 网硕互联帮助中心
网硕互联帮助中心Claude的Skills机制是一种按需加载的专业知识模块,具有"用完即回收"特点,与传统工具调用和Multi-Agent架构有本质区别。Skills通过临时增强System Prompt实现Token效率的量级提升,同时保持单体架构的简单性。文章探讨了Skills与Sub-Agent的区别,提出了根据任务复杂度选择架构的原则,强调模块化是应对复杂性的根本策略,建议从简单开始渐进演进。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
引言
最近研究 Claude 的 System Prompt 时,发现了一个有意思的机制——Skills。
表面上看,这只是"调用工具读取文件"的普通操作。但深入分析后发现,Skills 背后隐藏着一套精巧的架构设计思想,做 LLM 应用的人都应该了解。
从 Skills 机制出发,本文探讨 AI 系统的模块化设计哲学,以及它与 Multi-Agent 架构的本质区别。
一、什么是 Skills?
Skills 是 Claude 按需加载的专业知识模块。当你让 Claude 创建 PPT、编辑 Word 文档或处理 Excel 时,Claude 会动态加载对应的最佳实践指南,完成任务后再将这些知识从上下文中移除。
三个关键特征:
你可能会问:这不就是普通的 function calling 吗?
确实,从技术实现看,Skills 就是一种特殊的工具调用。但它的独特之处在于架构理念。
二、Skills vs 普通工具调用
2.1 加载的内容不同
普通工具调用获取"数据":
get_weather() → 返回"今天 25°C"
search_database() → 返回"用户订单记录"
calculate() → 返回"计算结果 42"
这些都是任务相关的具体信息。
Skills 调用获取"元知识":
load_pptx_skill() → 返回"如何创建专业 PPT 的完整指南"
load_docx_skill() → 返回"Word 文档编辑的最佳实践"
Skills 返回的是任务无关的通用方法论——“授人以渔"而非"授人以鱼”。
2.2 Context 生命周期不同
这是最关键的区别。
普通工具返回的数据:
- 持久保留在对话上下文中
- 后续对话可以引用
- 占用空间直到对话结束
Skills 加载的知识:
- 只在当前任务期间使用
- 任务完成后被回收
- 不会永久占用上下文
举个例子:
场景1:普通工具
用户:“查一下北京天气” → get_weather() 返回:“北京 25°C,晴” → 这个数据留在 context 里
用户:“那上海呢?” → Claude 仍能看到之前的北京天气数据 → context 累积增长
场景2:Skills
用户:“帮我做个 PPT” → load_pptx_skill() 返回 8k tokens 的 PPT 制作指南 → Claude 基于这个指南创建 PPT → PPT 创建完成后,这 8k tokens 被回收
用户:“再帮我做个 Word 文档” → context 中已经没有 pptx skill 了 → 如果需要再次创建 PPT,会重新加载
这种"用完即回收"的设计带来两个好处:
2.3 加载时机不同
普通工具是响应式调用:
用户:"北京天气怎么样?"
→ Claude 推理:"需要天气数据"
→ 调用 get_weather("北京")
→ 得到数据后回答
Skills 是预判式加载:
用户:"帮我做个 PPT"
→ Claude 推理:"这需要 PPT 制作能力"
→ 调用 load_pptx_skill() // 注意:这时还没开始做
→ 学习了方法论后,再开始创建 PPT
Skills 是在执行任务之前加载"如何执行"的知识,而普通工具是在执行过程中获取需要的数据。
2.4 本质:临时增强 System Prompt
换个角度看:
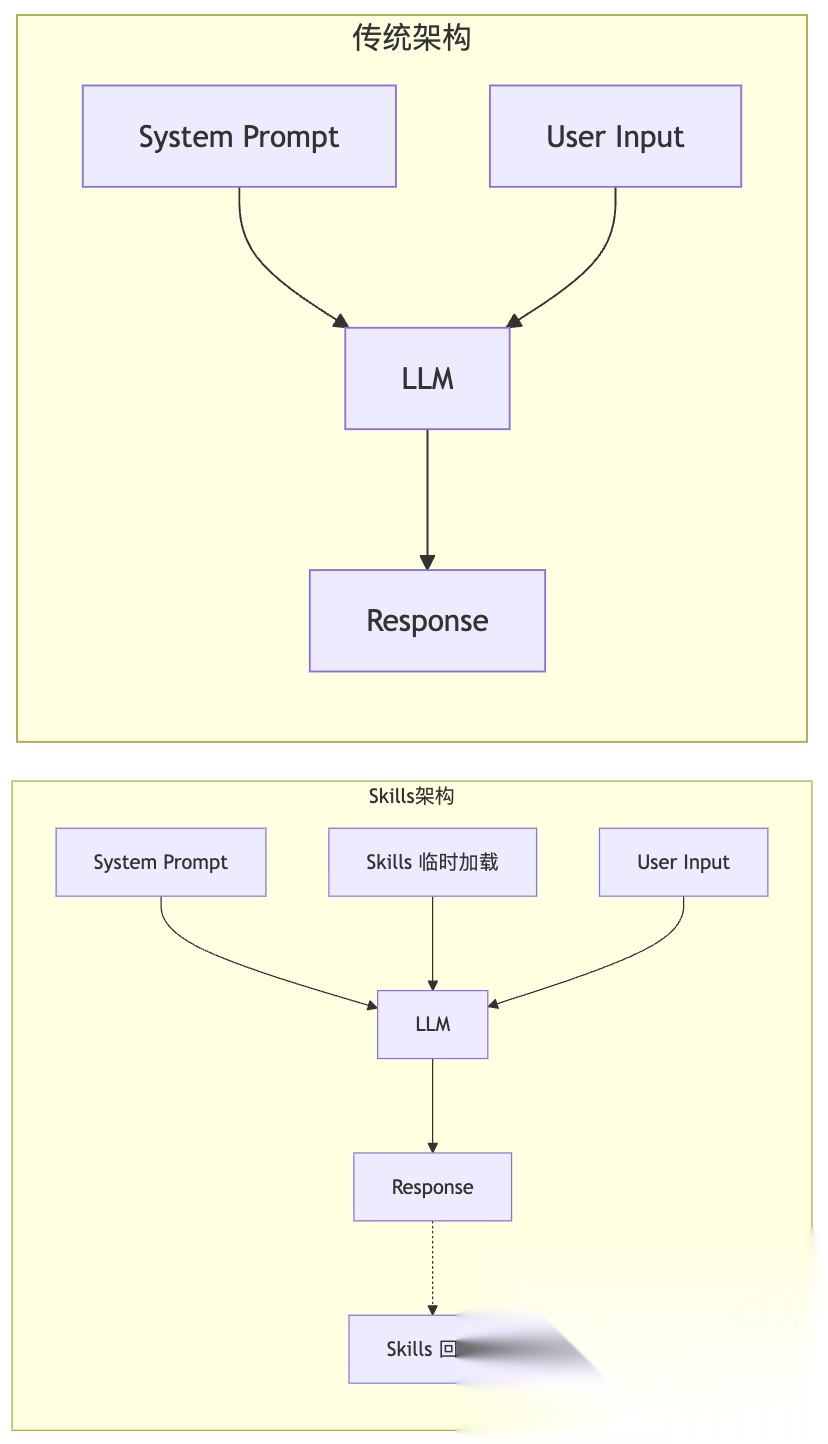
Skills 的本质是临时扩展系统提示词的能力边界,用完即弃。
这个理念可以推广到任何 LLM 应用:
Skills 更像是一种设计模式,类似于软件工程中的"资源池管理"在 LLM 领域的应用。
三、核心价值:Token 效率的量级提升
3.1 具体数据对比
假设一个典型的 AI 系统需要支持这些能力:
方案A:全量加载
| Word 处理 | 10,000 |
| PPT 制作 | 8,000 |
| Excel 分析 | 12,000 |
| PDF 操作 | 6,000 |
| 前端设计 | 15,000 |
| 总计 | 51,000 |
这意味着 Claude 200k 上下文窗口的 25% 被"可能用不到"的知识占据。
方案B:按需加载
| 普通对话 | 0 |
| 创建文档 | 10,000 |
| 创建 PPT | 8,000 |
平均节省:40-50k tokens/对话
3.2 回收机制的价值
更重要的是 Skills 用完后会被回收:
没有回收机制:
1. "做个 PPT" → 加载 8k tokens
2. "做个 Word" → 累计 18k tokens
3. "分析 Excel" → 累计 30k tokens(一直保留)
有回收机制:
1. "做个 PPT" → 8k tokens,完成后回收
2. "做个 Word" → 10k tokens,完成后回收
3. "分析 Excel" → 12k tokens,完成后回收
峰值占用:12k tokens(只在单个任务期间)
这意味着:
- 可以在一个对话中使用无限多的 skills
- Context 空间不会因为使用 skills 而累积消耗
- 长对话场景下优势更明显
3.3 优化的实际意义
3.4 更深层的价值
Token 效率只是表面,Skills 还带来这些价值:
这些价值解释了 Skills 作为一种设计模式的吸引力。但更大的问题是:Skills 和当下流行的 Multi-Agent 架构有什么本质区别?该选哪个?
四、Skills vs Sub-Agent:单体智能与分布式智能
“如果 Skills 按某种编排逻辑串联起来,不就跟 Sub-Agent 一样了吗?”
这个问题涉及到 AI 系统设计中一个核心问题:单体智能 vs 分布式智能。
4.1 表面相似:模块化 + 专业化
Sub-Agent 模式:
- 规划 Agent 负责分解任务
- 代码 Agent 专注于编程
- 研究 Agent 擅长信息检索
- 写作 Agent 精通文档创作
Skills 模式:
- docx skill 提供文档处理知识
- pptx skill 提供演示文稿知识
- frontend skill 提供前端设计知识
两者都在追求"专业化分工"。区别在哪?
4.2 三个关键差异
差异1:推理主体——一个 Claude vs 多个 Agent
这是最核心的区别。
Sub-Agent 模式像团队会议:
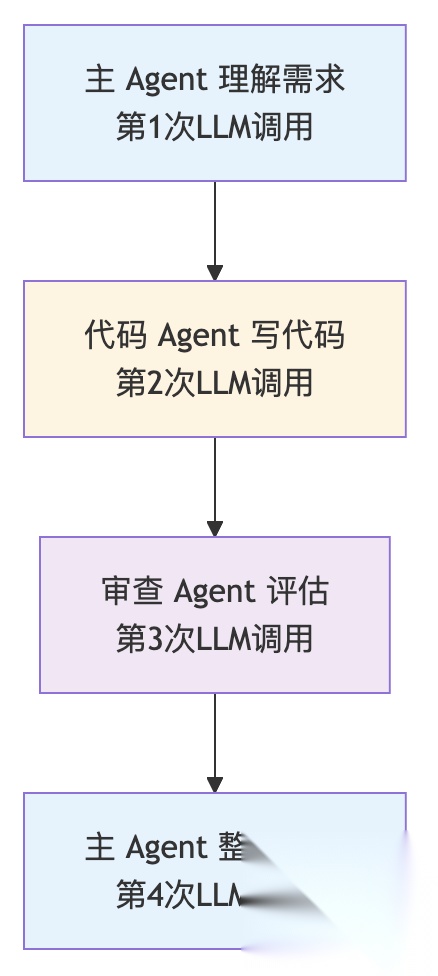
每个 Agent 都是完全独立的 LLM 实例,有自己的推理过程、角色设定,甚至可以用不同的模型。
Skills 模式像查阅参考书:
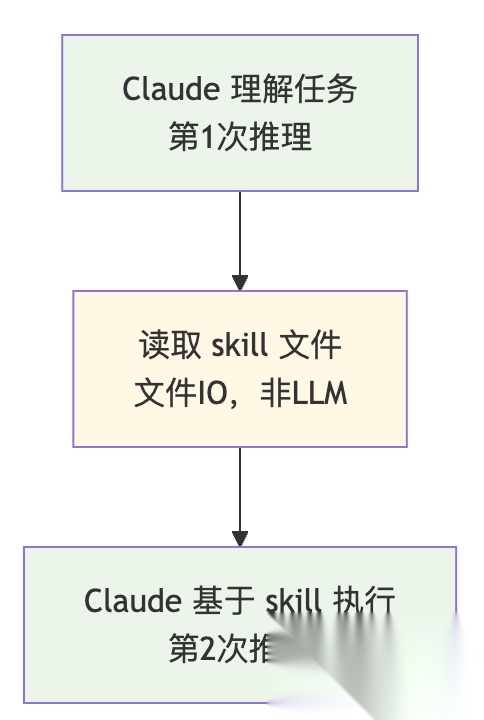
虽然也有多次 LLM 调用,但关键区别是:
- 始终是同一个 Claude 实例在思考
- 上下文是连续的,不需要在不同实例间传递状态
- 角色是一致的,不存在"视角切换"
差异2:调用开销——轻量 vs 重量
Sub-Agent 的每次调用:
- 加载完整模型
- 构建独立的系统提示词
- 完整的推理生成过程
- 每次都是"重新开始思考"
Skills 的工具调用:
- 第一次:理解任务(LLM 推理)
- 中间:读取文件(简单的文件 IO,几乎零成本)
- 第二次:基于加载的知识执行(LLM 推理)
两次调用之间状态是保持的。第二次推理时 Claude 清楚地知道:
- “我刚才理解了什么”
- “我加载了什么 skill”
- “我现在要做什么”
而 Sub-Agent 模式中,每个 Agent 是独立的,需要通过消息传递来"告诉"下一个 Agent 发生了什么。
差异3:状态管理——单体简单性 vs 分布式难题
Sub-Agent 面临的挑战:
- 如何在不同 Agent 之间共享上下文?
- 如果代码 Agent 发现了一个问题,研究 Agent 怎么知道?
- 如何避免信息在传递过程中丢失或曲解?
这需要复杂的状态管理机制:共享内存、消息队列、事件总线。这也是 LangGraph、CrewAI 这些框架显得复杂的原因。
Skills 的状态管理:
- 所有 skills 加载到同一个上下文中
- Claude 能"看到"所有信息
- 不需要额外的状态同步机制
这就是单体架构的优势。
4.3 更准确的类比
Skills 更像是"带中断的单次会话":
想象你在咨询一个专家:
- 传统方式:专家脑子里装着所有知识,直接回答你
- Skills 方式:专家说"等一下,让我查查资料"(加载 skill),然后基于资料继续回答
虽然有"暂停-查资料-继续"的过程,但还是同一个专家在回答,对话上下文是连续的。
- Sub-Agent 方式:你先问专家 A,专家 A 说"这个我不懂,你去问专家 B",专家 B 给了答案后,你再回来问专家 A 要结论
每次换人,就需要重新解释背景。
4.4 用代码来理解
# Skills 模式(懒加载)
def handle_task(task):
# 第一次推理:分析任务
skill_needed = analyze_task(task) # LLM 调用
# 加载模块(文件读取,非 LLM)
skill_content = load_skill(skill_needed)
# 第二次推理:使用加载的知识执行
result = execute_with_skill(task, skill_content) # LLM 调用
return result
# Sub-Agent 模式(独立进程)
def handle_task(task):
plan = planner_agent.think(task) # 新进程,LLM 调用
code = coder_agent.implement(plan) # 新进程,LLM 调用
review = reviewer_agent.check(code) # 新进程,LLM 调用
return review
关键差异:Skills 的多次调用是同一个进程的暂停-恢复,Sub-Agent 是多个独立进程的通信。
五、从 Skills 到智能编排:技术演进趋势
Skills 能进化成 Sub-Agent 吗?完全可以,而且可能已经在这条路上了。
5.1 现有的编排逻辑
Claude 的 System Prompt 里有这样一段指导:
“Claude 在使用计算机工具完成任务时,首要任务是检查可用的 skills,判断哪些与当前任务相关,然后再采取行动。”
这已经是一种简单的编排逻辑:

5.2 未来可能的演进
阶段一:智能规划
Claude 不仅判断"需要哪个 skill",还能规划"以什么顺序使用这些 skills"。
比如:“先用 data skill 分析数据,再用 visualization skill 制图,最后用 pptx skill 制作演示”
阶段二:分步执行
对于复杂任务,Claude 可能会多次调用自己:
阶段三:自我反思
在每个步骤之后,Claude 评估结果质量。如果不满意,重新加载相关 skill 并调整策略,形成"规划-执行-反思"的闭环。
到了这个阶段,Skills 机制就真正进化成了一个 Agent 框架。但与传统 Sub-Agent 不同的是,这个框架仍然保持了单体架构的简单性——所有的"协作"都发生在同一个 Claude 实例的多轮对话中。
5.3 三代架构对比
第一代:Monolithic Prompt
- 所有知识塞在一个超长 Prompt 里
- 简单直接,但 Token 浪费严重
- 修改困难,牵一发动全身
第二代:Skills(现在)
- 知识模块化,按需加载
- Token 效率提升,可维护性增强
- 仍然是单个实例推理
第三代:智能编排(未来)
- 可能演变成多 Agent 协作
- 支持复杂任务的自动分解
- 在保持效率的同时提升能力上限
这和软件架构的演进路径很像:单体应用 → 模块化设计 → 微服务架构
5.4 这种演进的优势
- 简单任务:单次调用,零额外开销
- 中等任务:2-3 次调用,轻量级编排
- 复杂任务:多次调用,完整的 Agent 工作流
- 即使是多轮调用,仍然是同一个对话历史
- 不需要复杂的状态传递机制
- 用户体验更加流畅
- 只在真正需要时才进行多次调用
- 不像传统 Sub-Agent 那样每个任务都要启动多个实例
- 对于大规模部署来说,成本差异巨大
六、架构选择要点
根据任务复杂度选择架构:
| 纯 Skills | 单一任务、明确目标 | 简单、成本低、延迟小 | 只能处理简单任务 |
| Skills + 编排 | 多步骤任务、需要规划 | 中等复杂度、成本可控 | 需要设计任务分解 |
| 完整 Sub-Agent | 高度复杂、需要协作 | 能力上限高、支持并行 | 复杂度高、成本高 |
选择原则:
七、总结:三个核心洞察
1. 模块化是应对复杂性的根本策略
无论传统软件还是 AI 系统,模块化都是核心:
- 清晰的边界让系统更易理解
- 独立的模块可以单独优化
- 标准化的接口支持灵活组合
Skills 的本质就是将 AI 能力模块化。
2. 没有完美方案,只有合适的权衡
关键问题不是"哪个架构更好",而是:
- 你的任务复杂度在什么层级?
- 你能接受的成本上限是多少?
- 用户对延迟有什么要求?
根据这些问题的答案选择架构,而不是追逐最新技术。
3. 从简单开始,渐进演进
不要一开始就构建复杂系统:
过早引入复杂性往往弊大于利。
后记
技术架构的选择,本质上是在复杂性和效率之间寻找平衡点。最成功的系统往往不是最复杂的,而是在给定约束下做出了最合理权衡的。
留给你的思考题:
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。 大模型学习流程较短,学习内容全面,需要理论与实践结合 学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)  第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓 





评论前必须登录!
注册