 网硕互联帮助中心
网硕互联帮助中心一、Swin Transformer核心概念
Swin Transformer(Shifted Window Transformer)是专为视觉任务设计的 Transformer 变体,解决了原始 Transformer 在处理高分辨率图像时计算量爆炸的问题,核心创新是分层结构和移位窗口注意力机制。
核心概念:
- 分层特征提取:模仿 CNN 的层级结构,通过 Patch Merging 逐步缩小特征图尺寸、提升通道数,适配不同尺度的视觉特征。
- 窗口注意力(Window Attention):将特征图划分为不重叠的窗口,仅在窗口内计算自注意力,把复杂度从
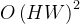 降低到
降低到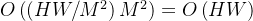 ,其中M 为窗口大小。
,其中M 为窗口大小。 - 移位窗口注意力(Shifted Window Attention):解决窗口间信息孤立问题,通过循环移位生成新窗口,同时用「掩码(Mask)」避免无效计算,保证窗口内注意力的正确性。
二、Swin Transformer数学公式
(1)Patch Partition(分块)
将原始图像(H×W×3)划分为大小为 4×4 的不重叠 Patch,每个 Patch 展平为一维向量:
![Patch(i,j)=Image\\left [ 4i:4i+4,4j:4j+4,: \\right ]\\rightarrow R^{4\\times 4\\times 3}\\rightarrow R ^{48}](https://www.wsisp.com/helps/wp-content/uploads/2026/02/20260224145752-699dbc702d044.png)
最终得到 (H/4×W/4)×48 的特征图,记为 。
。
(2)Window Attention 计算
在每个窗口内计算自注意力,核心公式与标准自注意力一致,但作用域限制在窗口内:
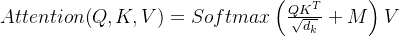
- Q,K,V:查询 / 键 / 值矩阵,由输入特征线性变换得到,dk 为 Q/K 的维度;
- M:掩码矩阵在仅 Shifted Window 时生效,用于屏蔽移位后跨原始窗口的无效注意力计算。
(3)Shifted Window 移位操作
设窗口大小为 M,特征图尺寸为 H×W,移位量为 ⌊M/2⌋,移位后坐标变换:
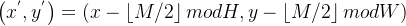 ;
;
(4)Patch Merging(分层下采样)
将 2×2 相邻 Patch 拼接,通道数翻倍,尺寸减半:
![Out\\left [ i,j,: \\right ]=In\\left [ 2i:2i+2,2j:2j+2,: \\right ]\\rightarrow R^{4C}\\rightarrow R^{2C}](https://www.wsisp.com/helps/wp-content/uploads/2026/02/20260224145752-699dbc706c71c.png)
最终特征图尺寸变为 H/2×W/2×2C。
三、实例代码解释
模块一:核心代码导入
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
模块二:窗口注意力
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads):
"""
窗口注意力模块初始化
Args:
dim: 输入特征的通道数(如 96、192)
window_size: 窗口大小(M),默认7,代表7×7的窗口
num_heads: 多头注意力的头数,需满足 dim % num_heads == 0
"""
super().__init__()
# 保存基础参数
self.dim = dim # 输入通道数
self.window_size = window_size # 窗口大小 M
self.num_heads = num_heads # 注意力头数
self.head_dim = dim // num_heads # 每个注意力头的维度
self.scale = self.head_dim ** -0.5 # 缩放因子 1/√d_k,防止内积值过大
# 线性变换层:将输入特征一次性映射为Q、K、V(效率高于3个独立线性层)
# 输入dim → 输出3*dim(Q/K/V各占dim)
self.qkv = nn.Linear(dim, dim * 3)
# 输出投影层:将注意力计算后的特征映射回原维度
self.proj = nn.Linear(dim, dim)
# 相对位置偏置表:解决绝对位置编码的局限性,捕捉窗口内位置关系
# 尺寸:(2M-1)×(2M-1) × num_heads → 覆盖窗口内所有可能的相对位置
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size – 1) * (2 * window_size – 1), num_heads)
)
# ————————– 预计算相对位置索引 ————————–
# 生成窗口内的坐标网格:[0,1,…,M-1]
coords = torch.arange(self.window_size)
# 生成2×M×M的坐标矩阵:coords_grid[0]是行坐标,coords_grid[1]是列坐标
coords_grid = torch.stack(torch.meshgrid([coords, coords], indexing="ij"))
# 展平坐标:2 × M²(把M×M的坐标拉成一维)
coords_flatten = torch.flatten(coords_grid, 1)
# 计算所有位置对的相对坐标:(2, M², M²) → 每个位置相对于其他位置的偏移
relative_coords = coords_flatten[:, :, None] – coords_flatten[:, None, :]
# 维度重排:(M², M², 2) → [位置i, 位置j, 行/列偏移]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
# 将相对坐标从[-M+1, M-1]映射到[0, 2M-2](避免负数索引)
relative_coords[:, :, 0] += self.window_size – 1 # 行偏移修正
relative_coords[:, :, 1] += self.window_size – 1 # 列偏移修正
# 行索引编码:行偏移 × (2M-1) + 列偏移 → 唯一标识每个相对位置
relative_coords[:, :, 0] *= 2 * self.window_size – 1
# 求和得到最终的相对位置索引:(M², M²)
relative_position_index = relative_coords.sum(-1)
# 注册为缓冲区(不参与梯度更新)
self.register_buffer("relative_position_index", relative_position_index)
def forward(self, x, mask=None):
"""
窗口注意力前向传播
Args:
x: 输入特征,形状 [num_windows*B, M², dim]
– num_windows: 特征图划分的窗口总数
– B: batch size
– M²: 单个窗口的像素数
– dim: 通道数
mask: 掩码矩阵(仅移位窗口时使用),形状 [num_windows, M², M²]
Returns:
output: 注意力计算后的特征,形状 [num_windows*B, M², dim]
"""
# 获取输入维度:B_=num_windows*B, N=M², C=dim
B_, N, C = x.shape
# ————————– 生成Q/K/V ————————–
# 1. 线性变换:[B_, N, C] → [B_, N, 3*C]
# 2. 维度重排:[B_, N, 3, num_heads, head_dim] → 拆分3个维度给Q/K/V
# 3. 维度置换:[3, B_, num_heads, N, head_dim]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
# 拆分Q/K/V:每个的形状都是 [B_, num_heads, N, head_dim]
q, k, v = qkv[0], qkv[1], qkv[2]
# ————————– 计算注意力分数 ————————–
q = q * self.scale # 缩放Q,对应公式中的 1/√d_k
# Q @ K^T:[B_, num_heads, N, head_dim] × [B_, num_heads, head_dim, N] → [B_, num_heads, N, N]
attn = (q @ k.transpose(-2, -1))
# ————————– 添加相对位置偏置 ————————–
# 从偏置表中取出对应位置的偏置:[M²*M², num_heads] → [M², M², num_heads]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size * self.window_size, self.window_size * self.window_size, -1
)
# 维度重排:[num_heads, M², M²]
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
# 添加偏置:[B_, num_heads, N, N] + [1, num_heads, N, N] → 广播相加
attn = attn + relative_position_bias.unsqueeze(0)
# ————————– 应用掩码(移位窗口专用) ————————–
if mask is not None:
nW = mask.shape[0] # 获取窗口数量
# 1. 维度适配:将attn拆分为 [B//nW, nW, num_heads, N, N]
# 2. 掩码广播:mask [nW, N, N] → [1, nW, 1, N, N]
# 3. 相加:将掩码值(-100)加到跨窗口的注意力分数上
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
# 还原维度:[B_, num_heads, N, N]
attn = attn.view(-1, self.num_heads, N, N)
# Softmax归一化:掩码位置的-100会被Softmax为0,不参与计算
attn = F.softmax(attn, dim=-1)
else:
# 无掩码时直接Softmax
attn = F.softmax(attn, dim=-1)
# ————————– 注意力加权求和V ————————–
# attn [B_, num_heads, N, N] × v [B_, num_heads, N, head_dim] → [B_, num_heads, N, head_dim]
# 维度置换:[B_, N, num_heads, head_dim] → 合并头维度 → [B_, N, dim]
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
# ————————– 输出投影 ————————–
x = self.proj(x) # 线性变换,保持维度不变
return x
# ========================== 辅助函数:窗口划分与还原 ==========================
def window_partition(x, window_size):
"""
将特征图划分为不重叠的窗口
Args:
x: 输入特征,形状 [B, H, W, C]
window_size: 窗口大小 M
Returns:
windows: 窗口化特征,形状 [num_windows*B, M, M, C]
num_windows = (H/M) × (W/M)
"""
B, H, W, C = x.shape
# 维度拆分:[B, H, W, C] → [B, H//M, M, W//M, M, C]
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# 维度置换:[B, H//M, W//M, M, M, C] → 合并前三维 → [num_windows*B, M, M, C]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
将窗口化特征还原为完整特征图(window_partition的逆操作)
Args:
windows: 窗口化特征,形状 [num_windows*B, M, M, C]
window_size: 窗口大小 M
H, W: 原始特征图的高和宽
Returns:
x: 还原后的特征图,形状 [B, H, W, C]
"""
# 计算batch size:num_windows = (H*W)/(M*M) → B = total_windows / num_windows
B = int(windows.shape[0] / (H * W / window_size / window_size))
# 维度拆分:[num_windows*B, M, M, C] → [B, H//M, W//M, M, M, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, C)
# 维度置换:[B, H//M, M, W//M, M, C] → 合并维度 → [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, C)
return x
模块三:Swin Transformer Block
class SwinTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0):
"""
Swin Transformer 基础块(包含窗口注意力/移位窗口注意力)
Args:
dim: 输入通道数
num_heads: 注意力头数
window_size: 窗口大小 M
shift_size: 移位量(0=普通窗口,M//2=移位窗口)
"""
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size # 移位量,核心参数
# 层归一化(Transformer标准操作,放在注意力前)
self.norm1 = nn.LayerNorm(dim)
# 实例化窗口注意力模块
self.attn = WindowAttention(dim, window_size, num_heads)
def forward(self, x):
"""
Swin Block 前向传播
Args:
x: 输入特征,形状 [B, H, W, C]
Returns:
x: 输出特征,形状 [B, H, W, C](残差连接后)
"""
B, H, W, C = x.shape
shortcut = x # 保存残差连接的输入
# 1. 层归一化
x = self.norm1(x)
# ————————– 移位操作(Shifted Window) ————————–
if self.shift_size > 0:
# 循环移位:向左、向上移动shift_size个像素(负数表示左/上移)
# 例如M=7,shift_size=3 → 左移3,上移3
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# ————————– 生成移位窗口的掩码 ————————–
# 1. 初始化掩码矩阵:[1, H, W, 1],用于标记不同原始区域
img_mask = torch.zeros((1, H, W, 1), device=x.device)
# 2. 划分移位后的区域切片(共3×3=9个区域)
h_slices = (slice(0, -self.window_size), # 上半部分
slice(-self.window_size, -self.shift_size), # 中间过渡区
slice(-self.shift_size, None)) # 下半部分
w_slices = (slice(0, -self.window_size), # 左半部分
slice(-self.window_size, -self.shift_size), # 中间过渡区
slice(-self.shift_size, None)) # 右半部分
# 3. 为每个区域分配唯一标签(0-8)
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# 4. 将掩码划分为窗口:[num_windows, M, M, 1]
mask_windows = window_partition(img_mask, self.window_size)
# 5. 展平掩码:[num_windows, M²]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
# 6. 计算注意力掩码:判断两个位置是否属于同一原始区域
# – 同一区域:mask=0 → Softmax后正常计算
# – 不同区域:mask=-100 → Softmax后为0,不参与计算
attn_mask = mask_windows.unsqueeze(1) – mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
# 普通窗口:不移位,无掩码
shifted_x = x
attn_mask = None
# ————————– 窗口注意力计算 ————————–
# 1. 划分窗口:[B, H, W, C] → [num_windows*B, M, M, C]
x_windows = window_partition(shifted_x, self.window_size)
# 2. 展平窗口:[num_windows*B, M², C](适配WindowAttention输入)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
# 3. 窗口注意力前向计算
attn_windows = self.attn(x_windows, mask=attn_mask)
# ————————– 还原窗口为特征图 ————————–
# 1. 还原窗口形状:[num_windows*B, M², C] → [num_windows*B, M, M, C]
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
# 2. 窗口还原为特征图:[num_windows*B, M, M, C] → [B, H, W, C]
shifted_x = window_reverse(attn_windows, self.window_size, H, W)
# ————————– 逆移位(恢复原始位置) ————————–
if self.shift_size > 0:
# 向右、向下移动shift_size个像素,还原到原始位置
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
# ————————– 残差连接 ————————–
x = shortcut + x # 残差相加,提升梯度传播
return x
模块四:Patch Merging(分层下采样)
class PatchMerging(nn.Module):
def __init__(self, dim):
"""
Patch Merging 模块:将2×2相邻Patch合并,实现下采样
Args:
dim: 输入通道数
"""
super().__init__()
self.dim = dim
# 线性变换:将4*dim通道压缩为2*dim(下采样后通道数翻倍)
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
# 层归一化:放在线性变换前,提升稳定性
self.norm = nn.LayerNorm(4 * dim)
def forward(self, x):
"""
Patch Merging 前向传播
Args:
x: 输入特征,形状 [B, H, W, C]
Returns:
x: 下采样后的特征,形状 [B, H/2, W/2, 2C]
"""
B, H, W, C = x.shape
# ————————– 2×2 Patch合并 ————————–
# 1. 维度拆分:[B, H, W, C] → [B, H//2, 2, W//2, 2, C]
x = x.view(B, H // 2, 2, W // 2, 2, C)
# 2. 维度置换:[B, H//2, W//2, 2, 2, C] → 合并最后三维 → [B, H//2, W//2, 4C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H // 2, W // 2, -1)
# ————————– 归一化+通道压缩 ————————–
x = self.norm(x) # 层归一化
x = self.reduction(x) # 4C → 2C,通道数翻倍
return x
模块五:测试代码
if __name__ == "__main__":
# 模拟输入:batch_size=2,特征图56×56,通道数96(Swin-T的第一层特征)
x = torch.randn(2, 56, 56, 96)
# 1. 测试普通窗口注意力块(无移位)
block1 = SwinTransformerBlock(dim=96, num_heads=8, window_size=7, shift_size=0)
out1 = block1(x)
print("普通窗口注意力输出形状:", out1.shape) # 预期:torch.Size([2, 56, 56, 96])
# 2. 测试移位窗口注意力块(移位量=3)
block2 = SwinTransformerBlock(dim=96, num_heads=8, window_size=7, shift_size=3)
out2 = block2(x)
print("移位窗口注意力输出形状:", out2.shape) # 预期:torch.Size([2, 56, 56, 96])
# 3. 测试Patch Merging下采样
patch_merge = PatchMerging(dim=96)
out3 = patch_merge(x)
print("Patch Merging输出形状:", out3.shape) # 预期:torch.Size([2, 28, 28, 192])
用 “分窗口算注意力” 降低计算量,用 “挪窗口 + 掩码” 打通窗口间信息,用 “合并像素块” 构建分层特征,最终让 Transformer 能高效处理图片,既快又能学到有用的特征。、
运行结果:
普通窗口注意力输出形状: torch.Size([2, 56, 56, 96])
移位窗口注意力输出形状: torch.Size([2, 56, 56, 96])
Patch Merging输出形状: torch.Size([2, 28, 28, 192])
- 输入一张真实图片(比如猫、狗的照片);
- 模型输出这张图片的 “高级特征”(不是像素,是能描述 “这是猫、那是狗” 的特征);
- 再搭配简单的分类 / 检测头,就能实现图片分类、目标检测、语义分割等视觉任务(比如识别图片里有什么、找到物体的位置)。
四、总结
- 核心创新:Swin Transformer 用「窗口注意力」降低计算复杂度,用「移位窗口注意力」解决窗口间信息孤立问题,适配高分辨率视觉任务;
- 数学核心:窗口内自注意力公式,其中掩码 M 是移位窗口的关键;
- 代码核心:
- 窗口划分 / 还原是窗口注意力的基础;
- 移位 + 掩码是实现 Shifted Window 的核心;
- Patch Merging 实现分层下采样,模仿 CNN 的层级特征。









评论前必须登录!
注册