 网硕互联帮助中心
网硕互联帮助中心华为昇腾服务器安装Xinference详细记录
-
-
- 开始安装
- 启动容器
- 进入容器
- Xinf启动模型
- 测试
- 推理测试
-
注意:截止2025年4月14日,310P3 NPU,Xinference社区版推理LLM速度非常慢,建议安装MindIE(
跳转)
!!!无特别需求,尽量都选用MindIE。亲测MindIE性能 > vllm-ascend。!!!
目前vllm支持情况: Currently, ONLY Atlas A2 series (Ascend-cann-kernels-910b) are supported: Atlas A2 Training series (Atlas 800T A2, Atlas 900 A2 PoD, Atlas 200T A2 Box16, Atlas 300T A2) Atlas 800I A2 Inference series (Atlas 800I A2) Below series are NOT supported yet: Atlas 300I Duo、Atlas 300I Pro (Ascend-cann-kernels-310p) might be supported on 2025.Q2 Atlas 200I A2 (Ascend-cann-kernels-310b) unplanned yet Ascend 910, Ascend 910 Pro B (Ascend-cann-kernels-910) unplanned yet
开始安装

Xinference需要配置驱动、torch、torch-npu等环境,最简单的方法是套用MindIE镜像。省略下载容器,详情见(跳转)
启动容器
docker run -it -d –net=host –shm-size=1g \\
–name Xinf \\
–device /dev/davinci0 \\
–device /dev/davinci1 \\
–device /dev/davinci2 \\
–device /dev/davinci3 \\
–device /dev/davinci4 \\
–device /dev/davinci5 \\
–device /dev/davinci6 \\
–device /dev/davinci7 \\
–device /dev/davinci_manager \\
–device /dev/devmm_svm \\
–device /dev/hisi_hdc \\
-v /usr/local/dcmi:/usr/local/dcmi \\
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \\
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \\
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \\
-v /etc/ascend_install.info:/etc/ascend_install.info \\
-v /data/modelscope/hub/models/deepseek-ai:/data/models \\
-it swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-300I-Duo-py311-openeuler24.03-lts bash
进入容器
docker exec -it Xinf bash
查看显卡是否正常: 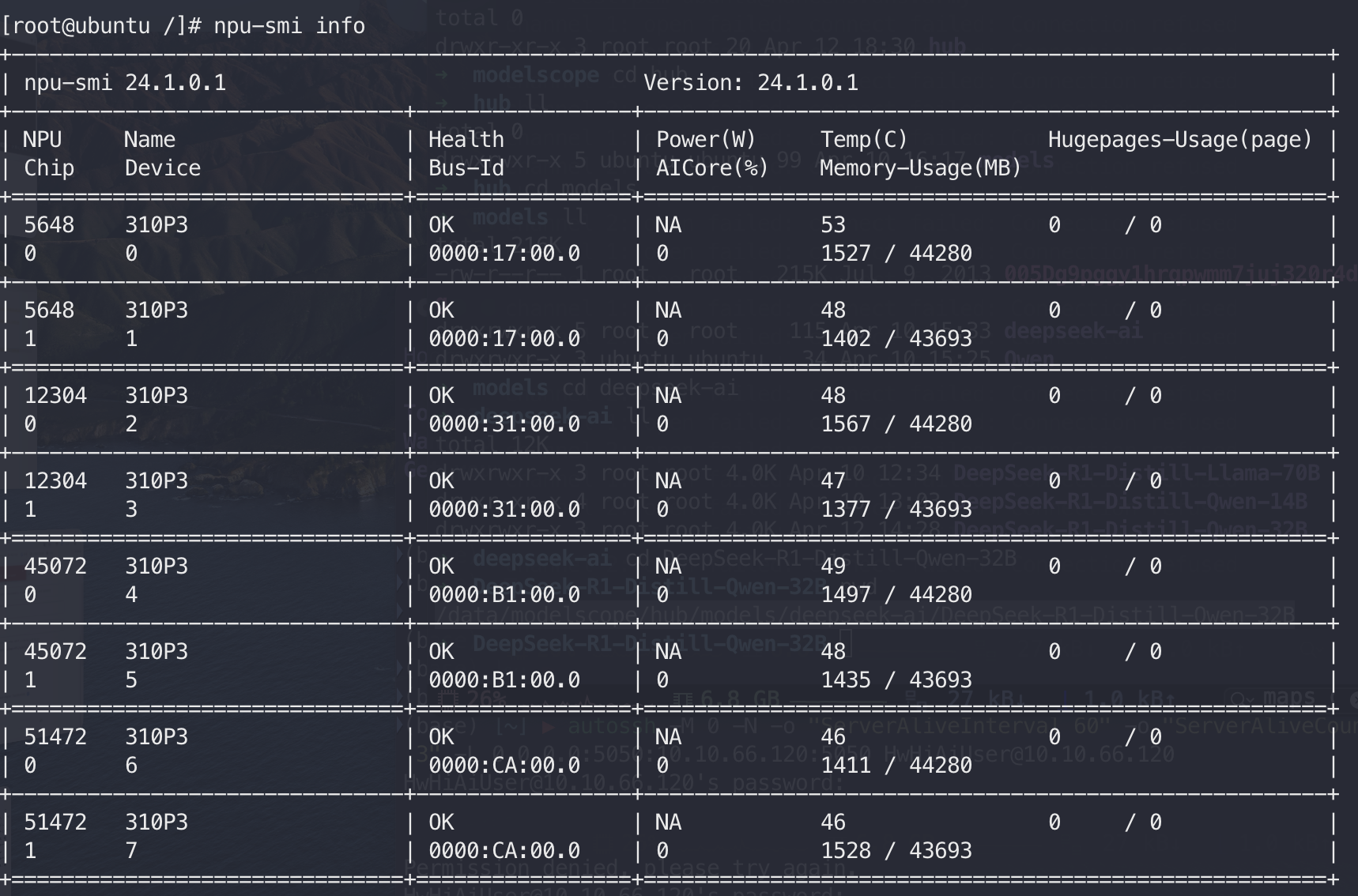 运行如下命令查看,如果正常运行,会打印昇腾 NPU 的个数。
运行如下命令查看,如果正常运行,会打印昇腾 NPU 的个数。
python -c "import torch; import torch_npu; print(torch.npu.device_count())"
开始安装Xinference
pip3 install xinference -i https://pypi.tuna.tsinghua.edu.cn/simple
版本参考: torch 2.1.0+cpu torch-npu 2.1.0.post10 torchvision 0.16.0 xinference 1.4.1
启动Xinference
xinference-local –host 0.0.0.0 –port 9997
后台运行:
nohup xinference-local –host 0.0.0.0 –port 9997 > xinference.log 2>&1 &
启动成功!
Xinf启动模型
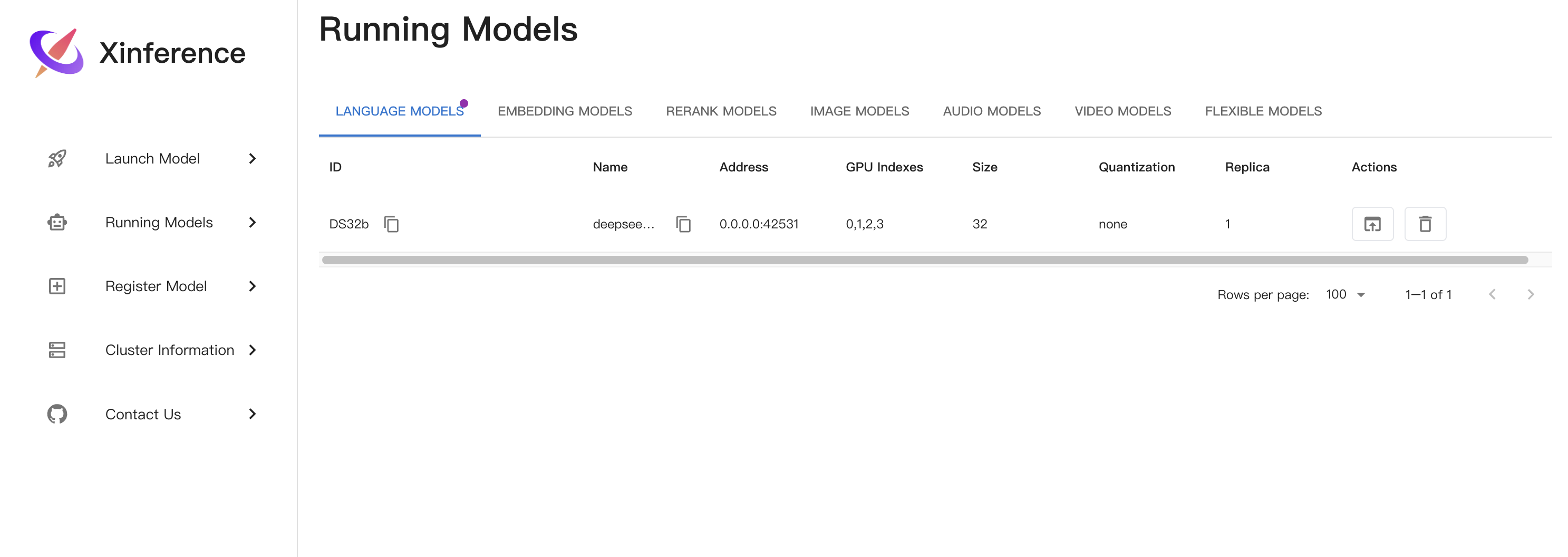
测试
curl -X 'POST' \\
'http://127.0.0.1:9997/v1/chat/completions' \\
-H 'accept: application/json' \\
-H 'Content-Type: application/json' \\
-d '{
"model": "DS14b",
"stream": true,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is the largest animal?"
}
]
}'
Xinference配置如下: 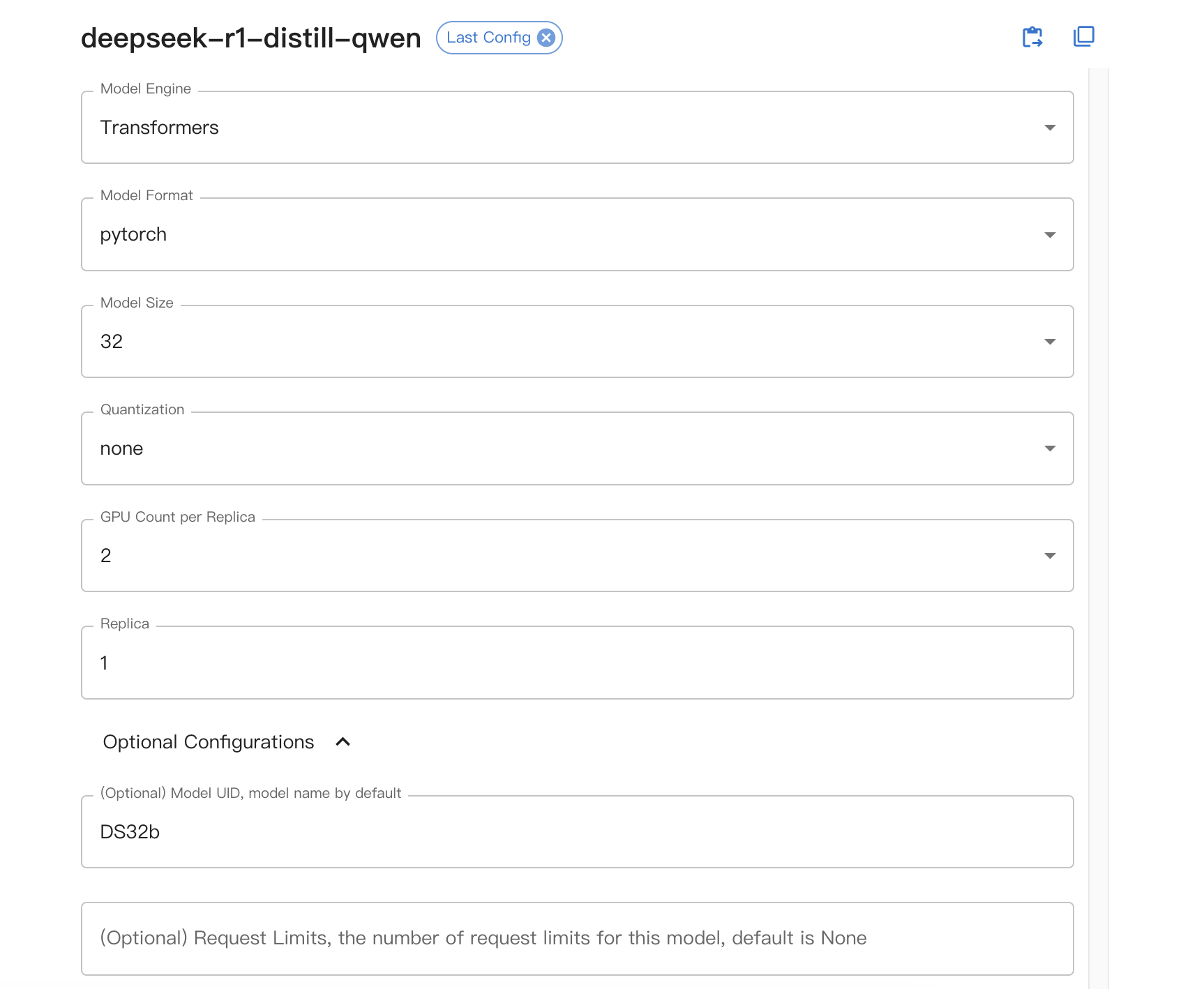
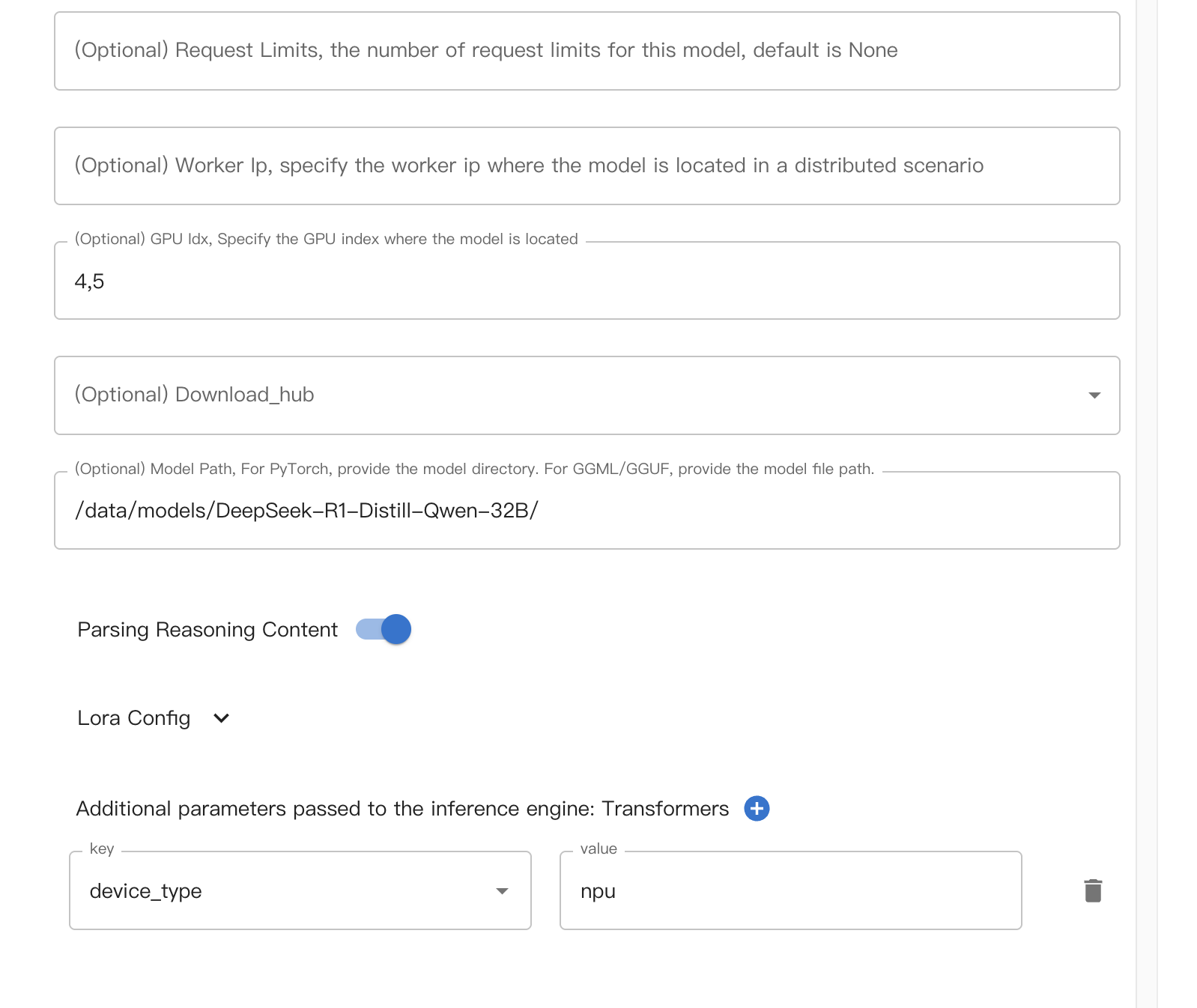
推理测试
正常!但是非常非常非常非常非常慢,根本不能使用。 如果你是310P NPU最好就是使用MindIE了。 Xinference企业版或升级昇腾的训练卡NPU? 成本较高了! 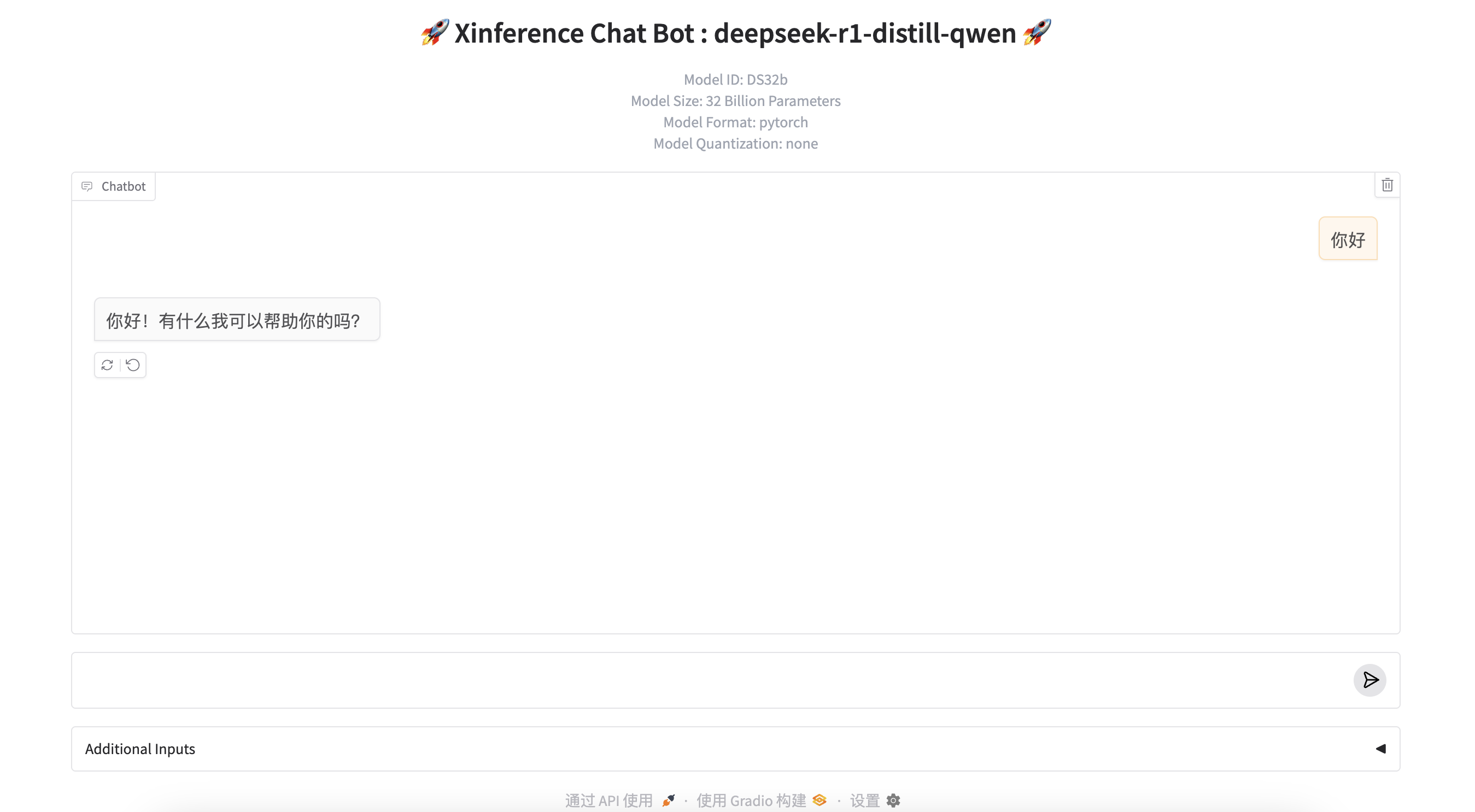 参考链接: https://github.com/Ascend/pytorch/issues/49
参考链接: https://github.com/Ascend/pytorch/issues/49


评论前必须登录!
注册