 网硕互联帮助中心
网硕互联帮助中心26年1月来自Meta的论文“What Drives Success In Physical Planning With Joint-embedding Predictive World Models? ”。
人工智能领域长期面临的挑战之一是开发能够解决各种物理任务并能泛化到新的、未见过的任务和环境的智体。一种流行的近期方法是利用状态-动作轨迹训练世界模型,然后将其与规划算法结合使用来解决新任务。规划通常在输入空间中进行,但最近出现一系列方法,这些方法引入在世界模型学习表示空间中进行优化的规划算法,其目标是通过抽象无关细节来提高规划效率。本文将这类模型定义为 JEPA-WM,并研究使这类算法有效运行的技术选择。其提出一项针对几个关键组成部分的全面研究,旨在找到该类模型中的最优方法。用模拟环境和真实世界的机器人数据进行实验,并研究模型架构、训练目标和规划算法如何影响规划的成功率。将研究结果结合起来,提出一种模型,该模型在导航和操作任务中均优于两个已建立的基线模型 DINO-WM 和 V-JEPA-2-AC。
如图总结 JEPA-WM 的训练和规划过程: 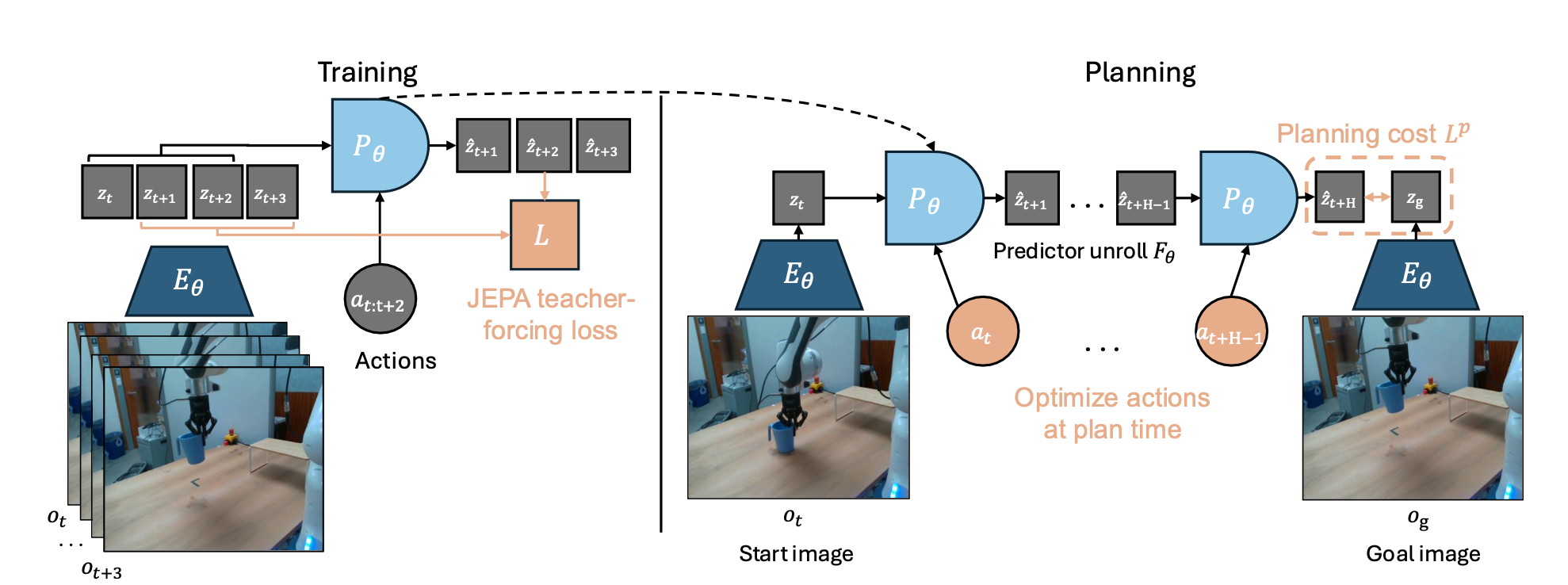
训练方法。在 JEPA-WM 中,用冻结的视觉编码器 Evis_φ 和(可选的)浅层的本体感觉编码器 Eprop_θ 对观测数据进行嵌入。将每个编码器应用于相应的模态构成全局状态编码器,记为 E_φ,θ = (Evis_φ, Eprop_θ)。动作编码器 A_θ 用于嵌入机器人动作。在此基础上,预测器 P_θ 以状态和动作嵌入作为输入。Eprop_θ、A_θ 和 P_θ 联合训练,而 Evis_φ 保持冻结状态。对于过去 w 个观测值 o_t−w:t := (o_t−w, …, o_t),包括视觉输入和(可选的)本体感觉输入以及过去的动作 a_t−w:t,它们在批次 B 个元素上的共同训练预测目标为L。L 作为损失函数,分别计算视觉预测与目标值之间以及本体感觉预测与目标值之间的损失。在实验中,选择 L 作为均方误差 (MSE)。
本研究中编码器和预测器的架构均采用 ViT(Dosovitskiy,2021),与基线模型(Zhou,2024a;Assran,2025)相同。在DINO-WM(Zhou,2024a)中,动作编码器和本体感觉编码器只是线性层,它们的输出沿着嵌入维度与视觉编码器的输出连接起来,这被称为特征条件化(Garrido,2024),这与序列条件化不同。在序列条件化中,动作和本体感觉被编码为token,并与视觉token序列连接起来,V-JEPA-2(Assran,2025)采用这种方法。强调P_θ是使用帧因果注意掩码进行训练的,因此,它同时被训练来预测从w = 0到w = W − 1的所有上下文长度,其中W是一个训练超参,设置为W = 3。因果预测器被训练来预测多个动作的结果,而不仅仅是单个动作的结果。为此,可以跳过 f 个观测值,并将对应的 f 个动作连接起来,形成一个更高维度 f × A 的动作,如 DINO-WM (Zhou et al., 2024a) 中所述。
规划。在 H 时域进行规划是一个在乘积动作空间上的优化问题,其中每个动作的维度为 A,当在训练时使用帧跳跃时,其维度可以设为 f × A。给定初始观测值-目标观测值对 (o_t,o_g),每个动作轨迹 a_t:t+H−1 := (a_t, . . . , a_t+H−1) 都应使用规划目标 Lp 进行评估。与训练时类似,考虑一个相异性度量 L(例如 L_1、L_2 距离或负余弦相似度),该度量成对应用于每个模态,记为 L_vis 表示两个视觉嵌入之间的相异性,L_prop 表示本体感觉嵌入之间的相异性。当使用同时训练本体感觉和视觉输入的模型进行规划时,给定 α ≥ 0,旨在最小化规划目标 Lp_α 。
在此递归地定义 F_φ,θ 为预测器从 z_t = E_φ,θ(o_t) 在动作的展开,最大上下文长度为 w(固定为 Wp)。
在例子中,将 G_φ,θ 取为展开函数 F_φ,θ,但也可以选择 G_φ,θ 为所有中间展开步的函数,而不仅仅是最后一步。
基本配置是无本体感觉的DINO-WM,配备ViT-S编码器和相同嵌入维度的深度-6预测器。根据设计选择的影响范围对其进行优先级排序:规划时的选择会影响所有评估,因此首先优化这些选择,并为每个环境固定最佳规划器用于后续实验;训练和架构选择随后进行。每个组件都独立地相对于基本配置进行调整,以隔离其影响。
规划器。各种优化算法都可用于解决最小化可微分的规划目标问题。Zhou(2024a);Hansen(2024);Sobal(2025);Assran(2025);Bar(2025)采用交叉熵方法(CEM)(或其变体MPPI(Williams,2015))。由于这是一种基于种群(population)的优化方法,不依赖于成本函数的梯度,引入一个规划器,该规划器可以使用NeverGrad(Bennet,2021)中的任何优化方法。在实验中,选择默认的NGOpt优化器(Anonymous,2024),它被指定为“元”优化器。不调整该优化器的任何参数。
尝试基于梯度的规划器(GD 和 Adam),它们通过反向传播直接优化动作序列。这四个优化器共有的规划超参包括:定义与预测器相关的成本函数 G_θ、规划时域 H、在环境中执行的规划动作数量 m ≤ H 以及输入到预测器中过去预测结果的最大滑动上下文窗口大小 Wp。CEM 和 NG 或 Adam 和 GD 共有的超参包括:并行评估成本的候选动作轨迹数量 N 以及并行成本评估的迭代次数 J。在探索 CEM 和 NG 共有的规划超参对成功率的影响后,将它们固定为相同值。用 L_1 或 L_2 嵌入空间距离作为成本 Lp_α 中的相异性度量 L。
模型预测控制 (MPC)。在元世界中,执行 MPC,该过程允许在环境中执行规划后进行重规划。将环境中可执行的最大动作数设置为 100,这构成一个episode。在episode的每个规划步骤中,用交叉熵方法 (CEM) 或 NG 规划器。
交叉熵方法。CEM 优化算法与算法 1 相同。本质上,拟合具有对角协方差的时变多元高斯分布的参数。

NG 规划器。设计一个程序,可以使用任何 NeverGrad 优化器来实现规划目标 Lp_α(o_t,a_t:t+H−1,og),并行评估的动作轨迹数量和总预算与 CEM 相同,详见算法 2。在本研究考虑的所有评估设置中,NGOpt 元优化器始终选择具有特定参数化的 CMA-ES 算法的对角变型。当搜索空间较大时,建议使用 CMA 的对角版。尝试对角 CMA 算法的其他参数化后,例如其精英版(缩放因子为 0.895 而不是默认值 1),在 Wall、Maze 和 Push-T 任务上的成功率可能会下降 20%。 
梯度下降规划器。还尝试基于梯度的规划器,这些规划器通过反向传播直接优化动作序列。与基于采样的方法(CEM、NG)不同,这些规划器利用世界模型的可微性来计算规划目标 Lp_α相对于动作的梯度。梯度下降 (GD) 规划器首先将动作初始化为标准高斯分布(按 σ_0 缩放)或零,然后以学习率 λ 执行 J 次梯度下降。每次梯度下降后,都会向动作添加标准差为 σ_noise 的高斯噪声,以鼓励探索并帮助跳出局部最小值。动作裁剪用于限制特定动作维度。默认超参为:J = 500 次迭代,λ = 1,σ_0 = 1,σ_noise = 0.003。
Adam 规划器。Adam 规划器扩展 GD 规划器,使用 Adam 优化器代替传统的随机梯度下降。 Adam 算法维护梯度(一阶矩)和梯度平方(二阶矩)的指数移动平均值,从而提供更稳定的优化动态特性。默认超参为 β_1 = 0.9,β_2 = 0.995,ε = 10⁻⁸,其他参数的默认值与 GD 算法相同(J = 500,λ = 1,σ_0 = 1,σ_noise = 0.003)。
多步展开训练。在每次训练迭代中,除了逐帧教师强制损失之外,还计算额外的损失项,作为 k 步展开损失 L_k,其中 k ≥ 1。L_1 = L。在实践中,执行时间截断反向传播 (TBPTT)(Elman,1990;Jaeger,2002),这意味着舍弃累积梯度来计算 zˆ_t+H,并且仅反向传播最后一次预测的误差。将使用损失项之和直至 L_k 损失训练的模型表示为 k 步模型。训练的模型最多使用 6-步损失,这需要比默认值 W = 3 更大的上下文大小,因此设置 W = 7 来进行训练,这与之后引入的 W 值增大的模型类似。
本体感觉。将 DINO-WM 的标准设置(Zhou,2024a)与仅使用视觉输入的设置进行比较。在 DINO-WM 中,联合训练本体感觉编码器、预测器和动作编码器。与 V-JEPA-2-AC 不同,同时使用视觉损失项和本体感觉损失项来训练预测器、本体感觉编码器和动作编码器。 训练上下文大小。旨在测试允许预测器在训练时看到更长的上下文是否能够更好地展开更长的动作序列。测试 W = 1 到 W = 7 的值。 编码器类型。正如 Zhou(2024a)所提出的,局部特征保留对解决当前任务至关重要的空间细节。因此,使用DINOv2和最近提出的DINOv3(Siméoni,2025)的局部特征,后者在密集任务上表现更佳。在视频编码器(即V-JEPA(Bardes,2024)和V-JEPA-2(Assran,2025))之上训练预测器。考虑的是ViT-L版本。在探索帧编码策略后,最终选择性能最佳的策略,该策略包括复制o_t−W+1, …, o_t+1帧,并将每对帧独立编码为一个2-帧视频。帧预处理和编码过程均已优化,以确保每个时间步的视觉嵌入标记数量相同,因此主要区别在于直接使用的编码器的权重。
预测器架构。Zhou(2024a)的预测器架构与Assran(2025)的预测器架构的主要区别在于,前者使用特征条件化,并采用sincos位置嵌入;而后者则使用RoPE进行序列条件化(Su,2024)。在前一种架构中,动作嵌入A_θ(a)与视觉特征E_θ(o)沿嵌入维度连接,预测器的隐维度从D增加到D+f_a,其中f_a为动作的嵌入维度。然后,这些特征使用3D sincos位置嵌入进行处理。在后一种架构中,动作被编码为单独的tokens,并与视觉tokens沿序列维度连接,保持预测器的隐维度为D(与编码器相同)。旋转位置嵌入(RoPE)用于预测器的每个模块。还测试一种将特征条件化与RoPE相结合的架构。另一种高效的条件化技术是AdaLN(Xu,2019),Bar(2025)也采用这种方法,在此使用RoPE对其进行测试。这种方法允许动作信息影响预测器的所有层,而不仅仅是输入层,从而有可能防止动作信息在网络中消失。还研究AdaLN-zero变型(Peebles&Xie,2023),将条件化MLP初始化为输出零向量,使得预测器在训练开始时表现得像一个无条件ViT模块。
模型规模化。用带寄存器的DINOv2 ViT-B和ViT-L(Darcet,2024)将编码器大小增加到ViT-B和ViT-L。随着编码器大小的增加,预期预测任务会变得更难,因此需要更大的预测器。因此,相应地增加预测器的嵌入维度以匹配编码器。还研究预测器深度的影响,将其从 3 到 12 变化。
评估设置
数据集。对于元世界,通过训练 TD-MPC2(Hansen,2024)在线智体来收集数据集,并评估两个任务:“Reach”和“Reach-Wall”,分别记为 MW-R 和 MW-RW。用Zhou(2024a)发布的离线轨迹数据集,即 Push-T(Chi,2023)、Wall 和 PointMaze。每个数据集的训练集占比均为 90%。在 DROID 数据集(Khazatsky,2024)上进行训练,并通过定义自定义的取放任务(即“Place”和“Reach”,分别记为 Rc-Pl 和 Rc-R),在 Robocasa 数据集(Nasiriany,2024)上进行零样本评估。这些任务基于远程操控轨迹。没有在 Robocasa 轨迹上对 DROID 模型进行微调。此外,还使用一组 16 个在实验室拍摄的真实 Franka 机械臂的视频进行评估,该视频更接近 DROID 分布,并将此任务记为 DROID。在 DROID 任务中,跟踪规划器输出的动作与定义初始状态和目标状态的数据集中轨迹的真实动作之间的 L_1 误差。然后,重新调整该动作误差的倒数,得到动作得分,这是一个需要最大化的指标。
目标定义。从 Metaworld 提供的专家策略中采样目标帧,从 Push-T、DROID 和 Robocasa 的数据集中采样目标帧,并从 Wall 和 Maze 的随机 2D 状态采样器中采样目标帧。对于具有本体感觉的模型,用本体感觉嵌入距离进行规划,方法是将规划目标函数中的 α 设置为 0.1,但 DROID 和 Robocasa 除外,将其 α 设置为 0,以便与 V-JEPA-2-AC 进行比较。
指标。主要追求最大化的是成功率,但也跟踪其他几个指标,这些指标独立于规划过程跟踪世界模型的质量,并且比成功率噪声更小。这些指标包括预测器展开过程中的嵌入空间误差、展开过程中的本体感觉解码误差、开环展开的视觉解码(以及这些解码与真实未来帧之间的 LPIPS)。
统计显著性。为了考虑训练过程中的变异性,在最终模型中,每个模型使用 3 个种子进行训练。为了考虑评估过程中的变异性,在每个 epoch,启动 e = 96 个 episode,每个 episode 都具有不同的初始状态和目标状态,这些状态要么来自数据集(Push-T、Robocasa、DROID),要么由模拟器(Metaworld、PointMaze、Wall)生成。对于 DROID,采用 e = 64 进行评估,这对于获得可靠的评估结果至关重要,即使比较的是连续动作得分指标。对于 Robocasa,由于其规划 episode 的成本较高(需要重规划 12 次),设置 e = 32。对这些 episode 取平均值以获得成功率。尽管在每个 epoch 中对三个种子及其评估 episode 的成功率取平均值,但整个训练过程中存在较大的变异性。因此,为了获得每个模型的综合得分,对最后 n 个训练 epochs的成功率取平均值,所有数据集的 n = 10,但 DROID 数据集上训练的模型除外。






评论前必须登录!
注册