 网硕互联帮助中心
网硕互联帮助中心本文作者:kaiyuan 大模型推理必学:专业术语与概念引导(上) 大模型推理必学:专业术语与概念引导(下)
本文总结了LLM推理相关的一些基础知识,包括经常用到的专业术语(缩写、名词)、关键特性、引擎参数等,帮助读者对该方向有个初步了解。
1 关键特性

- Continus-batching:持续地往GPU中送入请求数据,而不是离散的进行数据推理。一个请求结束立刻下发新的请求,保证GPU利用率,参考[1]。
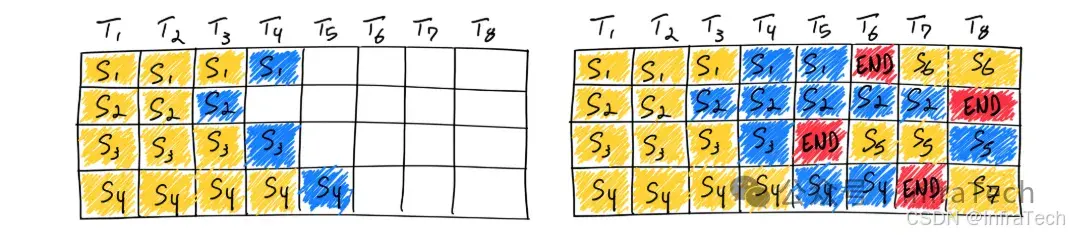
静态vs持续 batching的对比

continuous batching
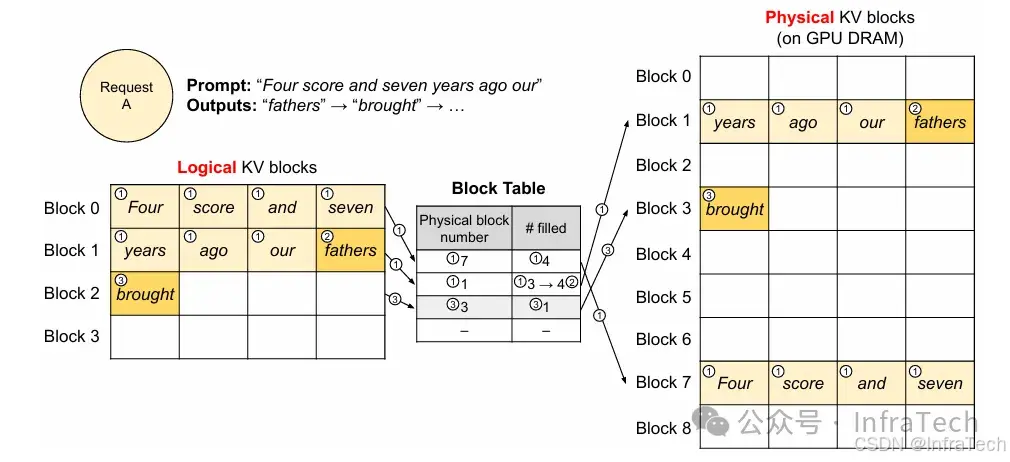
- Paged Attention:分页注意力机制。将Attention运算中的KV值按照虚拟映射的方式管理起来,可降低内存碎片化,参考[2]。
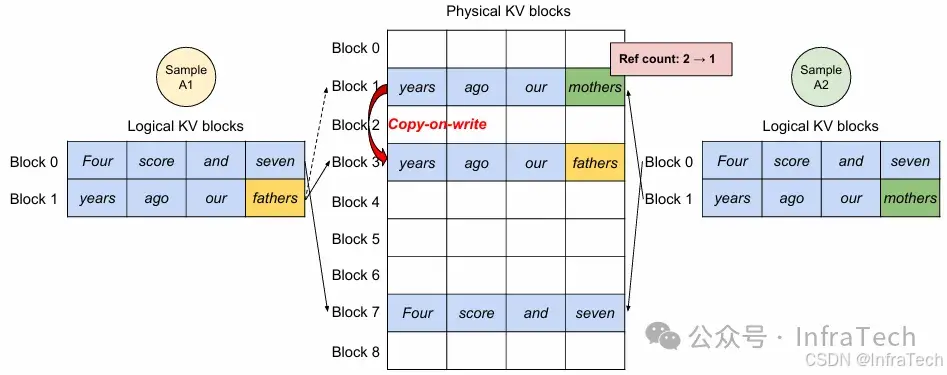
- Copy-on-write:写时复制。多个请求复用一个未使用完的block前缀,当请求写入数据不同时才为该请求复制数据到一个新的block中。
- Radix Attetnion:用基数树数据结构构建attention的KV cache管理。用键值缓存张量以非连续的分页布局存储,其中每页的大小等同于一个token。参考[3]。
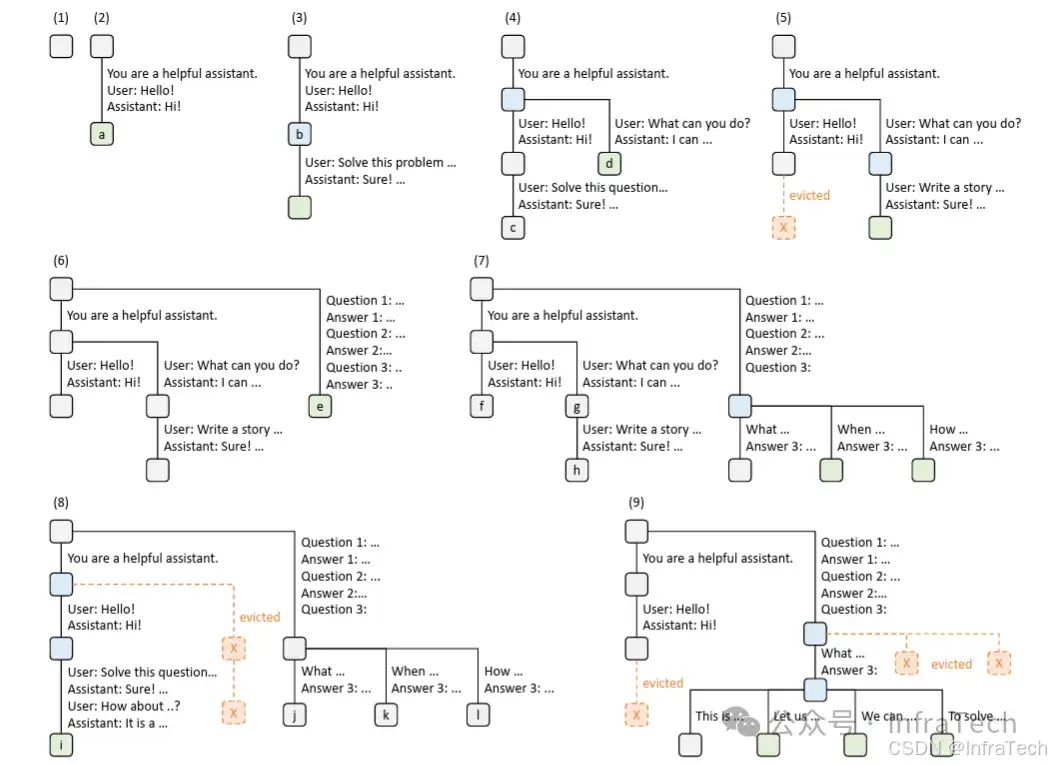
采用LRU策略的基数树示例
-
PD Disaggregation:PD分离部署。模型计算过程拆成两步:P(prefill,算力密集)、D(decode,存储密集),将P和D拆分部署提升GPU利用率。参考[4]。
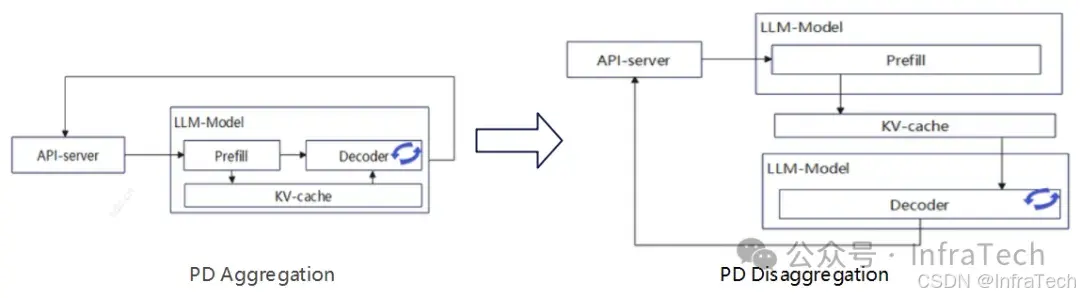
-
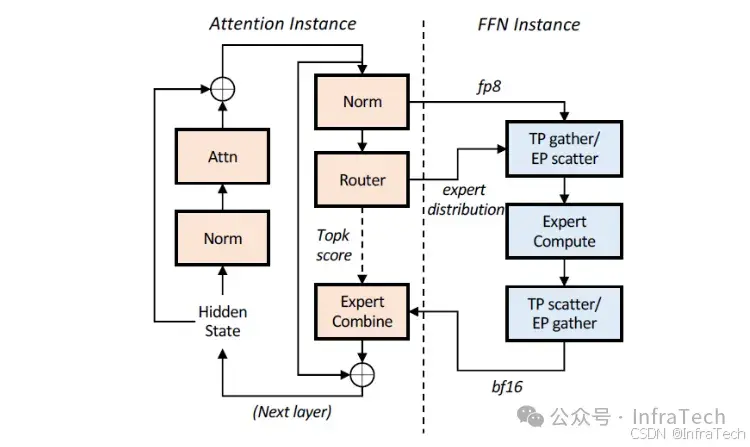
AFD(Attention-FFN Disaggregation):Attention与FFN分离。将Attention与FFN子模块分别部署到不同设备上,通过调整不同的A与F配比可实现较高推理性能。参考[5]。
-
APC(Auto Prefix Cache):自动前缀缓存,复用历史的KV cache信息,降低prefill阶段的计算量从而提升首token性能。参考[6]。
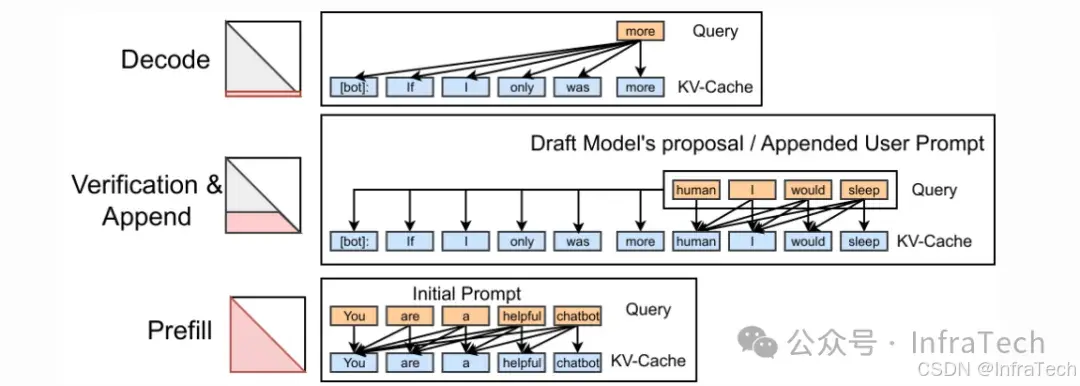
Speculative Decoding:投机推理/推测解码。用草稿模型生成数据,然后用参数量较大的模型进行结果验证/生成。参考<LLM提速利器:投机推理的原理与常见方案>。 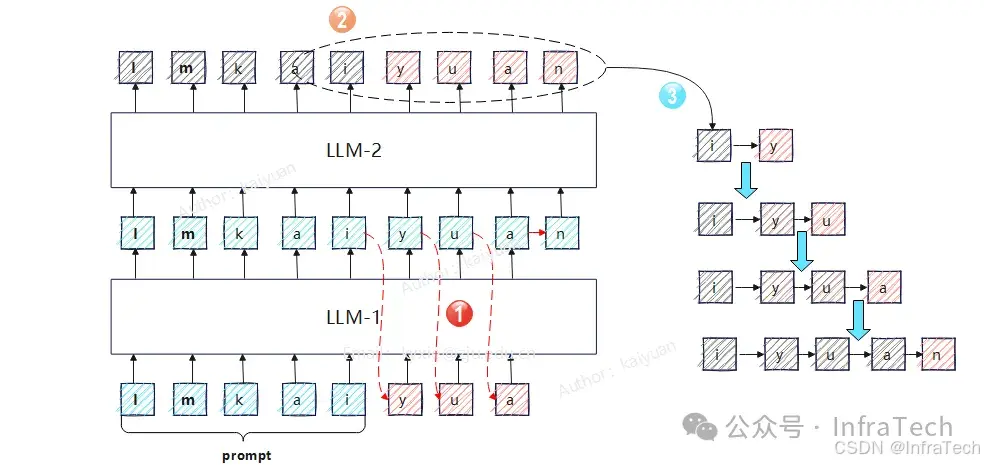
LLM-1负责输出、LLM-2负责校验
Chunked Prefill: 分块预填充,分块预填充允许将大的prefill分块成更小的块(切分序列长度),并将它们与解码请求一起批处理。参考1[7],2[8]。
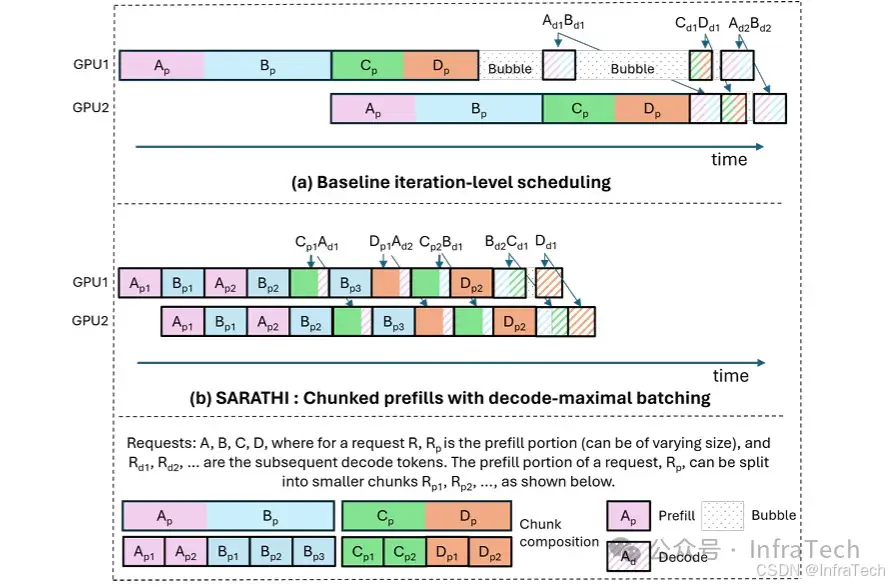
Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
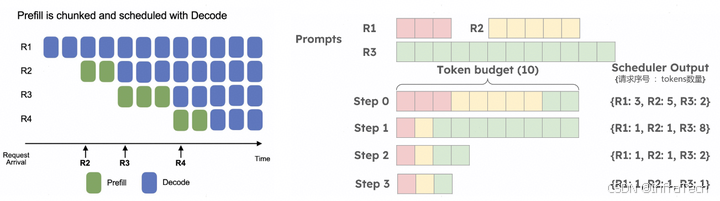
Chunked prefill 在vLLM推理框架中的应用
- W8A16:一种量化的格式,W8表示权重(Weight)使用 8 位整数(INT8)进行量化,A16:表示激活值(Activation)保留较高的精度,通常使用 16位浮点数(FP16)或者混合精度。与之类似还有W8A8,W4A16等,后面可跟参数类型,如w8a8_int8。参考1[9],2[10]。
- Multi-Lora(Low-Rank Adaptation):多LoRA适配器共用基础模型,在拥有一个基础预训练模型与针对不同任务分别微调的多个特定LoRA适配器的情况下,多LoRA服务机制能根据传入请求动态选择所需的LoRA模块。参考Lora[11],Multi-LoRA[12]。
- Guided Decoder:引导解码器。约束模型输出,使其严格遵循预定义的格式或语法规则(如 JSON、SQL、正则表达式等),从而生成结构化、可控的文本输出。
- Function Call/Tool Call:工具调用。利用LLM的引导解码输出支持函数调用所需参数格式,使得LLM能够调用工具,参考1[13],2[14]。
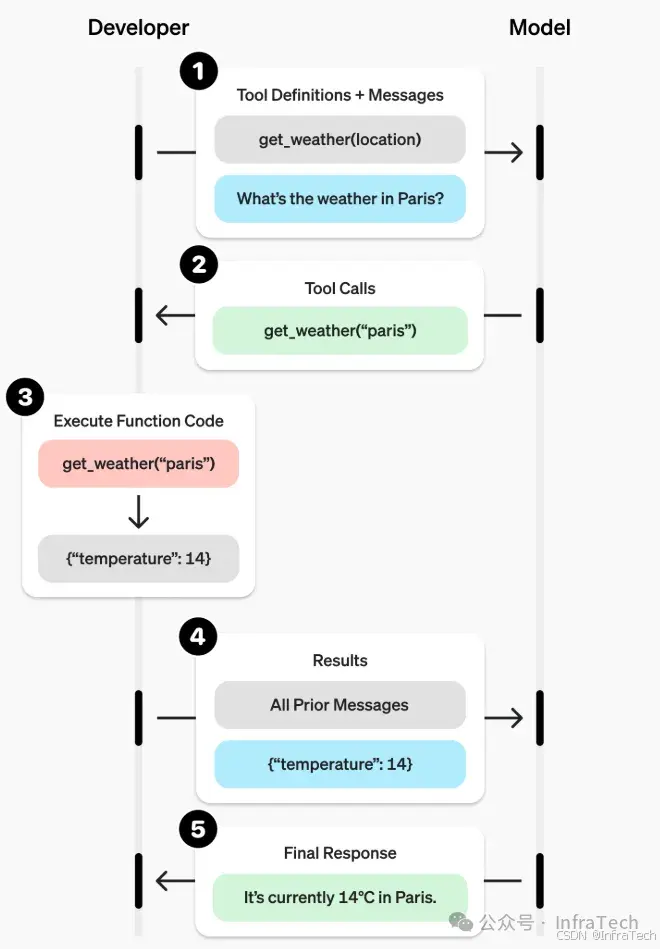
函数调用的示例
- DP/SP/TP/PP: 推理并行的常见方式,包括,数据并行(DP)、序列并行(SP)、张量并行(TP)、层并行(PP),参考[15]。

一般切batch为DP、切序列为SP、切隐藏层尺寸为TP。
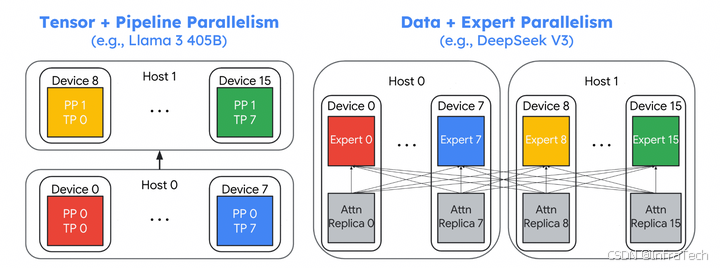
混合并行的示意图
- TBO/DBO(Two Batch Overlap/Dual Batch Overlap): 请求拆分为微批次,将注意力计算与分发(dispatch)/组合(combine)操作交错进行,计算流和通信流交错执行,提升算力利用率。参考1[16],21[17]。
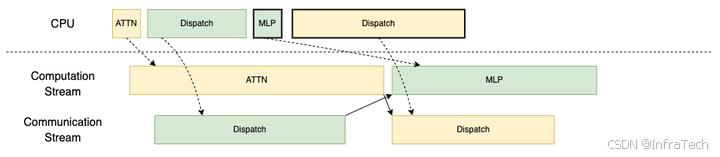
TBO下发示意图
- FA(FlashAttention): 一种加速Attention运算的算法,主要是两个版本FA1、FA2。FA1[18]使用online softmax技巧,将自注意力中多个操作步骤融合为单个算子,降低了从全局内存(HBM)中读/存注意力矩阵的开销。FA2[19] , 进一步优化性能,采用更合理的分块策略并减少非张量运算操作数量,以缓解NVIDIA A/H架构中非张量计算核心性能偏低的问题。
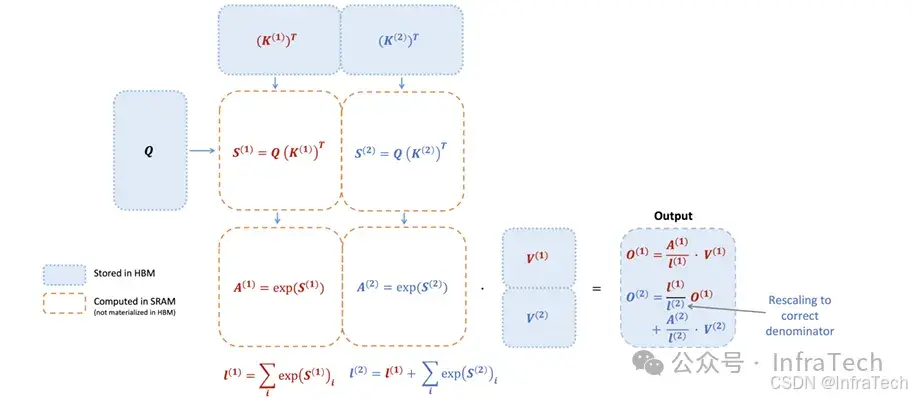
FA2
Flash-Decoding: 针对长序列推理解码的Attention计算方式,参考[20]。
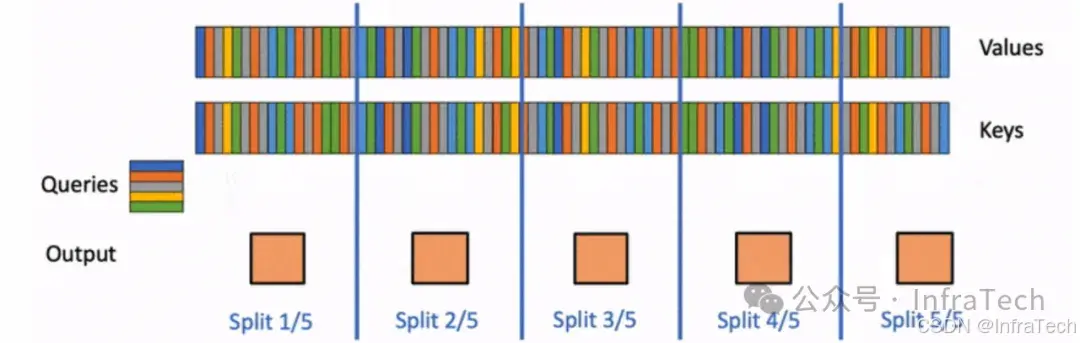
长序列分块运算
- FIA(Flash Infer Attention):在LLM框架中使用的一种推理库,针对推理的不同阶段(prefill/append/decode)实现了性能更优的FlashAttention算子,参考[21]。
FIA
- LinearAttention:线性注意力(Linear Attention)是LLM中一种高性能(存储更小、计算更快)范式。采用线性注意力的混合模型的精度在不断提升,某些方面已达到标准注意力(Full/Standard Attention)的水平。参考[22]。
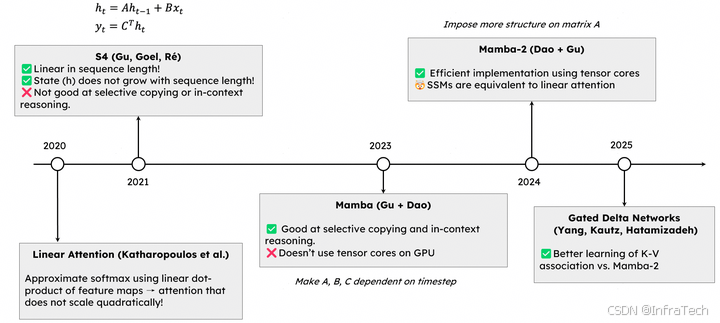
SSMs发展历程
-
DPLB(Data parallel Load Balancing):数据并行负载均衡,一种调度机制保证分发到实例上的推理请求负载均衡,从而提升整个模块的吞吐/效率,参考[23]。

-
EPLB(Expert Parallelism Load Balancer):专家负载均衡,在MoE模型中让不同设备上的专家负载均衡,参考[24]。

DPLB + EPLB
2 性能指标
推理的性能指标用于评价推理系统的能力,通过tokens生成速率来衡量服务的质量。

- TTFT(Time To First Token):首token生成的时间,用于衡量prefill性能的指标。

- E2EL(End-to-End Latency): 端到端请求时延。从输入提示词到生成所有结果并返回结束。

- ITL(Inter token Latency): 解码(decode)阶段每个token的生成时间。一般公式[25]:
I
T
L
=
E
2
E
L
−
T
T
F
T
n
−
1
ITL = \\frac{E2EL- TTFT}{n-1}
ITL=n−1E2EL−TTFT

- TBT(Time Between Tokens): 生成token之间的时间差,一般指某个token的生成时间。公式:
T
B
T
i
=
l
a
t
e
n
c
y
i
−
l
a
t
e
n
c
y
i
−
1
TBT_i = latency_i – latency_{i-1}
TBTi=latencyi−latencyi−1 - TPOT(Time Per Output Token): 所有tokens生成的平均时间,包括首token。公式:
T
P
O
T
=
E
2
E
L
n
TPOT = \\frac{E2EL}{n}
TPOT=nE2EL
注意:一些应用场景下(比如vLLM中[26]),ITL采用了TBT的计算方式,TPOT采用了ITL的计算方式。
- QPS(Queries Per Second): 每秒处理的请求数量;公式:
Q
P
S
=
T
Σ
r
e
q
u
e
s
t
=
0
T
l
a
t
e
n
c
y
(
i
)
QPS = \\frac{T}{\\Sigma_{request=0}^{T} latency(i)}
QPS=Σrequest=0Tlatency(i)T

- TPS(TokensPerSecond): 每秒吞吐量的总输出 token 数; 公式[27]:
T
P
S
=
n
t
o
k
e
n
s
T
y
−
T
x
TPS = \\frac{n_{tokens}}{T_y – T_x}
TPS=Ty−Txntokens ,单位tok/s。

TPS计算示意
- QPM(Queries Per Minute): 每分钟处理的请求的数量。
- TP90(Top Percentile): 至少有90%或者99%的请求满足该条件,类似指标还有TP50、TP99。
- RPS(Requests per Second): 每秒请求数,用于控制测试时的请求注入速率,也是吞吐量测试的重要参考指标,单位req/s。
- Ramp Up: 爬坡测试,在修改RPS来测试服务性能。
- SLO(Service Level Objective):服务质量目标,是确保为客户提供优质服务的关键。例如过去一段时间内请求是否都满足TP99,TPS=20tok/s。
- MFU(Model Flops Utilization):是衡量模型对GPU算力资源使用效率的一个指标[28]。
采样相关概念:
- Temperature:温度,操作用于调整logits的概率分布整体情况,能让概率分布变得尖锐或者平坦。
- TopK:概率排序后,保留概率最大的K个值。取值范围是1~vocab_size(-1表示禁用)。
- TopP:概率排序后,取累积概率到P的值,先排序
p
(
1
)
≥
p
(
2
)
≥
⋯
≥
p
(
V
)
p_{(1)} \\geq p_{(2)} \\geq \\cdots \\geq p_{(V)}
p(1)≥p(2)≥⋯≥p(V),然后算累加值:C
k
=
∑
i
=
1
k
p
(
i
)
C_k = \\sum_{i=1}^k p_{(i)}
Ck=∑i=1kp(i), 保留C
k
≥
P
C_k \\geq P
Ck≥P的前K个值。topP取值范围0~1。 - MinP:保留所有概率至少为最高概率的P倍的候选词,保留所有满足 (
p
i
≥
minp
×
p
max
p_i \\geq\\text{minp}\\times p_{\\text{max}}
pi≥minp×pmax) 的候选词,min_p的取值范围>0。 - Frequency Penalty:频率惩罚,对出现过的词,根据其出现频率降低logits值,频率越高衰减越严重。
- Presence Penalty:存在惩罚,对出现过的词,在logits中减去一个相应惩罚值,每个词至多惩罚一次。
- Repetition Penalty:重复惩罚,对重复出现的词进行衰减,类似频率处理。
- Beam Search:束搜索,是一种结合topK和剪枝的搜索算法,每次保留束宽(beam width)k个结果。

束宽=2的beam search示意
采样参数的详细解释参考LLM推理基础:采样(Sampling)常见知识概览
3 引擎与框架
- vLLM:一款主流的LLM推理框架,由加州大学伯克利分校(UCB)的天空计算实验室提出,最初是基于PagedAttention开发,主打一个功能全,生态好。参考1[29],2[30]。

vLLM执行流程(多DP场景)
- SGLang:另一款主流的LLM推理框架,由UCB+斯坦福提出,最初是基于RadixAttetnion开发,主打一个速度快,参考1[31],2[32]。
- Dynamo:NVIDIA自研的一款针对分布式推理系统的解决方案,参考1[33],2[34] ,3[35]。

Dynamo架构图概览
- AIBrix:LLM推理的云原生解决方案,由字节跳动推出,参考1[36],2[37]。

AIBrix架构图概览
常见服务参数(vLLM):
- max-num-seqs:每次迭代的最大序列数。
- max-num-batched-tokens:每次迭代的最大批处理 token 数。控制总 token 数。
- max-model-len:模型的上下文长度。如果未指定,则从模型配置中自动推导。最大输入+输出 tokens。
- max-input-length:输入限制长度现需。
- load-format:加载模型权重的格式。其中"dummy":用随机值初始化权重,主要用于性能分析。
- dtype:模型权重和激活的数据类型。可选值: auto, half, float16, bfloat16, float, float32
- gpu-memory-utilization: 用于模型执行器的 GPU 内存比例,并不是推理的整体使用量,参看[38]。
- block-size:kv cache中block的大小,连续token的数量。
- enforce-eager:PyTorch始终使用 eager 模式 。
- pipeline-parallel-size, pp:流水线阶段的数量。
- tensor-parallel-size, tp:张量并行副本的数量。
- data-parallel-size:数据并行副本的数量。
- enable-expert-parallel:对 MoE 层使用专家并行而不是张量并行。EP=DP*TP,参考[39]。

MoE中DP=2、TP=2、EP=4。
常见服务参数(SGLang):

内存和调度
注意:引擎版本的不同参数略有差异,具体参看官网介绍vLLM[40]、SGLang[41]。
vLLM引擎主要模块:
-
Scheduler调度器,根据系统资源和请求情况组织每次推理需要计算的数据。参考[42]。

-
KV cache管理:以PagedAttention为基础进行构建,分了逻辑层与物理层,该方式类似于操作系统的虚拟内存(virtual memory)管理。参考[43]。

-
Engine core执行单元:执行调度器下发的单步任务,包括KV传输、模型执行,参考[44]。

4 软/硬件知识点
- CoT(Chain of Thought):思维链,提示中引导或要求模型展示其逐步的推理过程,LLM的深度思考,参考[45]

一般输出与CoT输出的差异
- FCFS(First-Come, First-Served): 先到先服务,一种调度策略。
- GPTQ(Generative Pre-trained Transformer Quntanization): 针对GPT的一种量化方法,基于近似二阶信息的新型单次权重量化方法,参考[46]。
- AWQ(Activation-aware Weight Quantization): 激活感知的权重量化方法。根据激活值分布来对权重进行量化,量化粒度是通道级的(区别于整层用一个系数),参考[47]。
- Llama-2-7b-hf:Hugging Face格式的Llama2模型,参数2billion。
- Round Robin:轮询算法。例如,假设时间片为10毫秒,进程A、B、C按顺序进入就绪队列,操作系统会先让进程A运行10毫秒,然后切换到进程B运行10毫秒,接着是进程C,之后再回到进程A,如此循环。这种算法的优点是公平,每个进程都能获得一定的时间片来运行,不会出现饥饿现象(进程长时间得不到CPU调度)。
- EOS:特殊的序列结束标记,一般生成token时遇到EOS会停止输出。
- logprobs:对数概率,计算方式ln§,概率累积相乘时能够避免面溢出(超过浮点进度的表达范围),比如0.9^200。
- Reasoning Parser: 推导过程解析器,可从结果中分离出推理过程。
- Stream Reasoning: 流式推理,一个接一个的生成结果。与之对应的是非流式,生成所有结果后一次性返回。
- Structured Output: 结构化输出,使得输入按照一定的结构约束,如,json格式,参看[48]。

- RPC(Remote Procedure Call Protocol):远程过程调用协议,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
- Prometheus:普罗米修斯采集工具,是一款基于时序数据库的开源监控告警系统。
- ORCA(Open Request Cost Aggregation):它定义了服务端点(如Envoy代理)如何向外报告其实时负载指标,以便上游的负载均衡器做出更智能的流量分发决策,参考1[49]、2[50]。
- FlashMLA(Multi-Head Latent Attention),deepseek推出的极速版针对推理解码的MLA,参考[51]。

5 推理中常用python库
triton:一种深度学习的编译器和加速库,有许多高性能GPU操作(kernel),参考1[52]、2[53]。

- ray: 机器学习框架库,具备灵活的资源调度与管理,最初设计主要是支持强化学习。在推理中主要用于支撑多机资源并行运算,参考[54]。
- lmcache:一款KV cache存储/传输的库,致力于降低TTFT指标,参考[55]。
- nixl(NVIDIA Inference Xfer Library ): NVIDIA推出的一款针对推理的传输库,参考[56]。
- mooncake:一款KV cache分布式存储/传输的库,里面的TransferEngine常用于cache传输,参考[57]。
- pytorch:通用的深度学习框架。
- punica:支持multi-lora功能的库,特点是提供统一的服务接口,参考1[58],2[59]。
- asyncio:用于编写单线程的并发代码。它基于事件循环(event loop)来处理异步任务,允许程序在等待 I/O 操作(如网络请求、文件读写)时切换到其他任务。推理中,经常用它进行cpu异步操作。

- uvloop:替代asyncio,性能更高。
- tqdm:是一个用于快速创建进度条的第三方库,名称源自阿拉伯语 “taqaddum”(意为 “进展”)。
- zmq:是ZeroMQ的缩写,全称为zero message queue。是一个高性能、可扩展的消息传递库,用于构建分布式和并发应用程序[60]。
- fastapi:创建API server常用的工具,其中APIRouter 是一个非常有用的工具,它可以帮助你更好地组织和管理路由,提高代码的可读性和可维护性。
写在最后,入门的一个建议:初学大模型推理时会遇到许多新概念,不懂时会借助搜索引擎、大模型来寻找答案,但有些结果不一定准确,所以当遇到文中内容与你所了解概念不一致时,建议先参看对应的引用文章。
参考 [1]https://www.anyscale.com/blog/continuous-batching-llm-inference [2]Efficient Memory Management for Large Language Model Serving with PagedAttention https://arxiv.org/abs/2309.06180 [3]SGLang: Efficient Execution of Structured Language Model Programs https://arxiv.org/pdf/2312.07104 [4]https://zhuanlan.zhihu.com/p/1889243870430201414 [5]https://zhuanlan.zhihu.com/p/1952393747112367273 [6]https://zhuanlan.zhihu.com/p/1896927732027335111 [7]https://arxiv.org/pdf/2308.16369 [8]https://arxiv.org/pdf/2403.02310 [9]https://docs.vllm.com.cn/en/latest/features/quantization/index.html [10]https://docs.sglang.com.cn/backend/quantization.html [11]https://arxiv.org/pdf/2106.09685 [12]https://huggingface.co/blog/multi-lora-serving [13]https://platform.openai.com/docs/guides/function-calling [14]https://vllm.hyper.ai/docs/features/tool_calling/ [15]https://zhuanlan.zhihu.com/p/1937449564509545940 [16]https://docs.vllm.ai/en/latest/design/dbo/ [17]https://lmsys.org/blog/2025-05-05-large-scale-ep/#two-batch-overlap [18[https://arxiv.org/abs/2205.14135 [19]https://arxiv.org/abs/2307.08691 [20]https://crfm.stanford.edu/2023/10/12/flashdecoding.html [21]https://flashinfer.ai/2024/02/02/introduce-flashinfer.html [22]https://zhuanlan.zhihu.com/p/1969419528065773811 [23]https://zhuanlan.zhihu.com/p/1927317160889386326 [24]https://zhuanlan.zhihu.com/p/29963005584 [25]参考GenAI-Perf定义 [26]vllm/vllm/v1/metrics/stats.py [27]https://developer.nvidia.cn/blog/llm-benchmarking-fundamental-concepts/ [28]https://zhuanlan.zhihu.com/p/20401860293 [29]https://vllm.hyper.ai/docs/ [30]https://github.com/vllm-project/vllm [31]https://arxiv.org/abs/2312.07104 [32]https://github.com/sgl-project/sglang [33]https://developer.nvidia.com/dynamo [34]https://www.zhihu.com/question/15465759171/answer/129570965681 [35]https://developer.nvidia.cn/dynamo [36]https://arxiv.org/html/2504.03648v1 [37]https://aibrix.readthedocs.io/latest/ [38]https://zhuanlan.zhihu.com/p/1916529253169734444 [39]https://zhuanlan.zhihu.com/p/1937556222371946860 [40]https://vllm.hyper.ai/docs/inference-and-serving/engine_args [41]https://docs.sglang.com.cn/backend/server_arguments.html [42]https://zhuanlan.zhihu.com/p/1900957007575511876 [43]https://zhuanlan.zhihu.com/p/1954128446398633139 [44]https://zhuanlan.zhihu.com/p/1909265969823580330 [45]https://arxiv.org/pdf/2201.11903 [46]https://arxiv.org/abs/2210.17323 [47]https://arxiv.org/abs/2306.00978 [48]https://vllm.hyper.ai/docs/getting-started/examples/offline-inference/structured_outputs/ [49]https://docs.cloud.google.com/load-balancing/docs/https/applb-custom-metrics?hl=zh-cn [50]https://docs.google.com/document/d/1C1ybMmDKJIVlrbOLbywhu9iRYo4rilR-cT50OTtOFTs/edit?tab=t.0 [51]https://zhuanlan.zhihu.com/p/27976368445 [52]https://github.com/triton-lang/triton [53]https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf [54]https://docs.ray.io/en/latest/index.html [55]https://github.com/LMCache/LMCache [56]https://github.com/ai-dynamo/nixl [57]https://github.com/kvcache-ai/Mooncake [58]https://arxiv.org/abs/2310.18547 [59]https://github.com/punica-ai/punica [60]https://zeromq.org/languages/python/
InfraTech申明:未经允许不得转载!







评论前必须登录!
注册