 网硕互联帮助中心
网硕互联帮助中心在二分类任务中,模型性能不能仅通过准确率进行衡量,而需要基于混淆矩阵对预测结果进行更细粒度分析。TP、FP、FN、TN 构成了评价体系的基础,并进一步推导出 Precision、Recall、F1-score 与 AUC 等核心指标。本文将围绕这些指标的定义与计算方法进行技术层面的系统说明。
一、混淆矩阵(Confusion Matrix)
在二分类任务中,模型的预测结果只有两种取值:正类(Positive)与负类(Negative)。
为了系统地分析模型的预测情况,需要将“预测结果”与“真实标签”进行交叉统计,这种统计结构就是混淆矩阵。
混淆矩阵本质上是一个 2×2 的统计表,用于描述模型预测与真实情况之间的对应关系。
| 实际为正类 | TP | FN |
| 实际为负类 | FP | TN |
1️⃣ 四个核心变量含义
TP(True Positive)
真实为正类,模型也预测为正类。
表示“正确识别出的正样本”。
FP(False Positive)
真实为负类,但模型预测为正类。
表示“误报”。
FN(False Negative)
真实为正类,但模型预测为负类。
表示“漏报”。
TN(True Negative)
真实为负类,模型也预测为负类。
表示“正确识别出的负样本”。
2️⃣ 从概率角度理解
设数据集中共有:
-
正样本数量:P
-
负样本数量:N
则:
P=TP+FN
N=TN+FP
总样本数:
Total=TP+TN+FP+FN
混淆矩阵实际上刻画的是:
-
正样本被分到正类或负类的分布
-
负样本被分到正类或负类的分布
因此它本质上描述的是一个二分类决策边界的误差结构。
二、Accuracy(准确率)
Accuracy 是最直观的评价指标,用于衡量模型整体预测正确的比例。
1️⃣ 数学定义
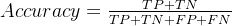
表示模型预测正确的样本比例。
其中:
-
分子:预测正确的样本数量
-
分母:样本总数
2️⃣ 技术理解
Accuracy 衡量的是:
模型整体预测正确的比例
但它并不区分错误类型。
例如:
-
1000 个样本
-
990 个为负类
-
模型全部预测为负类
则:
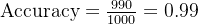
但模型实际上完全没有识别正类。
因此,在类别严重不平衡时,Accuracy 可能失去参考意义。
三、Precision(精确率)
Precision(精确率)用于衡量模型预测为正类的样本中,有多少是真正的正类。
它回答的问题是:
当模型“判断为正类”时,它有多大概率是正确的?
换句话说,Precision 关注的是预测结果的可信度。
1️⃣ 数学定义
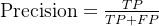
其中:
-
分母:模型预测为正类的样本总数
-
分子:其中真实为正类的数量
2️⃣ 技术理解
Precision 衡量的是模型的误报控制能力。
如果 Precision 很高,说明:
-
模型预测为正类时通常是对的
-
误报(False Positive)较少
如果 Precision 很低,则说明:
-
模型经常把负类误判为正类
-
预测结果的可信度较低
Precision 主要关注的是:
FP(假正例)对模型性能的影响
FP 越多,Precision 越低。
3️⃣ 举例说明
假设:
-
模型预测为正类的样本共有 50 个
-
其中 40 个是真正的正类
-
10 个是误判的负类
则:
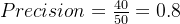
这表示:
模型每预测 100 次正类,大约有 80 次是正确的。
4️⃣ 应用场景
Precision 适用于:
误报(False Positive)成本较高的场景。
如果模型把“负类”错误判断为“正类”会带来严重后果,那么就需要优先关注 Precision。
典型应用包括:
-
垃圾邮件过滤(不能误删正常邮件)
-
金融风控系统(不能误判正常用户为欺诈者)
-
权限认证系统(不能误识别非法用户为合法用户)
-
法律或风控审核系统(误判成本极高)
在这些场景中:
-
宁可少报(Recall 低一点)
-
也不能误报(Precision 必须高)
换句话说:
当“错杀无辜”的代价很高时,应重点关注 Precision。
四、Recall(召回率)
Recall(召回率)用于衡量模型对真实正类样本的识别能力。
它回答的问题是:
在所有真正属于正类的样本中,模型成功找回了多少?
换句话说,Recall 关注的是模型是否“漏掉”了正类样本。
1️⃣ 数学定义
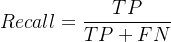
其中:
-
分母:真实正类样本总数
-
分子:被正确识别的正类样本
2️⃣ 技术理解
Recall 衡量的是模型的覆盖能力(Coverage)。
如果一个模型的 Recall 很高,说明:
-
它几乎没有漏掉正类样本
-
对正类的检测能力很强
但这并不意味着模型一定准确,因为它可能会把很多负类也误判为正类(Precision 可能很低)。
因此:
-
Recall 关注的是 漏检问题(FN)
-
FN 越多,Recall 越低
在很多实际应用中,漏检的代价远高于误检。例如:
-
疾病筛查(不能漏掉真正的病人)
-
网络入侵检测(不能漏掉真实攻击)
-
金融欺诈识别(不能放过异常交易)
在这些场景中,高 Recall 往往比高 Accuracy 更重要。
3️⃣ 举例说明
假设:
-
有 100 个真实正类样本
-
模型成功识别出 85 个
-
漏掉 15 个
则:
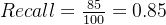
这表示模型找回了 85% 的正类样本。
如果 Recall 很低,比如 0.3,就说明模型漏掉了大量真正重要的样本。
4️⃣ 应用场景
Recall 适用于:
漏报(False Negative)成本较高的场景。
如果模型漏掉真正的正类样本会带来严重后果,那么就必须优先保证 Recall。
典型应用包括:
-
医疗疾病筛查(不能漏掉真正的患者)
-
网络入侵检测(不能放过真实攻击)
-
欺诈检测(不能放过异常交易)
-
故障报警系统(不能漏掉真实故障)
在这些场景中:
-
宁可多报(Precision 低一点)
-
也不能漏报(Recall 必须高)
换句话说:
当“漏掉关键样本”的代价很高时,应重点关注 Recall
五、F1-score
F1-score 是 Precision 与 Recall 的调和平均数。
1️⃣ 数学公式
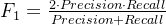
展开形式:
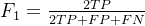
其中:
-
TP:真正例
-
FP:假正例
-
FN:假负例
2️⃣ 技术理解
F1-score 使用的是调和平均数(Harmonic Mean),而不是普通的算术平均数。
调和平均数是一种特殊的平均方式。
对于两个数 aaa 和 bbb,调和平均数定义为:
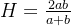
为什么使用调和平均?
因为调和平均会对较小的数值更加敏感。只要其中一个数很小,结果就会被大幅拉低。
这意味着:
-
如果 Precision 很高但 Recall 很低,F1 不会很高
-
如果 Recall 很高但 Precision 很低,F1 也不会很高
-
只有当两者都比较均衡时,F1 才会高
因此,F1-score 强调的是:
模型是否在“误报”和“漏报”之间取得平衡
3️⃣ 举例说明
假设:
-
Precision = 0.9
-
Recall = 0.6
则:
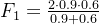
计算结果:
F1 ≈ 0.72
可以看到,即使 Precision 很高,但因为 Recall 较低,F1 也不会特别高。
4️⃣ 应用场景分析
F1-score 特别适用于:
-
类别严重不平衡问题
-
不能单独依赖 Accuracy 的场景
-
同时关注误报与漏报的任务
例如:
-
医疗诊断
-
入侵检测
-
欺诈识别
-
信息检索
在这些任务中,单独使用 Accuracy 可能具有误导性,而 F1-score 能更全面反映模型性能。
六、ROC 曲线
ROC(Receiver Operating Characteristic)曲线用于分析模型在不同分类阈值下的整体表现能力。
分类阈值的意思是:
当模型预测概率 ≥ 阈值时,判为正类
当模型预测概率 < 阈值时,判为负类
例如默认情况下:
阈值 = 0.5
也就是:
-
概率 ≥ 0.5 → 正类
-
概率 < 0.5 → 负类
1️⃣ 数学公式
ROC 曲线本质上就是:
以 FPR 为横轴,TPR 为纵轴,绘制出的曲线。
两个核心指标为
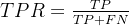
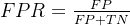
其中:
-
TPR(True Positive Rate):真正率,也就是 Recall
-
FPR(False Positive Rate):假正率
需要注意:
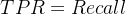
2️⃣ 技术理解
ROC 曲线描述的是:
在不同分类阈值下,模型“查全率”和“误报率”的变化关系。
当阈值降低时:
-
模型更容易判为正类
-
TPR 增大
-
FPR 也增大
当阈值升高时:
-
模型更严格
-
TPR 降低
-
FPR 也降低
理想模型的 ROC 曲线应尽量靠近左上角:
-
左上角点 (0,1) 表示完美分类
-
对角线表示随机分类
ROC 本质上衡量的是模型的整体区分能力,而不是某一个固定阈值下的表现。
3️⃣ 举例说明
假设模型输出概率:
| A | 正类 | 0.9 |
| B | 正类 | 0.7 |
| C | 负类 | 0.6 |
| D | 负类 | 0.2 |
当阈值为 0.5 时:
-
TPR 较高
-
FPR 也会上升
当阈值为 0.8 时:
-
TPR 降低
-
FPR 降低
随着阈值不断变化,每一个阈值都会产生:
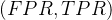
所有这些点连起来:
就形成了 ROC 曲线。
七、AUC(Area Under Curve)
AUC 表示 ROC 曲线下的面积,是对模型整体区分能力的量化指标。
1️⃣ 数学公式
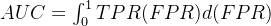
取值范围:
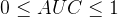
2️⃣ 技术理解
AUC 可以理解为:
随机抽取一个正样本和一个负样本,模型将正样本排在负样本前面的概率。
如果:
-
AUC = 0.5 → 相当于随机猜测
-
AUC 接近 1 → 区分能力强
-
AUC 接近 0 → 模型判断方向完全错误
AUC 衡量的是模型的排序能力,而不是某个固定阈值下的分类结果。
3️⃣ 举例说明
假设:
-
模型对正类样本给出的概率普遍高于负类
-
在大多数情况下,正样本得分 > 负样本得分
则 AUC 会接近 1。
如果:
-
正负样本得分混杂严重
则 AUC 接近 0.5。
总结:指标选择建议
在实际应用中,可以根据任务目标选择指标:
-
类别均衡 → Accuracy 可作为参考
-
误报代价高 → 关注 Precision
-
漏报代价高 → 关注 Recall
-
需要平衡 → 使用 F1-score
-
想评估整体区分能力 → 使用 AUC
在论文或工程实践中,通常会同时报告:
Precision + Recall + F1 + AUC
以全面反映模型性能。









评论前必须登录!
注册