 网硕互联帮助中心
网硕互联帮助中心文章目录
- 特征降维
-
-
- 1 特征选择
-
- 低方差过滤特征选择
- 基于相关系数的特征选择
- 2 主成分分析(PCA)
-
- KNN算法
-
- 距离
-
- 1. 欧氏距离(Euclidean Distance)
- 2. 曼哈顿距离(Manhattan Distance)
- 3. 切比雪夫距离(Chebyshev Distance)
- 4. 闵可夫斯基距离(Minkowski Distance)
- 5. 余弦相似度(Cosine Similarity)
- 6. 杰卡德相似度(Jaccard Similarity)
- 7. 马氏距离(Mahalanobis Distance)
- KNN算法
- 模型保存与加载
- 模型选择与调优
-
- 交叉验证
-
- 1 保留交叉验证(Train-Test Split)
- 2 K-折交叉验证(K-fold)
- 3 分层K-折交叉验证(Stratified k-fold)
- 超参数搜索 GridSearchCV
- 朴素贝叶斯算法
-
- 1.条件概率
- 2. 全概率公式
- 3. 贝叶斯定理
- 4 朴素贝叶斯推断
- 5. 拉普拉斯平滑
特征降维
特征降维是指通过减少数据集的特征数量同时保留关键信息的过程。高维数据(特征过多)会导致计算复杂度增加、过拟合风险提高,以及所谓的 “维度灾难”。降维可以减少数据集维度,同时尽可能保留数据的重要性。
降维可以:
特征降维技术主要分为两类:特征选择和特征提取。
1 特征选择
特征选择是指直接从原始特征中选择有用的特征,而不该特征本身
低方差过滤特征选择
如果一个特征的方差很小,说明该特征的取值几乎没有变化,提供的信息量有限,可能对模型贡献不大,可考虑删除。
方差计算公式为
Var
(
X
)
=
1
n
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
\\text{Var}(X) = \\frac{1}{n} \\sum_{i=1}^{n} (x_i – \\bar{x})^2
Var(X)=n1i=1∑n(xi−xˉ)2 如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或者变化不大,包含的信息很少,那这个特征就可以去除
sklearn.feature_selection.VarianceThreshold(threshold=2.0)
- 设定阈值threshold:任何低于阈值的特征都将被视为低方差特征
- 过滤:移除所有低方差特征
from sklearn.feature_selection import VarianceThreshold
data = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
# 创建方差阈值选择器
transfer = VarianceThreshold(threshold=0.5)
data = transfer.fit_transform(data)
print(data)
[[0]
[4]
[1]]
【处理鸢尾花数据集】
from sklearn.datasets import load_iris
from sklearn.feature_selection import VarianceThreshold
from sklearn.model_selection import train_test_split
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
# 创建转换器
transfer = VarianceThreshold(threshold=0.8)
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
print(x_train)
[[1.6]
[1.5]
[4. ]
[4.4]
…
[4.5]
[5.9]
[6. ]
[1.9]
[5.6]
[6.7]]
基于相关系数的特征选择
相关性:指两个或多个变量之间存在的关联关系—— 当一个变量的取值发生变化时,另一个变量的取值也倾向于以某种规律变化。。这种变化不一定是直接引起的,可以间接或者偶然。
- 相关性不意味着因果关系(“相关非因果”):例如 “冰淇淋销量” 和 “溺水事故” 正相关,但并非因果,而是共同受 “气温” 影响。
- 相关性有方向和强度:
- 方向:正相关(一个变量增大,另一个也增大,如 “身高” 与 “体重”)、负相关(一个变量增大,另一个减小,如 “商品价格” 与 “销量”)。
- 强度:从 “弱相关” 到 “强相关”(可用数值量化,如相关系数)。
皮尔逊相关系数(Pearson Correlation Coefficient)
衡量线性相关性的指标,取值范围为[-1, 1]
- ρ = 1:完全正线性相关;
- ρ = -1:完全负线性相关;
- ρ = 0:无线性相关(但可能存在非线性相关)。
对于两组数据 𝑋={𝑥1,𝑥2,…,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,…,𝑦𝑛},皮尔逊相关系数可以用以下公式计算:
ρ
=
Cos
(
x
,
y
)
D
x
⋅
D
y
=
E
[
(
x
−
E
x
)
(
y
−
E
y
)
]
D
x
⋅
D
y
=
∑
i
=
1
n
(
x
−
x
~
)
(
y
−
y
ˉ
)
/
(
n
−
1
)
∑
i
=
1
n
(
x
−
x
ˉ
)
2
/
(
n
−
1
)
⋅
∑
i
=
1
n
(
y
−
y
ˉ
)
2
/
(
n
−
1
)
\\rho=\\frac{\\operatorname{Cos}(x, y)}{\\sqrt{D x} \\cdot \\sqrt{D y}}=\\frac{E[(x_-E x)(y-E y)]}{\\sqrt{D x} \\cdot \\sqrt{D y}}=\\frac{\\sum_{i=1}^{n}(x-\\tilde{x})(y-\\bar{y}) /(n-1)}{\\sqrt{\\sum_{i=1}^{n}(x-\\bar{x})^{2} /(n-1)} \\cdot \\sqrt{\\sum_{i=1}^{n}(y-\\bar{y})^{2} /(n-1)}}
ρ=Dx
⋅Dy
Cos(x,y)=Dx
⋅Dy
E[(x−Ex)(y−Ey)]=∑i=1n(x−xˉ)2/(n−1)
⋅∑i=1n(y−yˉ)2/(n−1)
∑i=1n(x−x~)(y−yˉ)/(n−1)
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
from scipy.stats import pearsonr
r1 = pearsonr(x,y)
from scipy.stats import pearsonr
x=[5,6,7,2,1,5,12,9,0,4]
y=[2,4,5,4,5,8,9,0,1,3]
p = pearsonr(x,y)
print(p)
PearsonRResult(statistic=np.float64(0.3504442861308587), pvalue=np.float64(0.32081529829352373))
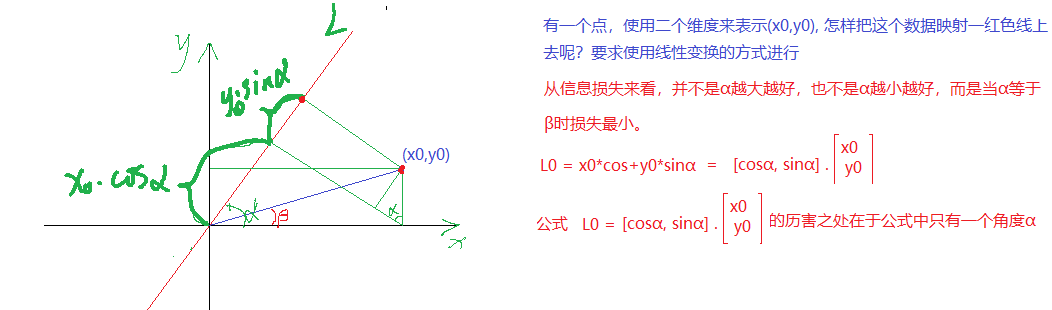
2 主成分分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
from sklearn.decomposition import PCA
- PCA(n_components=None)
- 主成分分析
- n_components:
- 实参为小数时:表示降维后保留百分之多少的信息
- 实参为整数时:表示减少到多少特征
from sklearn.decomposition import PCA
import numpy as np
data = np.array([[2,8,4,5],
[6,3,0,8],
[5,4,9,1]])
pca = PCA(n_components=2)
data_new = pca.fit_transform(data)
print(data_new)
[[-1.28620952e-15 3.82970843e+00]
[-5.74456265e+00 -1.91485422e+00]
[ 5.74456265e+00 -1.91485422e+00]]
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
iris = load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
transfer = PCA(n_components=2)
x_train = transfer.fit_transform(x_train)
#训练模型
#用模型预测
x_test = transfer.transform(x_test)
print(x_test)
[[-2.36170948 0.64237919]
[ 2.05485818 0.16275091]
[ 1.23887735 0.10868042]
…
[ 0.3864534 -0.37888638]
[ 1.57303541 -0.53629936]
[-2.73553694 -0.15148737]
[ 2.53493848 0.51260491]
[ 1.91514709 0.1205521 ]
[ 2.42377809 0.38254852]
[ 1.41198549 -0.14338675]]
KNN算法
距离
在机器学习中,样本距离是衡量数据点之间相似性或差异性的核心概念,广泛应用于分类、聚类、降维等算法中。
1. 欧氏距离(Euclidean Distance)
最常见的两点或多点之间的距离表示方法,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
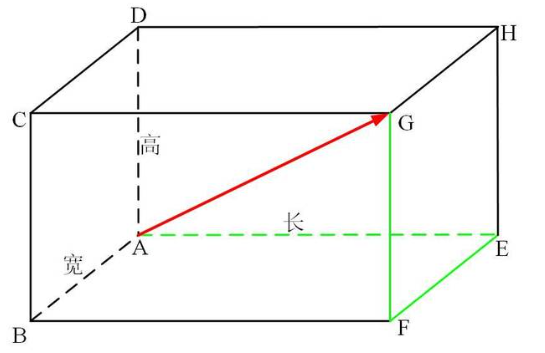
在 n 维空间中,两个点欧氏距离为:
d
(
A
,
B
)
=
(
x
1
−
y
1
)
2
+
(
x
2
−
y
2
)
2
+
⋯
+
(
x
n
−
y
n
)
2
d(A,B) = \\sqrt{(x_1 – y_1)^2 + (x_2 – y_2)^2 + \\dots + (x_n – y_n)^2}\\
d(A,B)=(x1−y1)2+(x2−y2)2+⋯+(xn−yn)2
公式可简化为向量形式(若 A 和 B 表示为向量):
d
(
A
,
B
)
=
∥
A
−
B
∥
2
d(A,B) = \\| A – B \\|_2\\
d(A,B)=∥A−B∥2
2. 曼哈顿距离(Manhattan Distance)
两点在网格状坐标系中走过的最短路径(只能沿坐标轴方向移动),又称 “城市街区距离”。
在 n 维空间中,A 与 B 之间的曼哈顿距离公式为:
d
(
A
,
B
)
=
∣
x
1
−
y
1
∣
+
∣
x
2
−
y
2
∣
+
⋯
+
∣
x
n
−
y
n
∣
d(A,B) = |x_1 – y_1| + |x_2 – y_2| + \\dots + |x_n – y_n|
d(A,B)=∣x1−y1∣+∣x2−y2∣+⋯+∣xn−yn∣ 公式可简化为向量形式:
d
(
A
,
B
)
=
∥
A
−
B
∥
1
d(A,B) = \\| A – B \\|_1
d(A,B)=∥A−B∥1 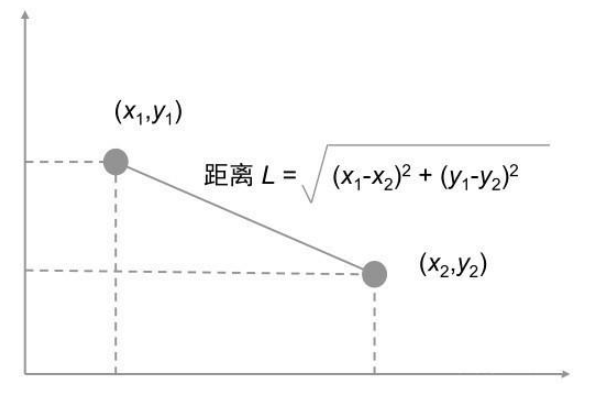
3. 切比雪夫距离(Chebyshev Distance)
两点在各维度上差值的最大值,相当于 “国际象棋中国王的移动距离”。
d
(
x
,
y
)
=
max
i
=
1
n
∣
x
i
−
y
i
∣
d(\\mathbf{x}, \\mathbf{y}) = \\max_{i=1}^{n} |x_i – y_i|
d(x,y)=i=1maxn∣xi−yi∣ 公式可通过数学变换与曼哈顿距离关联(需借助坐标转换),但核心是对 “最大维度差异” 的直接度量。
4. 闵可夫斯基距离(Minkowski Distance)
欧氏距离和曼哈顿距离的广义形式,通过参数 p 控制距离度量的阶数。
d
(
x
,
y
)
=
(
∑
i
=
1
n
∣
x
i
−
y
i
∣
p
)
1
/
p
d(\\mathbf{x}, \\mathbf{y}) = \\left( \\sum_{i=1}^{n} |x_i – y_i|^p \\right)^{1/p}
d(x,y)=(i=1∑n∣xi−yi∣p)1/p
- 当 (p=1) 时,退化为曼哈顿距离;
- 当 (p=2) 时,即为欧氏距离;
- 当 (p \\to \\infty) 时,收敛于切比雪夫距离。
5. 余弦相似度(Cosine Similarity)
计算两向量夹角的余弦值,衡量方向的相似性(而非大小)。
cosine
(
x
,
y
)
=
x
⋅
y
∣
∣
x
∣
∣
⋅
∣
∣
y
∣
∣
=
∑
i
=
1
n
x
i
y
i
∑
i
=
1
n
x
i
2
⋅
∑
i
=
1
n
y
i
2
\\text{cosine}(\\mathbf{x}, \\mathbf{y}) = \\frac{\\mathbf{x} \\cdot \\mathbf{y}}{||\\mathbf{x}|| \\cdot ||\\mathbf{y}||} = \\frac{\\sum_{i=1}^{n} x_i y_i}{\\sqrt{\\sum_{i=1}^{n} x_i^2} \\cdot \\sqrt{\\sum_{i=1}^{n} y_i^2}}
cosine(x,y)=∣∣x∣∣⋅∣∣y∣∣x⋅y=∑i=1nxi2
⋅∑i=1nyi2
∑i=1nxiyi 余弦相似度的结果范围是 [-1, 1],具体含义如下:
- θ = 0°:(\\cos(\\theta) = 1) → 两向量方向完全相同(相似度最高);
- θ = 90°:(\\cos(\\theta) = 0) → 两向量垂直,方向无关;
- θ = 180°:(\\cos(\\theta) = -1) → 两向量方向完全相反(相似度最低)。
6. 杰卡德相似度(Jaccard Similarity)
用于比较两个集合的相似性,定义为交集与并集的比值。
对于两个集合 A 和 B,杰卡德相似度为:
J
(
A
,
B
)
=
∣
A
∩
B
∣
∣
A
∪
B
∣
J(A, B) = \\frac{|A \\cap B|}{|A \\cup B|}\\
J(A,B)=∣A∪B∣∣A∩B∣ 杰卡德距离为:
d
(
A
,
B
)
=
1
−
J
(
A
,
B
)
d(A, B) = 1 – J(A, B)
d(A,B)=1−J(A,B) 杰卡德相似度的结果范围是 [0, 1],具体含义如下:
- J = 1:两个集合完全相同(交集 = 并集);
- J = 0:两个集合没有任何共同元素(交集为空);
- 数值越接近 1,说明两个集合的重叠度越高,相似性越强。
7. 马氏距离(Mahalanobis Distance)
考虑数据分布协方差的距离度量,可消除特征间相关性的影响,且对尺度不敏感。
对于两个数据点 x 和 y,若它们来自同一分布(协方差矩阵为 S,则两者之间的马氏距离为:
d
(
x
,
y
)
=
(
x
−
y
)
T
S
−
1
(
x
−
y
)
d(\\mathbf{x}, \\mathbf{y}) = \\sqrt{(\\mathbf{x} – \\mathbf{y})^T S^{-1} (\\mathbf{x} – \\mathbf{y})}
d(x,y)=(x−y)TS−1(x−y)
KNN算法
K 近邻(K-Nearest Neighbors, KNN)是一种基本且常用的监督学习算法,可用于分类和回归任务。其核心思想是:给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,然后基于这 k 个实例的信息来进行预测。
缺点:
- 对于大规模的数据集,计算量过大
- 维度灾难–对于高维数据,最近邻与最远邻的距离差异缩小,导致模型性能下降。
- K 值选择困难
- K 值过小:模型过拟合,对噪声敏感(如 K=1 时易受离群点影响)。
- K 值过大:模型欠拟合,忽略局部特征(如 K=n 时退化为全局多数表决)。
模型保存与加载
import joblib
# 保存模型
joblib.dump(estimator, "my_ridge.pkl")
# 加载模型
estimator = joblib.load("my_ridge.pkl")
#使用模型预测
y_test=estimator.predict([[0.4,0.2,0.4,0.7]])
print(y_test)
模型选择与调优
交叉验证
交叉验证的核心思想是将原始数据集划分为多个子集,轮流将其中一个子集作为测试集,其余作为训练集,多次训练和评估模型后取平均值作为最终性能指标。
交叉验证主要解决以下问题:
- 传统的单次训练测试分割可能导致结果不稳定
- 模型在特定测试集上可能过拟合
- 充分利用有限的数据进行模型评估
1 保留交叉验证(Train-Test Split)
保留交叉验证(Hold-Out Cross Validation,又称 Train-Test Split)是最直观、最简单的模型验证方法,核心思想是将原始数据集一次性分割为两个互斥的子集:训练集(Train Set)和测试集(Test Set),用训练集训练模型,用测试集评估模型的泛化能力。
常见比例为训练集 70%-80%,测试集 20%-30%。
sklearn.model_selection.train_test_split
- test_size:测试集占比(如 0.2 表示 20% 数据作为测试集)。
- random_state:随机种子,固定后分割方式不变,保证实验可复现。
- stratify:用于类别不平衡数据(如二分类中正负样本比例悬殊),设置为y时,训练集和测试集会保持与原始数据相同的类别比例(避免测试集某类样本过少导致评估失真)。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22,shuffle=True,stratify=y)
#stratify=y :按照y的分布进行分层
print(y_test)
[1 2 0 0 0 0 0 2 1 0 1 2 1 1 2 1 0 2 0 1 1 1 1 0 2 2 2 0 2 2]
优点
缺点
2 K-折交叉验证(K-fold)
将数据集划分为K 个互不重叠的子集(折),每个分区被称为 一个”Fold”。一个Fold被用作验证集,其余的K-1个Fold被用作训练集,重复 K 次。最终模型性能是 K 次评估结果的平均值。
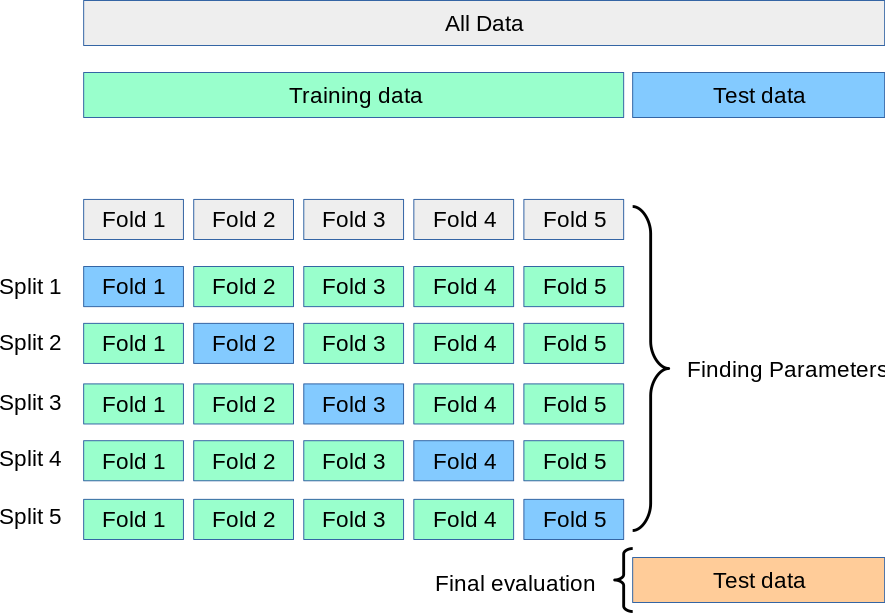
from sklearn.model_selection import KFold
- n_splits:折数,通常取 5 或 10
- shuffle:是否在划分前打乱数据
- random_state:随机种子,确保结果可重现
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.datasets import load_iris
x,y = load_iris(return_X_y=True)
k = KFold(n_splits=5,shuffle=True,random_state=22)
re = k.split(x,y)
# print(re)# 迭代器
# print(next(re))
for train_index,test_index in re:
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
print(y_test)
[0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
缺点:对不平衡数据集不友好(可能导致某类样本在测试集中缺失)
随机划分可能导致某些折中某类别样本极少甚至缺失,尤其是当某类别样本占比较低时(如欺诈检测中欺诈样本通常不足 1%)。这种不平衡会导致:
- 训练集和测试集分布不一致
- 模型评估指标不可靠(如准确率虚高)
- 对少数类别的预测能力无法得到有效验证
3 分层K-折交叉验证(Stratified k-fold)
分层 K – 折交叉验证(Stratified K-Fold Cross-Validation)是 K – 折交叉验证的改进版本,特别适用于分类问题,尤其是类别不平衡的数据集。其核心思想是在每次划分时保持每个折中各类别样本的比例与原始数据集一致,从而确保评估结果的可靠性。
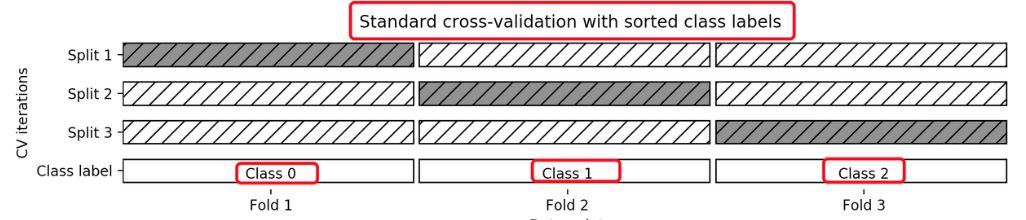
from sklearn.model_selection import StratifiedKFold
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
- n_splits划分为几个折叠
- shuffle是否在拆分之前被打乱(随机化),False则按照顺序拆
- random_state随机因子
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import load_iris
x,y = load_iris(return_X_y=True)
k = StratifiedKFold(n_splits=5,shuffle=True,random_state=22)
re = k.split(x,y)
# print(re)# 迭代器
# print(next(re))
for train_index,test_index in re:
x_train,x_test = x[train_index],x[test_index]
y_train,y_test = y[train_index],y[test_index]
print(y_test)
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
超参数搜索 GridSearchCV
在机器学习中,超参数是模型训练前需要人为设定的参数(如 KNN 中的k值、决策树的max_depth等)。超参数搜索是寻找最优超参数组合的过程,而 **网格搜索(Grid Search)**是最常用的方法之一。
GridSearchCV API
class sklearn.model_selection.GridSearchCV(estimator, param_grid)
GridSearchCV(
estimator, # 模型(如KNN、RandomForest等)
param_grid, # 超参数网格(字典形式)
score=None, # 评估指标
cv=None, # 交叉验证折数或策略
...
)
-
含义:需要优化的模型对象。
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier() # 创建KNN模型
-
含义:待搜索的超参数组合,格式为字典的列表。
param_grid = {
'n_neighbors': [3, 5, 7, 9], # K值
'weights': ['uniform', 'distance'], # 权重计算方式
'p': [1, 2] # 距离度量(1=曼哈顿,2=欧氏)
}
-
含义:交叉验证的折数或自定义策略。
-
常用值
- 整数:指定 K 折(如cv=5)
- 交叉验证生成器:如StratifiedKFold(处理类别不平衡)
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
网格搜索结束后,可以通过以下属性获取结果:
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
iris = load_iris()
x,y = load_iris(return_X_y=True)
knn = KNeighborsClassifier()
model = GridSearchCV(knn,param_grid={'n_neighbors':[1,2,3,4,5,6,7,8,9,10]},cv = 5)
model.fit(x,y)
# 查看结果
print("最佳参数:",model.best_params_)
print("最佳结果:",model.best_score_)
print("最佳模型:",model.best_estimator_)
# print("交叉验证结果:",model.cv_results_)
#model本身是个模型
# 使用模型
y_predict = model.predict([[5.1,3.5,1.4,0.2]])
print("预测结果为:",y_predict,iris.target_names[y_predict])
最佳参数: {'n_neighbors': 6}
最佳结果: 0.9800000000000001
最佳模型: KNeighborsClassifier(n_neighbors=6)
预测结果为: [0] ['setosa']
朴素贝叶斯算法
1.条件概率
条件概率是概率论中的核心概念,用于描述在已知某一事件发生的情况下,另一事件发生的概率。
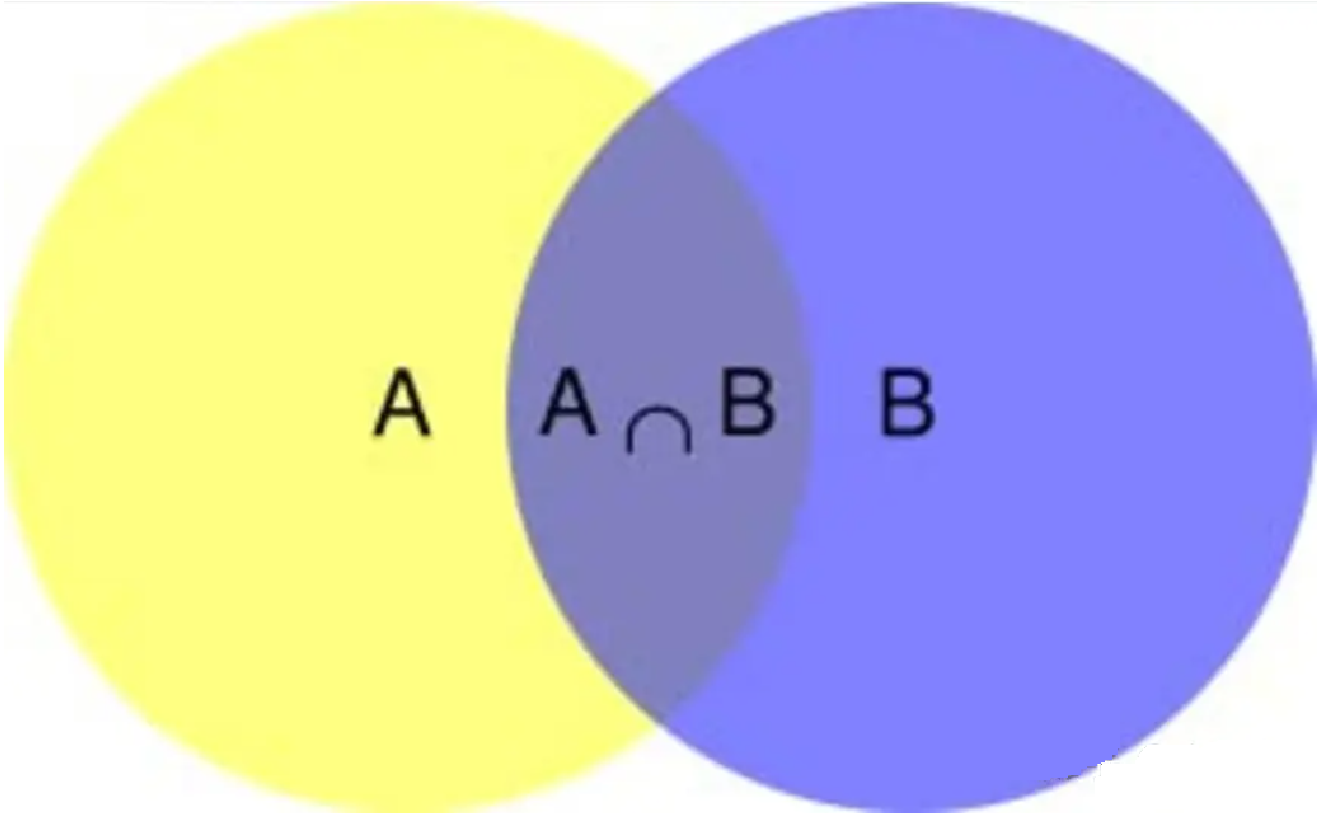
设 A 和 B 是样本空间Ω中的两个事件,且 (P(B) > 0),则在事件 B 发生的条件下,事件 A 发生的条件概率记为 (P(A|B)),定义为:𝑃(𝐴|𝐵)=𝑃(𝐴∩𝐵)/𝑃(𝐵)
𝑃(𝐴∩𝐵)=𝑃(𝐴|𝐵)𝑃(𝐵)
𝑃(𝐴∩𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)
𝑃(𝐴|𝐵)=𝑃(B|A)𝑃(𝐴)/𝑃(𝐵)
2. 全概率公式
假定样本空间S,是两个事件A与A’的和。
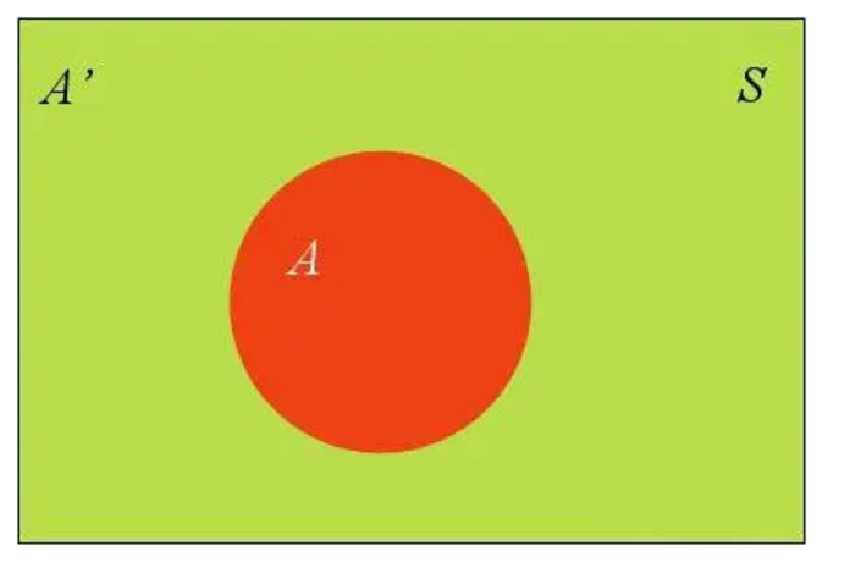
事件B可以划分成两个部分:𝑃(𝐵)=𝑃(𝐵∩𝐴)+𝑃(𝐵∩𝐴′)
因为𝑃(𝐵∩𝐴)=𝑃(𝐵|𝐴)𝑃(𝐴)
所以𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′)
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
∣
A
)
P
(
A
)
+
P
(
B
∣
A
,
)
P
(
A
,
)
P(A|B)=\\frac{P(B|A)P(A)}{P(B|A)P(A)+P(B|A^,)P(A^,)}
P(A∣B)=P(B∣A)P(A)+P(B∣A,)P(A,)P(B∣A)P(A)
3. 贝叶斯定理
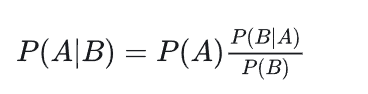
贝叶斯定理描述了条件概率之间的关系 其中:
- P(A):“先验概率”,即在B事件发生之前,我们对A事件概率的一个判断。
- P(A|B):“后验概率”(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
- P(B|A)/P(B):“可能性函数”,这是一个调整因子,使得预估概率更接近真实概率。
- 后验概率 = 先验概率x调整因子
4 朴素贝叶斯推断
朴素贝叶斯分类器的关键假设是特征之间的条件独立性,即给定类别 a ,特征
x
i
x_i
xi 和
x
j
x_j
xj (其中
i
≠
j
i \\neq j
i=j 相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
P
(
X
∣
a
)
=
P
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
a
)
=
P
(
x
1
∣
a
)
P
(
x
2
∣
a
)
.
.
.
P
(
x
n
∣
a
)
P(X|a) = P(x_1, x_2, …, x_n|a) = P(x_1|a)P(x_2|a)…P(x_n|a)
P(X∣a)=P(x1,x2,…,xn∣a)=P(x1∣a)P(x2∣a)…P(xn∣a)
将这个条件独立性假设应用于贝叶斯公式,我们得到:
P
(
a
∣
X
)
=
P
(
x
1
∣
a
)
P
(
x
2
∣
a
)
.
.
.
P
(
x
n
∣
a
)
P
(
a
)
P
(
X
)
P(a|X) = \\frac{P(x_1|a)P(x_2|a)…P(x_n|a)P(a)}{P(X)}
P(a∣X)=P(X)P(x1∣a)P(x2∣a)…P(xn∣a)P(a)
5. 拉普拉斯平滑
某些事件或特征可能从未出现过,这会导致它们的概率被估计为零。
解决:
P
(
x
i
∣
y
)
=
N
y
,
x
i
+
α
N
y
+
α
n
P(x_i|y) = \\frac{N_{y,x_i} + \\alpha}{N_y + \\alpha n}
P(xi∣y)=Ny+αnNy,xi+α
-
α
\\alpha
α:平滑系数(通常为1) -
n
n
n:特征取值数
sklearn.naive_bayes.MultinomialNB() estimator.fit(x_train, y_train) y_predict = estimator.predict(x_test)
【贝叶斯对鸢尾花的分类】
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
model = MultinomialNB()
#训练:统计先验概率
model.fit(x_train,y_train)
score = model.score(x_test,y_test)
print("准确率:",score)
x_new = [[5.1,3.5,1.4,0.2],
[1,2,4,3]]
y_new = model.predict(x_new)
print("预测结果为:",y_new)
print("预测结果为:",model.predict(x_new))
print(iris.target_names[y_new])
准确率: 0.6666666666666666
预测结果为: [0 2]
预测结果为: [0 2]
['setosa' 'virginica']
【贝叶斯对葡萄酒的分类】
from sklearn.datasets import load_wine
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 加载数据集
wine = load_wine()
x,y = load_wine(return_X_y=True)
# 无量纲化处理–多项式朴素贝叶斯要求输入特征非负
transfer = MinMaxScaler()
x=transfer.fit_transform(x)
# 数据集的划分
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
# 创建模型
model = MultinomialNB(alpha=1.0)
# 模型训练
model.fit(x_train,y_train)
# 模型评估
print("准确率:",model.score(x_test,y_test))
y_predict = model.predict(x_test)
print(y_predict)
准确率: 0.8888888888888888
[1 2 2 2 0 1 0 1 1 1 1 1 0 0 1 0 0 0 2 2 1 1 2 1 1 2 1 1 2 2 0 0 0 1 0 2]









评论前必须登录!
注册