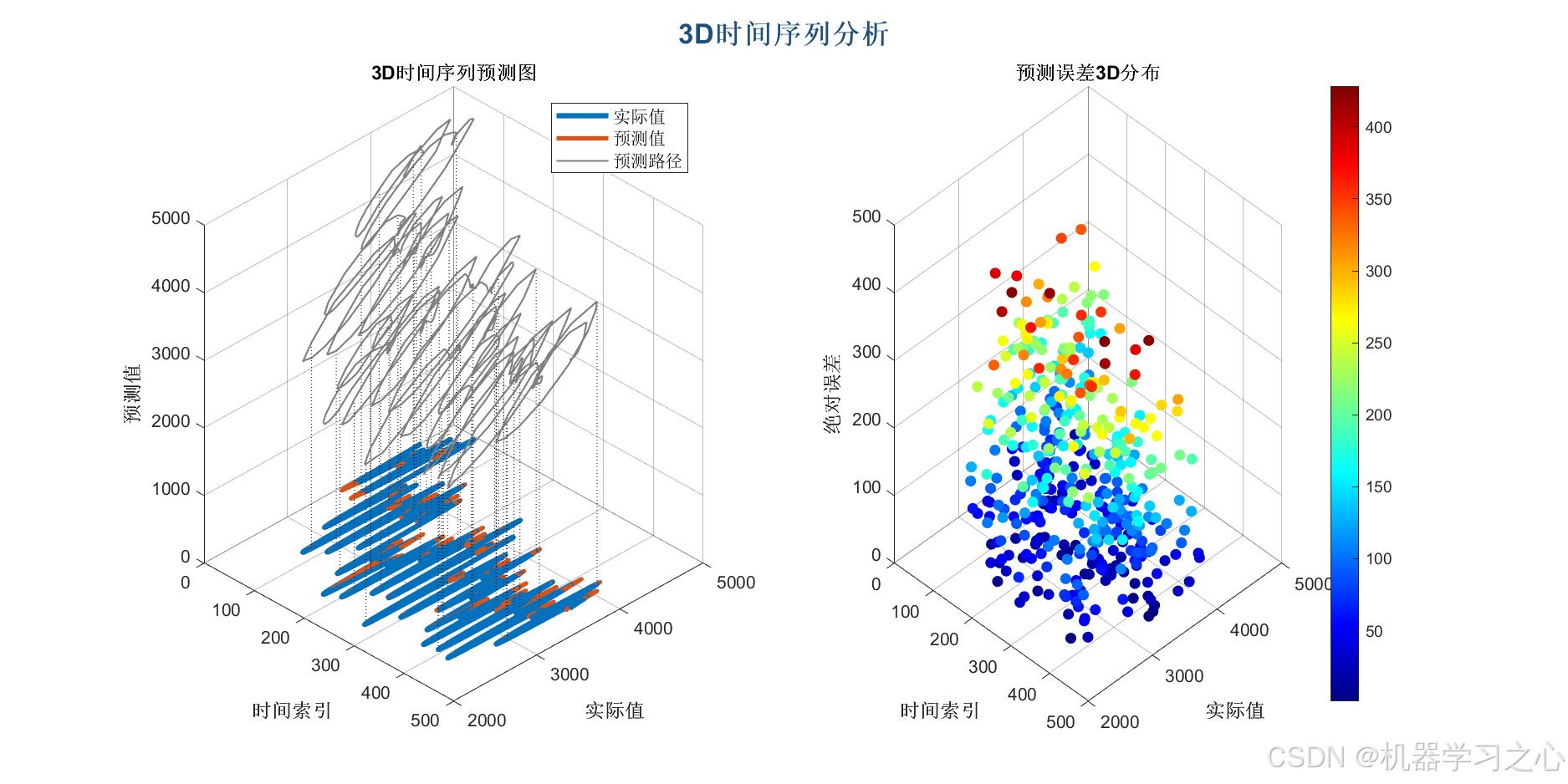
- 计算 RMSE、MAE、R² 等指标,绘制多种图表(如预测对比图、残差分析图、置信区间图等)。
三、算法步骤与技术路线
数据加载与预处理
- 读取 data.xlsx,提取特征和目标变量。
VMD 分解
- 将目标变量分解为 K 个 IMF。
样本熵分析与高低频划分
- 计算每个 IMF 的样本熵,均值作为阈值,划分低频(熵低)和高频(熵高)分量。
数据归一化与时间序列重构
- 分别对低频、高频和特征进行归一化,构建滑动窗口样本(kim 步历史数据预测 zim 步后的值)。
模型构建与训练
- GRU 模型:用于低频分量,包含两层 GRU + Dropout + 全连接层。
- Transformer 模型:用于高频分量,包含位置嵌入、自注意力层、索引层等。
预测与融合
- 分别预测低频和高频分量,相加得到最终预测值。
性能评估与可视化
- 计算训练集和测试集的 RMSE、MAE、R²、MAPE、SMAPE 等指标。
- 绘制 VMD 分解图、样本熵图、预测对比图、残差图、置信区间图、雷达图等。
四、公式原理
VMD 分解
- 将原始信号 ( f(t) ) 分解为 K 个模态 ( u_k(t) ):
min
{
u
k
}
,
{
ω
k
}
{
∑
k
∥
∂
t
[
(
δ
(
t
)
+
j
π
t
)
∗
u
k
(
t
)
]
e
−
j
ω
k
t
∥
2
2
}
\\min_{\\{u_k\\},\\{\\omega_k\\}} \\left\\{ \\sum_k \\left\\| \\partial_t \\left[ \\left( \\delta(t) + \\frac{j}{\\pi t} \\right) * u_k(t) \\right] e^{-j\\omega_k t} \\right\\|_2^2 \\right\\}
{uk},{ωk}min{k∑
∂t[(δ(t)+πtj)∗uk(t)]e−jωkt
22} 约束条件:(\\sum_k u_k = f)。
样本熵(Sample Entropy)
- 衡量时间序列复杂度,值越大表示序列越不规则。
GRU
- 更新门 ( z_t ) 和重置门 ( r_t ):
z
t
=
σ
(
W
z
x
t
+
U
z
h
t
−
1
)
z_t = \\sigma(W_z x_t + U_z h_{t-1})
zt=σ(Wzxt+Uzht−1)r
t
=
σ
(
W
r
x
t
+
U
r
h
t
−
1
)
r_t = \\sigma(W_r x_t + U_r h_{t-1})
rt=σ(Wrxt+Urht−1)h
~
t
=
tanh
(
W
h
x
t
+
U
h
(
r
t
⊙
h
t
−
1
)
)
\\tilde{h}_t = \\tanh(W_h x_t + U_h (r_t \\odot h_{t-1}))
h~t=tanh(Whxt+Uh(rt⊙ht−1))h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
~
t
h_t = (1 – z_t) \\odot h_{t-1} + z_t \\odot \\tilde{h}_t
ht=(1−zt)⊙ht−1+zt⊙h~t
Transformer 自注意力机制
- 自注意力输出:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V
Attention(Q,K,V)=softmax(dkQKT)V
五、参数设定
| alpha | 2000 | VMD 惩罚因子 |
| K | 5 | 模态数量 |
| m | 2 | 样本熵嵌入维度 |
| r_coefficient | 0.2 | 样本熵阈值系数 |
| kim | 2 | 历史步长 |
| zim | 1 | 预测步长 |
| num_size | 0.7 | 训练集比例 |
| GRU 隐藏层 | 64, 32 | GRU 单元数 |
| Transformer head | 4 | 多头注意力头数 |
| 学习率 | 0.001 | 初始学习率 |
| 训练轮数 | 80 | 最大迭代次数 |
六、运行环境
- MATLAB 版本:建议 R2024b 及以上
七、应用场景
- 金融时间序列预测(如股票价格、汇率)
- 能源负荷预测(如电力负荷、风电功率)
- 气象预测(如温度、降水量)
- 交通流量预测
- 工业设备状态监测与剩余寿命预测



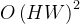

评论前必须登录!
注册