目录
论文传送门:https://dl.acm.org/doi/10.1145/3383313.3412236
一、多任务学习背景
首先在进入论文分享前,需要思考🤔️一下,什么是多任务学习?为什么需要多任务学习?
什么是多任务学习?
为什么需要多任务学习?(优势/意义)
提升泛化性能
数据效率优化
降低计算成本
多任务学习中存在的跷跷板现象是什么?会有什么样的问题?
跷跷板现象是什么?
会有什么样的问题?
任务间负迁移:
主导任务压制
收敛困难
深挖下背后的根本原因
梯度冲突
任务相关性不足
损失权重分配不合理
常规的解决方案
动态梯度调整
自适应损失加权
任务分组与解耦
优化目标设计
小结:背景涵盖的东西可能比较多,很多部分单独拉出来也能说很多,大家先有个宏观的框架认知,随着论文分享的不断增多,就会逐渐熟悉每一个部分,螺旋式上升,莫急。
期望:希望各位看完ple的论文分享,问自己以下3个问题
二、论文背景
当前现状
多任务学习mtl模型往往会出现性能退化和负迁移问题,源自于现实推荐系统中任务关联的复杂性和竞争性
“跷跷板”现象的发现:提升某一任务性能时,往往会损害其他某些任务的性能。
本文的意义
提出了一种具有创新共享结构设计的渐进式分层提取(PLE)模型。
应用场景与实验结果
线上效果与扩展验证
三、论文核心讲解
CGC(Customized Gate Control)模型结构讲解
结构有三部分
专家网络
塔式网络
门控网络
为什么要ple,cgc还不够吗?
权重函数、选择矩阵和门控网络的计算
多专家与门控网络的渐进式分层提取
PLE(渐进式分层提取)通过多层次专家和门控网络,为每个任务提取并融合更深层的语义表征,从而提升泛化能力。如,MMOE采用全连接路由策略,CGC采用早期分离策略,而PLE则采用渐进式分离路由机制:吸收所有底层专家的信息,提取更高层次的共享知识,并逐步分离任务特定参数
渐进式分离的化学类比
路由策略的对比与收敛性
多任务学习的联合损失优化
四、总结
论文传送门:https://dl.acm.org/doi/10.1145/3383313.3412236
一、多任务学习背景
首先在进入论文分享前,需要思考🤔️一下,什么是多任务学习?为什么需要多任务学习?
什么是多任务学习?
简化版本:就是同时学习多个任务
学术版本:多任务学习(Multi-Task Learning, MTL)是一种机器学习范式,通过同时训练模型完成多个相关任务,共享模型的部分结构或参数。其核心思想是利用任务间的关联性,提升模型在各项任务上的泛化能力,而非独立训练多个单任务模型。
为什么需要多任务学习?(优势/意义)
提升泛化性能
简化版本:
学术版本:多个任务共享部分模型参数时,模型需学习对所有任务通用的特征表示,从而减少过拟合风险。例如,在自然语言处理中,同时训练词性标注和命名实体识别任务,模型能更好地捕捉语言结构的共性
数据效率优化
简化版本:针对于数据缺失的任务,可以“借用”数据充足的任务
学术版本:某些任务可能数据稀缺(如医疗影像分析),而其他相关任务数据丰富。多任务学习允许数据丰富的任务辅助数据稀缺的任务,充分利用有限标注数据。
降低计算成本
简化版本:实惠
学术版本:单一模型处理多个任务比维护多个独立模型更节省存储和计算资源。例如,自动驾驶系统需同时检测行人、车辆和交通标志,多任务模型可共享主干网络。
多任务学习中存在的跷跷板现象是什么?会有什么样的问题?
跷跷板现象是什么?
跷跷板现象(Seesaw Phenomenon)是多任务学习(MTL)中常见的问题,指模型在优化多个任务时,某些任务性能提升的同时其他任务性能下降,导致任务间出现动态的竞争关系。这种现象类似于跷跷板的两端此起彼伏,难以同时平衡所有任务的性能。
会有什么样的问题?
任务间负迁移:
部分任务因共享参数或特征空间,在梯度更新时产生冲突。例如,任务A的梯度优化方向可能对任务B的性能产生负面影响。
主导任务压制
某些任务(如损失值较大或数据量较多的任务)可能在训练中占据主导地位,导致其他任务被忽略,最终整体性能不均衡。
收敛困难
动态的梯度竞争可能导致模型难以稳定收敛,训练过程波动较大,甚至陷入局部最优解。
深挖下背后的根本原因
梯度冲突
不同任务的损失函数梯度方向不一致,尤其在共享底层网络时,反向传播的梯度可能相互抵消或对抗。
任务相关性不足
若任务间的关联性较弱(如语义差异大),强行共享特征空间会导致跷跷板效应加剧。
损失权重分配不合理
固定或人工设定的任务权重无法适应训练过程中的动态变化,导致某些任务被过度优化或忽略。
常规的解决方案
动态梯度调整
通过梯度归一化(如PCGrad)或投影(如GradDrop)方法,减少任务间梯度的冲突。例如,PCGrad会将冲突的梯度投影到彼此的正交方向。
自适应损失加权
采用动态权重调整策略(如Uncertainty Weighting、GradNorm),根据任务难度或梯度大小自动平衡损失权重。
任务分组与解耦
对相关性强的任务共享底层参数,弱相关任务使用独立模块,减少干扰。例如,MMoE(Multi-gate Mixture of Experts)通过门控机制灵活分配专家网络。
优化目标设计
引入帕累托优化(Pareto Optimality)或多目标优化方法,直接优化任务间的平衡性而非单一任务性能。
小结:背景涵盖的东西可能比较多,很多部分单独拉出来也能说很多,大家先有个宏观的框架认知,随着论文分享的不断增多,就会逐渐熟悉每一个部分,螺旋式上升,莫急。
期望:希望各位看完ple的论文分享,问自己以下3个问题
ple的网络结构,是否掌握
ple应该在什么场景下进行使用
ple出现的意义是什么?
二、论文背景
当前现状
多任务学习mtl模型往往会出现性能退化和负迁移问题,源自于现实推荐系统中任务关联的复杂性和竞争性
性能退化(Performance Degeneration):模型在实际应用中表现不如预期的现象。
负迁移(Negative Transfer):多任务学习中,某些任务间的相互干扰导致模型整体性能下降的现象。
任务关联(Task Correlation):不同任务之间的依赖或冲突关系,可能促进或阻碍模型学习。
“跷跷板”现象的发现:提升某一任务性能时,往往会损害其他某些任务的性能。
本文的意义
提出了一种具有创新共享结构设计的渐进式分层提取(PLE)模型。
该模型显式分离共享组件与任务特定组件,并采用渐进式路由机制逐步提取和分离更深层次的语义知识,从而提升联合表示学习效率以及通用场景下跨任务信息路由的效果。
应用场景与实验结果
在腾讯视频推荐数据集的十亿级样本上,PLE被应用于复杂关联任务和常规关联任务,涵盖双任务到多任务场景。实验结果表明,在不同任务相关性和任务组规模下,PLE显著优于当前最先进的多任务学习(MTL)模型。
线上效果与扩展验证
在腾讯大规模内容推荐平台上的在线评估显示,PLE相比现有最优MTL模型实现了2.23%的观看量提升和1.84%的观看时长增长,这一显著改进验证了其有效性。此外,在公开基准数据集上的大量离线实验证明,PLE可适配推荐系统之外的多种场景,有效消除"跷跷板效应"。
三、论文核心讲解
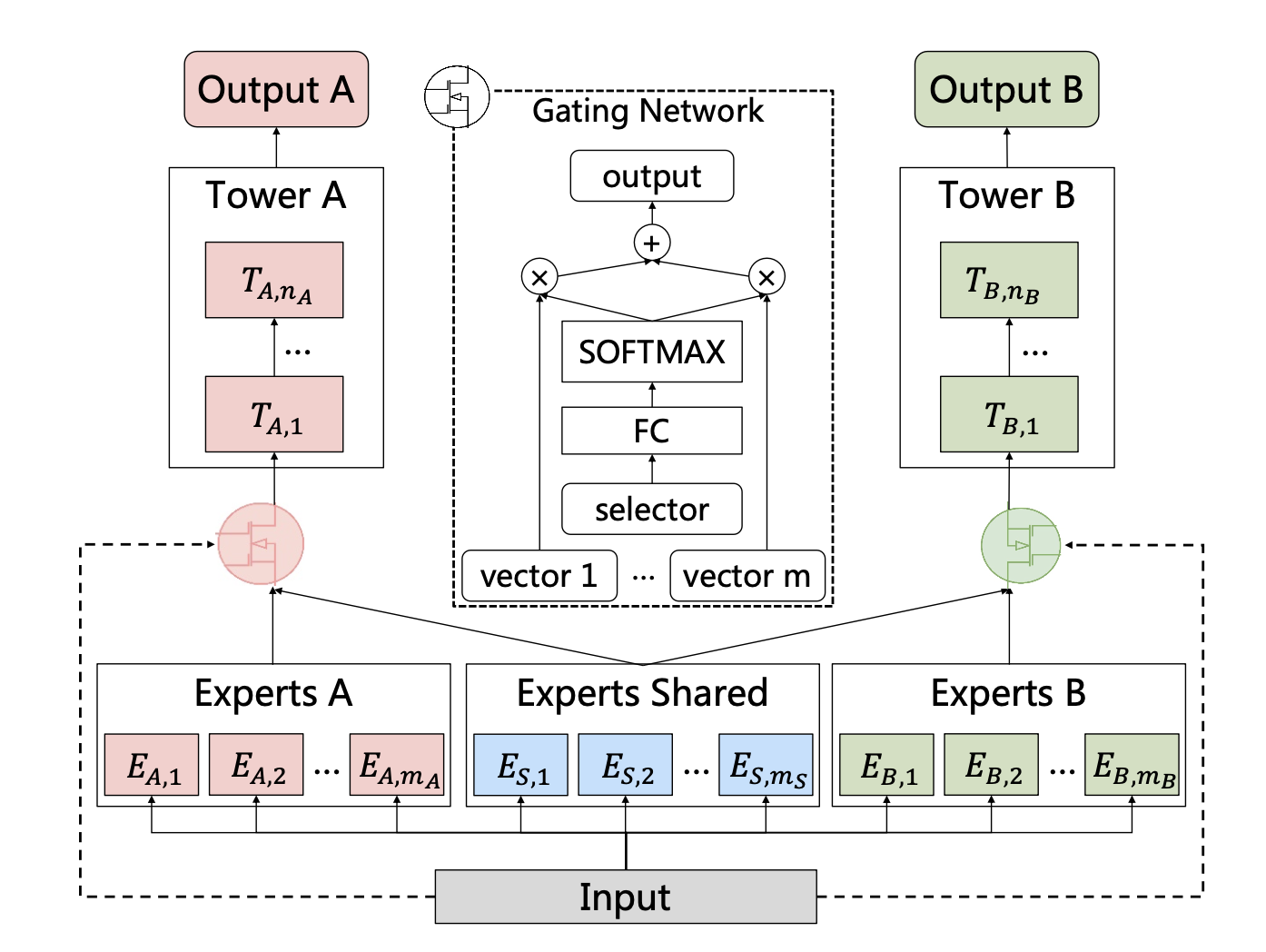
CGC(Customized Gate Control)模型结构讲解
结构有三部分
输入->中间的专家网络->顶部的任务特定的塔式网络
专家网络
共享专家负责学习跨任务的通用模式
任务特定专家提取与单一任务相关的独特模式
共享专家参数受所有任务影响,而任务特定专家参数仅受对应任务影响
塔式网络
每个塔式网络同时接收来自共享专家和自身任务特定专家的知识
门控网络
共享专家和任务特定专家通过门控网络进行选择性融合,如上图所示,门控网络的结构基于单层前馈网络,采用SoftMax作为激活函数,输入作为选择器计算选定向量(即专家输出的加权和)。
任务k的门控网络输出可表述为:
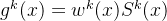 其中x 为输入表征,
其中x 为输入表征,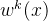 为权重函数,通过线性变换和 SoftMax 层计算任务 k 的权重向量。
为权重函数,通过线性变换和 SoftMax 层计算任务 k 的权重向量。
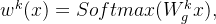 其中
其中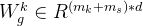 ,是一个参数矩阵
,是一个参数矩阵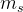 和
和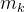 分别是共享专家和任务k的独有专家的专家个数;
分别是共享专家和任务k的独有专家的专家个数;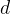 是输入表征的维度。
是输入表征的维度。
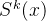 是一个挑选矩阵,由共享专家和任务k的独有专家构成。
是一个挑选矩阵,由共享专家和任务k的独有专家构成。
![S^k (x) = [E^T(k,1), E^T(k,2), . . . , E^T(k,m_k ), E^T(s,1), E^T(s,2), . . . , E^T(s,m_s )]^T](https://www.wsisp.com/helps/wp-content/uploads/2025/08/20250813153434-689cb08ae9a37.png) 最后任务k的预测就是
最后任务k的预测就是
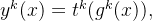
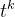 指的是任务k的tower层
指的是任务k的tower层
为什么要ple,cgc还不够吗?
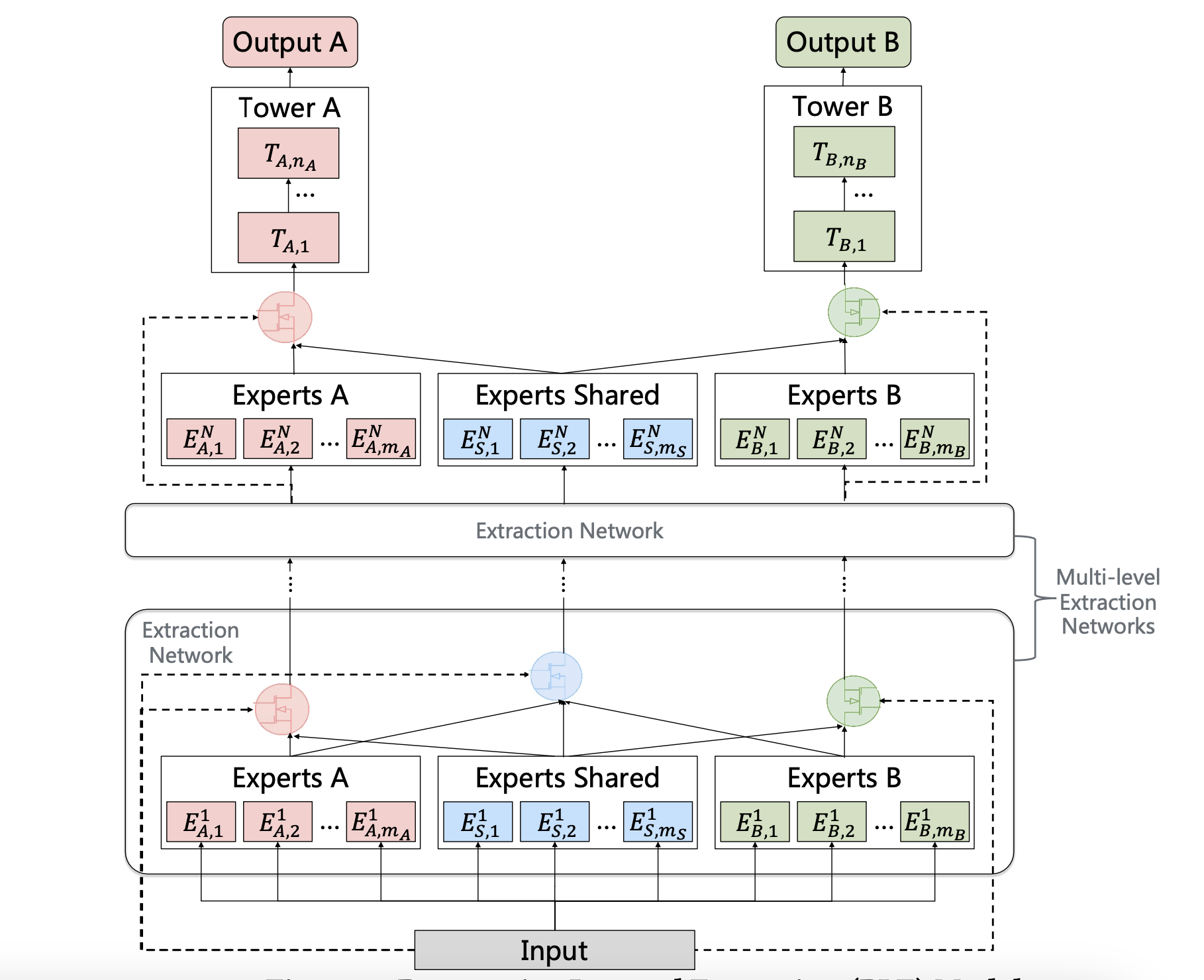
CGC显式分离任务特定组件和共享组件,但在深度多任务学习(MTL)中,模型需逐步构建更深层次的语义表征,而中间表征应归类为共享还是任务特定通常难以明确界定。为解决该问题,通过*渐进式分层提取(PLE)*对CGC进行扩展。
如上图所示,PLE包含多级提取网络,用于提取更高层次的共享信息。除任务特定专家门控机制外,提取网络还为共享专家设计门控网络,以整合当前层所有专家的知识。因此,PLE中不同任务的参数在底层并非如CGC般完全隔离,而是随层级上升逐步分离。
高层提取网络的门控机制以低层门控的融合结果(而非原始输入)作为选择依据,因其能更有效筛选高层专家提取的抽象知识。
权重函数、选择矩阵和门控网络的计算
在PLE(Progressive Layered Extraction)模型中,权重函数、选择矩阵和门控网络的计算方式与CGC(Customized Gate Control)模型一致。具体而言,PLE的第j个提取网络中,任务k的门控网络的计算公式如下:
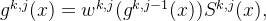 其中,
其中,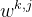 是任务 k 的加权函数,以
是任务 k 的加权函数,以 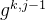 作为输入;
作为输入;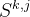 是任务 k 在第 j 个提取网络中的选择矩阵。
值得注意的一点是,PLE(渐进分层提取)模型中共享模块的选定矩阵与任务专用模块略有不同,因为该矩阵由当前层的所有共享专家和任务专用专家共同组成。
在计算完所有门控网络和专家模块后,最终可以得到PLE中任务k的预测结果。
是任务 k 在第 j 个提取网络中的选择矩阵。
值得注意的一点是,PLE(渐进分层提取)模型中共享模块的选定矩阵与任务专用模块略有不同,因为该矩阵由当前层的所有共享专家和任务专用专家共同组成。
在计算完所有门控网络和专家模块后,最终可以得到PLE中任务k的预测结果。
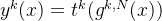
多专家与门控网络的渐进式分层提取
PLE(渐进式分层提取)通过多层次专家和门控网络,为每个任务提取并融合更深层的语义表征,从而提升泛化能力。如,MMOE采用全连接路由策略,CGC采用早期分离策略,而PLE则采用渐进式分离路由机制:吸收所有底层专家的信息,提取更高层次的共享知识,并逐步分离任务特定参数
渐进式分离的化学类比
渐进式分离过程类似于化学中从化合物逐步提取目标产物的流程。在PLE的知识提取与转化过程中,底层表征在高层共享专家层联合提取/聚合并路由,获取共享知识后逐步分发至特定任务塔层。这种方式实现了更高效、灵活的联合表征学习与共享。
路由策略的对比与收敛性
尽管MMOE的全连接路由看似是CGC和PLE的一般化设计,但实际研究表明(见论文第5.3节),MMOE无法收敛到CGC或PLE的结构,即便存在理论可能性。
多任务学习的联合损失优化
在设计了高效的网络结构后,当前重点转向以端到端方式联合训练任务特定层和共享层。多任务学习中,联合损失的常见形式是各任务损失的加权求和
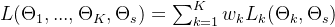 θs 表示共享参数,K 是任务数量,Lk、ωk 和 θk 分别表示任务 k 的损失函数、损失权重和任务特定参数。
然而,存在多个问题使得多任务学习(MTL)模型的联合优化在实际应用中具有挑战性。本文通过优化联合损失函数,解决了现实推荐系统中两个关键问题。
第一个问题是由用户连续行为导致的异质样本空间。例如,用户只有在点击某物品后才能分享或评论,这导致不同任务的样本空间不同)。为了联合训练这些任务,将所有任务的样本空间并集作为整体训练集,并在计算每个单独任务的损失时忽略其自身样本空间之外的样本。
θs 表示共享参数,K 是任务数量,Lk、ωk 和 θk 分别表示任务 k 的损失函数、损失权重和任务特定参数。
然而,存在多个问题使得多任务学习(MTL)模型的联合优化在实际应用中具有挑战性。本文通过优化联合损失函数,解决了现实推荐系统中两个关键问题。
第一个问题是由用户连续行为导致的异质样本空间。例如,用户只有在点击某物品后才能分享或评论,这导致不同任务的样本空间不同)。为了联合训练这些任务,将所有任务的样本空间并集作为整体训练集,并在计算每个单独任务的损失时忽略其自身样本空间之外的样本。
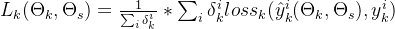
 是任务k的损失,基于预测值
是任务k的损失,基于预测值  与真实值
与真实值  计算得出;
计算得出; ∈{0,1} 表示样本i是否属于任务k的样本空间。
第二个问题是,多任务学习(MTL)模型的表现对训练过程中损失权重的选择非常敏感,因为这些权重决定了各任务在联合损失中的相对重要性。实际观察发现,不同任务在不同训练阶段的重要性可能动态变化。因此,将每个任务的损失权重视为动态值而非静态值更为合理。具体实现中,先为任务k设定初始损失权重ωk,0,随后根据更新比率γk在每一步训练后调整权重。
∈{0,1} 表示样本i是否属于任务k的样本空间。
第二个问题是,多任务学习(MTL)模型的表现对训练过程中损失权重的选择非常敏感,因为这些权重决定了各任务在联合损失中的相对重要性。实际观察发现,不同任务在不同训练阶段的重要性可能动态变化。因此,将每个任务的损失权重视为动态值而非静态值更为合理。具体实现中,先为任务k设定初始损失权重ωk,0,随后根据更新比率γk在每一步训练后调整权重。
 t 指的是训练的epoch,
t 指的是训练的epoch, 和
和 是模型的超参。
是模型的超参。
四、总结
内容到这里就暂告一段落了,ple的核心理论部分应该都已经进行阐述,后续的实验环节大家感兴趣的可以去查看论文,欢迎👏大家有问题评论区进行交流。~后续多任务还会持续分享,论文也会继续分享~
 网硕互联帮助中心
网硕互联帮助中心








评论前必须登录!
注册