 网硕互联帮助中心
网硕互联帮助中心本文从爬取《红楼梦》全卷,到将其切分为120篇,详细的讲解如何操作。以此类推可以爬取《》《西游记》、《三国演义》等其他文本,有的网站无法单独爬取各章节,本文也会介绍如何将各章节完整切分。
一、爬取红楼梦全卷
1.1找到需要爬取的位置
我是在百度随便找了一个网站:https://hongloumeng.5000yan.com/
大家可以自己找,我会详细介绍我们爬虫需要获取的信息,当需要爬取其他网站时原理也是一样的。
在打开我们需要爬取的网站以后,打开开发者工具。
打开开发者模式有两种方法: 1.直接按“f12”
2.在选项-更多工具-开发者工具当中(这里不好截图)
打开开发者工具以后记得刷新。
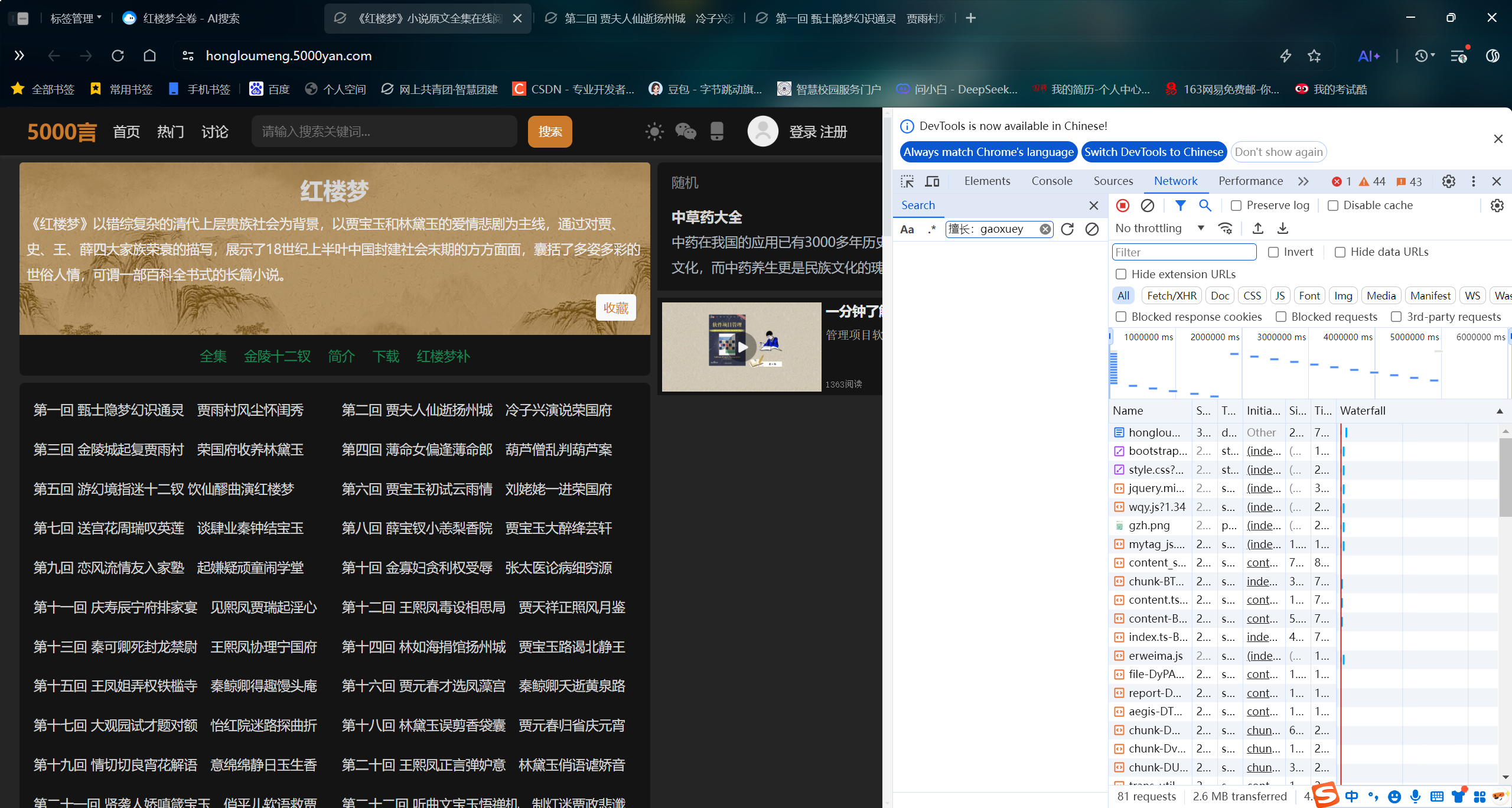
然后找到network网络,然后找到状态:304,类型:document那一栏数据,其他网址也是找状态:304,类型:document那一栏数据。
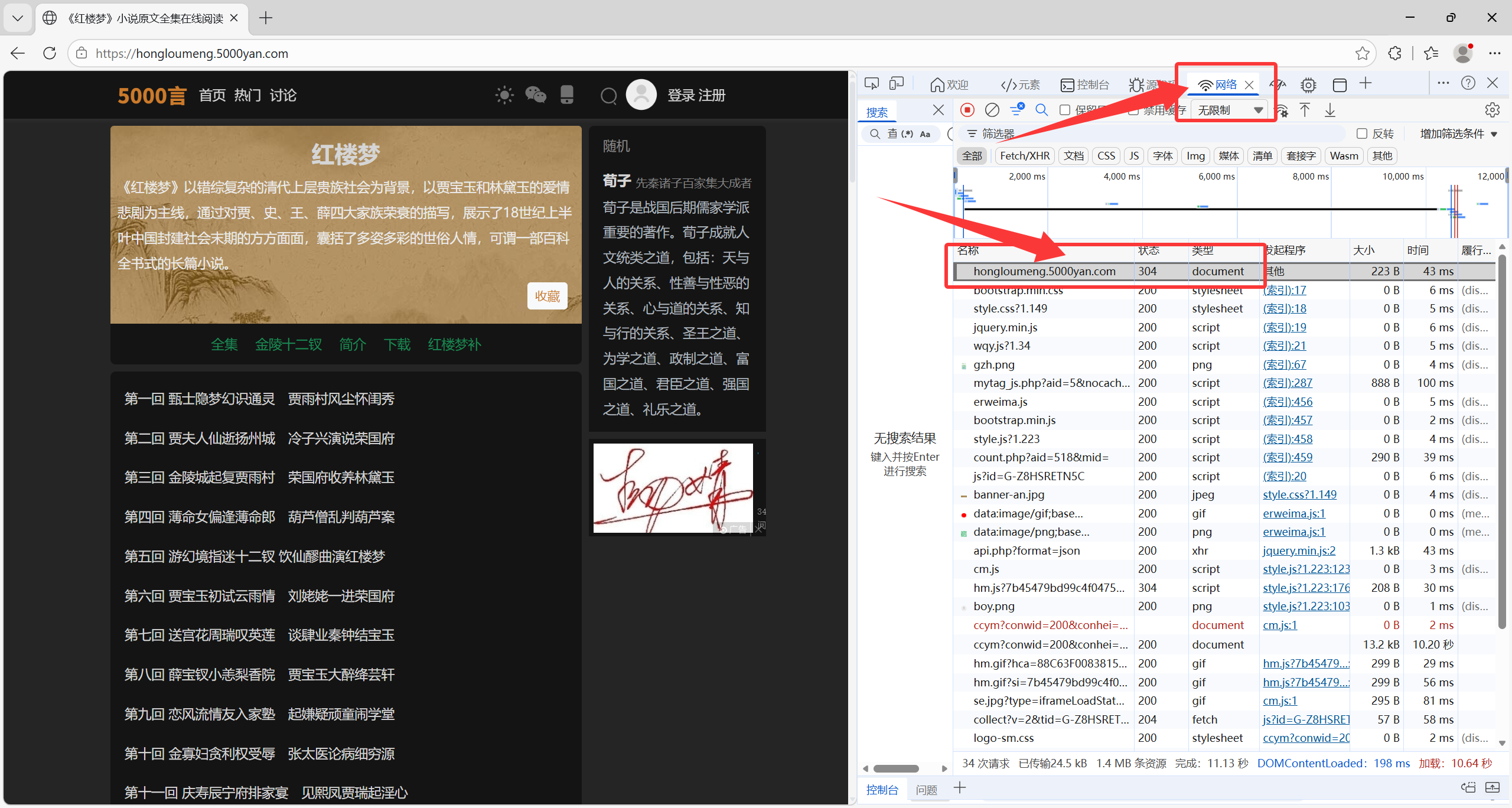
点开
这里我们需要找到三个关键信息:
1."user-agent": Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.0.0, 2."accept":text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 3."host": hongloumeng.5000yan.com
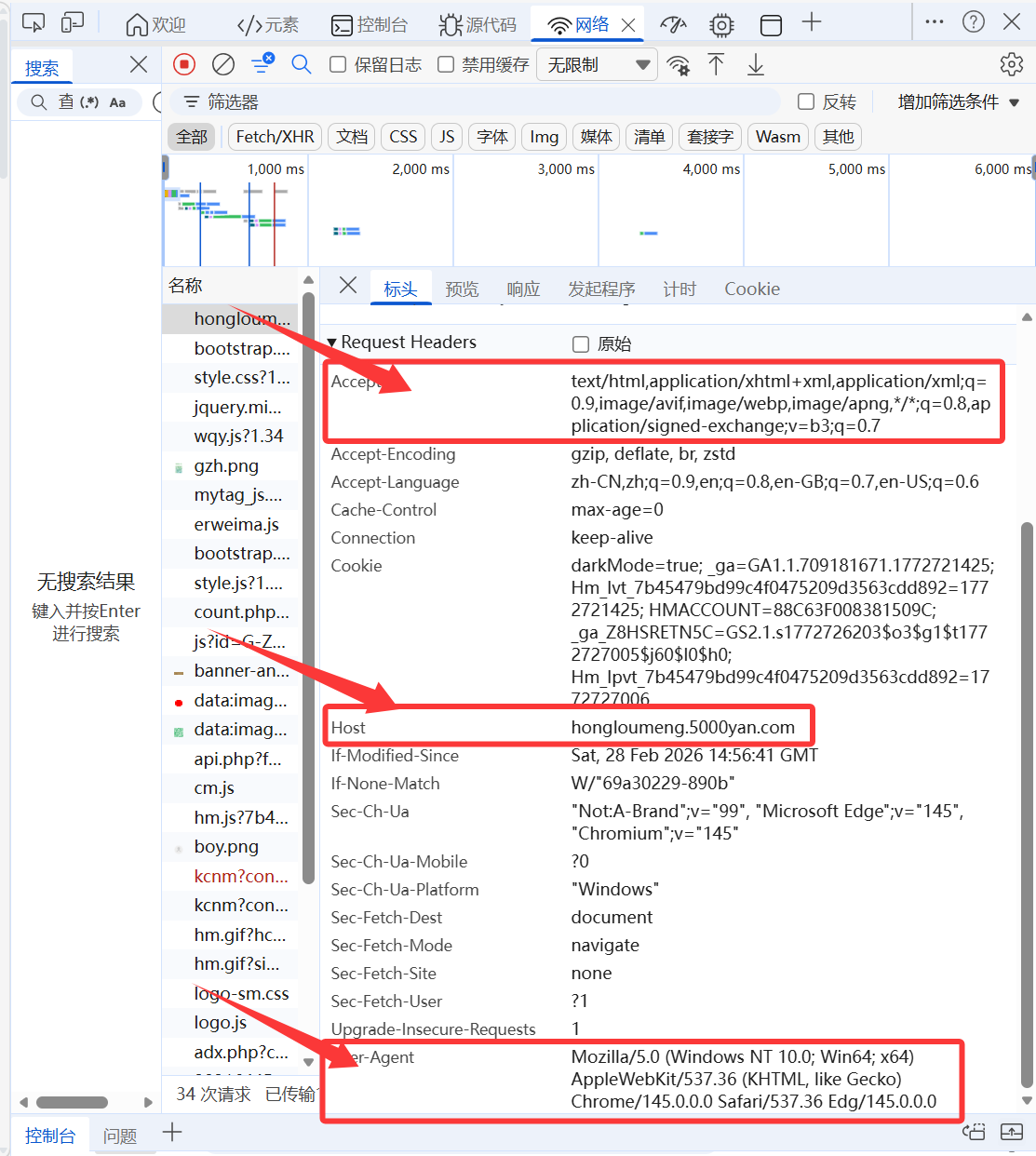
那其他有爬虫基础的同学就要问了,为了反爬虫我加上其他的信息,比如cookie行不行,可以,但是使用cookie需要注意,cookie是不断刷新的,你现在的cookie可以用,但是可能第二天就要重新获取cookie,所以不需要cookie也能爬,就最好不加cookie。
1.2找到需要爬取各章节的URL
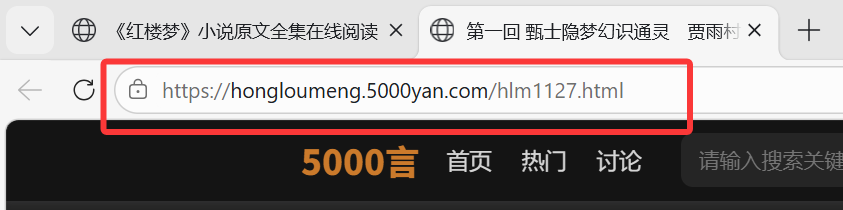
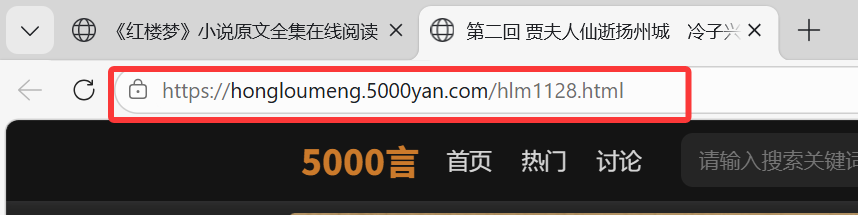
注意到,第1章是https://hongloumeng.5000yan.com/hlm1127.html
第2章https://hongloumeng.5000yan.com/hlm1128.html
第120章https://hongloumeng.5000yan.com/hlm1246.html
它们的URL是从1127到1246的,我们在后续代码就可以从1127爬到1246

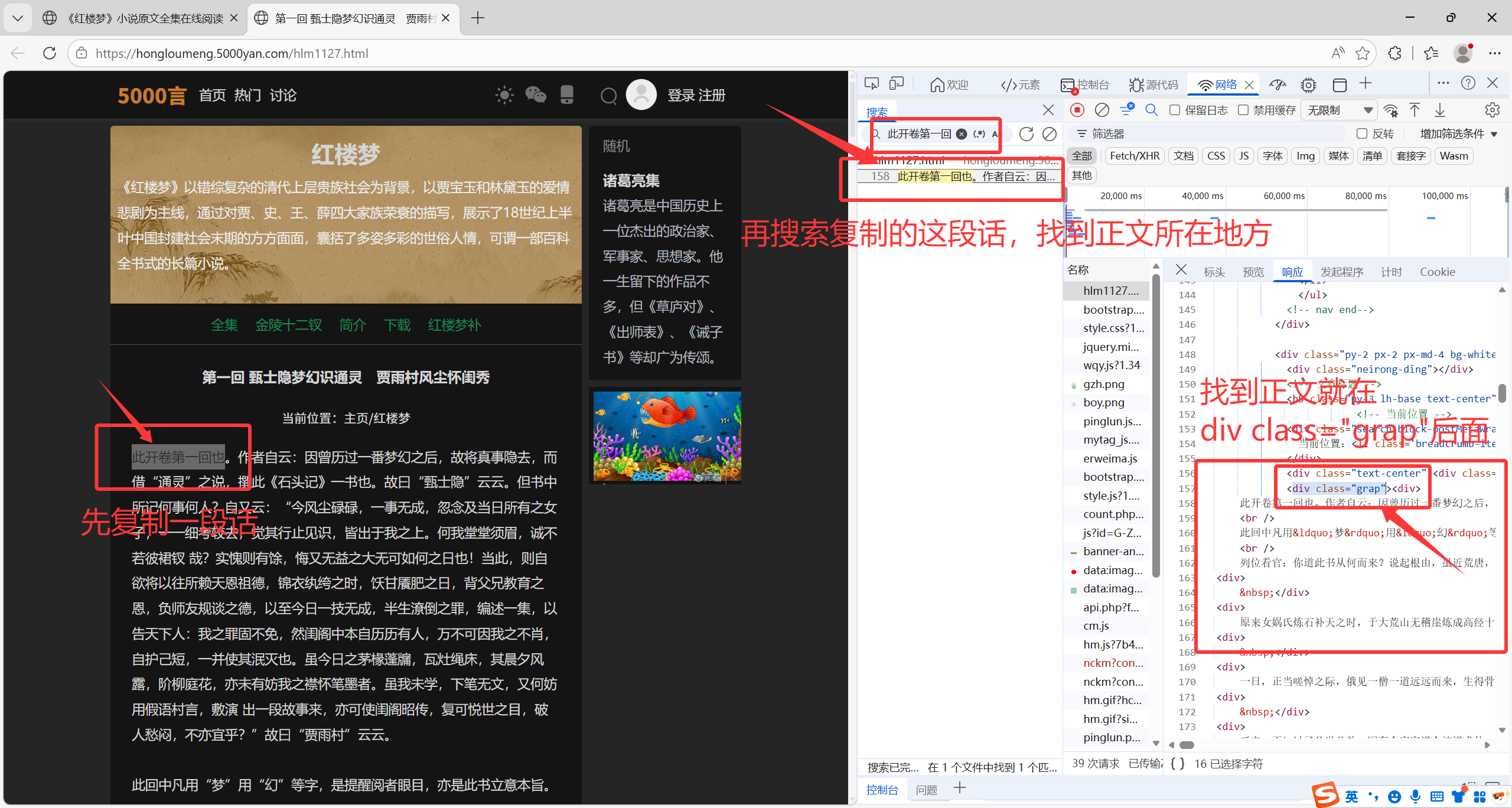
1.3找到爬取需要爬取的正文
1.我们先复制一段话
2.再在搜索框当中搜索,找到正文所在位置
3.找到正文就在div class="grap"后面
OK,现在我们爬虫需要的全部信息都已经获取到了。
二.爬虫代码
import requests
from bs4 import BeautifulSoup
import time
import os
# 配置项
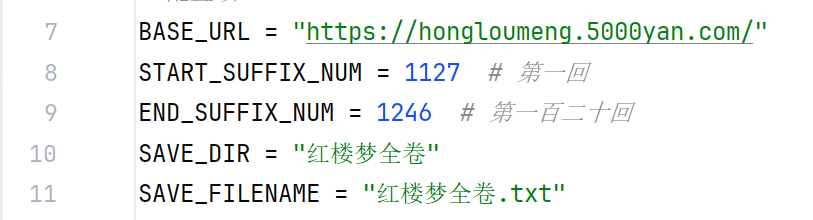
BASE_URL = "https://hongloumeng.5000yan.com/"
START_SUFFIX_NUM = 1127 # 第一回
END_SUFFIX_NUM = 1246 # 第一百二十回
SAVE_DIR = "红楼梦全卷"
SAVE_FILENAME = "红楼梦全卷.txt"
HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"host": "hongloumeng.5000yan.com"
}
def create_save_dir():
"""创建保存目录"""
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
print(f"创建保存目录:{SAVE_DIR}")
def get_chapter_content(url):
"""获取单回内容(精准适配目标网站结构)"""
try:
time.sleep(1) # 防反爬延时
response = requests.get(url, headers=HEADERS, timeout=15)
response.raise_for_status() # 抛出HTTP错误
response.encoding = "utf-8" # 强制UTF-8编码,避免乱码
soup = BeautifulSoup(response.text, "html.parser")
# 1. 提取章节标题
title_tag = soup.find("h5", class_="py-3 lh-base text-center")
chapter_title = title_tag.get_text(
strip=True) if title_tag else f"第{(int(url.split('hlm')[1].split('.')[0]) – 1126)}回 未知标题"
# 2. 提取正文
grap_tag = soup.find("div", class_="grap")
if not grap_tag:
return chapter_title, "未找到正文"
# 3. 清理正文:提取所有文本,去除多余换行和空格
content = []
# 遍历grap下的所有子节点,提取文本
for child in grap_tag.descendants:
if child.name is None and child.strip(): # 只取文本节点,且非空
text = child.strip().replace("\\u200b", "").replace("“",
"“").replace("”",
"”")
text = text.replace("‘", "‘").replace("’", "’").replace(
"<br />", "\\n")
content.append(text)
# 合并文本,去除连续空行
chapter_content = "\\n\\n".join([line for line in content if line])
if not chapter_content:
return chapter_title, "正文内容为空"
return chapter_title, chapter_content
except requests.exceptions.RequestException as e:
return "请求失败", f"错误信息:{str(e)}"
except Exception as e:
return "解析失败", f"错误信息:{str(e)}"
def save_all_chapters_to_single_file(all_chapters):
"""将所有章节保存到单个文件"""
filepath = os.path.join(SAVE_DIR, SAVE_FILENAME)
with open(filepath, "w", encoding="utf-8") as f:
# 写入文件头部
f.write("《红楼梦》全卷\\n")
f.write("=" * 80 + "\\n\\n")
# 按顺序写入所有章节
for chapter_num, chapter_title, chapter_content in all_chapters:
f.write(f"{chapter_title}\\n")
f.write(chapter_content)
f.write("\\n\\n")
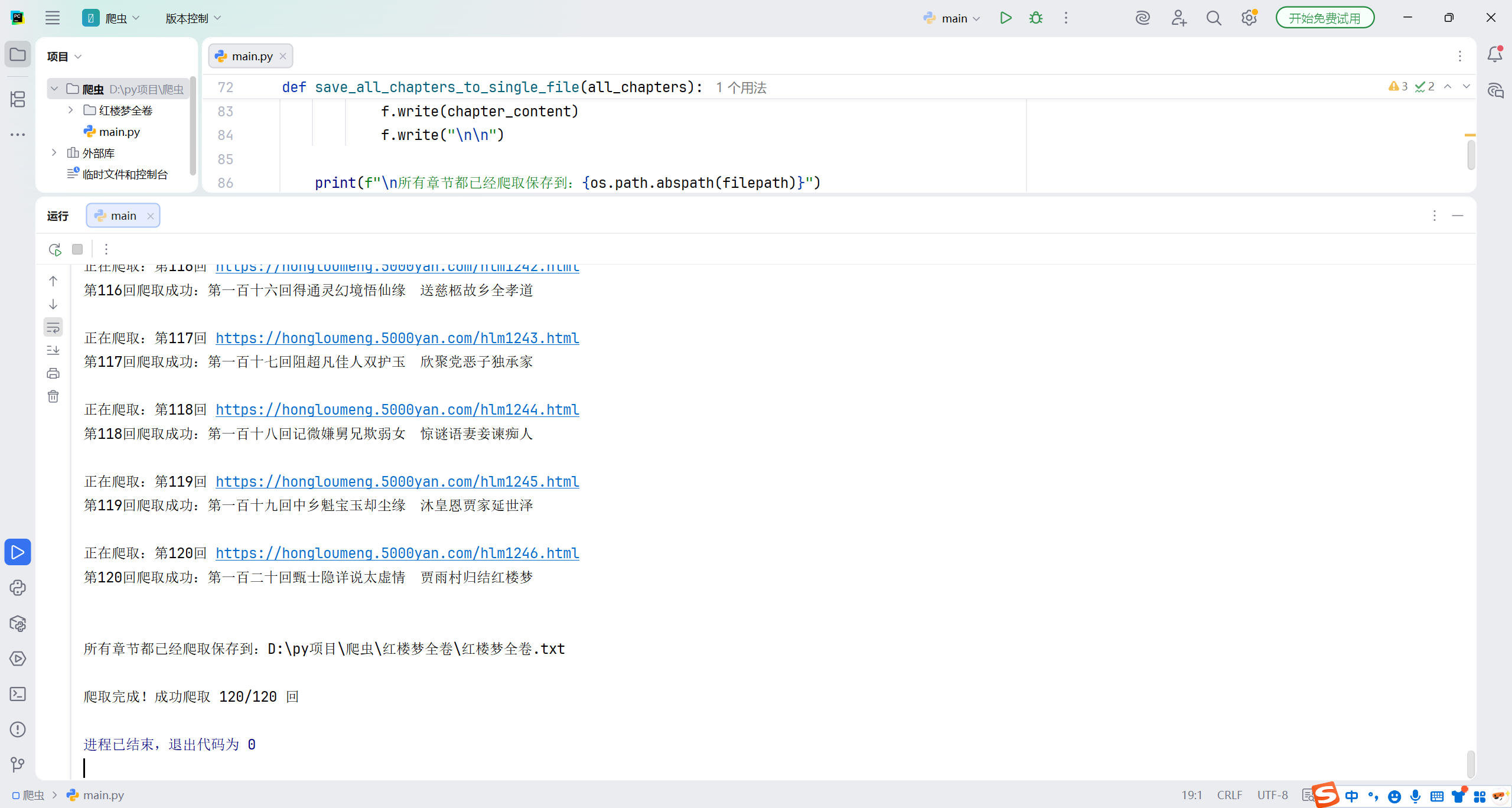
print(f"\\n所有章节都已经爬取保存到:{os.path.abspath(filepath)}")
def crawl_all_chapters():
"""爬取所有章节并合并保存"""
create_save_dir()
total_chapters = END_SUFFIX_NUM – START_SUFFIX_NUM + 1
print(f"开始爬取《红楼梦》全卷,共{total_chapters}回…\\n")
all_chapters = [] # 存储成功爬取的章节
failed_chapters = [] # 存储失败的章节
for idx, suffix_num in enumerate(range(START_SUFFIX_NUM, END_SUFFIX_NUM + 1)):
chapter_num = idx + 1
chapter_url = f"{BASE_URL}hlm{suffix_num}.html"
print(f"正在爬取:第{chapter_num}回 {chapter_url}")
# 获取章节内容
chapter_title, chapter_content = get_chapter_content(chapter_url)
# 处理爬取结果
if "错误信息" not in chapter_content and "未找到" not in chapter_content and "为空" not in chapter_content:
all_chapters.append((chapter_num, chapter_title, chapter_content))
print(f"第{chapter_num}回爬取成功:{chapter_title}\\n")
else:
failed_chapters.append((chapter_num, chapter_content))
print(f"第{chapter_num}回爬取失败:{chapter_content}\\n")
# 保存成功爬取的章节
if all_chapters:
save_all_chapters_to_single_file(all_chapters)
# 输出失败章节汇总
if failed_chapters:
print("\\n爬取失败的章节汇总:")
for c_num, error in failed_chapters:
print(f" 第{c_num}回:{error}")
print(f"\\n爬取完成!成功爬取 {len(all_chapters)}/{total_chapters} 回")
if __name__ == "__main__":
crawl_all_chapters()
介绍一下代码关键地方:

这一块代码是从第一回的1127爬到第一百二十回的1246

这一块代码是必要的请求头结点

这一块就是我们之前找到的正文部分,在div class="grap"后面。
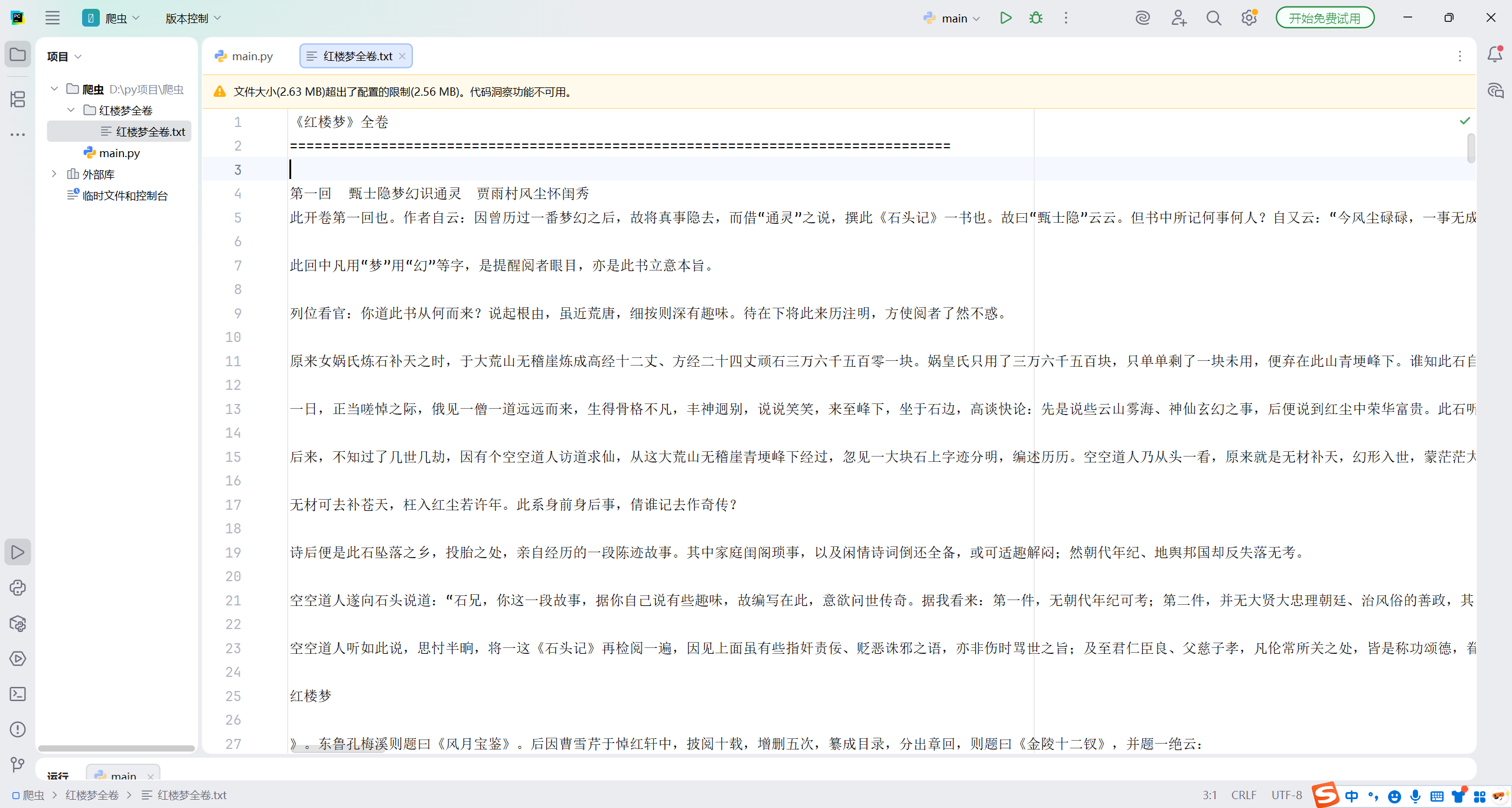
三:将红楼梦切分为120篇
这里我们爬取的是《红楼梦》全卷,我们想要分卷怎么办,首先我们要找我们分卷的依据。在这里我们每一个章节开头都是:第XX回,那么我们能不能用这个来切分。但是有一个需要注意的点:第XX回的XX是汉字不是阿拉伯数字,所以我们还需要提前转换一下。
import os
import re
CHAPTER_HEADER = '第'
CHAPTER_SUFFIX = '回'
CHINESE_NUMBERS = {
'零': 0, '一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9,
'十': 10, '百': 100}
source_file_path = '.\\\\红楼梦全卷\\\\红楼梦全卷.txt'
output_base_dir = '.\\\\红楼梦'
temp_file_path = '.\\\\红楼梦\\\\红楼梦分卷.txt'
chapter_output_dir = '.\\\\红楼梦\\\\红楼梦分卷'
os.makedirs(output_base_dir, exist_ok=True)
os.makedirs(chapter_output_dir, exist_ok=True)
file = open(source_file_path, encoding='utf-8')
flag = 0
juan_file = open(temp_file_path, 'w', encoding='utf-8')
chapter_pattern = re.compile(f'{CHAPTER_HEADER}[一二三四五六七八九十百零]+{CHAPTER_SUFFIX}')
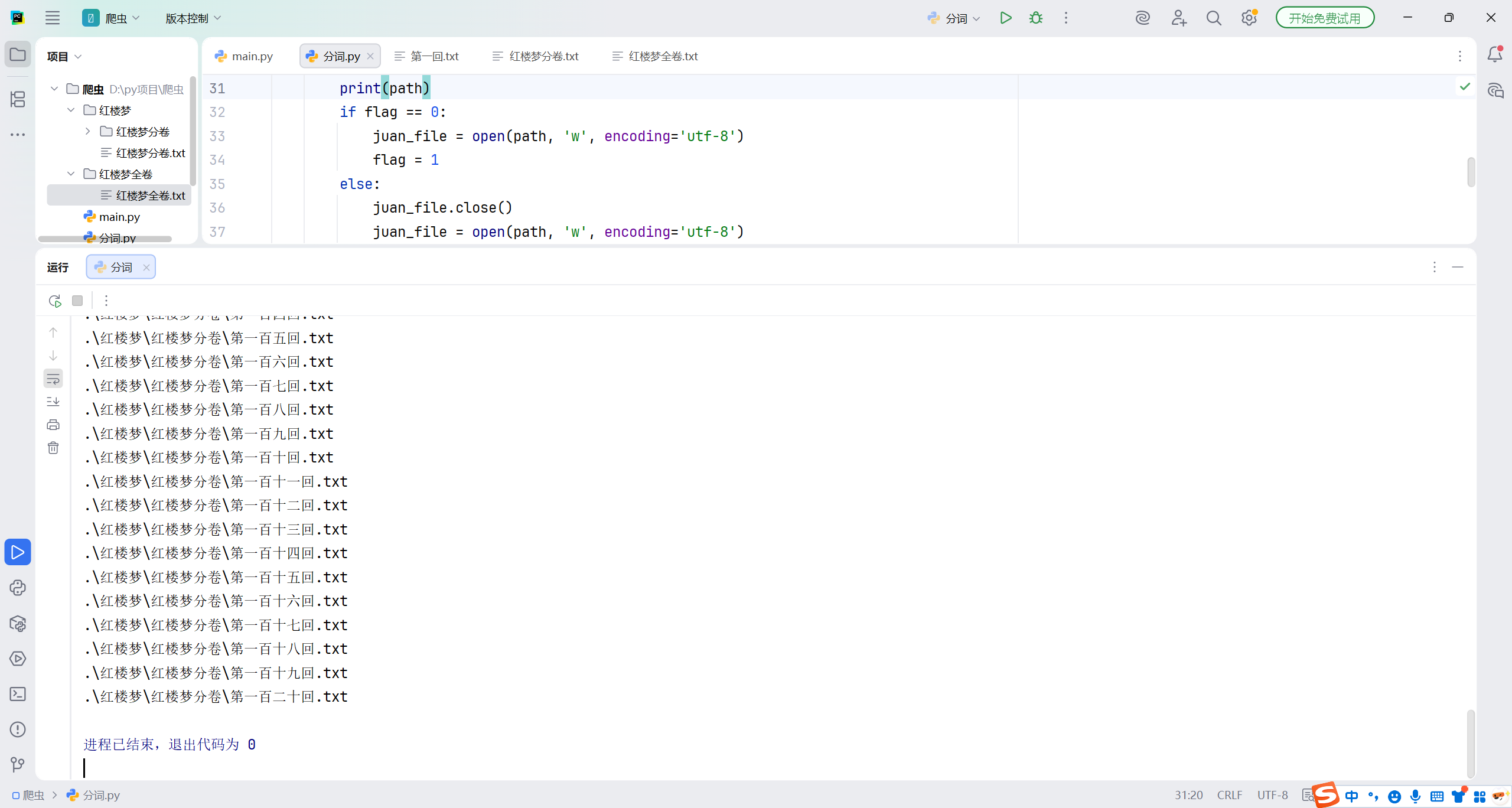
for line in file:
if chapter_pattern.search(line):
chapter_match = chapter_pattern.search(line)
chapter_name = chapter_match.group() + '.txt'
path = os.path.join(chapter_output_dir, chapter_name)
print(path)
if flag == 0:
juan_file = open(path, 'w', encoding='utf-8')
flag = 1
else:
juan_file.close()
juan_file = open(path, 'w', encoding='utf-8')
continue
juan_file.write(line)
juan_file.close()
file.close()

![]()
代码的这一块,我采取的是将汉字与阿拉伯数字一一对应,然后再在后面作为参考进行切分。






评论前必须登录!
注册