 网硕互联帮助中心
网硕互联帮助中心“我们能不能有自己的ChatGPT?” “买不起100张卡,搞不定大数据中心,也能做AI吗?” “一台服务器,到底能撑起多少智能应用?”
别觉得这是幻想,现在越来越多的中小企业,正在用一台服务器,悄悄搭建属于自己的“私有大模型”,跑通从训练、微调到推理落地的全流程。
你以为只有巨头才能搞AI?其实,算力平权时代,刚刚开始。
一、为啥连中小企业都在搞大模型?
2025年以后,“大模型平民化”趋势越来越明显:
-
国内外开源模型井喷:ChatGLM、Baichuan、Yi、LLaMA、Mistral……
-
微调技术门槛大幅降低:LoRA、QLoRA等让训练只需几个小时
-
硬件成本骤降:高性价比显卡如RTX 4090、二手A100市场火热
-
框架生态完善:一键部署、推理服务成熟化(如TextGen WebUI、FastChat、TGI)
一句话总结:不是AI门槛降低了,是“入门的路径”被打通了。
很多中小企业开始意识到:不必等巨头开API,你自己也能部署“企业级智能助手”,而且——数据不出本地,还更安全。
二、最小可行算力方案:卡要选对,别乱烧钱
有人一听部署大模型,脑子里立刻浮现“上百张H100”的景象。其实,不是所有模型都要上云、上集群。
✅ 实战配置推荐(以中小企业/团队级为例):
| 入门级 | RTX 4090 | 24G | Baichuan-7B / ChatGLM2 | 一台机器搞定,性价比王者 |
| 进阶级 | A100 40G(二手) | 40G | ChatGLM3 / Yi-34B | 支持中大型模型推理+微调 |
| 高阶级 | H100(单卡) | 80G | 多模态+高吞吐需求 | 成本高,但能拉满性能 |
📌 注意:
-
一张RTX 4090 + 128G内存 + 2T NVMe SSD,就可以搞定ChatGLM3推理+LoRA微调;
-
若做训练,可考虑两张4090或一张A100,搭配NVLink桥接提升效率;
-
千万别一上来就上集群,先跑通闭环再说!
三、从零搭建私有大模型:一条龙教程
你也可以像下面这样,一步一步搞定私有大模型系统:
✅ Step 1:系统准备
-
Ubuntu 22.04 + CUDA 12.1 + Pytorch 2.1
-
安装Miniconda,隔离环境
-
驱动、依赖一次装全(推荐使用automatic1111或Text Generation WebUI)
✅ Step 2:拉模型
-
去 HuggingFace 下载 ChatGLM3、Baichuan 等权重
-
或使用镜像站(防止速度太慢)
✅ Step 3:微调训练
-
使用QLoRA等低秩微调技术
-
本地跑:以7B模型为例,训练几个小时即可完成特定业务微调(如客服、合规审查等)
✅ Step 4:部署上线
-
使用 FastChat / TGI 等推理服务框架
-
提供 REST API / Web UI 接口,支持企业内部调用
-
可以接入飞书、钉钉等办公平台,打造“企业私有GPT助手”
四、自建 VS 云租:3个月回本的真实案例
一个创业团队做SaaS客服助手,用了下面这套方案:
-
采购硬件:1台双路服务器 + 2张RTX 4090 + 128G内存,总计约5万元
-
本地部署Baichuan2-13B,结合知识库微调
-
替代原先月租2万元的OpenAI调用成本
📊 效果如何?
-
模型响应延迟降低到800ms以内;
-
每月节省调用成本2万+;
-
本地数据不出网,满足合规需求;
-
仅2.5个月实现成本回本。
相比之下,云服务虽然弹性好,但成本高、不可控,数据外传风险更大。
五、别只盯显卡,搞懂“带宽+调度”才是真功夫
在实际部署过程中,很多人踩坑不是因为卡不够,而是忽视了:
⚠️ 数据带宽瓶颈
-
模型推理时,IO和内存带宽可能成为新瓶颈;
-
确保NVMe SSD读写 >3000MB/s,内存带宽充足。
⚠️ 任务调度混乱
-
多任务并发容易造成显卡空转;
-
推荐用CUDA_VISIBLE_DEVICES + nvidia-smi + 轻量化调度脚本,做好任务管理。
⚠️ 散热与电源
-
RTX 4090满负载功耗高达450W;
-
建议配1000W以上金牌电源+风道优化,防止宕机烧卡。
✅ 最后的建议:别怕开始,先做出第一个“小闭环”
说白了,“私有大模型”听着玄,其实就是一次普通IT系统集成 + AI工程实践。
你不需要一开始就做搜索引擎级别的系统,只要:
-
用一张卡跑通模型
-
用一个微调改出效果
-
用一个API完成内部集成
你就比90%的企业快了两步。
🧠 总结一下:
| 硬件选型 | 优先用RTX 4090或A100,H100非刚需 |
| 框架生态 | HuggingFace + FastChat / TGI 最稳妥 |
| 成本控制 | 自建方案回本周期短,性价比更高 |
| 数据安全 | 私有部署最大优势:数据不出企业网 |
| 起步策略 | 从7B模型入手,快速构建第一个智能助手 |
作者声明:本微信公众号(以下简称“本号”)发布的所有内容,包括但不限于文字、图片、视频、音频等,仅供参考和交流之用,不构成任何投资、法律、医疗或其他专业建议。用户在依据本号内容作出任何决定或采取任何行动前,应自行判断并咨询相关专业人士。
1、本号部分内容来源于网络或其他公开渠道,我们尽力确保信息的准确性和可靠性,但不对其真实性、完整性或及时性作出任何明示或暗示的保证。
2、对于转载和参考内容,我们会在合理范围内注明出处。如有版权问题,请相关权利人及时联系我们,我们将尽快处理。
3、用户因使用本号内容而导致的任何直接或间接损失,本号及其运营团队不承担任何责任。
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
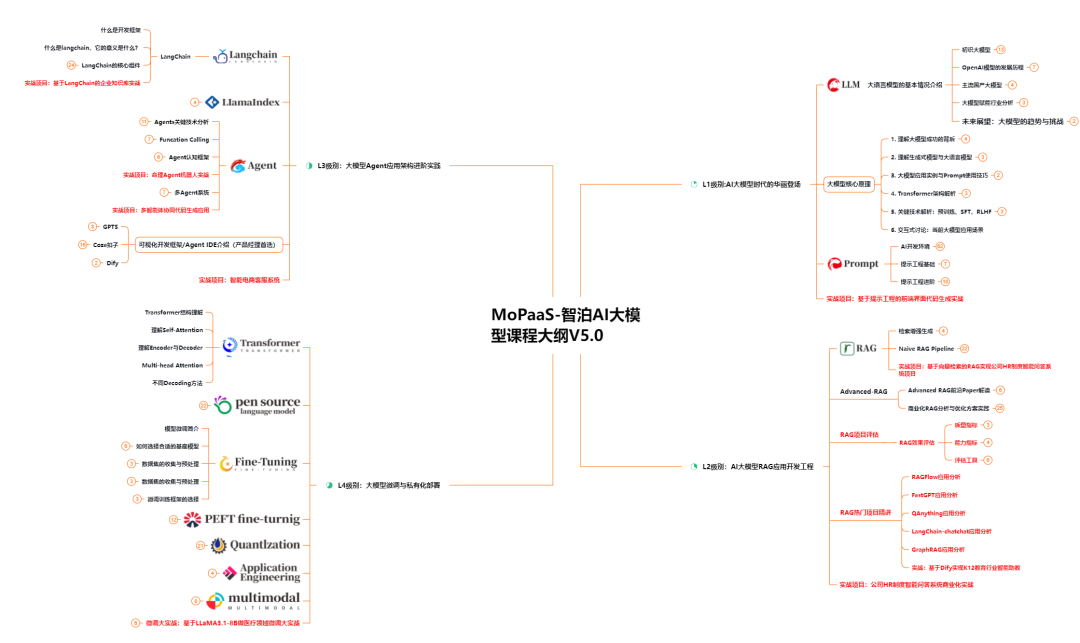
L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。
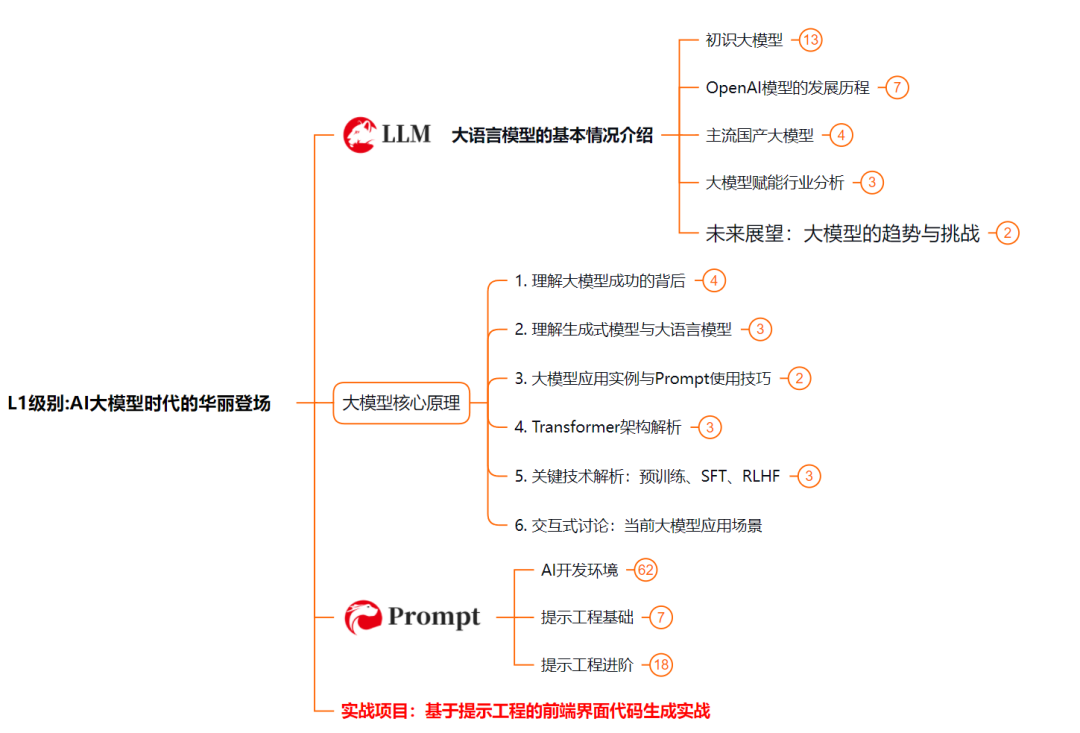
L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
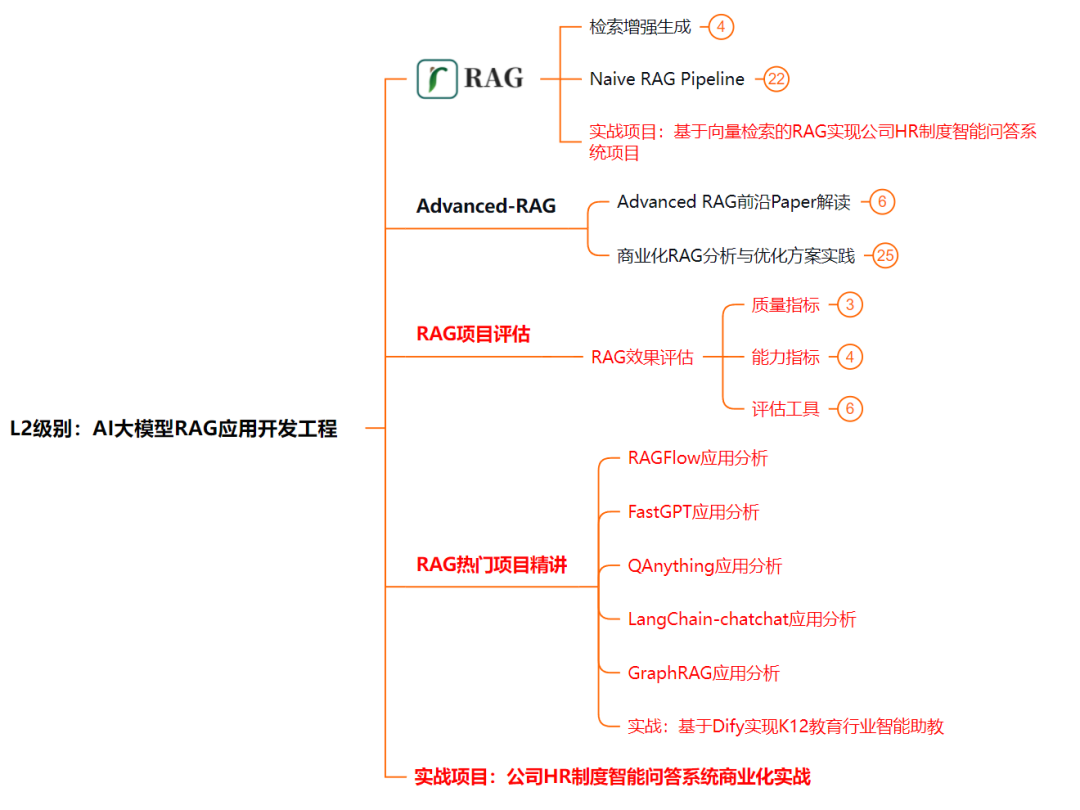
L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
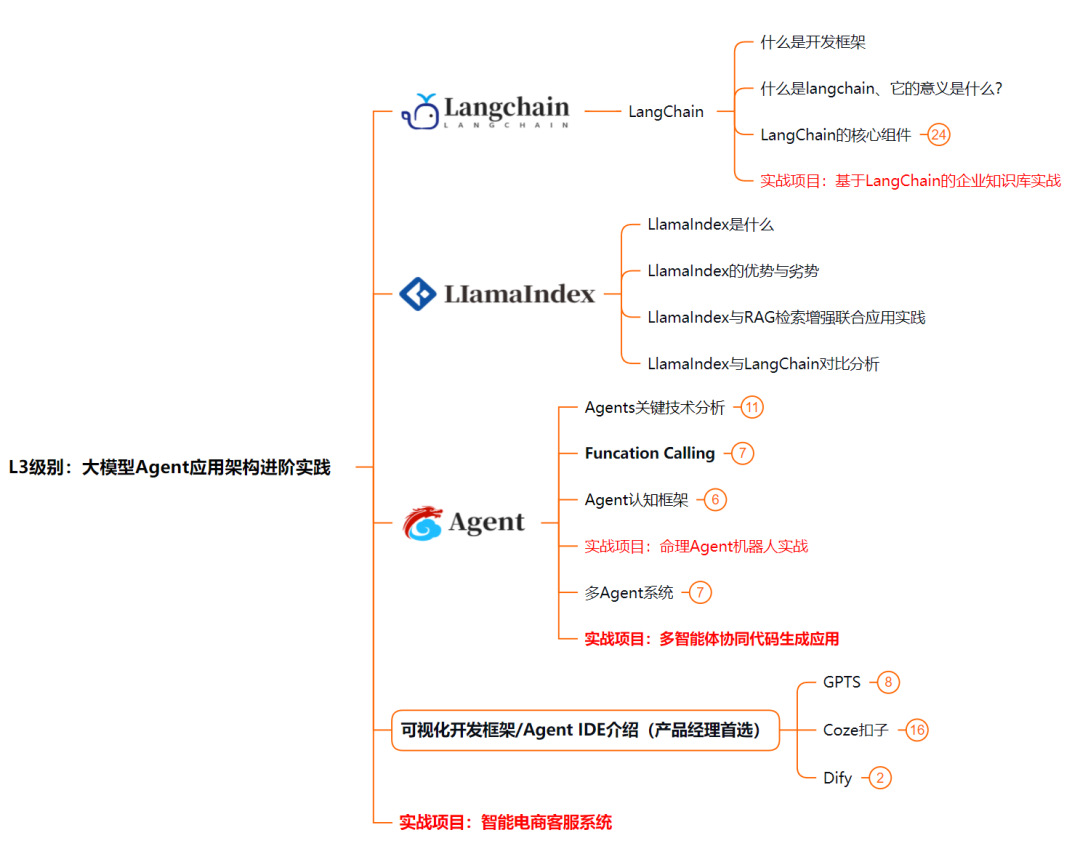
L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
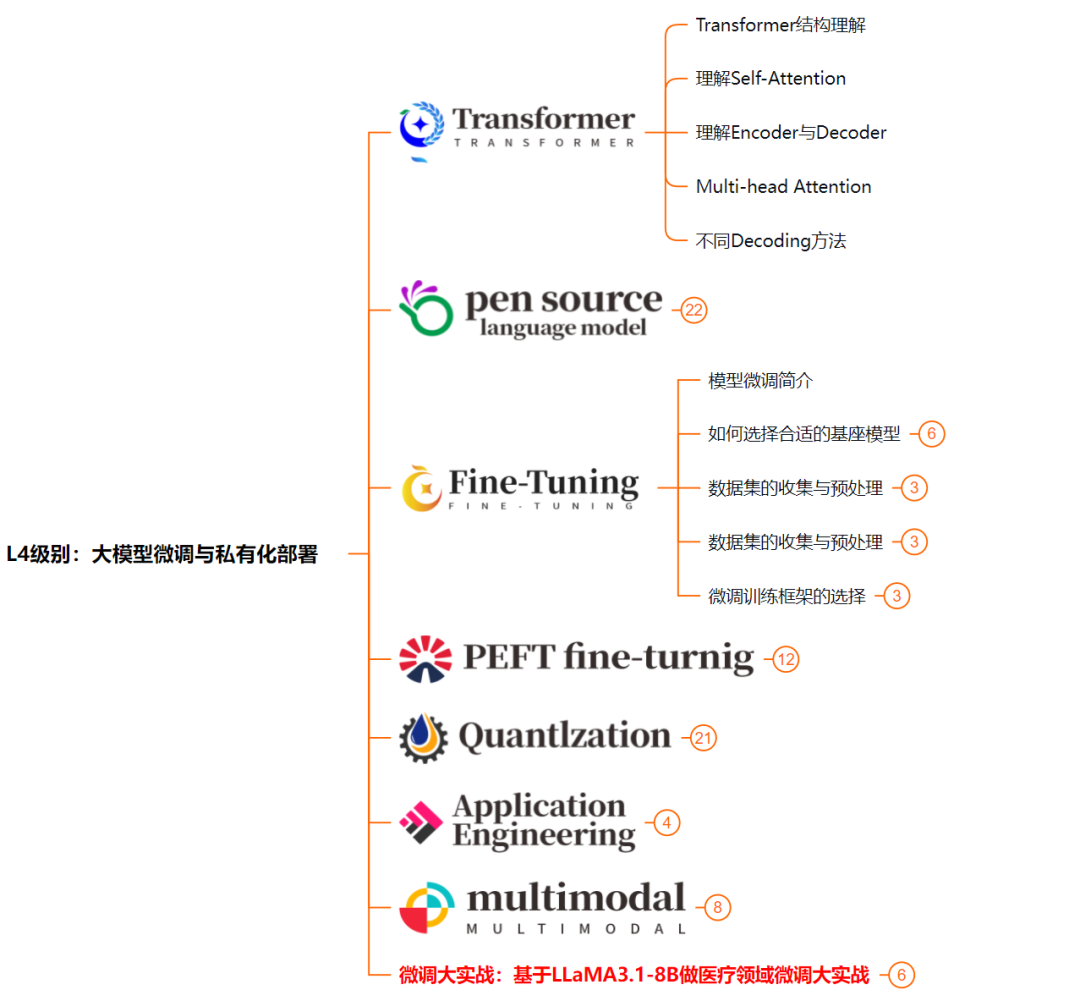
整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。
 因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享









评论前必须登录!
注册