 网硕互联帮助中心
网硕互联帮助中心幻觉——大模型时代的“阿喀琉斯之踵”
自以GPT系列为代表的大语言模型(LLMs)崛起以来,其展现的非凡语言生成与理解能力已深刻重塑了人机交互的范式。然而,一个幽灵始终徘徊在AI世界的上空——幻觉(Hallucination)。它特指模型生成的内容在语法上流畅连贯,逻辑上看似严谨,实则与输入源信息(忠实性)或客观事实(事实性)严重不符的现象。正如Gartner在2024年报告中所警示,幻觉与模型滥用已成为生成式AI的两大核心风险。在医疗诊断、法律咨询、金融分析等高风险场景中,一个微小的幻觉便可能引发决策误导、信任崩塌乃至严重的社会伦理危机。例如,在真实案例中,加拿大航空的聊天机器人因误解“特殊退款”政策,生成虚构的退款条件,最终引发了法律纠纷。幻觉仿佛成为大模型强大泛化能力与生俱来的“基因缺陷”,对其的治理不仅是技术难题,更是确保AI可靠、可信、可用的关键。
传统的幻觉缓解策略,如有监督微调(SFT)、人类反馈强化学习(RLHF)、检索增强生成(RAG)等,虽有效但存在瓶颈。SFT和RLHF高度依赖高质量且昂贵的标注数据,且容易陷入对特定数据分布的过拟合,牺牲模型的泛化能力。RAG虽能引入外部知识,但其效果严重受限于检索系统的准确性与时效性,且“知识间隙”问题——即模型在内部参数化知识与外部检索证据之间难以平衡——仍普遍存在。因此,业界亟需一种更轻量、更通用、能在模型推理阶段即时生效的干预手段。
在此背景下,两种前沿的提示工程策略应运而生:“Sorry, Come Again?(SCA)”提示与 [PAUSE]令牌注入技术。它们并非通过修改模型参数,而是通过优化输入的“提示”本身,从理解与生成两个维度双管齐下,为解决幻觉问题提供了全新的思路。本文将作为一篇面向专业架构师的分析文章,深入剖析这两种策略的技术原理、实现机制、演进脉络,并探讨其创新设计与未来方向。

追本溯源:大模型幻觉的成因与分类学
欲治其疾,先知其因。要理解SCA与[PAUSE]技术的精妙之处,必须首先洞察幻觉产生的根源。
幻觉的技术本质与分类
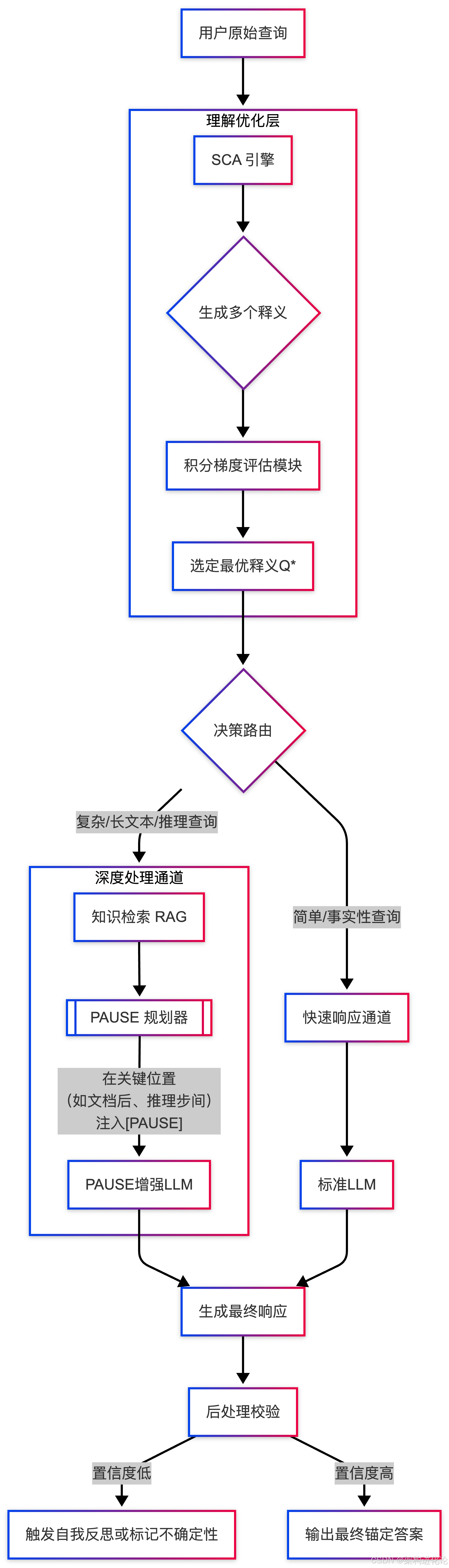
从技术原理看,大语言模型本质上是基于概率的自回归预测机器。它通过海量语料训练,学习到的是令牌(Token)之间的统计相关性,而非对人类语义的理解或对事实的判断。其生成过程可形式化为:在给定上下文 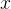 和历史生成
和历史生成 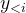 的条件下,模型从词汇表
的条件下,模型从词汇表 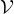 中选择下一个令牌
中选择下一个令牌 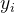 ,其概率为
,其概率为 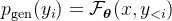 。这一机制决定了模型倾向于生成“概率上合理”而非“事实上正确”的序列。
。这一机制决定了模型倾向于生成“概率上合理”而非“事实上正确”的序列。
根据权威研究综述,幻觉可从两个维度进行分类:
-
忠实性幻觉(Faithfulness Hallucination):模型输出与提供的输入源(如指令、上下文)不一致。这又可分为内在幻觉(与输入直接矛盾)和外在幻觉(增添了输入中未提及且难以验证的细节)。
-
事实性幻觉(Factual Hallucination):模型输出与客观世界可验证的事实不符。
幻觉产生的三大核心机制
深入其生成机制,幻觉主要源于以下三方面的耦合作用:
数据集的固有缺陷:预训练语料库本身包含不准确、过时或偏见信息,模型将其作为“世界知识”记忆。当面对训练数据中罕见或缺失的“长尾知识”时,模型更易陷入基于统计模式的“臆测”。例如,要求模型讲述“林黛玉倒拔垂杨柳”的故事,它无法像人类一样识别该命题的荒谬性,而会基于“林黛玉”和“倒拔垂杨柳”各自在语料中的关联片段,拼接出一个看似合理实则荒诞的叙事。
知识间隙与上下文迷失:在复杂的推理或多轮对话中,模型存在“Lost in the Middle”现象,即对冗长提示的中间部分关注度不足,导致关键信息被忽略。同时,当用户问题与模型内部存储的知识格式不匹配时,会产生“知识间隙”,模型可能选择忽视外部检索的证据,而依赖可能已有偏差的内部参数化知识。
优化与推理过程的偏差:训练阶段的最大似然估计和教师强迫策略(扩展阅读:Decoder-Only模型的“双重人格”:从教师强制到自回归的必然路径)可能导致模型机械“复述”数据,而非真正理解。在推理阶段,为了提高创造性而采用的采样策略(如高温采样、Top-p采样)会引入不确定性,加剧幻觉。更严重的是,模型一旦开始生成幻觉,往往会为了维持前后文的连贯性而“滚雪球”式地编造更多内容进行自圆其说。
以下流程图概括了幻觉产生的核心路径:
SCA策略:通过最优释义重塑模型认知
面对上述挑战,“Sorry, Come Again?(SCA)”策略提供了一种新颖的解决思路:如果问题本身存在理解障碍,那么优化问题的表述方式,就是提升回答准确性的第一步。
SCA核心原理:从语言可读性到理解完整性
SCA策略基于一个深刻洞察:大语言模型在理解人类语言时,其面临的困难与人类相似。一个可读性低、形式化程度不当或表述过于抽象模糊的提示,会给模型带来理解挑战。当模型无法清晰把握问题的全部要义时,它便会倾向于利用其“联想记忆”去填补信息缺口,进行猜测性生成,这正是幻觉滋生的温床。
因此,SCA策略的核心包含两步:
最优释义生成:将用户的原始查询,自动重述为多个在可读性、正式度和具体性等语言学维度上不同的版本。
最优版本遴选:利用积分梯度(Integrated Gradients)等归因分析方法,评估模型对每个释义版本中每一个词的关注程度。选择那个能确保模型“均匀且充分”地处理提示中所有关键信息的版本作为最优提示。
案例解析
设想一位非专业用户向医疗AI提问:“我老是觉得心慌慌的,晚上睡不着,是不是心脏要罢工了?”
-
原始问题的问题:口语化、情绪化、包含隐喻(“罢工”)。模型可能过度关注“罢工”的隐喻,或对“心慌慌”的模糊描述产生多种医学联想。
-
SCA优化过程:系统可能生成多个释义,如:
-
版本A(更正式):“请评估‘心悸伴失眠’症状的潜在心血管病因。”
-
版本B(更具体):“患者主诉持续性心悸与入睡困难,两者是否存在关联?请列举可能的常见诊断。”
-
-
最优选择:通过积分梯度分析发现,模型对版本B中的“心悸”、“失眠”、“关联”、“常见诊断”等关键医学术语都给予了高且均衡的注意力权重,而版本A的“潜在病因”可能仍显宽泛。因此,系统将版本B送入模型进行回答生成,极大降低了因误解“罢工”而臆测出严重心脏病的幻觉风险。
技术实现与伪代码示例
以下是SCA策略中“最优释义遴选”核心模块的一个简化实现框架:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from captum.attr import IntegratedGradients
class SCAPromptOptimizer:
def __init__(self, model_name: str):
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.ig = IntegratedGradients(self.model) # 积分梯度归因分析器
def generate_paraphrases(self, original_prompt: str) -> list:
"""生成多个释义版本(此处为示例,实际可使用微调的T5等模型)"""
# 示例:简单规则与模板,实际应用需更复杂的NLP模型
base_paraphrases = [
original_prompt, # 保留原版
f"请详细解释:{original_prompt}", # 增加解释指令
f"关于'{original_prompt}',请提供基于事实的准确信息。" # 强调事实性
]
# … 这里可以接入一个释义生成模型,产生更多样化的版本
return base_paraphrases
def compute_attention_comprehensiveness(self, prompt: str) -> float:
"""计算模型对该提示的理解完整度得分"""
inputs = self.tokenizer(prompt, return_tensors='pt')
input_ids = inputs['input_ids']
# 使用积分梯度计算每个输入token的归因分数
attributions, delta = self.ig.attribute(
inputs=input_ids,
target=0, # 通常选择第一个logit作为参考
return_convergence_delta=True
)
# 归因分数取绝对值并归一化,表示每个token的重要性
normalized_attributions = torch.abs(attributions).sum(dim=-1).squeeze(0)
normalized_attributions = normalized_attributions / normalized_attributions.sum()
# 计算“理解完整度”:关键token(如名词、动词)是否获得高于平均的关注?
# 这里简化处理:计算注意力分布的熵,熵值小表示注意力集中且均匀于关键部分
# 更复杂的实现可以结合POS标签识别关键token
attention_entropy = -torch.sum(normalized_attributions * torch.log2(normalized_attributions + 1e-9))
# 将熵值转换为一个直观的分数(熵越小,分数越高)
completeness_score = 1.0 / (1.0 + attention_entropy.item())
return completeness_score
def select_optimal_prompt(self, original_prompt: str) -> str:
"""选择最优提示"""
candidates = self.generate_paraphrases(original_prompt)
best_prompt = original_prompt
best_score = -1.0
for candidate in candidates:
score = self.compute_attention_comprehensiveness(candidate)
if score > best_score:
best_score = score
best_prompt = candidate
print(f"选择最优提示:'{best_prompt}',理解完整度得分:{best_score:.4f}")
return best_prompt
# 使用示例
optimizer = SCAPromptOptimizer('meta-llama/Llama-2-7b-chat-hf')
user_query = "黑洞会不会把时间也吸进去?"
optimal_query = optimizer.select_optimal_prompt(user_query)
# 随后,将 optimal_query 而非原始查询送入模型进行最终生成
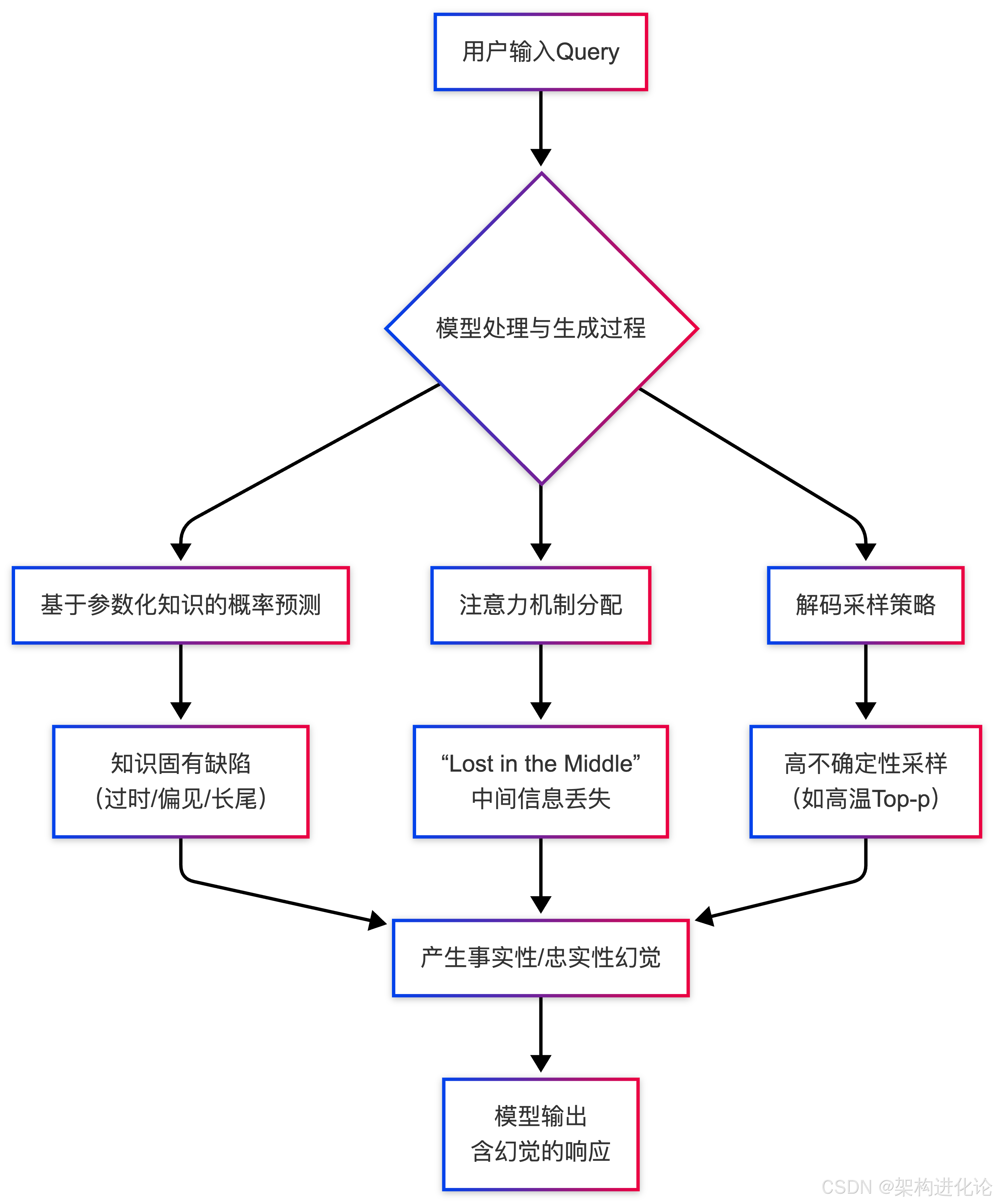
[PAUSE]注入技术:赋予模型“三思而后行”的能力
如果说SCA是从“输入端”进行优化,那么[PAUSE]注入技术则是从“处理过程”中植入一种强制性的认知缓冲机制。其灵感来源于人类阅读长难句时的自然行为——在关键处稍作停顿,以整合信息、深化理解。
核心原理:对抗“Lost in the Middle”与思维链加速
[PAUSE]技术的核心思想是在模型的输入序列中,或在生成过程的特定位置,插入一个特殊的、经过训练的 [PAUSE] 令牌。这个令牌的作用不是产出文本,而是指示模型在此处进行额外的内部计算(额外的前向传播),对已读内容进行“消化”和“总结”,然后再继续。
这直接针对了两个问题:
缓解“Lost in the Middle”:在长上下文的关键节点(如复杂指令的中间、多个证据文档之后)注入[PAUSE],能有效提升模型对全局信息的整合能力,防止关键细节被遗忘。
促进深度推理:在思维链(Chain-of-Thought)推理(扩展阅读:思维链(CoT)的演进与创新:Few-Shot与Zero-Shot架构设计深度解析、SynAdapt:基于连续思维链的自适应推理框架架构设计、Cantor:多模态思维链架构的创新设计与技术演进)的每一步之间注入[PAUSE],可以防止模型为了追求生成速度而进行肤浅的、基于模板的推理,促使其进行更扎实的逐步计算。研究证实,这种“慢思考”(扩展阅读:AI是否存在“系统一”与“系统二”?——从认知科学到深度学习架构的跨学科解读)能显著降低推理错误和事实性幻觉。
案例解析
想象模型需要处理一个长指令:“总结下面这篇关于量子纠缠的文章(文章略),然后基于总结,用类比的方式向高中生解释,最后评论一下它在量子通信中的应用前景。”
-
无[PAUSE]时:模型可能一气呵成,但容易出现“虎头蛇尾”——总结尚可,类比牵强,对应用前景的评论则完全脱离前文总结的内容,凭空编造。
-
有[PAUSE]注入时:系统可在指令中预设位置插入[PAUSE]令牌,如: “总结下面这篇关于量子纠缠的文章(文章略)[PAUSE]。然后基于总结,用类比的方式向高中生解释[PAUSE]。最后评论一下它在量子通信中的应用前景。” 在每个[PAUSE]处,模型暂停生成,内部更新对当前任务状态的表示。这确保了“基于总结”的解释真的用到了第一步的总结,而最终的评论也与前两部分保持逻辑一致,显著提升了输出的连贯性与事实一致性。
技术实现与架构设计
[PAUSE]注入的实现涉及对现有模型进行轻量级微调,使其学会如何有效利用这个特殊令牌。
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
class PauseInjectionModel(nn.Module):
def __init__(self, base_model_name: str):
super().__init__()
self.base_model = AutoModelForCausalLM.from_pretrained(base_model_name)
self.base_model.resize_token_embeddings(len(self.base_model.tokenizer) + 1) # 为[PAUSE]增加新令牌
self.pause_token_id = len(self.base_model.tokenizer) – 1 # 假设新令牌ID
# 可训练的“暂停投影层”,用于在暂停后调整隐藏状态
self.pause_projection = nn.Linear(self.base_model.config.hidden_size,
self.base_model.config.hidden_size)
def forward_with_pause(self, input_ids, attention_mask=None, pause_positions=None):
"""带暂停机制的前向传播"""
outputs = self.base_model(input_ids, attention_mask=attention_mask, output_hidden_states=True)
hidden_states = outputs.hidden_states[-1] # 最后一层隐藏状态
if pause_positions:
adjusted_hidden_states = hidden_states.clone()
for batch_idx, positions in enumerate(pause_positions):
for pos in positions:
if pos < len(input_ids[batch_idx]):
# 获取暂停位置的隐藏状态,并应用投影变换(模拟“思考”)
pause_state = hidden_states[batch_idx, pos]
transformed_state = self.pause_projection(pause_state.unsqueeze(0))
# 将变换后的状态广播到后续位置,影响后续生成
# 这是一个简化实现,更复杂的可以设计跨层的注意力更新
adjusted_hidden_states[batch_idx, pos+1:, :] += transformed_state * 0.1 # 小权重影响
# 使用调整后的隐藏状态继续计算(此处需根据模型架构调整,此为概念说明)
# 实际中,可能需要自定义生成循环,在暂停点重新计算上下文表示
return outputs
# 微调数据准备:需要构造包含[PAUSE]令牌和最佳插入位置的训练数据
# 例如,从长文档QA数据集中,根据句子边界或语义转折点自动/人工标注暂停位置
def create_pause_dataset(examples):
tokenizer = AutoTokenizer.from_pretrained('llama-2-7b')
processed = {'input_ids': [], 'attention_mask': [], 'pause_positions': []}
for text in examples['text']:
# 假设我们有一个函数`find_optimal_pause_positions`来确定最佳暂停点
# 这可以基于语法解析树的深度、句子边界、或学习到的关键phrase检测器
tokens = tokenizer.encode(text)
pause_pos = find_optimal_pause_positions(tokens) # 返回暂停位置的索引列表
# 在tokens中插入[PAUSE]令牌ID
tokens_with_pause = []
current_pos = 0
for i, tok in enumerate(tokens):
tokens_with_pause.append(tok)
if current_pos in pause_pos:
tokens_with_pause.append(pause_token_id)
current_pos += 1
processed['input_ids'].append(tokens_with_pause)
processed['attention_mask'].append([1]*len(tokens_with_pause))
processed['pause_positions'].append(pause_pos) # 记录原始暂停位置,用于损失计算
return processed
# 训练流程(概念性)
# model = PauseInjectionModel('llama-2-7b')
# dataset = … # 加载并应用create_pause_dataset处理
# training_args = TrainingArguments(output_dir='./pause-model', per_device_train_batch_size=4)
# trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
# trainer.train()
架构演进图:从基础模型到[PAUSE]增强模型
以下序列图展示了[PAUSE]注入技术如何改变模型的推理流程:
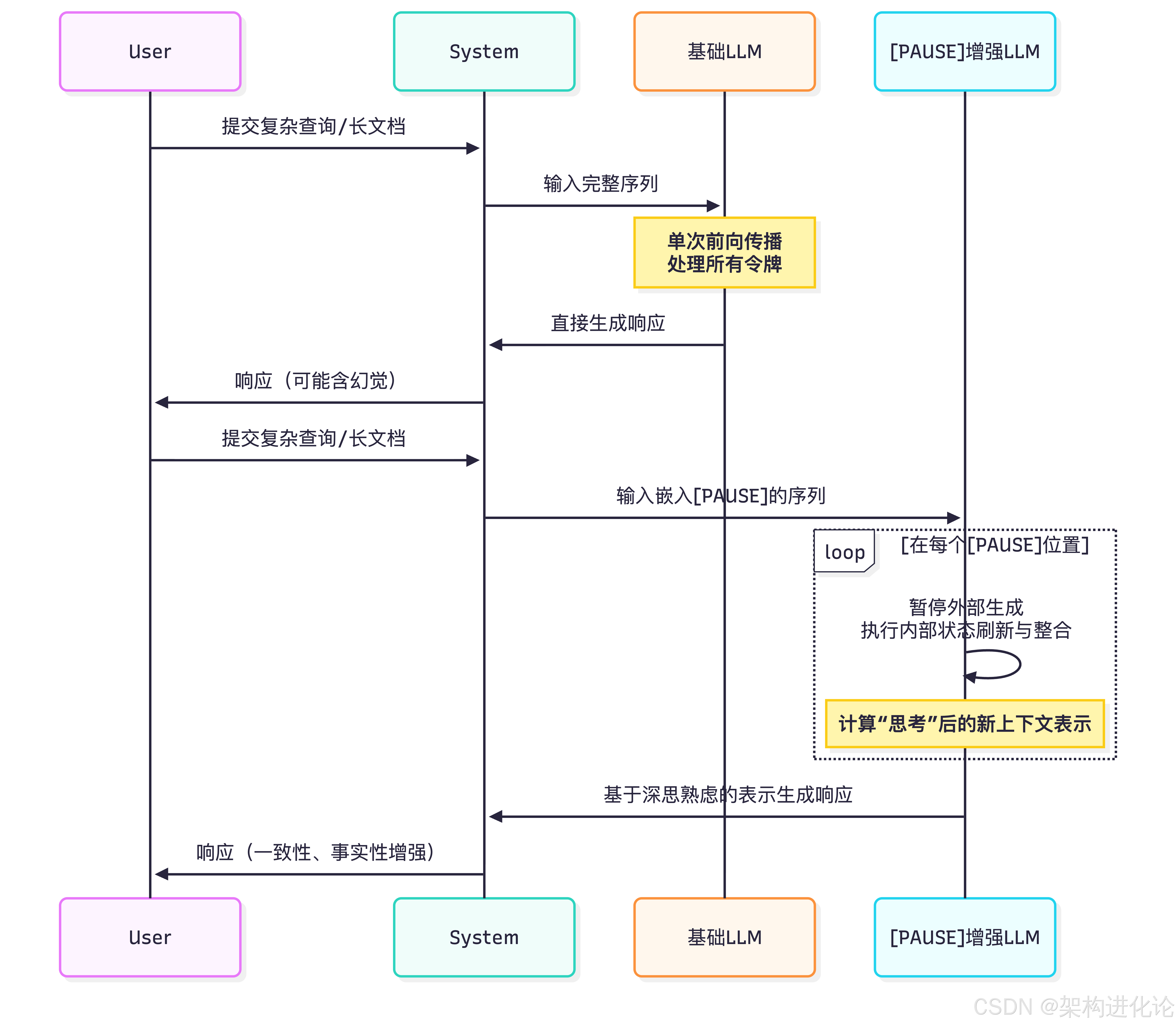
横向对比与创新设计展望
SCA与[PAUSE]技术的协同与对比
| 干预层面 | 输入侧(提示工程) | 模型内部处理过程 |
| 核心目标 | 确保模型正确理解问题的全部意图 | 确保模型充分消化已接收的信息 |
| 主要优势 | 零样本/少样本即可应用,无需修改模型,轻量灵活。 | 从认知机制上强制模型进行深度处理,尤其适合长文本、复杂推理。 |
| 挑战 | 释义生成的质量和评估非常关键;对事实性错误的纠正能力有限。 | 需要对模型进行微调;确定最优的暂停位置和数量是开放性问题。 |
| 互补性 | 强。可先使用SCA生成清晰、完整的提示,再在该提示的关键节点注入[PAUSE],实现“理解”与“思考”的双重优化。 |
与传统及前沿技术的融合演进
SCA与[PAUSE]技术并非孤岛,它们代表了大模型幻觉治理从“重训练”向“轻推理”演进的重要趋势。它们可以与现有技术栈无缝融合:
-
与RAG结合:在RAG流程中,对用户查询使用SCA优化,提升检索相关性;在模型阅读完检索到的多篇文档后,注入[PAUSE]令牌,帮助其整合跨文档信息,减少矛盾。
-
与Self-Reflection(自我反思)结合:让模型生成初步答案后,以“[PAUSE]请检查上述回答中是否存在事实错误或逻辑矛盾”为指令,触发其批判性思维链。
-
与动态系统提示(Dynamic System Prompt)结合:如阿里云通义大模型的实践,根据用户问题场景动态调整系统指令。SCA可以作为生成这些动态指令的底层优化器,而[PAUSE]则可以嵌入到这些系统指令中,指导模型在特定步骤进行停顿与核查。
面向架构师的创新设计提案
基于以上分析,我提出一个名为 “CogAnchor”(认知锚点)的综合性幻觉缓解系统架构设计:
CogAnchor系统工作流:
理解锚定:所有用户查询先经过SCA引擎,被重述为最清晰、最易被模型全面理解的版本(Q*)。
路径决策:轻量级分类器根据Q*的复杂度、长度和领域,决定走“快速通道”还是“深度通道”。
思考锚定:深度通道中,结合RAG获取外部知识,并由“[PAUSE]规划器”(可基于规则或学习模型)在输入序列中插入[PAUSE]令牌。
生成与验证:模型生成响应后,通过轻量级的事实一致性检查(如命名实体验证、与检索片段的一致性评分)进行后处理。低置信度回答可触发二次验证或明确标注不确定性。
结论
大模型的幻觉问题,根植于其概率生成的本质,是能力与可靠性永恒博弈的体现。完全消除幻觉既无可能,在当前阶段也无必要——正如人类创作既需要严谨的科学报告,也需要天马行空的文学幻想。关键在于实现场景化的精准控制。
“Sorry, Come Again?”与[PAUSE]注入技术,分别从语言理解的清晰化和认知加工的深度化两个维度,为我们提供了在推理阶段进行精细调控的有力工具。它们代表了幻觉缓解技术从依赖大量标注数据和模型重构的“重模式”,向利用提示工程和轻量微调的“灵巧模式”演进的重要方向。
展望未来,一个理想的、可信赖的大模型系统,必然是多层次防御体系的集成:它需要高质量的预训练与对齐(基石),需要RAG等外部知识的高效接入(延伸),更需要像SCA和[PAUSE]这样在推理时刻灵活应变的“认知调节器”(精调)。作为架构师,我们的任务就是巧妙地将这些技术编织在一起,在模型的“想象力”与“事实性”之间,在生成的“流畅度”与“可靠性”之间,为不同的应用场景找到那个动态的最优平衡点,最终构建出既能畅游思想星空,也能脚踏实地服务人类的AI伙伴。









评论前必须登录!
注册