 网硕互联帮助中心
网硕互联帮助中心
Python作业:爬虫爬取《红楼梦》全卷,并将其切分为120篇(附完整源代码)
本文从爬取《红楼梦》全卷,到将其切分为120篇,详细的讲解如何操作。以此类推可以爬取《》《西游记》、《三国演义》等其他文本ÿ...
本文从爬取《红楼梦》全卷,到将其切分为120篇,详细的讲解如何操作。以此类推可以爬取《》《西游记》、《三国演义》等其他文本ÿ...
1. 背景引入:实时数据抓取的行业痛点与技术突破1.1 实时数据抓取的核心痛点在数据驱动的开发场景中,实时数据抓取是爬虫程序员的核心...
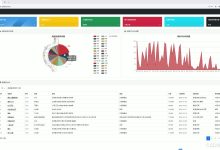
从0到1构建知乎评论数据分析系统:Python爬虫 情感分析 数据研究全流程实践#Python #数据分析 #数据挖掘 #机器学习 #NLP ...
一、引言:为什么需要艺术作品数据库? 在数字时代,艺术作品的数字化管理和分析已成为艺术界、学术界和商业领域的重要需求...
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心...
在高风控网站(如 Amazon、Instagram、Google Ads)的数据采集场景中,静态代理 IP 已成为提升...
一、前言 51job 作为国内主流的招聘平台,其岗位数据是求职分析、行业调研的重要数据源。传统的页面元素解析爬虫易受页面结构变更影响...
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心...
![基于深度学习的糖尿病视网膜病变诊断系统[python]-计算机毕业设计源码+LW文档-网硕互联帮助中心](https://www.wsisp.com/helps/wp-content/uploads/2026/02/20260206021924-69854fac5d043-220x150.jpg)
摘要:糖尿病视网膜病变是糖尿病常见的严重并发症之一,及时准确的诊断对于预防视力损害至关重要。本文提出了一种基于深度学习的糖尿病视网膜...
前言:对于刚入门Python爬虫的小伙伴来说,爬取股票数据是一个非常好的实战案例——数据公开易获取、需求明确(开盘价、收盘价、涨幅等核心指标),还能结合数据可视...
