 网硕互联帮助中心
网硕互联帮助中心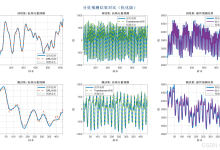
VMD-SE-GRU+Transformer多变量时序预测,MATLAB代码
该代码实现了一种基于 VMD(变分模态分解)- 样本熵 - GRUTransformer 的混合多变量时间序列预测模型。 一、研究背...
该代码实现了一种基于 VMD(变分模态分解)- 样本熵 - GRUTransformer 的混合多变量时间序列预测模型。 一、研究背...
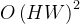
一、Swin Transformer核心概念 Swin Transformer(Shifted Window Transformer)...

线性注意力机制 (Linear Attention Mechanism) 是为了解决传统 Transformer 模型“记性越好,算得越慢” 这一...

本篇技术博文摘要 🌟 文章开篇即阐明使用PyTorch框架实现Transformer的实际价值与重要意义,指出其在自然语言处理等领...
步骤1:位置嵌入与词映射import torch import torch.nn as nn import mathclass Transform...
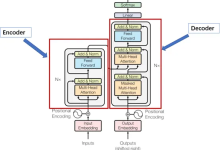
一、Transformer 的输入是什么? Transformer 的输入是数字化的序列数据,需经过3 层编码后才能送入注意力层和...
从Transformer 底层原理 来看,提示词的“冗余”是一个与模型的 注意力机制 、 上下文理解逻辑 以及 信息处理效率 一、先理解:为什么叫「自注意力」?...
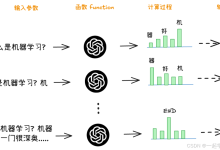
目录 1 LLM (大语言模型) 2 Transformer (自注意力机制) 3 Prompt (提示词) 4 理解API 5 Function Callin...

本文深入探讨了Anthropic的Skills与MCP如何协同工作构建智能代理。MCP提供外部工具连接性,Skills提供工作流程逻辑和专业知识&...
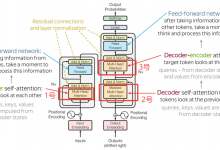
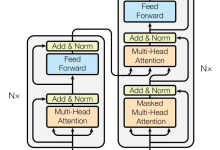
目的 为避免一学就会、一用就废,这里做下笔记 说明 本文内容紧承前文-Transformer架构1-整体介绍、Transformer架构2-...
