 网硕互联帮助中心
网硕互联帮助中心近期,DeepSeek团队推出的DeepSeek-R1在AI界掀起了波澜。他们通过强化学习与知识蒸馏技术,成功将670B参数的大型模型能力迁移至仅7B参数的轻量级模型中。这一成果不仅超越了同规模的传统模型,还逼近了OpenAI的顶尖小模型OpenAI-o1-mini的表现。知识蒸馏技术在这一过程中的关键作用,正逐步显现为解决AI模型实际应用难题的重要法宝。

知识蒸馏技术深度剖析
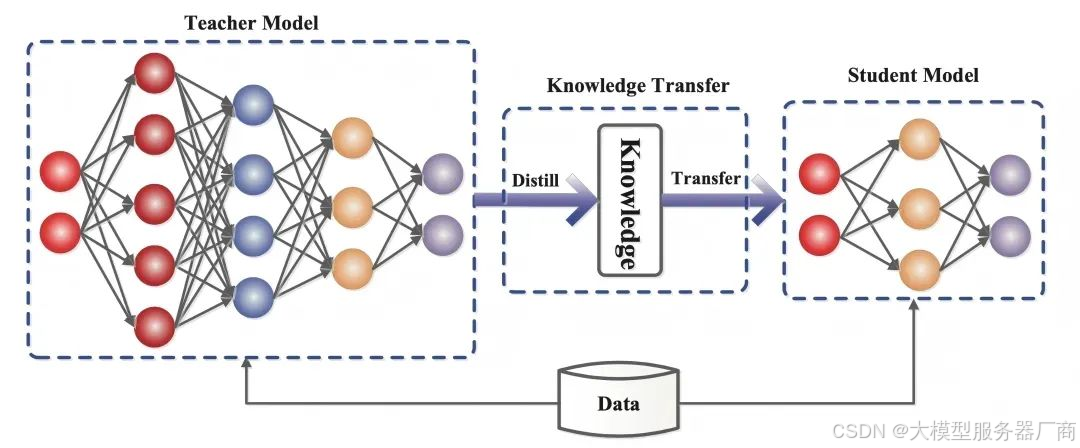
知识蒸馏,作为机器学习领域的一项前沿技术,其核心在于将已经训练成熟的大型模型(即教师模型)的知识智慧,有效地传递给规模较小的“学生模型”。在深度学习的广阔天地里,知识蒸馏以其独特的模型压缩和知识传递能力,为大规模深度神经网络的应用开辟了新路径。
具体过程包括:首先,选取一个性能卓越、泛化能力强的深度学习模型作为教师模型,让它对训练数据集进行预测,生成包含丰富信息的软标签(即概率分布)。随后,初始化一个相对简单的学生模型,其参数选择可灵活多样,如随机选取教师模型的参数或采用其他策略。接着,定义一个损失函数,如Kullback-Leibler (KL) 散度或交叉熵,用于衡量学生模型输出与教师模型软标签之间的差异。为了兼顾准确性,学生模型还需直接学习真实标签。在此过程中,温度参数成为调节软标签平滑程度的关键,温度较高时,概率分布更为平滑,有助于学生模型学习泛化特征;温度较低时,分布则更接近真实标签,便于学习具体信息。最后,在损失函数的指导下,不断训练和优化学生模型,直至其性能达到预期。

GPU在知识蒸馏中的关键角色
在知识蒸馏的复杂过程中,GPU(图形处理器)的重要性不言而喻。无论是教师模型的训练,还是学生模型在模仿教师模型输出时的繁重计算,都离不开GPU强大的计算能力。GPU凭借其庞大的计算核心阵列,能够高效地并行处理多个任务,显著加速了深度学习模型的训练和推理过程。
以DeepSeek-R1为例,将670B参数的大型模型知识迁移到7B参数的模型中,涉及海量的数据计算和复杂的算法运算。在GPU的助力下,这些操作得以在短时间内高效完成,大大缩短了模型训练和蒸馏的时间。若缺乏GPU的并行计算能力,完成如此大规模的模型蒸馏任务将变得异常艰难,甚至可能因耗时过长而无法满足AI研发的高效和快速迭代需求。
服务器:知识蒸馏的坚实后盾
服务器作为AI模型训练和部署的基础设施,在知识蒸馏技术的应用中同样扮演着举足轻重的角色。在模型训练阶段,服务器提供了稳定可靠的运行环境,以及强大的数据存储与处理能力。大规模的训练数据集被妥善存储在服务器的高性能存储设备中,而服务器的CPU(中央处理器)和内存则协同工作,负责数据的调度、管理和传输,与GPU紧密配合,共同推动模型训练的高效进行。
当涉及到多个GPU并行计算时,服务器的网络架构成为决定计算效率的关键因素。高速、低延迟的网络连接确保了多个GPU之间的数据传输畅通无阻,从而提高了整体计算效率。在知识蒸馏过程中,可能需要跨越多台服务器进行分布式训练,此时服务器之间的网络性能便成为影响蒸馏任务进度和效果的重要因素。
在模型部署阶段,服务器的性能同样至关重要。对于经过知识蒸馏的小型模型而言,虽然其计算需求有所降低,但仍需服务器提供稳定的计算资源和网络服务,以满足实时或近实时的推理需求。特别是在移动设备和嵌入式系统等资源受限的环境下,服务器还需对模型进行优化和适配,确保模型能够在这些设备上高效、稳定地运行。
结语:知识蒸馏与硬件设施的协同发展
DeepSeek-R1的成功案例充分展示了知识蒸馏技术的巨大潜力,而GPU和服务器作为底层硬件支撑,为知识蒸馏技术的应用和发展提供了坚实的保障。随着AI技术的不断进步,知识蒸馏技术与硬件设施的协同发展将推动AI模型在更多领域实现更高效、更广泛的应用。未来,我们有理由相信,知识蒸馏技术将在AI的广阔舞台上绽放出更加璀璨的光芒。









评论前必须登录!
注册