 网硕互联帮助中心
网硕互联帮助中心深度强化学习全栈指南:从理论原理到机器人实战
摘要:本文系统梳理强化学习(Reinforcement Learning, RL)的理论框架与技术体系,深入剖析其与监督学习、无监督学习的本质差异,重点讲解基于人类反馈的强化学习(RLHF)在GPT等大模型训练中的应用,并通过具身智能(Embodied AI)与机器人控制实战案例,展示RL在真实场景中的落地路径。最后提供完整的代码实现框架与开源资源导航,助力开发者快速入门强化学习工程实践。
关键词:强化学习;RLHF;具身智能;机器人控制;Stable Baselines;Gym
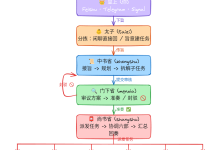
一、强化学习基本概念与核心框架
1.1 定义:智能体的序贯决策过程
强化学习(Reinforcement Learning, RL) 是机器学习的重要范式,其核心在于训练智能体(Agent) 在复杂不确定环境(Environment) 中,通过试错学习(Trial-and-Error) 最大化长期累积奖励(Cumulative Reward)。
与监督学习的"开卷考试"模式不同,强化学习更接近探索-利用困境(Exploration-Exploitation Dilemma):智能体需要在尝试新策略(探索)与执行已知最优策略(利用)之间取得平衡,以获取最大长期收益。
数学形式化(马尔可夫决策过程,MDP):
M
=
(
S
,
A
,
P
,
R
,
γ
)
\\mathcal{M} = (\\mathcal{S}, \\mathcal{A}, \\mathcal{P}, \\mathcal{R}, \\gamma)
M=(S,A,P,R,γ)
其中:
-
S
\\mathcal{S}
S:状态空间(State Space) -
A
\\mathcal{A}
A:动作空间(Action Space) -
P
(
s
′
∣
s
,
a
)
\\mathcal{P}(s'|s,a)
P(s′∣s,a):状态转移概率 -
R
(
s
,
a
)
\\mathcal{R}(s,a)
R(s,a):即时奖励函数 -
γ
∈
[
0
,
1
]
\\gamma \\in [0,1]
γ∈[0,1]:折扣因子(平衡即时与长期奖励)
1.2 关键组件解析
| 策略(Policy) |
π ( a ∣ s ) \\pi(a|s) π(a∣s):状态到动作的映射 |
随机策略(Softmax)vs 确定性策略(Argmax) |
| 价值函数(Value Function) |
V π ( s ) V^\\pi(s) Vπ(s):状态长期价值评估 |
蒙特卡洛估计 vs 时序差分(TD)学习 |
| Q函数(Action-Value) |
Q π ( s , a ) Q^\\pi(s,a) Qπ(s,a):状态-动作对价值 |
DQN、Double DQN、Dueling DQN架构 |
| 模型(Model) | 环境动态的学习表示 | Model-Based RL(如MuZero)vs Model-Free RL |
二、三大学习范式对比:强化学习的独特定位
理解强化学习在机器学习版图中的位置,是掌握其应用场景的前提。
2.1 监督学习(Supervised Learning)
核心特征:有标签反馈,预测未来
- 数据流:
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi) 输入-输出对 - 目标:学习映射函数
f
:
X
→
Y
f: \\mathcal{X} \\to \\mathcal{Y}
f:X→Y 最小化预测误差 - 典型任务:图像分类(如猫狗识别)、情感分析、语音识别
- 局限性:依赖大量标注数据,难以处理动态交互场景
类比:如同学生通过标准答案(标签)学习,适合有明确"正确答案"的任务。
2.2 无监督学习(Unsupervised Learning)
核心特征:挖掘数据中的隐藏结构,无直接反馈
- 数据流:仅含输入
{
x
i
}
\\{x_i\\}
{xi},无标签 - 目标:发现数据内在分布规律(聚类、降维、密度估计)
- 典型任务:客户分群、异常检测、特征学习
- 局限性:缺乏明确优化目标,评估困难
类比:如同学生自主整理笔记,发现知识点间的关联,但无明确对错标准。
2.3 强化学习(Reinforcement Learning)
核心特征:基于奖励机制,采取行动序列以优化长期结果
- 数据流:
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_t, a_t, r_t, s_{t+1})
(st,at,rt,st+1) 状态-动作-奖励-下一状态序列 - 目标:最大化累积奖励
E
[
∑
t
=
0
∞
γ
t
r
t
]
\\mathbb{E}[\\sum_{t=0}^{\\infty} \\gamma^t r_t]
E[∑t=0∞γtrt] - 关键差异:
- 时序依赖性:当前动作影响未来状态(非独立同分布)
- 延迟反馈:奖励可能滞后多个时间步(Credit Assignment问题)
- 主动探索:智能体通过行为影响数据分布
类比:如同婴儿学走路,通过跌倒(负奖励)和站稳(正奖励)的反馈,逐步优化动作策略。
2.4 范式对比总结
┌─────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ 维度 │ 监督学习 │ 无监督学习 │ 强化学习 │
├─────────────────┼──────────────────┼──────────────────┼──────────────────┤
│ 数据形式 │ (输入, 标签) │ 仅输入数据 │ (状态, 动作, 奖励)序列 │
│ 反馈类型 │ 即时、明确 │ 无直接反馈 │ 延迟、稀疏 │
│ 决策性质 │ 单步预测 │ 模式发现 │ 序贯决策 │
│ 环境交互 │ 无 │ 无 │ 主动、动态 │
│ 典型应用 │ 图像分类 │ 聚类分析 │ 游戏AI、机器人 │
└─────────────────┴──────────────────┴──────────────────┴──────────────────┘
三、基于人类反馈的强化学习(RLHF):大模型对齐的关键技术
3.1 RLHF技术背景与流程
RLHF(Reinforcement Learning from Human Feedback) 是将强化学习应用于大语言模型(LLM)对齐的核心技术,被广泛应用于GPT系列、ChatGPT、Claude等模型的训练后期阶段。
标准三阶段流程:
阶段一:监督微调(SFT, Supervised Fine-Tuning)
- 使用高质量人工标注数据对预训练模型进行初步行为塑造
- 让模型学习基本的指令遵循能力和对话格式
阶段二:奖励模型训练(Reward Model Training)
- 收集人类偏好数据:对同一提示的多个输出进行成对比较(Pairwise Comparison)
- 训练奖励模型
r
θ
(
x
,
y
)
r_\\theta(x,y)
rθ(x,y) 预测人类偏好分数 - 损失函数(Bradley-Terry模型):
L
R
M
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
σ
(
r
θ
(
x
,
y
w
)
−
r
θ
(
x
,
y
l
)
)
]
\\mathcal{L}_{RM} = -\\mathbb{E}_{(x,y_w,y_l)\\sim \\mathcal{D}} \\left[ \\log \\sigma \\left( r_\\theta(x,y_w) – r_\\theta(x,y_l) \\right) \\right]
LRM=−E(x,yw,yl)∼D[logσ(rθ(x,yw)−rθ(x,yl))]
其中
y
w
y_w
yw 为人类偏好的"胜"输出,
y
l
y_l
yl 为"负"输出。
阶段三:强化学习优化(PPO优化)
- 使用近端策略优化(Proximal Policy Optimization, PPO) 算法微调策略
- 目标函数包含奖励最大化与KL散度约束(防止模型偏离太远):
L
P
P
O
=
E
[
min
(
π
θ
(
a
∣
s
)
π
θ
o
l
d
(
a
∣
s
)
A
t
,
clip
(
⋅
,
1
−
ϵ
,
1
+
ϵ
)
A
t
)
]
\\mathcal{L}_{PPO} = \\mathbb{E} \\left[ \\min \\left( \\frac{\\pi_\\theta(a|s)}{\\pi_{\\theta_{old}}(a|s)} A_t, \\text{clip}(\\cdot, 1-\\epsilon, 1+\\epsilon) A_t \\right) \\right]
LPPO=E[min(πθold(a∣s)πθ(a∣s)At,clip(⋅,1−ϵ,1+ϵ)At)]
3.2 RLHF在GPT模型训练中的实践意义
| 有用性(Helpfulness) | 高奖励分配给详细、准确回答 | 提升回答质量与信息密度 |
| 无害性(Harmlessness) | 惩罚有害、偏见、危险内容 | 降低模型输出风险 |
| 诚实性(Honesty) | 奖励承认不确定性 | 减少幻觉(Hallucination) |
> 工程洞察:RLHF的成功关键在于奖励模型的质量。若奖励模型存在偏见,强化学习会放大这种偏见(Reward Hacking),因此需要迭代优化奖励模型与策略的协同训练。
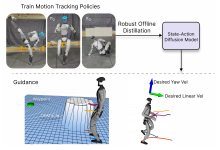
四、具身智能与机器人应用:RL的物理世界落地
4.1 具身智能(Embodied AI)的技术内涵
具身智能强调智能体通过物理身体与环境的实时交互获得智能,是强化学习最具挑战也最具前景的应用领域。与纯软件AI不同,具身智能面临:
- 部分可观测性(Partial Observability):传感器噪声与视野限制
- 高维连续动作空间:机械臂关节控制、底盘速度调节
- 样本效率危机:真实环境交互成本极高
4.2 核心应用场景与技术方案
4.2.1 机器人运动控制与环境感知
- 挑战:平衡动态稳定性、能耗优化与任务完成度
- 方案:
- 分层强化学习(Hierarchical RL):高层策略规划路径,低层策略控制执行
- Sim-to-Real迁移:在仿真环境(MuJoCo、Isaac Gym)训练,通过域随机化(Domain Randomization) 提升真实场景泛化性
4.2.2 视觉识别与物体抓取
- 挑战:光照变化、物体形状多样性、遮挡处理
- 方案:
- 视觉-动作联合学习:CNN提取视觉特征,融合到策略网络
- 抓取姿态检测(Grasp Pose Detection):结合6D位姿估计与RL优化抓取策略
4.2.3 虚拟仿真平台训练
主流仿真平台对比:
| Gym/Gymnasium | 多种 | OpenAI标准接口,生态丰富 | 算法验证、入门学习 |
| MuJoCo | MuJoCo | 高精度接触物理,轻量级 | 灵巧操作、步态控制 |
| Isaac Gym | PhysX | GPU并行加速,大规模场景 | 并行训练、Sim-to-Real |
| PyBullet | Bullet | 开源免费,易部署 | 快速原型、教育演示 |
4.2.4 工业自动化与生产
- 应用:柔性制造中的装配顺序优化、AGV路径规划、质量检测策略
- 价值:适应小批量多品种生产,替代硬编码规则,提升产线柔性
五、强化学习案例分析:从仿真到真实机器人
5.1 案例一:夹爪机器人抓取(Gripper Grasping)
任务定义
训练机械臂夹爪在杂乱场景中抓取目标物体并放置到指定位置。
状态空间(State Space)设计
- 视觉输入:RGB-D相机图像(
224
×
224
×
4
224 \\times 224 \\times 4
224×224×4) - 本体感知:夹爪开合角度、指尖力矩传感器读数
- 任务状态:目标物体位姿(若可获取)、放置区域位置
动作空间(Action Space)设计
- 位置控制:末端执行器在XYZ坐标系的位移增量
(
Δ
x
,
Δ
y
,
Δ
z
)
(\\Delta x, \\Delta y, \\Delta z)
(Δx,Δy,Δz) - 姿态控制:夹爪绕Z轴旋转角度
Δ
θ
\\Delta \\theta
Δθ - 夹爪控制:开合指令(离散或连续值)
a
t
=
[
Δ
x
,
Δ
y
,
Δ
z
,
Δ
θ
,
gripper_cmd
]
∈
R
5
\\mathbf{a}_t = [\\Delta x, \\Delta y, \\Delta z, \\Delta \\theta, \\text{gripper\\_cmd}] \\in \\mathbb{R}^5
at=[Δx,Δy,Δz,Δθ,gripper_cmd]∈R5
奖励函数(Reward Shaping)设计
采用稀疏奖励与密集奖励结合策略:
r
t
=
r
sparse
+
r
dense
r_t = r_{\\text{sparse}} + r_{\\text{dense}}
rt=rsparse+rdense
-
稀疏奖励:
-
+
10
+10
+10:成功抓取并放置 -
−
5
-5
−5:掉落或碰撞
-
-
密集奖励(引导学习):
- 接近目标:
−
λ
1
⋅
distance
(
gripper
,
object
)
– \\lambda_1 \\cdot \\text{distance}(\\text{gripper}, \\text{object})
−λ1⋅distance(gripper,object) - 对齐姿态:
−
λ
2
⋅
orientation_error
– \\lambda_2 \\cdot \\text{orientation\\_error}
−λ2⋅orientation_error - 保持抓取:
+
λ
3
⋅
grip_force
+ \\lambda_3 \\cdot \\text{grip\\_force}
+λ3⋅grip_force(当接触物体时)
- 接近目标:
5.2 案例二:机器人底盘控制(Mobile Robot Navigation)
任务定义
轮式机器人在动态环境中自主导航至目标点,同时避障并满足运动学约束。
状态空间
- 激光雷达:360度距离扫描(
L
=
{
d
1
,
d
2
,
.
.
.
,
d
360
}
L = \\{d_1, d_2, …, d_{360}\\}
L={d1,d2,…,d360}) - 里程计:当前位置
(
x
,
y
)
(x,y)
(x,y)、朝向θ
\\theta
θ、线速度v
v
v、角速度ω
\\omega
ω - 目标信息:相对目标点的距离与方位角
动作空间
- 线速度:
v
∈
[
0
,
v
m
a
x
]
v \\in [0, v_{max}]
v∈[0,vmax](前进速度) - 角速度:
ω
∈
[
−
ω
m
a
x
,
ω
m
a
x
]
\\omega \\in [-\\omega_{max}, \\omega_{max}]
ω∈[−ωmax,ωmax](转向速度)
a
t
=
[
v
,
ω
]
∈
R
2
\\mathbf{a}_t = [v, \\omega] \\in \\mathbb{R}^2
at=[v,ω]∈R2
奖励与惩罚机制
| 到达目标 |
+ 100 +100 +100 |
任务完成激励 |
| 碰撞 |
− 50 -50 −50 |
安全约束 |
| 超时 |
− 20 -20 −20 |
效率约束 |
| 接近目标 |
+ Δ d t a r g e t + \\Delta d_{target} +Δdtarget |
进度引导 |
| 超速 |
− α ⋅ ( v − v l i m i t ) 2 – \\alpha \\cdot (v – v_{limit})^2 −α⋅(v−vlimit)2 |
运动学约束 |
| 靠近障碍物 |
− β ⋅ 1 d o b s t a c l e – \\beta \\cdot \\frac{1}{d_{obstacle}} −β⋅dobstacle1 |
避障引导 |
六、强化学习的代码实现与开源资源
6.1 核心工具库:Stable Baselines3 + Gymnasium
Gymnasium(原OpenAI Gym) 提供标准化的环境接口(Env API),是RL算法的通用测试平台。
# 环境接口标准
import gymnasium as gym
env = gym.make('CartPole-v1')
observation, info = env.reset(seed=42)
for _ in range(1000):
action = env.action_space.sample() # 随机策略
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()
- 关键概念:
- reset():初始化环境,返回初始状态
- step(action):执行动作,返回 (next_state, reward, done, info)
- action_space / observation_space:动作与状态的边界定义(Box、Discrete等)
- Stable Baselines3(SB3) 基于PyTorch的高质量RL算法实现库,提供模块化、可扩展的算法组件。
- 支持算法:
| DQN | Value-Based | 经验回放、目标网络 | 离散动作、Atari游戏 |
| A2C/A3C | Actor-Critic | 同步/异步并行训练 | 简单连续控制 |
| PPO | On-Policy AC | 裁剪目标、稳定高效 | 通用首选,推荐入门 |
| SAC | Off-Policy AC | 最大熵、自动温度调节 | 连续控制、样本高效 |
| TD3 | Off-Policy AC | 双Q网络、延迟策略更新 | 连续控制、解决过估计 |
| DDPG | Off-Policy AC | 确定性策略梯度 | 连续控制(已被SAC/TD3超越) |
6.2 实战代码框架
- 示例:倒立摆控制(CartPole)与PPO训练
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
# 1. 创建环境
env = gym.make('CartPole-v1')
# 2. 初始化PPO模型
# MlpPolicy:多层感知机策略网络
# verbose=1:打印训练日志
model = PPO(
"MlpPolicy",
env,
verbose=1,
learning_rate=3e-4,
n_steps=2048,
batch_size=64,
n_epochs=10,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
tensorboard_log="./ppo_cartpole_tensorboard/"
)
# 3. 训练模型
# total_timesteps:总交互步数
model.learn(total_timesteps=100000)
# 4. 保存模型
model.save("ppo_cartpole")
# 5. 评估性能
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10)
print(f"Mean reward: {mean_reward:.2f} +/- {std_reward:.2f}")
# 6. 部署推理
obs, info = env.reset()
for _ in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
env.render()
if terminated or truncated:
obs, info = env.reset()
- 示例:自定义机器人环境(Gymnasium接口)
import gymnasium as gym
from gymnasium import spaces
import numpy as np
class RobotGraspEnv(gym.Env):
"""自定义夹爪抓取环境示例"""
metadata = {'render_modes': ['human']}
def __init__(self, render_mode=None):
super().__init__()
# 定义状态空间:机械臂关节角度(6) + 夹爪位置(1) + 目标位置(3)
self.observation_space = spaces.Box(
low=–np.inf, high=np.inf, shape=(10,), dtype=np.float32
)
# 定义动作空间:关节速度(6) + 夹爪开合(1)
self.action_space = spaces.Box(
low=–1.0, high=1.0, shape=(7,), dtype=np.float32
)
self.render_mode = render_mode
self.max_steps = 100
self.current_step = 0
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.current_step = 0
# 初始化随机状态
self.state = self.np_random.uniform(–0.5, 0.5, size=10)
self.target_pos = self.np_random.uniform(–0.3, 0.3, size=3)
info = {}
return self.state, info
def step(self, action):
# 模拟环境动态(实际应调用物理引擎如PyBullet/MuJoCo)
self.state[:7] += action * 0.1 # 简化的运动学更新
self.current_step += 1
# 计算奖励
gripper_pos = self.state[7:10]
distance = np.linalg.norm(gripper_pos – self.target_pos)
reward = –distance # 距离惩罚
# 成功抓取判断(简化)
terminated = distance < 0.05
truncated = self.current_step >= self.max_steps
if terminated:
reward += 10.0 # 成功奖励
info = {'distance': distance}
return self.state, reward, terminated, truncated, info
def render(self):
if self.render_mode == "human":
print(f"Step: {self.current_step}, Distance: {np.linalg.norm(self.state[7:10] – self.target_pos):.3f}")
def close(self):
pass
# 注册并使用环境
gym.register(id='RobotGrasp-v0', entry_point='__main__:RobotGraspEnv')
env = gym.make('RobotGrasp-v0')
6.3 开源资源导航
经典入门项目
| Stable Baselines3 | https://github.com/DLR-RM/stable-baselines3 | 最推荐的RL算法库 |
| Gymnasium | https://github.com/Farama-Foundation/Gymnasium | 标准环境接口 |
| CleanRL | https://github.com/vwxyzjn/cleanrl | 单文件算法实现,适合学习 |
| RL Baselines3 Zoo | https://github.com/DLR-RM/rl-baselines3-zoo | 预训练模型与调优指南 |
开源书籍与教程
- 《Reinforcement Learning: An Introduction》(Sutton & Barto):RL圣经,免费电子版
- Spinning Up in Deep RL(OpenAI):深度RL教育项目,含理论+代码
- 动手学强化学习(李航等):中文实践教程,含PyTorch实现
在线课程
- CS285: Deep Reinforcement Learning(UC Berkeley, Sergey Levine)
- Reinforcement Learning Specialization(Coursera, University of Alberta)
- 李宏毅机器学习课程:含RL专题,中文讲解清晰 前沿研究方向
- Offline RL:从固定数据集学习,避免在线交互风险
- Multi-Agent RL:多智能体协作与竞争
- Meta-RL:学会学习,快速适应新任务
- Safe RL:安全约束下的策略优化
七、结论与展望
7.1 技术总结
- 强化学习作为面向序贯决策的机器学习范式,在以下领域展现出巨大潜力:
- 游戏AI:AlphaGo、AlphaStar、OpenAI Five等突破人类顶尖水平
- 机器人控制:从仿真到真实环境的技能迁移日趋成熟
- 自动驾驶:决策规划模块的端到端优化
- 大模型对齐:RLHF成为构建安全、有用AI的关键技术
- 资源调度:数据中心冷却、芯片设计(Google TPU布局)、交通信号控制
7.2 工程实践建议
- 从仿真开始:利用Gymnasium和PyBullet快速验证算法,再迁移到真实硬件
- 重视奖励设计:奖励函数是RL的"编程语言",需精心设计避免奖励黑客(Reward Hacking)
- 关注样本效率:优先选择SAC、TD3等Off-Policy算法,结合经验回放提升数据利用率
- Sim-to-Real技巧:域随机化、系统辨识、残差策略学习缩小仿真与现实差距
- 安全优先:真实机器人部署前必须进行充分的安全边界测试
7.3 未来趋势
- 世界模型(World Models):学习环境的动态预测模型,提升规划能力
- Transformer与RL融合:Decision Transformer等序列建模方法重新定义RL范式
- 具身智能爆发:多模态大模型+机器人硬件的协同进化
- 自动化RL(AutoRL):超参数优化、网络架构搜索、奖励学习自动化
本文仅供交流学习参考,请勿用于商业用途。





评论前必须登录!
注册