 网硕互联帮助中心
网硕互联帮助中心基于去中心化数据的深度网络通信高效学习
(Communication-Efficient Learning of Deep Networks from Decentralized Data)
摘要 (Abstract)
现代移动设备能够访问大量适合用于训练模型的数据,这些模型反过来又能极大地改善设备上的用户体验。例如,语言模型可以改善语音识别和文本输入,图像模型可以自动挑选优质照片。然而,这些丰富的数据往往具有隐私敏感性、数量庞大或两者兼具,这可能会阻碍我们将其记录到数据中心并使用常规方法在那里进行训练。我们提倡一种替代方案,即让训练数据保留在分布式的移动设备上,并通过聚合本地计算的更新来学习一个共享模型。我们将这种去中心化的方法称为联邦学习 (Federated Learning)。
我们提出了一种基于迭代模型平均的深度网络联邦学习的实用方法,并进行了广泛的实证评估,考察了五种不同的模型架构和四个数据集。这些实验表明,该方法对不平衡和非独立同分布(non-IID)的数据分布具有鲁棒性,而这些数据分布正是此类场景的决定性特征。通信成本是首要的约束条件,我们证明了与同步随机梯度下降(SGD)相比,该方法将所需的通信轮数减少了 10 到 100 倍。
1 引言 (Introduction)
手机和平板电脑日益成为许多人的主要计算设备 [30, 2]。这些设备上强大的传感器(包括摄像头、麦克风和 GPS),加上它们经常被随身携带的事实,意味着它们能够获取前所未有的大量数据,其中大部分本质上是私密的。在这些数据上学习到的模型有望通过驱动更智能的应用来极大地提高可用性,但数据的敏感性意味着将它们集中存储存在着风险和责任。
我们研究了一种学习技术,它允许用户共同享受从这些丰富数据中训练出的共享模型的好处,而无需集中存储数据。我们将我们的方法称为联邦学习 (Federated Learning),因为学习任务是由一个松散的参与设备联邦(我们称之为客户端 (clients))来解决的,这些设备由一个中央服务器 (server)协调。每个客户端都有一个永远不会上传到服务器的本地训练数据集。相反,每个客户端会计算对服务器维护的当前全局模型的一个更新,并且仅传递这个更新。这是 2012 年白宫关于消费者数据隐私报告中提出的聚焦收集 (focused collection) 或数据最小化 (data minimization) 原则的直接应用 [39]。由于这些更新仅用于改进当前模型,因此一旦应用后就没有理由再存储它们。
这种方法的一个主要优势是将模型训练与直接访问原始训练数据的需求解耦。显然,仍然需要对协调训练的服务器给予一定的信任。然而,对于可以根据每个客户端可用数据来指定训练目标的应用,联邦学习通过将攻击面限制在仅设备层面,而不是设备和云端,可以显著降低隐私和安全风险。
我们的主要贡献有:1) 将移动设备上基于去中心化数据的训练问题确立为一个重要的研究方向;2) 选择了一种可以直接应用于此场景的简单实用的算法;3) 对所提出的方法进行了广泛的实证评估。更具体地说,我们引入了 FederatedAveraging 算法,它将每个客户端上的本地随机梯度下降(SGD)与执行模型平均的服务器相结合。我们对该算法进行了大量实验,证明它对不平衡和非独立同分布(non-IID)的数据分布具有鲁棒性,并且能够将去中心化数据上训练深度网络所需的通信轮数减少数个数量级。
联邦学习 (Federated Learning)
非常适合联邦学习的问题具有以下属性:1) 使用移动设备上的真实世界数据进行训练,相比于使用数据中心中通常可用的代理数据,具有明显的优势。2) 这些数据具有隐私敏感性或体量庞大(相对于模型大小而言),因此仅为了模型训练的目的将其记录到数据中心是不可取的(这符合聚焦收集原则)。3) 对于监督学习任务,数据上的标签可以从用户交互中自然地推断出来。
许多驱动移动设备智能行为的模型都符合上述标准。举两个例子:一是图像分类 (image classification),例如预测哪些照片将来最有可能被多次查看或分享;二是语言模型 (language models),可通过改进解码、下一个词预测甚至预测完整回复来改善触摸屏键盘上的语音识别和文本输入 [10]。这两个任务的潜在训练数据(用户拍摄的所有照片,以及他们在移动键盘上输入的所有内容,包括密码、URL、消息等)都可能是隐私敏感的。得出这些样本的分布也可能与容易获得的代理数据集大相径庭:聊天和短信中的语言使用通常与标准语言语料库(如维基百科和其他网络文档)大不相同;人们用手机拍摄的照片可能与典型的 Flickr 照片完全不同。最后,这些问题的标签是直接可用的:输入的文本就是语言模型自标注的标签,而照片标签可以通过用户与其照片应用的自然交互来定义(哪些照片被删除、分享或查看)。
这两项任务都非常适合学习神经网络。对于图像分类,前馈深度网络,特别是卷积神经网络 (CNN),众所周知能提供最先进的结果 [26, 25]。对于语言建模任务,循环神经网络,特别是 LSTM,也取得了最先进的结果 [20, 5, 22]。
隐私 (Privacy)
与持久化数据上的数据中心训练相比,联邦学习具有明显的隐私优势。哪怕持有的是“匿名化”的数据集,依然可能通过与其他数据的结合(joins)使用户隐私受到威胁 [37]。相比之下,联邦学习传输的信息是改善特定模型所需的最小更新(自然地,隐私收益的强度取决于更新的内容)。¹ 这些更新本身可以是(也应该是)短暂的 (ephemeral)。根据数据处理不等式,它们包含的信息永远不会多于原始训练数据,而且通常包含得少得多。此外,聚合算法不需要知道更新的来源,因此这些更新可以通过 Tor 等混合网络 [7] 或受信任的第三方进行传输,而无需识别元数据。在本文末尾,我们将简要讨论将联邦学习与安全多方计算和差分隐私相结合的可能性。
¹ 例如,如果更新是所有本地数据的损失总梯度,而特征是稀疏的词袋,那么非零梯度会准确地揭示用户在设备上输入了哪些词。相比之下,对于 CNN 这样的密集模型,许多梯度的总和为试图寻求单个训练实例信息的攻击者提供了一个更难攻破的目标(尽管攻击仍然可能发生)。
联邦优化 (Federated Optimization)
我们将联邦学习中隐含的优化问题称为联邦优化 (federated optimization),以建立其与分布式优化 (distributed optimization) 的联系(及对比)。联邦优化具有几个区别于典型分布式优化问题的关键属性:
- 非独立同分布 (Non-IID):给定客户端上的训练数据通常基于特定用户对移动设备的使用情况,因此,任何特定用户的本地数据集都不能代表总体人口分布。
- 不平衡 (Unbalanced):同样地,一些用户使用服务或应用程序的频率远高于其他用户,导致不同设备的本地训练数据量各不相同。
- 大规模分布式 (Massively distributed):我们预期参与优化的客户端数量远远大于每个客户端平均的样本数量。
- 有限的通信 (Limited communication):移动设备经常处于离线状态,或者连接在缓慢、昂贵的网络上。
在这项工作中,我们的重点是优化的非独立同分布和不平衡属性,以及通信约束的关键性质。一个部署的联邦优化系统还必须解决无数实际问题:随着数据的添加和删除,客户端数据集会发生变化;客户端的可用性以复杂的方式与本地数据分布相关联(例如,讲美式英语的用户的手机插电充电的时间,可能与讲英式英语的用户不同);以及有些客户端可能从不响应或发送损坏的更新。
这些问题超出了当前工作的范围;相反,我们使用适合实验的受控环境,但仍然解决了客户端可用性以及不平衡和非独立同分布数据的关键问题。我们假设一种分步通信轮次的同步更新方案。有一组固定的 KKK 个客户端,每个都有一个固定的本地数据集。在每轮开始时,随机选择一部分比例为 CCC 的客户端,服务器将当前的全局算法状态(例如,当前模型参数)发送给这些客户端中的每一个。我们仅选择部分客户端是为了提高效率,因为我们的实验表明,增加客户端数量超过一定程度后会带来收益递减。然后,每个选定的客户端根据全局状态和其本地数据集进行本地计算,并将更新发送到服务器。接着,服务器将这些更新应用到其全局状态,然后重复此过程。
虽然我们重点关注非凸的神经网络目标,但我们考虑的算法适用于任何形式的有限和 (finite-sum) 目标:
minw∈Rdf(w)其中f(w)=def1n∑i=1nfi(w).(1) \\min_{w \\in \\mathbb{R}^d} f(w) \\quad \\text{其中} \\quad f(w) \\stackrel{\\text{def}}{=} \\frac{1}{n} \\sum_{i=1}^n f_i(w). \\quad (1) w∈Rdminf(w)其中f(w)=defn1i=1∑nfi(w).(1)
对于机器学习问题,我们通常设定 fi(w)=ℓ(xi,yi;w)f_i(w) = \\ell(x_i, y_i; w)fi(w)=ℓ(xi,yi;w),也就是说,是用模型参数 www 对样本 (xi,yi)(x_i, y_i)(xi,yi) 进行预测时的损失。我们假设数据被划分在 KKK 个客户端上,Pk\\mathcal{P}_kPk 是客户端 kkk 上的数据点索引集合,其中 nk=∣Pk∣n_k = |\\mathcal{P}_k|nk=∣Pk∣。因此,我们可以将目标方程 (1) 重写为:
f(w)=∑k=1KnknFk(w)其中Fk(w)=1nk∑i∈Pkfi(w). f(w) = \\sum_{k=1}^K \\frac{n_k}{n} F_k(w) \\quad \\text{其中} \\quad F_k(w) = \\frac{1}{n_k} \\sum_{i \\in \\mathcal{P}_k} f_i(w). f(w)=k=1∑KnnkFk(w)其中Fk(w)=nk1i∈Pk∑fi(w).
如果划分 Pk\\mathcal{P}_kPk 是通过将训练样本均匀随机地分布在各个客户端上形成的,那么我们将有 EPk[Fk(w)]=f(w)\\mathbb{E}_{\\mathcal{P}_k}[F_k(w)] = f(w)EPk[Fk(w)]=f(w),其中期望是基于分配给固定客户端 kkk 的样本集计算的。这是分布式优化算法通常做出的独立同分布(IID)假设;我们将这种情况不成立的场景(即 FkF_kFk 可能是 fff 的任意糟糕的近似值)称为非独立同分布 (non-IID) 场景。
在数据中心优化中,通信成本相对较小,而计算成本占主导地位,最近许多重点放在使用 GPU 来降低这些成本。相反,在联邦优化中,通信成本占主导地位——我们通常会受限于 1 MB/s 或更低的上传带宽。此外,客户端通常只会在充电、插电且连接到不限流量的 Wi-Fi 时才自愿参与优化。另外,我们预计每个客户端每天只会参与少量的更新轮次。另一方面,由于单个设备上的数据集规模相对于总数据集较小,且现代智能手机拥有相对较快的处理器(包括 GPU),对于许多模型类型而言,相比于通信成本,计算几乎是免费的。因此,我们的目标是使用额外的计算量来减少训练模型所需的通信轮数。我们可以通过两种主要方式增加计算量:1) 增加并行度,在每个通信轮次之间让更多客户端独立工作;2) 增加每个客户端的计算量,不是执行像计算一次梯度这样简单的计算,而是每个客户端在每次通信轮次之间执行更复杂的计算。我们对这两种方法都进行了研究,但在达到客户端之间最低级别的并行度后,我们取得的加速效果主要归功于在每个客户端上增加了更多的计算量。
相关工作 (Related Work)
通过迭代平均本地训练模型来实现分布式训练,已经被 McDonald 等人 [28] (对于感知机) 和 Povey 等人 [31] (对于语音识别 DNN) 研究过。Zhang 等人 [42] 研究了一种采用“软(soft)”平均的异步方法。这些工作仅考虑了集群/数据中心场景(最多16个工作节点,基于高速网络的挂钟时间),并且没有考虑不平衡和非独立同分布(non-IID)的数据集,而这些属性对联邦学习场景至关重要。我们将这种风格的算法调整到联邦设置中,并进行了适当的实证评估,这提出了与数据中心设置相关问题不同的新问题,并需要不同的方法论。
出于与我们相似的动机,Neverova 等人 [29] 也讨论了将敏感用户数据保留在设备上的优势。Shokri 和 Shmatikov [35] 的工作在几个方面与我们相关:他们专注于训练深度网络,强调隐私的重要性,并通过在每轮通信中仅共享部分参数来解决通信成本问题;然而,他们同样没有考虑不平衡和非独立同分布的数据,并且其实证评估较为有限。
在凸优化的背景下,分布式优化和估计问题已引起了极大的关注 [4, 15, 33],一些算法确实专门针对通信效率进行了优化 [45, 34, 40, 27, 43]。除了假设目标是凸的之外,现有的这项工作通常还要求客户端的数量远少于每个客户端的样本数,要求数据以 IID 方式分布在各个客户端上,并且要求每个节点拥有完全相同数量的数据点——所有这些假设在联邦优化场景中都被打破了。异步分布式形式的 SGD 也被应用于神经网络训练中,例如 Dean 等人 [12],但这些方法在联邦设置中需要极其巨大的更新次数,这是不可接受的。分布式共识算法(如 [41])放宽了 IID 假设,但仍然不适合具有极大数量客户端的通信受限的优化问题。
我们考虑的(参数化)算法系列的一个极端情况是简单的单次平均(one-shot averaging),即每个客户端在其本地数据上求解最小化(可能具有正则化项的)损失的模型,然后将这些模型平均化以产生最终的全局模型。这种方法在具有 IID 数据的凸情况下已经被广泛研究,并且已知在最坏的情况下,产生的全局模型并不比在单个客户端上训练模型更好 [44, 3, 46]。
2 FederatedAveraging 算法 (The FederatedAveraging Algorithm)
近期深度学习领域的大量成功应用几乎都依赖于随机梯度下降(SGD)的变体进行优化;事实上,许多进展都可以理解为对模型结构(及由此产生的损失函数)的调整,使其更容易通过简单的基于梯度的方法进行优化 [16]。因此,我们从 SGD 出发构建联邦优化算法是很自然的。
SGD 可以粗糙地直接应用于联邦优化问题,即在每一轮通信中进行一次单批次的梯度计算(例如,在一个随机选定的客户端上)。这种方法在计算上是高效的,但需要非常大量的训练轮数才能产生良好的模型(例如,即使使用诸如批量归一化的先进方法,Ioffe 和 Szegedy [21] 还是使用大小为 60 的小批量(minibatch)在 MNIST 上训练了 50000 步)。我们在 CIFAR-10 实验中考虑了这一基线方法。
在联邦设置中,引入更多客户端在挂钟时间上的成本很小,因此对于我们的基线,我们采用大批量同步随机梯度下降(large-batch synchronous SGD);Chen 等人 [8] 的实验表明,这种方法在数据中心设置中是目前最先进的,其性能优于异步方法。为了在联邦设置中应用这种方法,我们在每一轮选择一部分比例为 CCC 的客户端,并计算这些客户端所持有的所有数据的损失梯度。因此,CCC 控制全局批次大小,C=1C = 1C=1 对应于全批次(非随机)梯度下降。² 我们将这种基准算法称为 FederatedSGD(或 FedSGD)。
² 虽然选择批次的机制与均匀随机抽取单个样本的机制不同,但 FedSGD 计算的批次梯度 ggg 仍满足 E[g]=∇f(w)\\mathbb{E}[g] = \\nabla f(w)E[g]=∇f(w)。
在 C=1C = 1C=1 且学习率恒定为 η\\etaη 的情况下,FedSGD 的典型实现是:每个客户端 kkk 计算 gk=∇Fk(wt)g_k = \\nabla F_k(w_t)gk=∇Fk(wt)(即在当前模型 wtw_twt 下其本地数据的平均梯度),中央服务器聚合这些梯度并应用更新 wt+1←wt−η∑k=1Knkngkw_{t+1} \\leftarrow w_t – \\eta \\sum_{k=1}^K \\frac{n_k}{n} g_kwt+1←wt−η∑k=1Knnkgk,因为 ∑k=1Knkngk=∇f(wt)\\sum_{k=1}^K \\frac{n_k}{n} g_k = \\nabla f(w_t)∑k=1Knnkgk=∇f(wt)。一个等效的更新写法是:∀k,wt+1k←wt−ηgk\\forall k, w^k_{t+1} \\leftarrow w_t – \\eta g_k∀k,wt+1k←wt−ηgk然后 wt+1←∑k=1Knknwt+1kw_{t+1} \\leftarrow \\sum_{k=1}^K \\frac{n_k}{n} w^k_{t+1}wt+1←∑k=1Knnkwt+1k。也就是说,每个客户端在当前模型上使用其本地数据在本地执行一步梯度下降,然后服务器对生成的模型进行加权平均。一旦算法写成这种形式,我们就可以通过在平均化步骤之前让客户端对局部更新 wk←wk−η∇Fk(wk)w^k \\leftarrow w^k – \\eta \\nabla F_k(w^k)wk←wk−η∇Fk(wk) 进行多次迭代,从而在每个客户端上增加更多计算量。我们将这种方法称为 FederatedAveraging(或 FedAvg)。计算量由三个关键参数控制:
- CCC,每轮进行计算的客户端的比例;
- EEE,每轮每个客户端遍历其本地数据集的训练轮数(epochs);
- BBB,客户端更新所使用的本地小批量大小(minibatch size)。
我们将 B=∞B = \\inftyB=∞ 用来表示整个本地数据集被视为单个小批量。因此,在这个算法家族的一个极端情况中,我们可以取 B=∞B = \\inftyB=∞ 和 E=1E = 1E=1,这正好对应于 FedSGD。对于拥有 nkn_knk 个本地样本的客户端,每轮的本地更新次数由 uk=EnkBu_k = E \\frac{n_k}{B}uk=EBnk 给出;完整的伪代码详见算法 1。
对于一般的非凸目标,在参数空间中对模型进行平均可能会产生任意糟糕的模型。
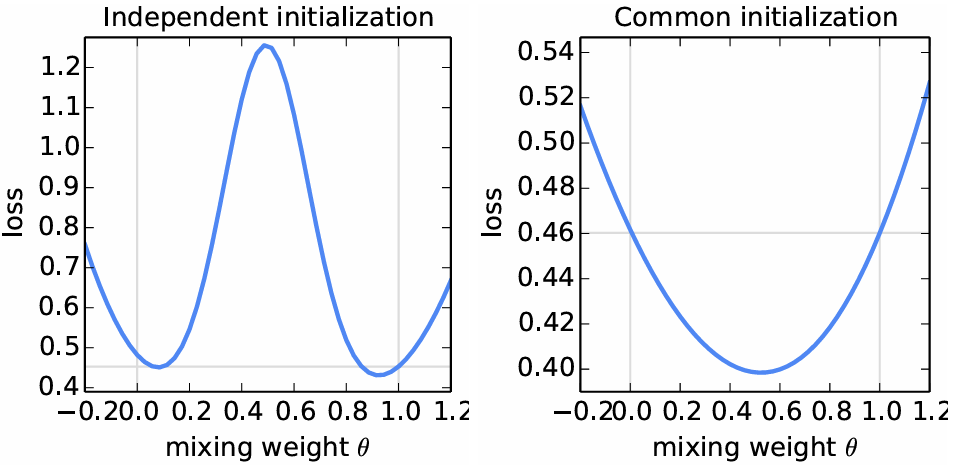
图 1 说明:
本图展示了由两个模型 www 和 w′w'w′ 参数平均生成的模型 θw+(1−θ)w′\\theta w + (1 – \\theta)w'θw+(1−θ)w′ 在全量 MNIST 训练集上的损失。横轴 θ\\thetaθ 取值范围为 [−0.2,1.2][-0.2, 1.2][−0.2,1.2],共有50个均匀分布的点。模型 www 和 w′w'w′ 是在不同的小型数据集上使用 SGD 训练得到的。
左图中,www 和 w′w'w′ 使用了不同的随机种子初始化;右图中,使用了相同的共享种子初始化。注意两图 y 轴比例不同。水平线表示 www 或 w′w'w′ 达到的最佳损失(两者非常接近,对应于 θ=0\\theta=0θ=0 和 θ=1\\theta=1θ=1 处的垂直线)。通过共享初始化,平均这两个模型在总训练集上显著降低了损失(远好于任何一个单一父模型的损失)。
遵循 Goodfellow 等人 [17] 的研究方法,当我们将从不同初始条件训练出的两个 MNIST 数字识别模型³进行平均时,我们确切地看到了这种糟糕的行为(图 1,左侧)。在这张图中,父模型 www 和 w′w'w′ 分别是从 MNIST 训练集中抽取的、互不重叠的 600 个样本的 IID 子集上进行训练的。训练使用固定学习率 0.1 的 SGD,批大小为 50,进行了 240 次更新(相当于在大小为 600 的小数据集上 E=20E = 20E=20 轮 epoch)。这大约是模型开始过度拟合其本地数据时的训练量。
近期研究表明,在实践中,充分参数化的神经网络的损失曲面出乎意料地表现良好,特别是不像以前认为的那样容易陷入糟糕的局部最小值 [11, 17, 9]。事实上,当我们从同一个随机初始化开始训练两个模型,然后再次在数据的不同子集上独立训练它们(如上所述)时,我们发现简单的参数平均效果好得出奇(图 1,右侧):这两个模型的平均值 12w+12w′\\frac{1}{2}w + \\frac{1}{2}w'21w+21w′ 在完整 MNIST 训练集上实现了明显低于任何一个小型数据集上独立训练所取得的最佳损失。虽然图 1 从一个随机初始化开始,但请注意,对于每一轮的 FedAvg 而言,它都是从一个共享的起始模型 wtw_twt 开始的,因此同样的直觉也适用。
³ 我们使用第3节中描述的“2NN”多层感知机。
[算法 1: FederatedAveraging 算法]

算法 1 译文:
FederatedAveraging. 有 KKK 个客户端由 kkk 索引;BBB 是本地小批量大小;EEE 是本地 epoch 数,η\\etaη 是学习率。
服务器执行:
初始化 w0w_0w0
对于 (for) 每个轮次 t=1,2,…t = 1, 2, \\ldotst=1,2,… 执行 (do):
m←max(C⋅K,1)m \\leftarrow \\max(C \\cdot K, 1)m←max(C⋅K,1)
St←S_t \\leftarrowSt← (随机选择的 mmm 个客户端的集合)
对于 (for) 每个客户端 k∈Stk \\in S_tk∈St 并行执行 (in parallel do):
wt+1k←ClientUpdate(k,wt)w_{t+1}^k \\leftarrow \\text{ClientUpdate}(k, w_t)wt+1k←ClientUpdate(k,wt)
mt←∑k∈Stnkm_t \\leftarrow \\sum_{k \\in S_t} n_kmt←∑k∈Stnk
wt+1←∑k∈Stnkmtwt+1kw_{t+1} \\leftarrow \\sum_{k \\in S_t} \\frac{n_k}{m_t} w_{t+1}^kwt+1←∑k∈Stmtnkwt+1k // 勘误4: 论文早期版本在这里错误地标明了对所有 K 个客户端进行求和。
ClientUpdate(k,w)\\text{ClientUpdate}(k, w)ClientUpdate(k,w): // 在客户端 kkk 上运行
B←\\mathcal{B} \\leftarrowB← (将 Pk\\mathcal{P}_kPk 分割成大小为 BBB 的批次)
对于 (for) 每个本地 epoch iii 从 1 到 EEE 执行 (do):
对于 (for) 批次 b∈Bb \\in \\mathcal{B}b∈B 执行 (do):
w←w−η∇ℓ(w;b)w \\leftarrow w – \\eta \\nabla \\ell(w; b)w←w−η∇ℓ(w;b)
将 www 返回给服务器
3 实验结果 (Experimental Results)
我们的动机来自于图像分类和语言建模任务,优秀的模型可以极大地提高移动设备的可用性。对于这些任务中的每一个,我们首先挑选了一个规模适中的代理数据集,以便我们可以彻底研究 FedAvg 算法的超参数。虽然每一次单独的训练运行相对较小,但我们为这些实验训练了 2000 多个独立模型。然后我们展示了基准 CIFAR-10 图像分类任务的结果。最后,为了证明 FedAvg 在自然分布于客户端的现实问题上的有效性,我们在一个大规模语言建模任务上进行了评估。
我们的初步研究包括两个数据集上的三个模型系列。前两个用于 MNIST 数字识别任务 [26]:1) 一个简单的多层感知机(具有 2 个隐含层,每层 200 个单元,使用 ReLu 激活函数,总计 199,210 个参数),我们将其称为 MNIST 2NN。2) 一个 CNN,具有两个 5×5 卷积层(第一层 32 个通道,第二层 64 个,每层后接 2×2 最大池化),一个具有 512 个单元和 ReLu 激活的全连接层,以及最终的 softmax 输出层(总计 1,663,370 个参数)。为了研究联邦优化,我们还需要指明数据是如何分布在客户端上的。我们研究了两种将 MNIST 数据划分给客户端的方法:IID (独立同分布):数据被洗牌后分为 100 个客户端,每个获得 600 个样本;以及 Non-IID (非独立同分布):我们首先按数字标签对数据进行排序,将其分成 200 个分片,每个分片大小为 300,然后为 100 个客户端各分配 2 个分片。这是一种病态的(pathological)非独立同分布数据划分,因为大多数客户端只有两个数字的样本,这让我们得以探索我们的算法在高度 non-IID 数据上的崩溃程度。不过,这两种划分是平衡的。⁵
对于语言建模,我们从《莎士比亚全集》[32] 中构建了一个数据集。我们为戏剧中至少有两句台词的每一个角色构建一个客户端数据集。这产生了一个包含 1146 个客户端的数据集。对于每个客户端,我们将数据分为一组训练行(该角色前 80% 的台词)和测试行(后 20%,向上取整至少保留一行)。得到的数据集在训练集中有 3,564,579 个字符,在测试集中有 870,014 个字符⁶。这些数据极不平衡,许多角色只有几句台词,而少数角色有大量台词。此外,请注意,测试集并不是句子的随机抽取,而是按照每部戏剧的时间顺序进行时间分离的。使用相同的训练/测试拆分,我们也形成了该数据集的一个平衡且 IID 的版本,同样包含 1146 个客户端。
在这份数据上,我们训练了一个堆叠式字符级 LSTM 语言模型,它在读取一行中的每个字符后,预测下一个字符 [22]。该模型将一系列字符作为输入,并将每个字符嵌入到一个学习到的 8 维空间中。然后这些嵌入字符通过 2 个 LSTM 层进行处理,每层 256 个节点。最后,第二个 LSTM 层的输出发送到一个 softmax 输出层,每个字符对应一个节点。完整模型有 866,578 个参数,我们使用了 80 个字符的展开长度(unroll length)进行训练。
SGD 对学习率参数 η\\etaη 的调优很敏感。此处报告的结果基于对足够宽的学习率网格进行训练得出(通常我们在分辨率为 101/310^{1/3}101/3 或 101/610^{1/6}101/6 的乘法网格上选取 11-13 个 η\\etaη 值)。我们检查以确保最佳学习率处于我们网格的中间部分,并且最佳学习率之间没有显著差异。除非另有说明,我们绘制的是各个 x 轴值对应单独选出的最佳性能速率的指标图。我们发现最佳学习率并没有随其他参数的改变而发生太大的变化。
⁵ 我们在这些数据集的不平衡版本上进行了额外的实验,发现它们实际上对 FedAvg 来说稍微更容易一些。
⁶ 我们始终使用字符 (character) 来指代一个单字节字符串,并使用角色 (role) 来指代戏剧中的角色。
增加并行度 (Increasing parallelism)
我们首先对客户端比例 CCC 进行实验,该参数控制多客户端的并行度。表 1 显示了改变 CCC 对两种 MNIST 模型的影响。我们报告了达到目标测试集准确率所需的通信轮数。为了计算这个值,我们为每个参数设置组合构建了一条学习曲线,如上文所述优化 η\\etaη,然后通过在之前所有轮次中取得最佳测试集准确率,使得每条曲线单调递增。随后,我们使用构成曲线的离散点之间的线性插值来计算曲线越过目标准确率的轮数。通过参考图 2(图中灰线显示目标)可以最好地理解这一点。
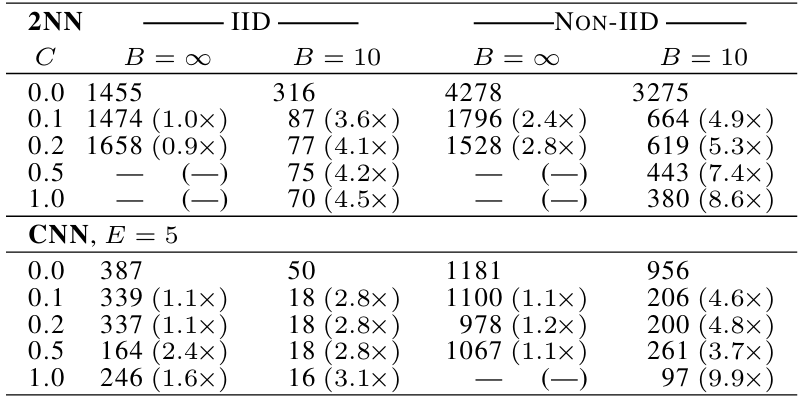
表 1 说明:
本表展示了客户端比例 CCC 对 MNIST 2NN (设定 E=1E = 1E=1) 和 CNN (设定 E=5E = 5E=5) 模型的影响。注意 C=0.0C = 0.0C=0.0 对应于每轮仅一个客户端;由于我们对 MNIST 数据使用 100 个客户端,这些行分别对应于 1、10、20、50 和 100 个客户端参与。每个表格条目给出了达到目标测试集准确率(2NN 为 97%,CNN 为 99%)所需的通信轮数,以及相对于 C=0C = 0C=0 基线的加速比。其中五次使用大批量的运行未在允许的时间内达到目标准确率。
在 B=∞B = \\inftyB=∞(对于 MNIST 而言,每轮将所有 600 个客户端样本作为一个单批次处理)的情况下,增加客户端比例的优势非常小。然而,使用较小的批次大小 B=10B = 10B=10 时,使用 C≥0.1C \\ge 0.1C≥0.1 会有显著的改进,尤其是在非 IID 的情况下。基于这些结果,在我们大多数剩余实验中,我们将 CCC 固定为 0.1,这在计算效率和收敛速度之间取得了良好的平衡。比较表 1 中 B=∞B = \\inftyB=∞ 和 B=10B = 10B=10 两列达到目标所需轮数,可以看到戏剧性的加速,我们在下文中将对此进行研究。
增加每个客户端的计算量 (Increasing computation per client)
在本节中,我们固定 C=0.1C = 0.1C=0.1,并在每一轮增加每个客户端的计算量——这可以通过减小 BBB、增加 EEE 或两者兼施来实现。图 2 表明,每轮增加局部 SGD 的更新次数可以极大地降低通信成本,表 2 则量化了这些加速。每轮每个客户端的预期更新次数为 u=(E[nk]/B)E=nE/(KB)u = (\\mathbb{E}[n_k]/B)E = nE/(KB)u=(E[nk]/B)E=nE/(KB),其中期望是对随机抽取客户端 kkk 求的。我们在表 2 的每个部分根据该统计量对行进行了排序。我们看到通过调整 EEE 和 BBB 来增加 uuu 都是有效的。只要 BBB 足够大以充分利用客户端硬件上的可用并行性,降低它实际上不会带来计算时间上的成本,因此在实践中它应该是首先被调优的参数。
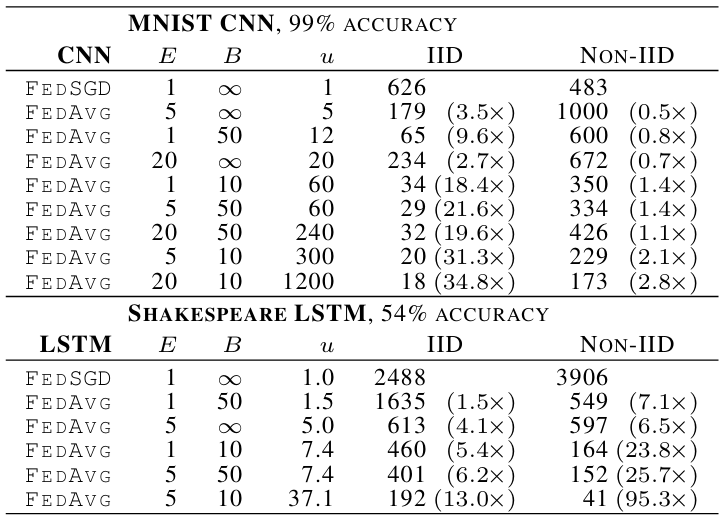
表 2 说明:
本表展示了达到目标准确率所需的通信轮数:FedAvg 对比 FedSGD(第一行,设定为 E=1E = 1E=1 和 B=∞B = \\inftyB=∞)。uuu 列给出了 u=En/(KB)u = En/(KB)u=En/(KB),即每轮预期的更新次数。上半部分是 MNIST CNN,目标准确率为 99%;下半部分是 Shakespeare LSTM,目标准确率为 54%。均列出了 IID 和 Non-IID 下的结果及加速倍数。
对于 MNIST 数据的 IID 划分,在每个客户端上使用更多的计算量使达到目标准确率所需的轮数大幅减少:CNN 减少了 35 倍,2NN 减少了 46 倍(详见附录 A 中的表 4 以获取 2NN 的细节)。病态划分的 Non-IID 数据的加速效果稍弱,但依然显著(2.8 – 3.7 倍)。当我们天真地对在完全不同的一对数字上训练出的模型参数进行平均时,发现这种平均竟然能提供任何优势(而没有导致实际发散),这是令人印象深刻的。因此,我们将此视为这种方法鲁棒性的有力证据。
Shakespeare 数据集(按剧中角色划分)不平衡和非独立同分布的特性,更能代表我们在实际应用中预期会遇到的数据分布种类。令人鼓舞的是,对于这个问题,在 non-IID 且不平衡的数据上学习实际上要容易得多(达到了 95 倍的加速,而平衡的 IID 数据只有 13 倍加速);我们推测这在很大程度上是因为有些角色拥有相对庞大的本地数据集,这使得增加局部训练变得尤为有价值。
对于所有三个模型类别,FedAvg 最终收敛到的测试集准确率都高于基线 FedSGD 模型。即使我们将测试线条延长超出所绘范围,这一趋势依然持续。例如,对于 CNN 模型,B=∞,E=1B = \\infty, E = 1B=∞,E=1 的 FedSGD 模型最终在 1200 轮后达到 99.22% 的准确率(并且直到 6000 轮都没有进一步提高),而 B=10,E=20B = 10, E = 20B=10,E=20 的 FedAvg 模型在仅 300 轮后就达到了 99.44% 的准确率。我们推测,除了降低通信成本外,模型平均还能产生类似于 dropout [36] 所带来的正则化效益。
我们主要关注泛化性能,但 FedAvg 在优化训练损失方面也很有效,甚至在测试集准确率达到平台期之后依然如此。我们观察到所有三个模型类都有类似的行为,并在附录 A 的图 6 中展示了 MNIST CNN 的图表。
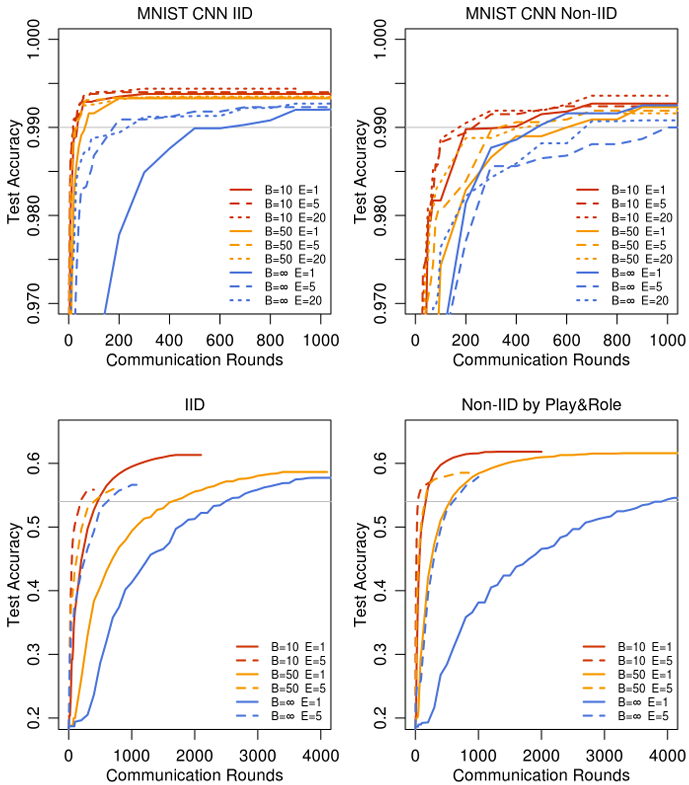
图 2 说明:
对于 MNIST CNN(先是 IID,然后是病态 non-IID)和 Shakespeare LSTM(先是 IID,然后是按 Play&Role 划分),在 C=0.1C = 0.1C=0.1 且优化 η\\etaη 的情况下,测试集准确率与通信轮数的关系。灰线显示表 2 中使用的目标准确率。2NN 模型的图表作为附录 A 中的图 7 给出。
我们会在客户端数据集上过度优化吗? (Can we over-optimize on the client datasets?)
当前的全局模型参数仅仅通过初始化的方式影响每个 ClientUpdate 内部的优化。因此,随着 E→∞E \\rightarrow \\inftyE→∞,至少对于凸问题,最终初始条件应该是无关紧要的,无论如何初始化都会达到全局最小值。即使对于非凸问题,我们也可以猜想,只要初始化位于同一个吸引盆内,算法就会收敛到相同的局部最小值。也就是说,我们预计虽然一轮平均可能会产生一个合理的模型,但额外的通信(和平均)轮次可能不会带来进一步的改进。
图 3 展示了在 Shakespeare LSTM 问题中,初始训练阶段使用极大 EEE 值的影响。事实上,对于非常大量的本地 epoch,FedAvg 可能会陷入停滞或发散。⁷ 这一结果表明,对于某些模型,尤其是在收敛的后期阶段,减少每轮本地计算的数量(通过转而使用更小的 EEE 或更大的 BBB)可能会有帮助,其方式与衰减学习率类似。附录 A 中的图 8 给出了针对 MNIST CNN 的类比实验。有趣的是,对于这个模型,在较大的 EEE 值下,我们没有看到收敛速度有显著下降。然而,在下文描述的大规模语言建模任务中,与 E=5E = 5E=5 相比,我们确实观察到 E=1E = 1E=1 时表现略好(参见附录 A 中的图 10)。
⁷ 请注意,由于这种行为,并且由于在较大 EEE 值下并未对所有学习率运行完整的轮次,我们在图 3 中报告的是固定学习率下的结果(令人惊讶的是,该学习率在整个 EEE 参数范围内近乎最佳),并且未强制这些线条呈现单调性。
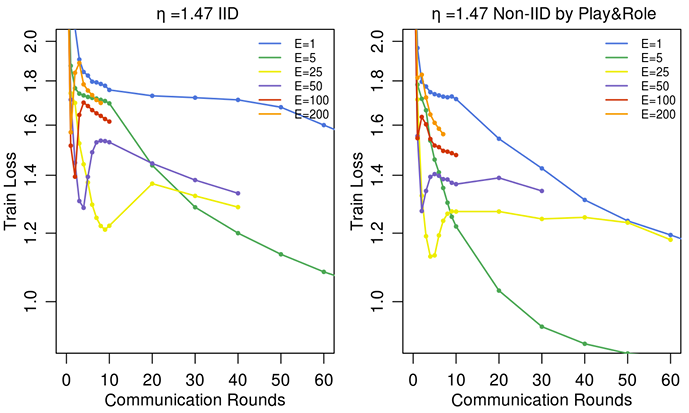
图 3 说明:
设定 B=10B = 10B=10 且 C=0.1C = 0.1C=0.1,Shakespeare LSTM 在固定学习率 η=1.47\\eta = 1.47η=1.47 的情况下,在各平均步骤之间训练众多本地 epoch(大 EEE 值)所产生的影响。
CIFAR 实验 (CIFAR experiments)
我们还在 CIFAR-10 数据集 [24] 上进行了实验,以进一步验证 FedAvg。该数据集由 10 个类别的 32×32 RGB 彩色图像组成。共有 50,000 个训练样本和 10,000 个测试样本。我们将它们划分到 100 个客户端中,每个客户端包含 500 个训练样本和 100 个测试样本;由于该数据没有自然的用户分布属性,我们考虑的是平衡且 IID 的场景。模型架构取自 TensorFlow 教程 [38],由两个卷积层、两个全连接层和一个输出 logits 的线性变换层组成,总计约 10610^6106 个参数。请注意,目前的先进方法在 CIFAR 上已达到 96.5% 的测试准确率 [19];尽管如此,我们使用的标准模型足以满足我们的需求,因为我们的目标是评估我们的优化方法,而不是在此任务上达到尽可能高的准确率。图像预处理作为训练输入管道的一部分进行,包括将图像裁剪为 24×24,随机左右翻转,以及调整对比度、亮度和进行白化处理。
对于这些实验,我们考虑了一个额外的基线方法:在完整训练集(无用户划分)上使用大小为 100 的小批量进行标准 SGD 训练。该方法在 197,500 次小批量更新(在联邦场景中,每次小批量更新都需要一轮通信)后达到了 86% 的测试准确率。而 FedAvg 在仅仅 2,000 轮通信后,就实现了类似的 85% 的测试准确率。对于所有算法,除了初始学习率之外,我们还调优了学习率衰减参数。表 3 给出了基线 SGD、FedSGD 和 FedAvg 达到三个不同目标准确率所需的通信轮数,图 4 则展示了 FedAvg 与 FedSGD 的学习率曲线对比。
通过在 SGD 和 FedAvg 两者上都运行小批量大小 B=50B = 50B=50 的实验,我们还可以考察准确率作为这样的小批量梯度计算次数的函数的表现。我们预计标准 SGD 在这里会做得更好,因为在每次小批量计算后都会依次迈出更新的步子。然而,正如附录中的图 9 所展示的那样,对于中等的 CCC 和 EEE 值,FedAvg 在每次小批量计算中取得的进展与之不相上下。此外,我们看到标准 SGD 和仅有一名客户端(C=0C = 0C=0)的 FedAvg 在准确率上都表现出显著的震荡,而在更多客户端上进行平均则平滑了这些波动。
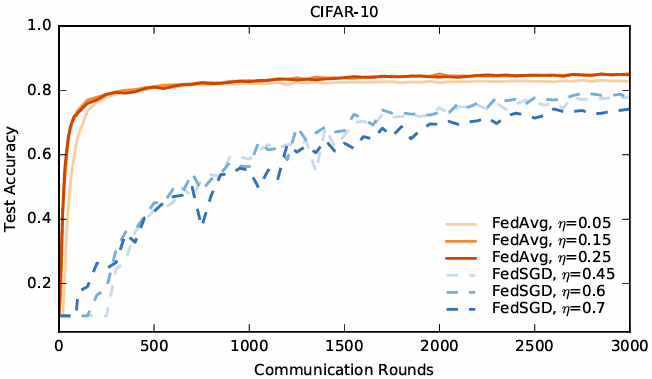
图 4 说明:
CIFAR-10 实验的测试准确率与通信轮数对比。FedSGD 使用每轮 0.9934 的学习率衰减;FedAvg 使用 B=50B = 50B=50,每轮 0.99 的学习率衰减,并且 E=5E = 5E=5。

表 3 说明:
在 CIFAR10 上达到目标测试集准确率所需的通信轮数及相较于基线 SGD 的加速比。SGD 设定小批量大小为 100。FedSGD 和 FedAvg 都使用 C=0.1C = 0.1C=0.1,其中 FedAvg 使用 E=5E = 5E=5 和 B=50B = 50B=50。表格给出了 80%、82% 和 85% 三个准确率阈值下的对比数据。
大规模 LSTM 实验 (Large-scale LSTM experiments)
我们在一个大规模的下一个词预测任务上进行了实验,以证明我们的方法在真实世界问题上的有效性。我们的训练数据集包括来自一个大型社交网络的 1000 万条公开帖子。我们按作者对帖子进行分组,总计超过 500,000 个客户端。这个数据集非常真实地模拟了用户移动设备上可能存在的文本输入类型数据。我们限制每个客户端的数据集最多不超过 5000 个单词,并在一个包含 10 万条不同(非训练)作者帖子的测试集上报告准确率(准确率被定义为在 10000 种可能性的词汇表中,预测概率最高的正是正确下一个词的数据比例)。我们的模型是一个在 10000 词汇量上的 256 节点 LSTM。每个单词的输入和输出嵌入维度均为 192,并与模型协同训练;总计有 4,950,544 个参数。我们使用 10 个单词的展开长度。
这些实验需要大量的计算资源,因此我们没有那么彻底地探索超参数:所有的运行每轮均抽取 200 个客户端进行训练;FedAvg 使用了 B=8B = 8B=8 和 E=1E = 1E=1。我们探索了针对 FedAvg 和基线 FedSGD 的一系列学习率。图 5 显示了最佳学习率的单调学习曲线。当 η=18.0\\eta = 18.0η=18.0 时,FedSGD 需要 820 轮才能达到 10.5% 的准确率,而 η=9.0\\eta = 9.0η=9.0 时,FedAvg 仅在 35 轮通信后就达到了 10.5% 的准确率(所需通信轮数比 FedSGD 少 23 倍)。我们观察到 FedAvg 测试准确率的方差较低,详情见附录 A 的图 10。该图还包括了 E=5E = 5E=5 时的结果,它表现得比 E=1E = 1E=1 稍差一点。
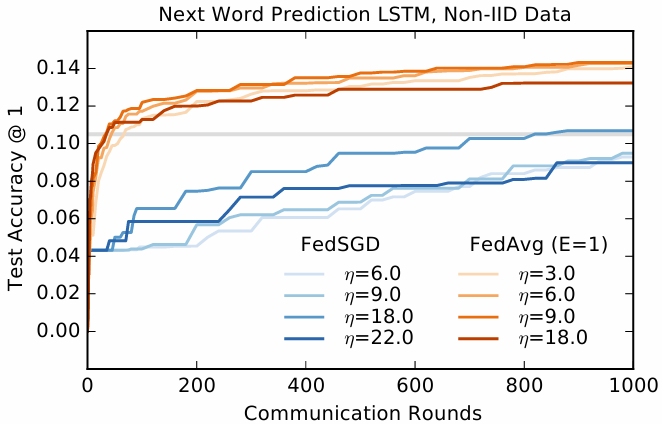
图 5 说明:
在非独立同分布数据上的大规模语言模型词级 LSTM 的单调学习曲线比较。显示了不同学习率下的 FedSGD 与 FedAvg (E=1) 的对比。
4 结论和未来工作 (Conclusions and Future Work)
我们的实验表明,联邦学习可以做到具有实用性,因为 FedAvg 通过利用相对较少的通信轮次就能训练出高质量的模型,这一点在多种模型架构的实验中得到了证明:包括一个多层感知机、两个不同的卷积神经网络、一个两层字符级 LSTM,以及一个大规模词级 LSTM。
虽然联邦学习提供了诸多实际的隐私保障,但是通过差分隐私 [14, 13, 1]、安全多方计算 [18] 或两者的结合提供更强有力的数据保障,依然是未来一个引人入胜的研究方向。值得注意的是,这两类技术都最自然地适用于像 FedAvg 这样的同步算法。⁸
⁸ 在这项工作之后,Bonawitz 等人 [6] 引入了一种用于联邦学习的高效安全聚合协议,Konečný 等人 [23] 提出了进一步降低通信成本的算法。
参考文献 (References)
见论文
附录 A: 补充图表 (A Supplemental Figures and Tables)
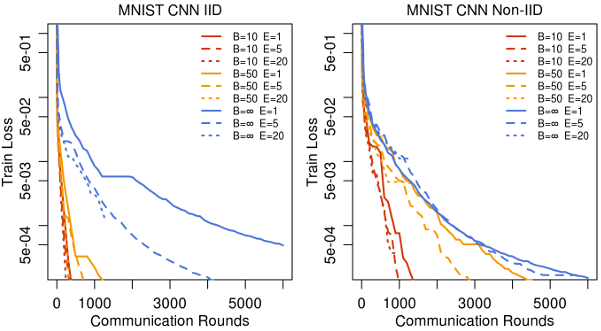
图 6 说明:
MNIST CNN 的训练集收敛情况。注意 y 轴采用对数刻度,x 轴涵盖的训练时间比图 2 更长。这些图表固定 C=0.1C = 0.1C=0.1。图示分左右,左为 IID,右为 Non-IID。
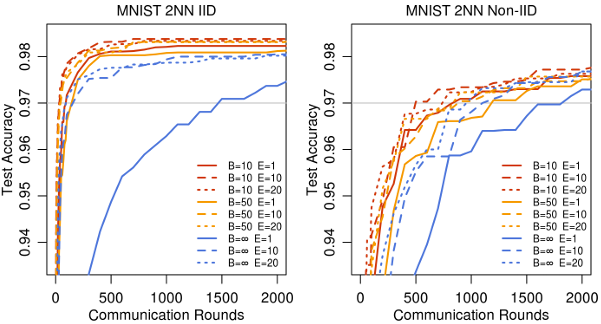
图 7 说明:
MNIST 2NN 模型在 C=0.1C = 0.1C=0.1 且优化 η\\etaη 时的测试集准确率与通信轮数。左列是 IID 数据集,右列是病态的每个客户端 2 个数字的 Non-IID 数据。
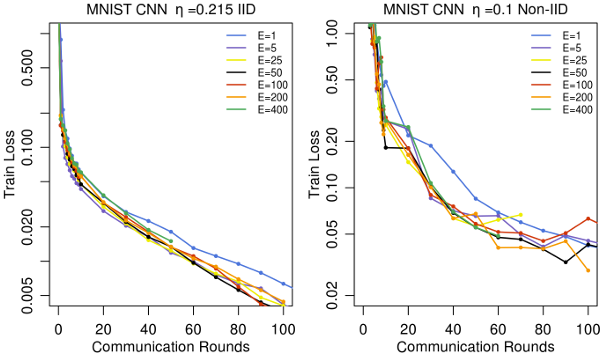
图 8 说明:
固定 B=10B = 10B=10 和 C=0.1C = 0.1C=0.1 时,在各个平均步骤之间进行多次本地轮数训练(大 EEE 值)所产生的影响。此图展示 MNIST CNN 的训练损失。注意,由于我们病态的非独立同分布(non-IID) MNIST 数据集的学习难度,使用了不同的学习率和 y 轴刻度。图示分左右,左为 IID (对应 η=0.215\\eta = 0.215η=0.215),右为 Non-IID (对应 η=0.1\\eta = 0.1η=0.1)。
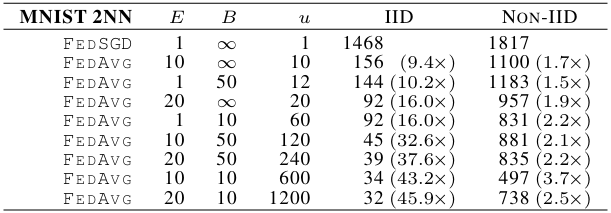
表 4 说明:
对于 MNIST 2NN 模型,达到 97% 目标准确率时 FedAvg 相较于 FedSGD(第一行)在通信轮数上的加速比表格。
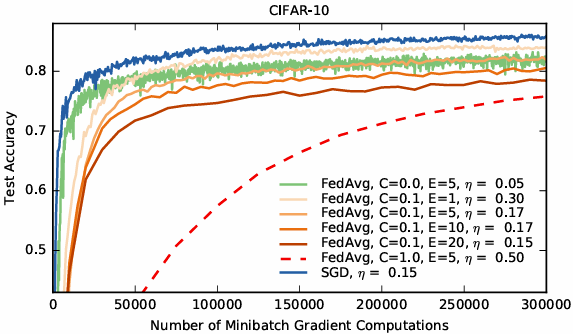
图 9 说明:
测试准确率与小批量梯度计算次数(B=50B = 50B=50)之间的关系图。基线是标准的顺序 SGD (绿色细线),与采用不同客户端比例 CCC(回忆一下,C=0C = 0C=0 意味着每轮只有一个客户端)和不同本地 epoch 数 EEE 的 FedAvg 进行对比。
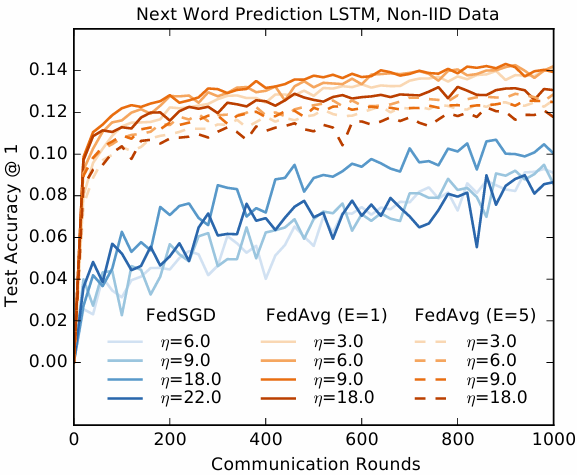
图 10 说明:
大规模语言模型词级 LSTM 的学习曲线,每 20 轮评估一次。在较少的本地 epoch 下(1 优于 5),FedAvg 实际上表现更好,而且与 FedSGD 相比,在跨轮次评估时测试准确率的方差也更小。
论文下载地址:https://arxiv.org/abs/1602.05629





评论前必须登录!
注册