 网硕互联帮助中心
网硕互联帮助中心25年12月来自智元研究的论文“Act2Goal: From World Model To General Goal-conditioned Policy”。
以既富表现力又精确的方式描述机器人操作任务仍然是一项核心挑战。虽然视觉目标提供一种简洁明确的任务描述,但现有的目标条件策略由于依赖于单步动作预测而缺乏对任务进展的显式建模,因此在处理长时程操作时往往力不从心。本文提出 Act2Goal,一种通用的目标条件操作策略,它将目标条件视觉世界模型与多尺度时间控制相结合。给定当前观测值和目标视觉状态,该世界模型会生成一个合理的中间视觉状态序列,以捕捉长时程结构。为了将这一视觉规划转化为稳健的执行,引入多尺度时域哈希(MSTH),它将想象的轨迹分解为密集的近端帧(用于细粒度的闭环控制)和稀疏的远端帧(用于锚定全局任务一致性)。该策略通过端到端的交叉注意机制将这些表征与运动控制相结合,从而在保持对局部扰动反应灵敏的同时,实现连贯的长时程行为。 Act2Goal 能够对新物体、空间布局和环境实现强大的零样本泛化能力。进一步通过基于 LoRA 的微调实现事后目标重标记,从而实现无奖励的在线自适应,无需外部监督即可快速自主改进。真实机器人实验表明,Act2Goal 在自主交互几分钟内,就能将具有挑战性的非分布任务的成功率从 30% 提高到 90%,验证具有多尺度时间控制的目标条件世界模型能够提供结构化指导,这对于稳健的长时程操作至关重要。
世界模型已成为机器人控制领域的一项强大工具,它使智体能够模拟环境动态[26, 27, 28]、生成用于训练的合成数据[29, 30],或作为学习型模拟器来指导策略学习[31, 32]。近期研究进一步将世界模型与动作专家(AE)相结合,构建策略规划系统[33, 34, 12, 11],其中世界模型提供未来状态特征,而动作专家则据此预测动作。
在这些方法中,GE-Act[13]采用双模型架构,其世界模型基于语言指令预测未来视觉特征,而基于Transformer的规划器则生成动作。WorldVLA[35]在统一的潜空间中联合预测视觉和动作,旨在实现更紧密的视觉-动作对齐。
与以往工作不同,Act2Goal利用纯粹基于视觉的目标条件世界模型,通过结构化的视觉轨迹来指导策略学习。
其框架旨在解决长期目标条件操控中的两个关键挑战:使动作策略与高层目标语义保持一致,以及在较长时间尺度上保持规划效率。如图所示,通过引入目标条件世界模型 (GCWM) 来应对第一个挑战,该模型利用想象的未来视觉信息来指导策略,从而提供丰富且时间连贯的表示。为了应对第二个挑战,提出多尺度时域哈希 (MSTH),它通过结构化的时间抽象,使策略能够同时关注短期执行和长期目标觉察。 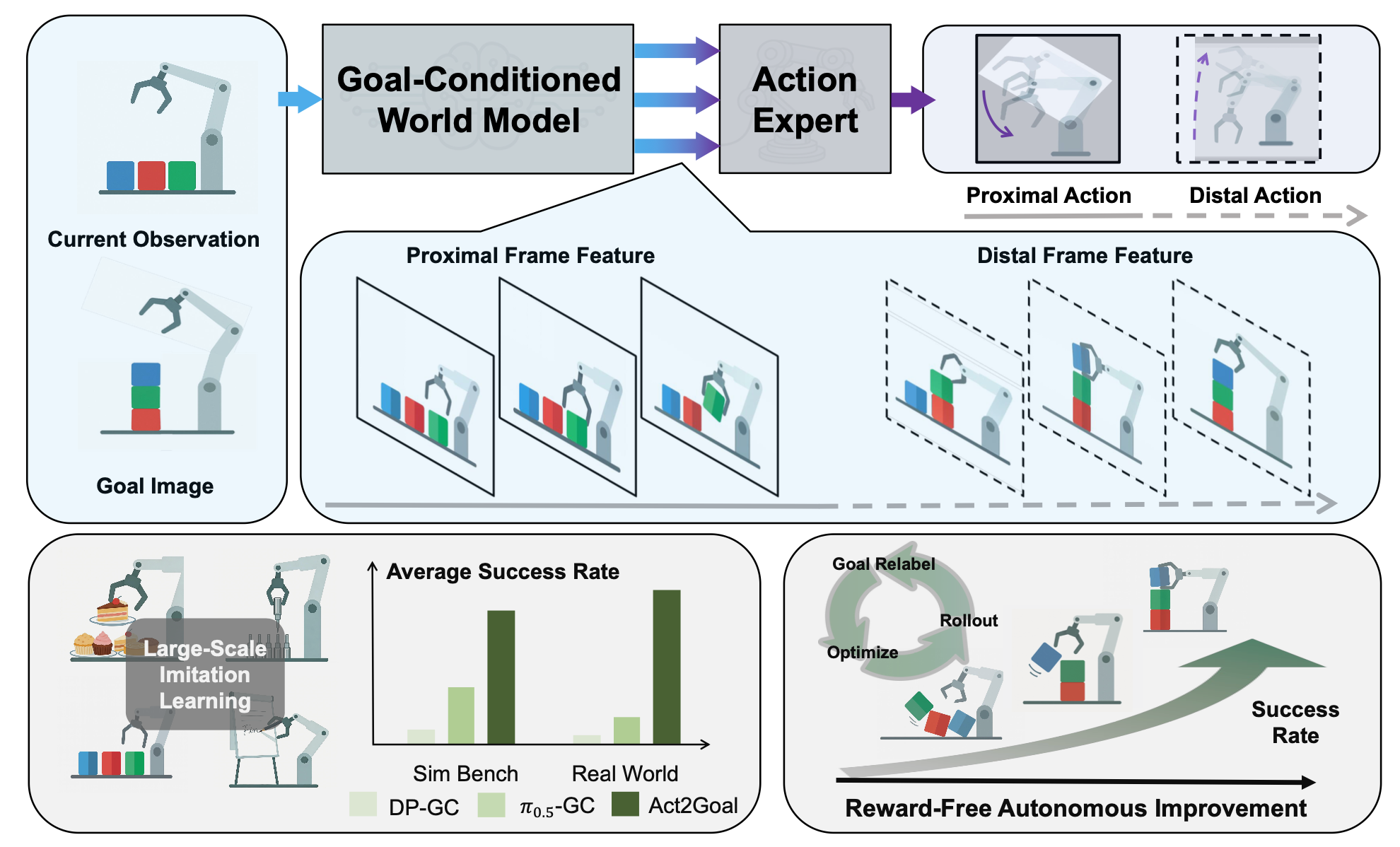
学习过程包含三个阶段。第一阶段对 GCWM 和动作专家进行联合训练,以使其表示保持一致。第二阶段侧重于动作自适应,进一步提升策略的性能。第三阶段引入可选的自主改进机制,使模型能够在部署过程中适应新的场景。
基于目标条件的世界模型引导策略
如图所示,目标条件世界模型基于 Genie Envisioner 架构[13],并针对目标条件策略学习进行关键性修改。引入一个目标视觉条件,该条件与当前观测值沿隐状态序列连接,同时移除所有语言条件组件,从而创建一个纯粹基于视觉的模型。 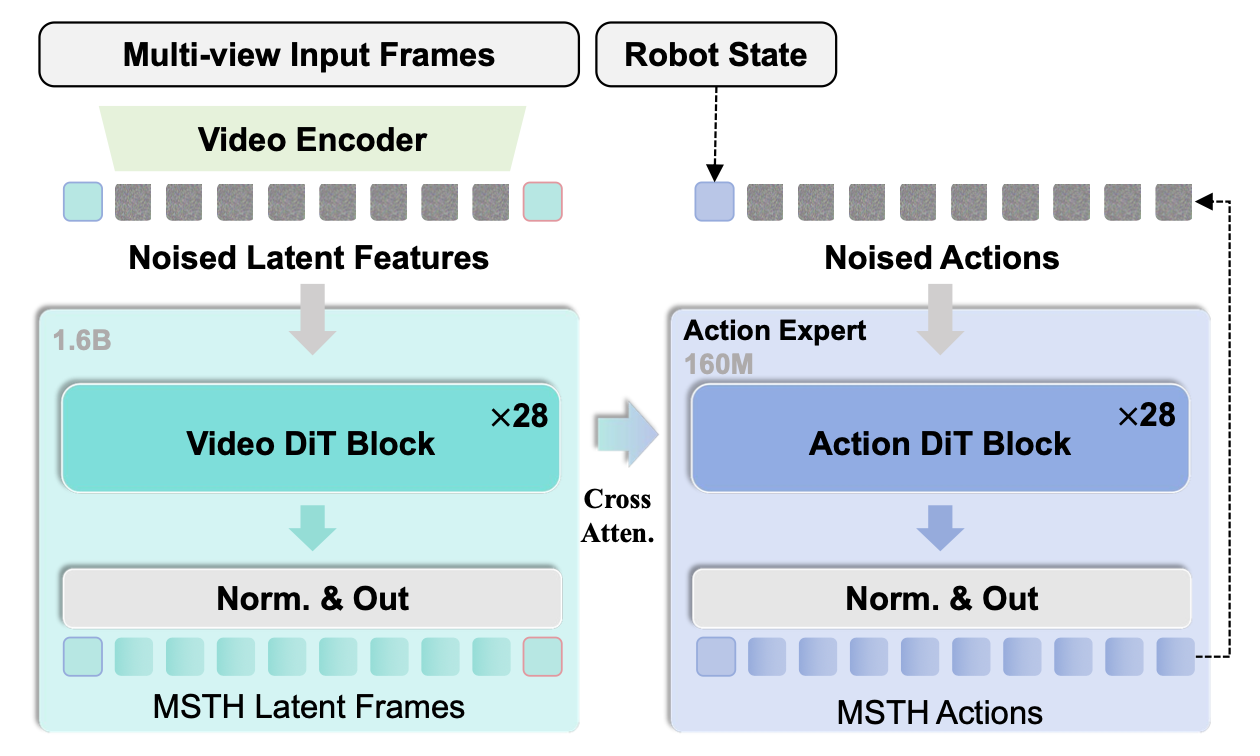
目标条件世界模型采用连续流匹配方法进行生成建模。该过程可以抽象为学习从随机噪声到结构化视觉序列的转换,该转换以当前观测值和目标状态为条件。
在推理过程中,模型通过确定性的流过程逐步细化噪声潜变量。使用 VAE 解码器可以将已完成的潜帧解码为视觉状态。
遵循 GE-Act 的实现方式 [13],动作专家采用一种与世界模型同构的网络架构,该架构包含相同数量的 DiT 模块,但网络宽度有所减小。动作轨迹的预测基于一个流匹配过程,该过程以本体感受状态 c_p 和来自世界模型的多尺度特征 c_w 为条件。在动作推理过程中,流匹配过程遵循一个迭代改进原则。
用于视觉状态和动作的多尺度时域哈希
在框架中,多尺度时域哈希(MSTH)机制共同指导目标条件化的世界模型和动作专家,从而实现一致且灵活的多尺度时间抽象。给定总的想象轨迹长度 K、近端视野 P 和视觉采样步长 r,MSTH 将未来轨迹划分为两个部分。
近端部分由高频短视野视觉状态 {s_t+kr} 组成,用于捕捉精细的局部动态。远端部分包含 M 个稀疏采样的视觉状态 {s_t+d_m},其中索引 d_m 由对数间隔确定。这种对数采样使得随着视野的扩展,时间间隔逐渐增大,从而提供粗略但与目标一致的长期指导。
预测的动作序列遵循相同的多尺度结构,但与视觉存在重要区别。近端动作在每个时间步都会被预测,{a_t+1, a_t+2, …, a_t+P},即使视觉状态被步幅子采样,也能实现精细的运动控制。相比之下,远端动作{a_t+d_m}与远端视觉状态对齐,并作为长时程的指导。在部署过程中,仅执行近端动作,而远端预测保持潜状态,并指导长期目标的达成。
两阶段离线训练
为了赋予 Act2Goal 强大的泛化能力,首先通过大规模离线模仿学习来训练模型。训练过程分为两个主要阶段,旨在确保过渡轨迹预测目标与指导动作规划的最终目标紧密契合。
在第一阶段,对预训练的世界模型进行微调,使其适应过渡轨迹预测任务,即根据初始观测值和目标条件之间的 MSTH 分布生成多视角视频帧。为了增强过渡轨迹预测和动作规划目标之间的契合度,用流匹配联合训练过渡轨迹预测任务和动作生成任务。
视觉生成组件的训练目标遵循流匹配损失公式。联合训练目标结合两个损失,并引入平衡系数 λ:L_stage1 = L_v + λ·L_a。这种联合优化确保目标导向的世界模型能够学习生成不仅在视觉上合理,而且可执行的视觉轨迹,从而为后续的策略学习阶段奠定坚实的基础。
在第二训练阶段,采用行为克隆技术,仅使用动作流匹配损失 L_stage2 = L_a 对整个模型进行端到端的微调,进一步增强其动作规划能力。该阶段的重点在于使从视觉感知到动作执行的整个流程与专家演示保持一致。动作损失的梯度会同时传递到动作生成组件和目标导向的世界模型中,从而实现针对动作规划的视觉表征优化。
这种两阶段离线训练方法使 Act2Goal 能够获得强大的世界理解和动作生成能力,并能有效地迁移到未见过的环境和任务中。
在线自主改进
尽管该模型在离线模仿学习后展现出强大的泛化能力,但在部署到物理机器人上时,如何在新的任务、环境、物体和运动控制链上实现高性能仍然是一个挑战——这是基于模仿学习策略的常见局限性。为了解决这个问题,引入一种基于后见之明经验回放(HER)的在线自主改进框架,从而能够在部署过程中实现自主性能提升[14]。
如算法1所示,系统运行如下:对于给定的预期目标条件,模型进行推理并执行动作。每个推理步骤——包括起始观测潜变量、初始本体状态、输出动作以及执行后的观测潜变量——都会自动收集到边缘设备的回放缓冲区中。关键在于,无论转换是否成功达到预期目标,都会在推理步骤结束时自动将目标条件重标记为机器人的观测值,从而无需手动标记转换。当回放缓冲区达到预设容量阈值时,采用与离线模仿学习第二阶段相同的方法,利用缓冲区转换执行固定次数的端到端训练迭代。为确保高效的设备端训练,Act2Goal模型中仅更新新增的LoRA层,而基础模型参数保持不变[15]。完成固定迭代次数的训练后,清空回放缓冲区,系统通过滚动更新继续收集新数据,重复此循环直至性能达到预期。其为不同任务设置最大推理次数;超过此阈值将触发机器人自动重置。在实际机器人实验中,唯一需要的人工干预是在必要时手动恢复或修改实验装置。 






评论前必须登录!
注册