 网硕互联帮助中心
网硕互联帮助中心1. 前言
上一篇文章我们逐个学习了 VFS 的四大核心对象,那么本篇文章我们将更加深入内核,深度拆解这些对象是如何通过路径查找、接口多态来协作完成一次真实的文件操作的。
我们话不多说,直接进入正题。
2. 路径查找
我们在写代码时,通常像下面这样打开一个文件:
int fd = open("/home/user/a.txt", O_RDONLY);
这里使用的路径是绝对路径,也可以使用相对路径。
对于用户程序来说,我们只是提供了一个冷冰冰的字符串路径,但是对于内核来说,它只认识 Inode。
那么,内核究竟是如何把这个字符串 /home/user/a.txt,一步步转换成内存中具体的 struct inode 的?其实这个过程在 Linux 内核中被称为 Path Walking(路径查找)。
具有一定编程思维的人可能在阅读内核源码之前就已经有思路了:只需要把字符串按 / 切分,一级一级找不就行了。
这个思路其实很简单,逻辑上也确实是这样的。但在工程实现上,为了保证极致的性能和功能的灵活性,就不能每切分一级目录就去读一次磁盘,还要做好对挂载点的处理,因此 Linux 在这里设计了极其精妙的机制。
2.1 目录项缓存 Dcache
如果真的像最原始的逻辑那样,每查找一级目录,都要去读一次物理磁盘,那么 Linux 的 I/O 性能将慢得令人崩溃。
我们按照这个原始逻辑感受一下,查找 /usr/bin/vim 这个路径:
每一次磁盘 IO 都是毫秒级的开销,为了避免这种耗时的操作,VFS 引入了 Dcache (Dentry Cache)。
还记得我们上篇文章讲的struct dentry吗?它不仅仅代表路径,在内存中它还是一个哈希表节点。
当内核开始解析路径时,它的第一反应绝不是读磁盘,而是查内存:看看 Dcache 里有没有缓存过 usr 这个目录项?
如果 Cache Hit(缓存命中):直接拿到 dentry,不需要读盘,纳秒级完成。
如果 Cache Miss(缓存未命中):就调用具体文件系统的 lookup 接口,去磁盘读取元数据,构建一个新的 dentry 放入缓存,以便下次高效查找。
这里讲一个冷知识:Linux 系统中 90% 以上的空闲内存往往都被 Page Cache 和 Dcache 占据。当你发现系统内存占用很高但运行流畅时,通常就是它们在替你加速。
2.2 路径解析的详细流程
让我们模拟一下内核解析 /home/user/a.txt 的全过程。虽然内核源码中负责此工作的 filename_lookup 函数非常复杂,但逻辑上我们分析个大概还是没有什么难度的。
确定起点
内核首先要判断从用户层接收到的字符串路径到底是绝对路径还是相对路径。这就是前面提到的open中不论填绝对路径还是相对路径都可以,内核中已经把判断的逻辑写好了。
如果字符串以/开头,那就说明是绝对路径,从 current->fs->root开始走。
如果字符串不以 / 开头,那就说明是相对路径,从current->fs->pwd开始走。
本例中,我们是绝对路径,从根目录 / 出发。
这里补充一点:可能有不少人知道current->fs->root大致是什么意思,但疑惑它到底是个什么,这部分内容将会放在本章小结中为大家解释。
逐级解析路径
内核会将路径字符串拆解为三个分量,即 home、user、a.txt,然后开始一个循环。
第一步:拿根目录的 dentry 和字符串 "home" 计算哈希值,在 Dcache 中查找。如果没找到,就让 EXT4 去磁盘把 home 目录读出来,生成一个 dentry 放在内存里。此外还会检查该进程有没有权限访问home目录。
第二步:拿着刚才找到的 home 的 dentry,在下面查找 "user",查找步骤与第一步相同。
第三步:同理,可以查找到"a.txt"。最终找到了目标文件的 dentry 和对应的 inode。
穿越挂载点
这可以说是路径查找中最让人摸不着头脑的地方。
假设你的系统里挂载了一个 U 盘,挂载点是 /mnt/usb。当你访问路径 /mnt/usb/photo.jpg 时,内核在解析到 usb 这一层时,会发现usb 这个目录项被打上了一个特殊的标记——DCACHE_MOUNTED。
这时 VFS 会意识到:这里虽然叫 usb,以及虽然是从 /mnt 走过来的,但它已经不是原来的那个目录了,它是另一个文件系统的入口。
此时,内核会根据挂载记录,自动跳转到对应文件系统的根目录 Dentry 上。
这些操作对用户是完全透明的,用户根本感觉不到自己已经跨越了文件系统的边界,从一个文件系统的地盘跳到了另一个文件系统的地盘。这就是 VFS 屏蔽底层差异的核心手段之一。
2.3 路径查找进入尾声
截至现在,VFS 终于找到了 a.txt 对应的 struct inode。
但 open() 系统调用返回给用户的,却是一个简单的整数 fd。虽然大家都知道这就是文件描述符,但我还是想讲一下它到底是怎么来的?
内核在创建 File 对象时,会分配一个全新的 struct file,将 f_path.dentry 指向刚才找到的 dentry,将 f_path.mnt 指向对应的挂载点,再初始化 f_pos 为 0。
然后在当前进程的文件描述符表fd_array中,找一个最小的空闲下标,作为文件描述符fd。
接着建立文件描述符表中相应位置与struct file指针的关系:
fd_array[fd] = 这个新的 struct file 指针
最后将fd返回给用户。
正因为 open 做了繁重的路径查找工作,并建立好了 fd 到 struct file 的映射,所以后续的 read 操作才能极其高效。内核直接通过 fd 就能拿到 file 和 inode,再也不用去解析那长长的字符串路径了。
2.4 小结
下面我们来讲一下current->fs->root到底在干什么。
current是内核中最重要的宏之一,它始终指向当前正在 CPU 上运行的那个进程的进程控制块(struct task_struct)。
fs是struct task_struct中的一个成员struct fs_struct,专门用来存储该进程与文件系统相关的上下文信息。它记录了根目录在哪、当前工作目录在哪。
root指向了该进程认为的根目录的dentry。
pwd指向了该进程认为的当前工作目录的dentry。
根目录作为一个所有进程都可能访问的目录,为什么要放在进程里面,而不是作为一个全局变量呢?
实际上,通常情况下所有进程的 root 都指向真正的系统根目录 /。但是,Linux 允许我们修改这个指向,这就是 chroot 命令 以及现代 容器技术(Docker) 的核心原理。
结果当容器内的进程去访问 /etc/passwd 时,内核从它的 fs->root 开始找,实际上找到的是宿主机那个子目录下的文件。容器进程就像被关在了一个小黑屋里,它以为自己看到了全世界(根目录),其实它看到的只是宿主机的一个角落,也就是我们想让它看到的东西。
3. 接口与多态
VFS 作为一个抽象层,它自己是不存储数据的。它不知道数据是在磁盘的第几个扇区,也不知道网卡收到了什么包。真正干活的,是底层的 EXT4,FAT32 或者 TCP/IP 协议栈。
而 VFS 在这个过程中要做的就只有标准化接口。
用面向对象的语言来说,这叫做多态。但 C 语言没有 interface 关键字,Linux 内核的大佬们就用函数指针手搓了一套多态机制。
3.1 三个操作集
这三个操作集结构体的内容都是比较多的,我就不放源码了,下文中只介绍关键成员,想看完整内核源码可以去源码目录/include/linux/fs.h中找,三个结构体连着定义的,很好找。
3.1.1 文件内容操作
文件内容操作struct file_operations:这是平时写应用程序时最常用的接口,它定义了对打开的文件内容可以做哪些操作。
该结构体的核心成员包括:read读文件内容,write写文件内容,mmap内存映射,open打开,release关闭。
下面具体描述一下:
如果我们要读的是 EXT4 文件,就将read对应的函数指针初始化为 ext4_file_read_iter,而ext4_file_read_iter的实现并不属于 VFS 的管理范畴,它是 EXT4 文件系统底层需要完成的。
如果是 Socket 套接字,函数指针就初始化为 sock_read_iter。
这就是将操作与相应函数对应起来的方法。
3.1.2 元数据操作
struct inode_operations这组接口关注的是文件本身或者说是目录项的操作,而不是文件里面的内容。
核心成员有:create创建新文件,mkdir创建目录,lookup在目录中查找文件,setattr修改权限和时间戳。
这里 **file_op 和 inode_op **一定要区分开,有些操作是不需要打开文件就可以执行的。比如 mkdir,你不需要打开一个目录就能创建它。比如 rm (调用 unlink),你删除文件时也不需要先 open 它。这些操作针对的是 Inode(文件实体)而非 File(句柄)。
3.1.3 文件系统整体操作
struct super_operations管理的是整个文件系统的生命周期。
核心成员:
3.2 具体场景演示
下面让我们看看当用户执行 read 时,内核里发生了什么?
在 VFS 层(源码目录fs/read_write.c),代码逻辑非常简洁,如下:
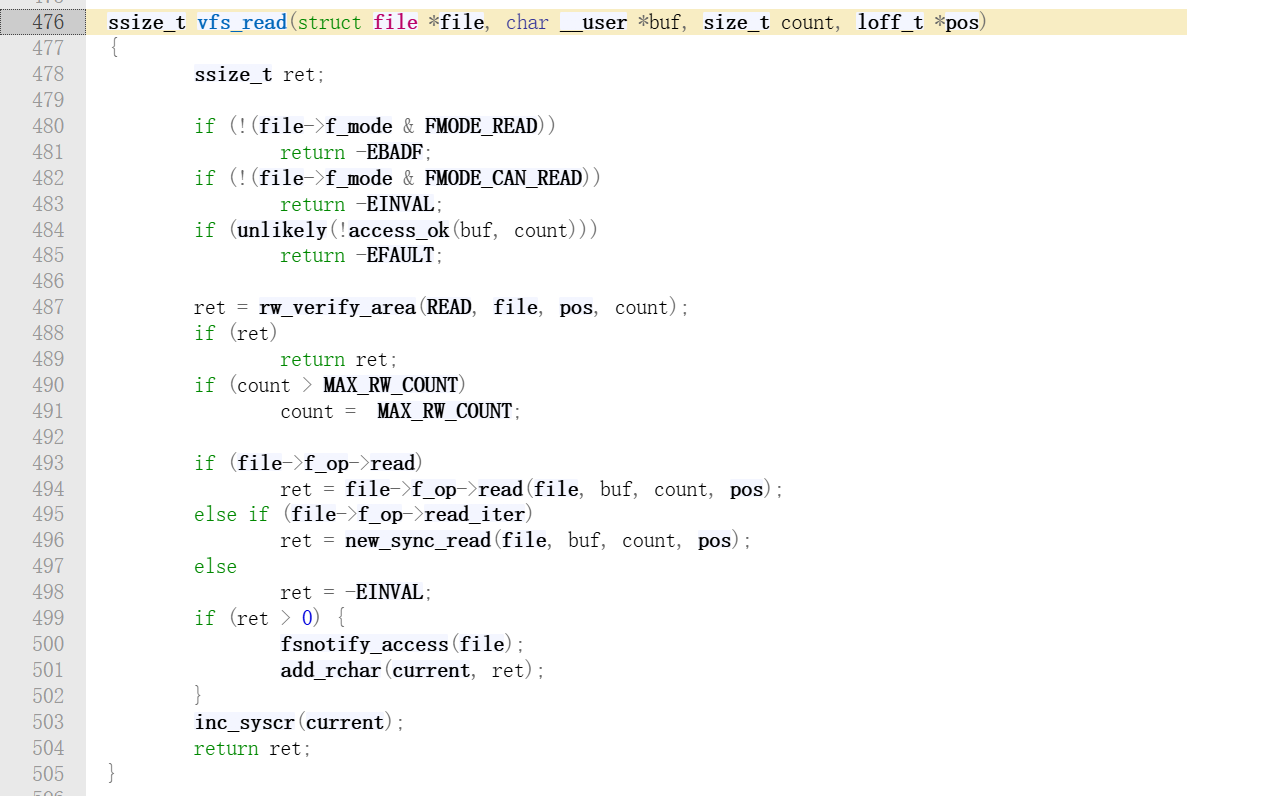
核心逻辑我们从第 493 行开始看,VFS 层直接调用函数指针,根本不关心它是 EXT4 文件系统还是 FAT32 文件系统。为什么可以这样做呢?
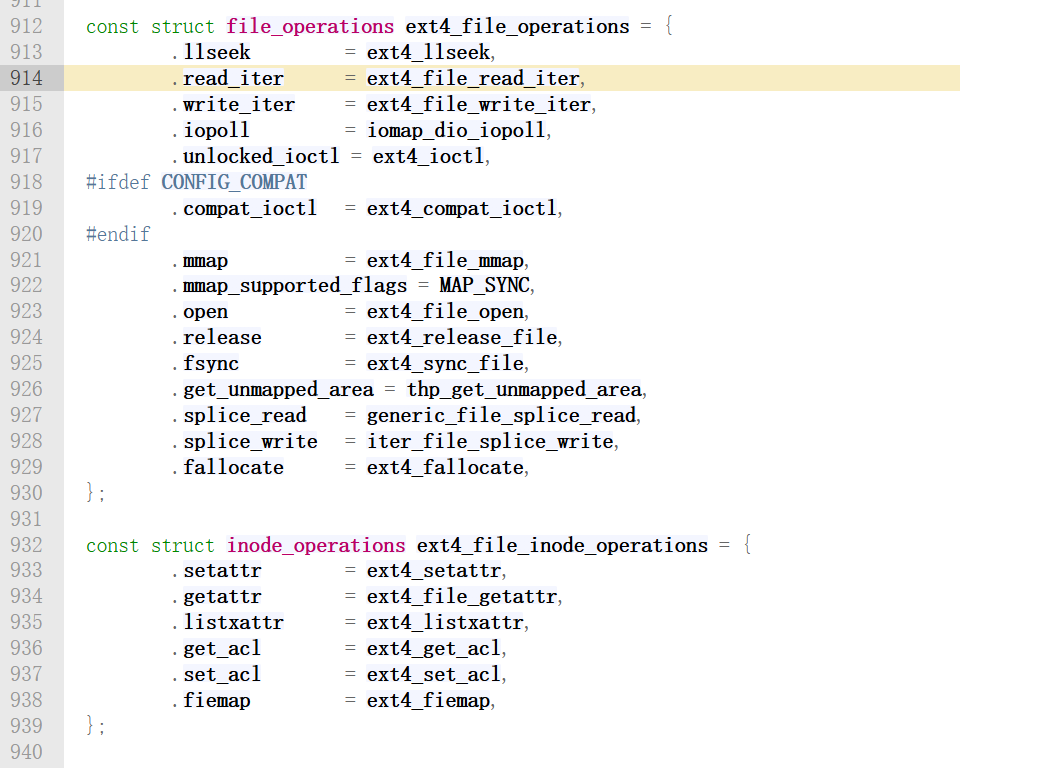
实际上,当 EXT4 文件创建时,内核把 inode->i_fop 指向了全局变量 ext4_file_operations,一个具体文件打开时,struct file出现了,file->f_op会继承 inode->i_fop,然后vfs_read 调用 file->f_op->read,实际上执行的是 ext4_file_read_iter。这就是 VFS 层调用再通向某个文件系统具体调用的过程。下面我们来看看这个过程在内核源码中的体现。
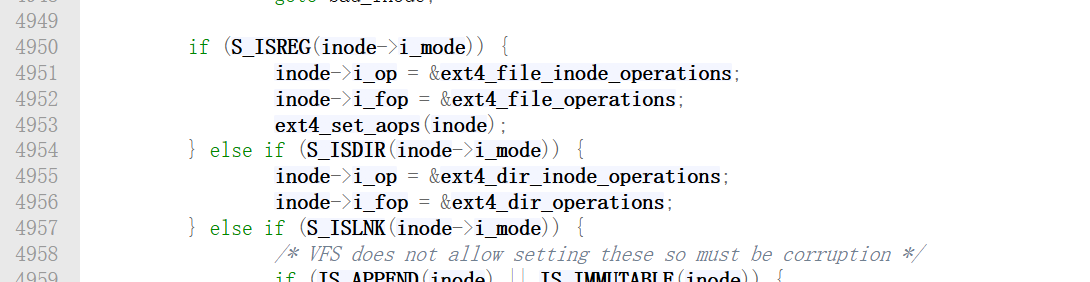
当 EXT4 从磁盘读出一个 Inode 时。如果发现这个 Inode 是个普通文件S_ISREG,就把 ext4_file_operations 挂上去,这样以后对它的 read 就会调用 EXT4 的读函数。如果发现它是个目录S_ISDIR,就把 ext4_dir_operations 挂上去,这样对它的 read就会去读取目录项列表。这个过程在函数__ext4_iget中实现,该函数位于内核源码/fs/ext4/inode.c中,这个函数有好几百行,我只截取了重要的几行,如下:
两个操作集的实现在/fs/ext4/file.c中,如下图:

就是在这里完成 VFS 层的读操作到EXT4文件系统读函数的映射的。
到此,我们已经把用户层调用read到具体的文件系统执行相关读函数这条线捋清了。
4. 全链路追踪一个read请求
假设应用程序执行了这样一行简单的代码:
ssize_t n = read(3, buf, 4096);
这是一个极其普通的调用,但在 Linux 内核的微观世界里,却相当复杂。
让我们结合内核源码,一行行追踪数据的流向。
4.1 系统调用入口
当用户程序执行 read 时,CPU 发生模式切换,通过系统调用表跳转到内核入口。在 Linux 源码中,系统调用的定义通常使用 SYSCALL_DEFINE 宏。
源码位于fs/read_write.c中,如下:

宏展开后就是 sys_read 函数,调用 ksys_read,这是内核内部的通用入口。
在ksys_read内部,根据用户传入的 fd 获取 struct file 指针,其实fdget_pos 就是去当前进程的 files_struct文件描述符表里查,把整数 fd变成了 struct file * 指针。第 629 行获取当前文件的读取位置。第 634 行进入 VFS 的通用读取逻辑。
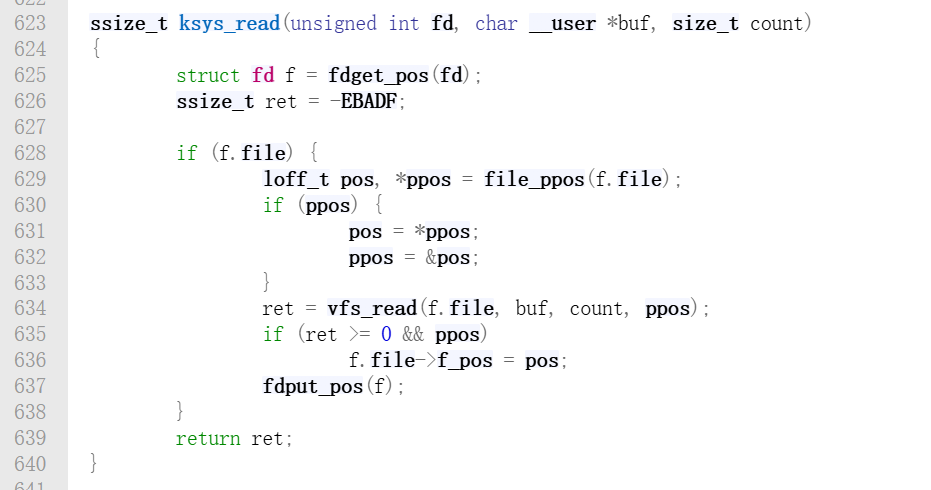
到此,我们已经踏入 VFS 的大门了。
4.2 VFS 分发
vfs_read 可以理解为一个具有分发功能的函数,它不负责具体的读写,只负责路由分发。它要根据文件系统的实现情况,决定调用哪个函数。源码位置:fs/read_write.c。
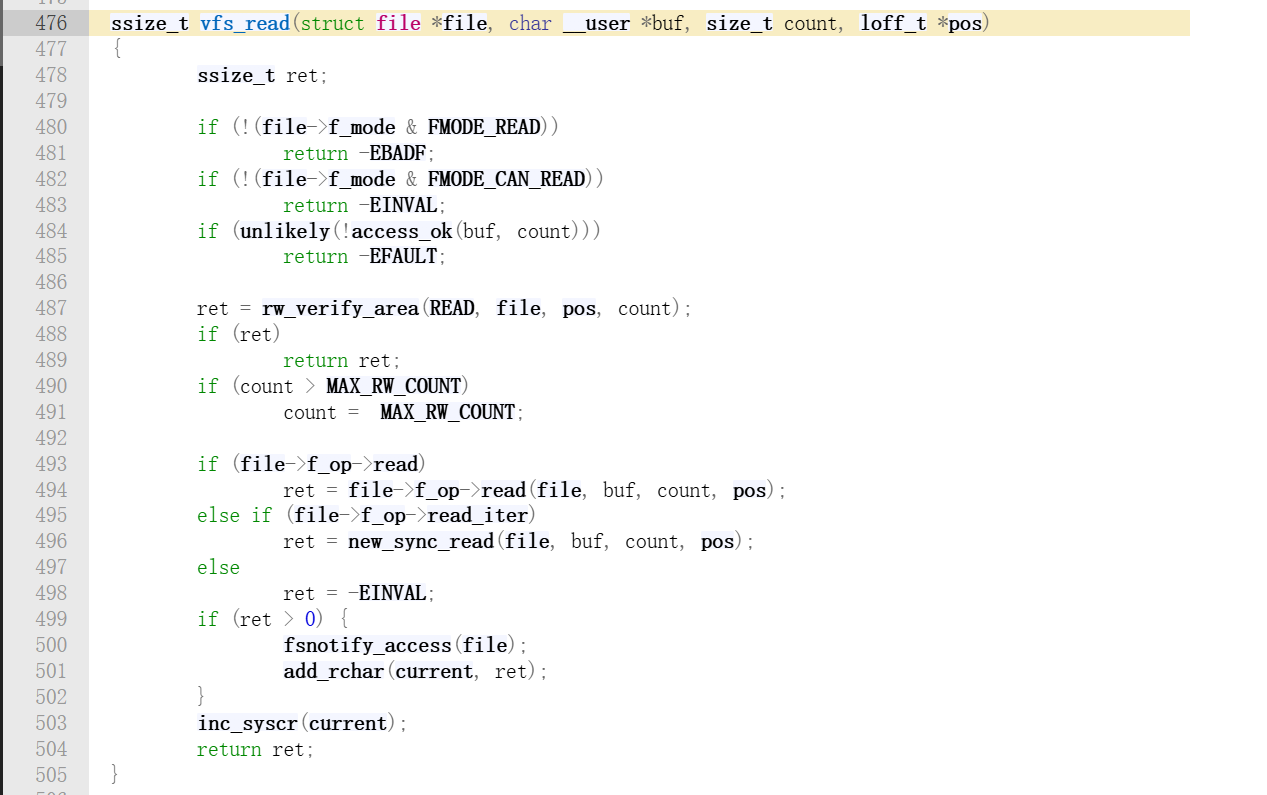
前面都是一些权限检查之类的操作,核心逻辑从 493 行开始。
第 493 行可以看到,VFS 会优先调用 read,没有read则调用 read_iter,区别在于read_iter比较现代,EXT4,XFS 等现代文件系统都在这里。
这里体现了 C 语言的多态。EXT4 没有实现 .read,而是实现了 .read_iter,所以逻辑会走到 new_sync_read。
该函数实现如下:
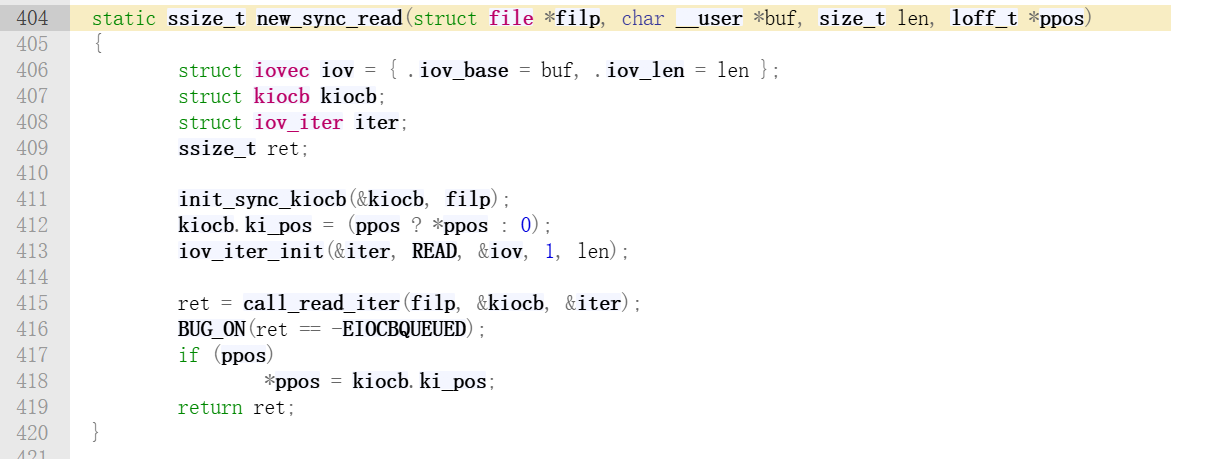
可以看到它最终调用了call_read_iter,它位于include/linux/fs.h,我们继续跳转:

到这里是不是有点熟悉的感觉。继续:
不管是read还是read_iter,兜兜转转都是来到了这里。
下一步我们将会离开 VFS,进入 EXT4 的领地。
4.3 进入EXT4
经过 VFS 的分发,控制权终于来到了具体的文件系统手中。源码位置fs/ext4/file.c。
我们来看看这个函数的具体实现:
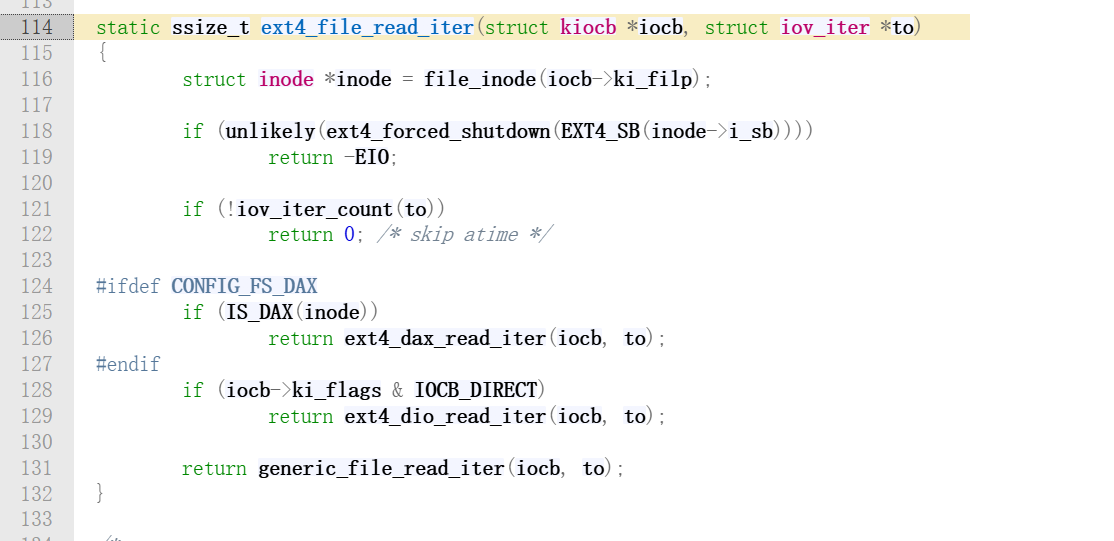
这个函数最后又调用了generic_file_read_iter函数,EXT4 最终又把脏活累活都外包给了 Linux 的内存管理子系统。
这其实正是 Linux 设计精妙之处,对于基于磁盘的文件系统,读取逻辑高度相似,都是查 Page Cache,没有就读盘,所以内核在 mm内存管理子系统里提供了一套通用的标准实现。
4.4 页缓存 Page Cache
这是 IO 性能的关键点,generic_file_read_iter 会去查询页缓存,该函数的实现位于mm/filemap.c。该函数依然只贴出关键部分的截图:
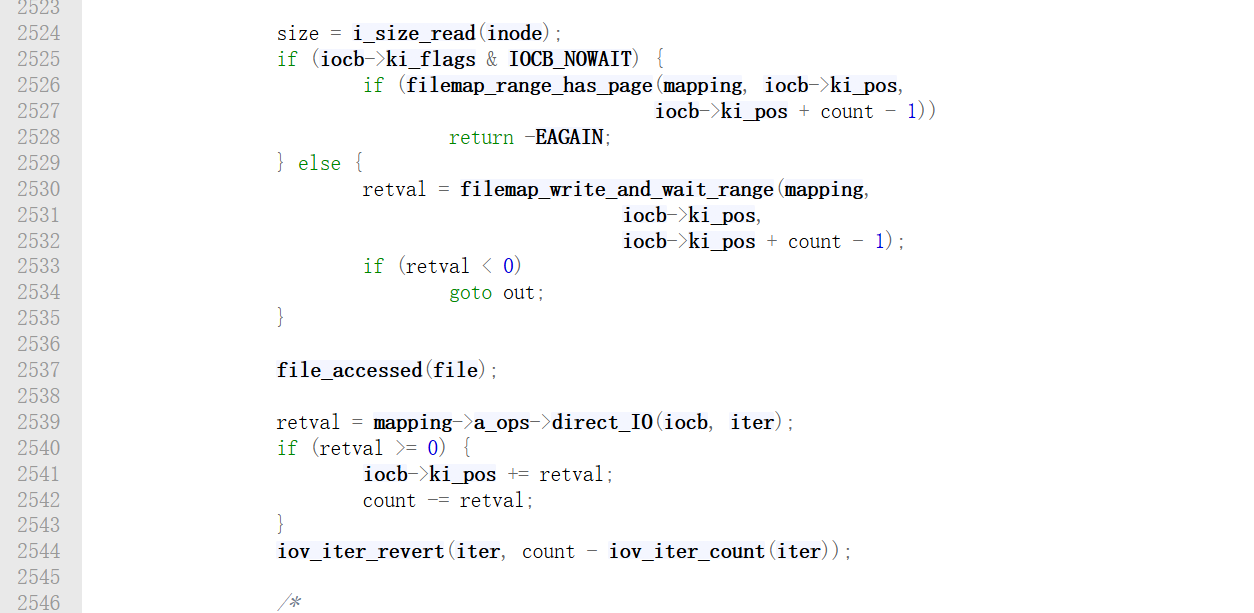
第 2525 行到第 2535 行是 Direct I/O 的执行逻辑,如果用户在 open 时加了 O_DIRECT 标志,iocb->ki_flags 就会有 IOCB_DIRECT,这样会绕过 Page Cache,直接调用文件系统的 direct_IO 接口。如果在这里读取成功,或者读完了,就直接在goto out,不走下面的缓存逻辑。

其实绝大多数都是走查缓存逻辑的,代码会执行 2560 行的generic_file_buffered_read。
这个函数极长,好几百行,这里就不贴代码了,这么多代码主要做了两件事。第一件是查缓存,去找有没有现成的页。第二件事是预读,如果没有现成的页,它不仅会把当前需要的页读进来,还会把后面几页也顺便读进来,以提高性能。
4.5 查找物理块
当内存子系统决定要从磁盘读数据时,它会问 EXT4 文件的第 0 页对应磁盘的哪个块。
该部分源码位置fs/ext4/inode.c。

将逻辑偏移量转换为物理扇区号,最终map->m_pblk 存储了物理磁盘块号。
拿到了物理块号,内核将其封装成一个 struct bio (Block IO) 请求,提交给通用块层。
submit_bio 会将请求放入电梯调度队列,最终由 NVMe 或 SATA 驱动通过 DMA 将数据搬运到内存。
4.6 小结
看到这里,你应该明白了,Linux 的 VFS 不仅仅是一层接口,它更像是一套精密的流水线。 上层的 read_write.c 负责接待,中层的 filemap.c 负责缓存加速,底层的 ext4 负责物理寻址,分工很明确。
5. 总结
至此,我们完成了对 Linux VFS 的拆解。
无论底层是 EXT4、FAT32 还是网络 NFS,VFS 都把它们伪装成统一的 struct file 和 struct inode。使得应用开发变的如此简单。
Linux 内核用最古老的 C 语言,通过结构体和函数指针,实现了最极致的多态与抽象,Linux 内核本身就是一本教科书。
希望通过这个系列文章,当你下次敲下 open() 或 read() 时,脑海中不再只是枯燥的 API 和记不完的参数,而是能浮现出那张巨大的关系图:从 fd 到 dentry,从 inode 到驱动,真真切切地感受内核中的数据漂流。
本文完。




评论前必须登录!
注册