 网硕互联帮助中心
网硕互联帮助中心提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、前言
- 二、YOLOv13的核心创新
-
- 1. 自适应超图相关性增强(HyperACE)
- 2. 全流程聚合与分发(FullPAD)范式
- 3. 基于深度可分离卷积的全流程轻量化
- 三、YOLOv13性能基准
- 四、环境搭建(windows版本)
-
- 1、基础环境搭建
- 2. requirements.txt安装
- 3. 安装flash-attention
- 4. 环境验证
- 五、量化流程
-
- 1. 在上述环境中安装量化依赖库
- 2. 导出 yolov13 torchscript
- 3. 转换静态尺寸输入的 torchscript
- 4. 修改 yolov13n_pnnx.py 模型脚本,支持动态尺寸输入
- 5. 注意力模块,修改支持动态尺寸输入
- 6. HGNN模块,修改支持动态尺寸输入
一、前言
YOLOv13于2025年6月重磅发布,提出了一种基于超图增强自适应视觉感知的全新架构,这彻底跳脱了YOLOv12所依赖的注意力机制和YOLOv11及更早版本的卷积范式。该模型通过引入超图理论来建模复杂的全局高阶语义关联,在显著提升目标检测准确性的同时,巧妙地控制了计算开销,维持了出色的实时推理性能。 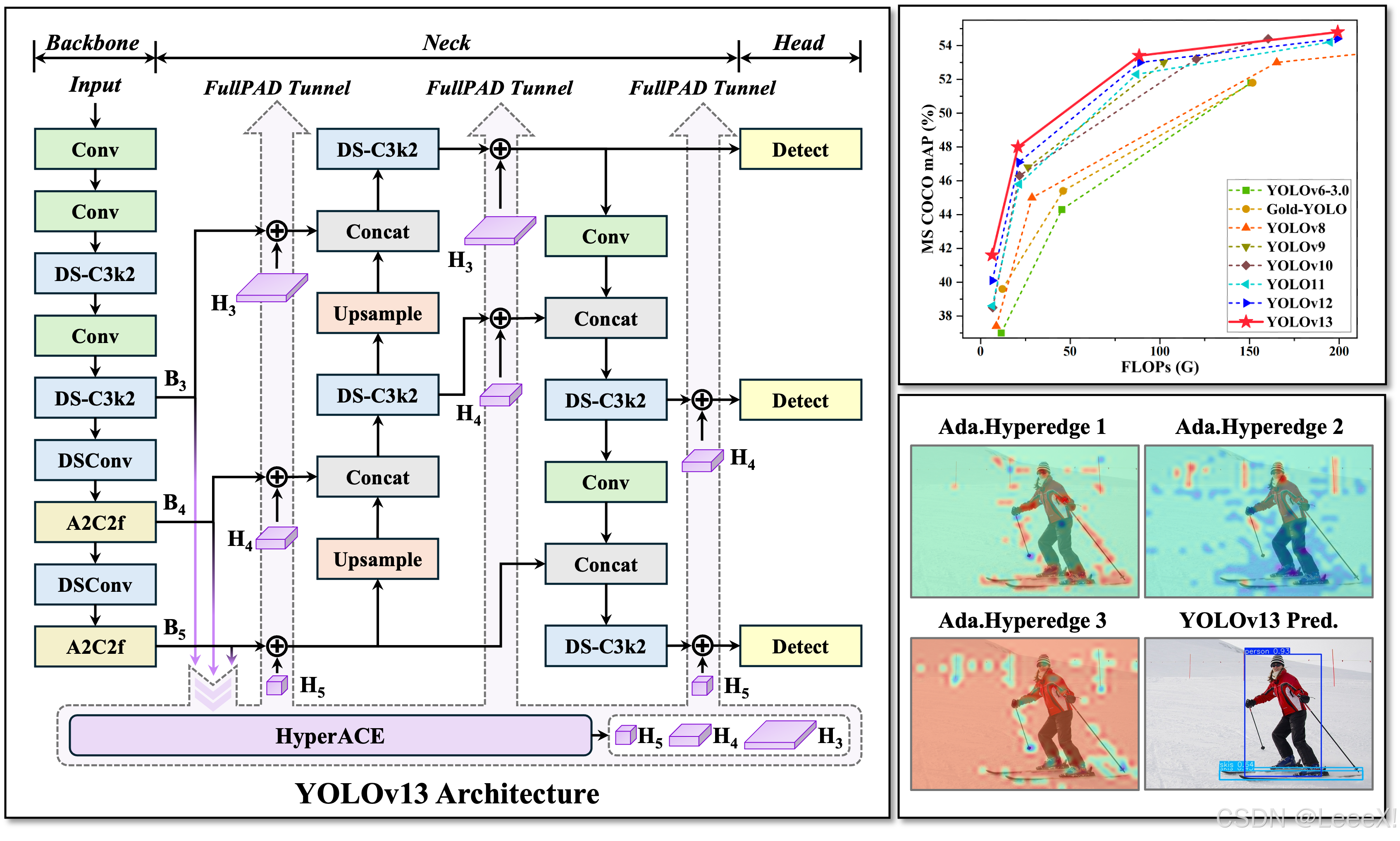 本文将深入解析YOLOv13的架构创新,重点介绍其自适应超图相关性增强(HyperACE) 机制和全流程聚合分发(FullPAD) 范式,如何通过轻量化设计实现效率与精度的双重突破,然后详细展示如何将YOLOv13模型通过PNNX转换并部署到NCNN框架,实现高性能目标检测。
本文将深入解析YOLOv13的架构创新,重点介绍其自适应超图相关性增强(HyperACE) 机制和全流程聚合分发(FullPAD) 范式,如何通过轻量化设计实现效率与精度的双重突破,然后详细展示如何将YOLOv13模型通过PNNX转换并部署到NCNN框架,实现高性能目标检测。
YOLOv13代码仓库: https://github.com/iMoonLab/yolov13 YOLOv13论文: https://arxiv.org/abs/2506.17733 ncnn-android-yolov13: https://github.com/LeeeFu/ncnn-android-yolov13
二、YOLOv13的核心创新
1. 自适应超图相关性增强(HyperACE)
在计算机视觉领域,无论是传统的卷积操作还是YOLOv12引入的区域注意力,都受限于局部信息聚合或成对(pairwise)像素关系建模。它们难以捕捉图像中真实存在的、超越两两交互的多对多高阶语义关联(例如,一辆车由车身、轮毂、车窗等多个部件协同构成)。YOLOv13通过引入自适应超图相关性增强(Hypergraph-based Adaptive Correlation Enhancement, HyperACE) 机制来解决这一根本性问题。 该机制将特征图中的像素视为顶点(vertices),并通过一个可学习的模块动态生成超边(hyperedges)。每条超边可以连接任意数量的顶点,从而一次性建模群组间的复杂关系。不同于依赖手工阈值构建超图的脆弱方法,HyperACE通过计算每个顶点对每条超边的连续参与度权重,形成了一个鲁棒且表达力强的关联矩阵。其内部采用“顶点→超边聚合”和“超边→顶点分发”的两阶段消息传递,实现了高效的全局特征融合,并通过线性复杂度优化确保了实时性。 在COCO数据集上,YOLOv13-N(Nano版本)实现了42.1% mAP,较YOLOv12-N的40.6% 提升了1.5%。关键优势在于其高阶语义理解能力:可视化结果表明,YOLOv13能更准确地处理遮挡(如花瓶后的植物)、区分目标与阴影(如网球拍),并在复杂场景中产生更可靠的检测结果,误检率显著降低。
2. 全流程聚合与分发(FullPAD)范式
传统的YOLO架构遵循严格的单向信息流:骨干网络 → 颈部网络 → 检测头。这种设计导致高层语义信息难以有效回溯至底层特征,造成小目标细节在深层网络中丢失。为了解决这一瓶颈,YOLOv13提出了全流程聚合与分发(Full-Pipeline Aggregation-and-Distribution, FullPAD) 范式。 该范式将HyperACE模块生成的、富含全局高阶语义的增强特征,通过可学习的门控融合机制,精准地反向注入到网络的三个关键节点:骨干与颈部连接处、颈部内部以及颈部与检测头连接处。这种“聚合-分发”的闭环设计,打破了单向信息流的壁垒,不仅极大地改善了梯度流动,缓解了梯度消失问题,还实现了全网络范围内的精细化信息协同。实验表明,FullPAD范式使COCO小目标AP提升了2.3%,显著增强了模型对细节的感知能力。
3. 基于深度可分离卷积的全流程轻量化
为了在引入强大的HyperACE和FullPAD后依然保持模型的轻量与高效,YOLOv13设计了一系列基于DSConv的新型轻量化模块:
三、YOLOv13性能基准
了解架构革新后,我整理了官方YOLO13和YOLOv12的测试数据,做成下面这个对比表。下表基于COCO val2017数据集,在相同硬件配置下对比YOLOv13与YOLOv12各尺寸模型的性能表现:
| YOLOv12n | 640 | 40.4 | 1.60 | 2.5 | 6.0 |
| YOLOv13n | 640 | 42.1 | 1.97 | 2.2 | 4.8 |
| YOLOv12s | 640 | 47.6 | 2.42 | 9.1 | 19.4 |
| YOLOv13s | 640 | 48.0 | 3.20 | 9.0 | 20.8 |
| YOLOv12m | 640 | 52.5 | 4.27 | 19.6 | 59.8 |
| YOLOv13m | 640 | 53.5 | 5.10 | 18.5 | 60.0 |
| YOLOv12l | 640 | 53.8 | 5.83 | 26.5 | 82.4 |
| YOLOv13l | 640 | 55.2 | 7.50 | 24.5 | 68.3 |
| YOLOv12x | 640 | 55.4 | 10.38 | 59.3 | 184.6 |
| YOLOv13x | 640 | 56.8 | 13.80 | 55.0 | 152.6 |
几个关键发现: YOLOv13-N比YOLOv12-N高1.5% mAP,同时参数量和FLOPs更低。这证明了超图驱动的高阶建模在提升精度方面的巨大潜力。与竞品的对比 与同类模型相比,YOLOv13展现出全面优势。与YOLO系列前代比较,所有尺寸模型均取得SOTA精度,且模型更轻量。定性分析显示YOLOv13在复杂场景(如密集、遮挡)和小目标检测上具有显著优势,能有效区分易混淆目标。 目前,YOLOv13主要专注于目标检测任务。虽然其架构设计为未来扩展(如分割、姿态估计)奠定了良好基础,但官方尚未发布相关模型。对于需要多功能一体的用户,YOLOv11或YOLOv12仍是更全面的选择。
四、环境搭建(windows版本)
注:利用Anaconda来搭建windows基础环境,YOLOv13推荐python3.11、pyTorch 2.4.1、torchvision 0.19.1、torchaudio 2.4.1 ultralytics 8.3.63 一定要在cuda12以上的环境,适配后面的flash-attention包
1、基础环境搭建
#1. 创建虚拟环境
conda create -n yolov13 python=3.11
#2. 进入虚拟环境
conda activate yolov13
#3. 下载YOLOv13源码
git clone https://github.com/iMoonLab/yolov13.git
#4. 下载预训练权重
wget https://github.com/iMoonLab/yolov13/releases/download/yolov13/yolov13n.pt
wget https://github.com/iMoonLab/yolov13/releases/download/yolov13/yolov13s.pt
#5. 安装pytorch(GPU),如果网速比较慢,我们也可以科学上网下载后,进行离线安装
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 –index-url https://download.pytorch.org/whl/cu124
离线安装包下载地址:http://download.pytorch.org/whl/torch_stable.html 也可以通过离线安装方式,但可能存在最新的包名找不到的问题 打开链接后,我们找到以下对应版本,torch2.4.1, torchvision0.19.1,torchaudio==2.4.1, 依次下载后,在环境中进行pip install 安装 顺序以此是:torch –>torchvision–>trochaudio 按照以上方式,在环境中成功安装torch相关工具 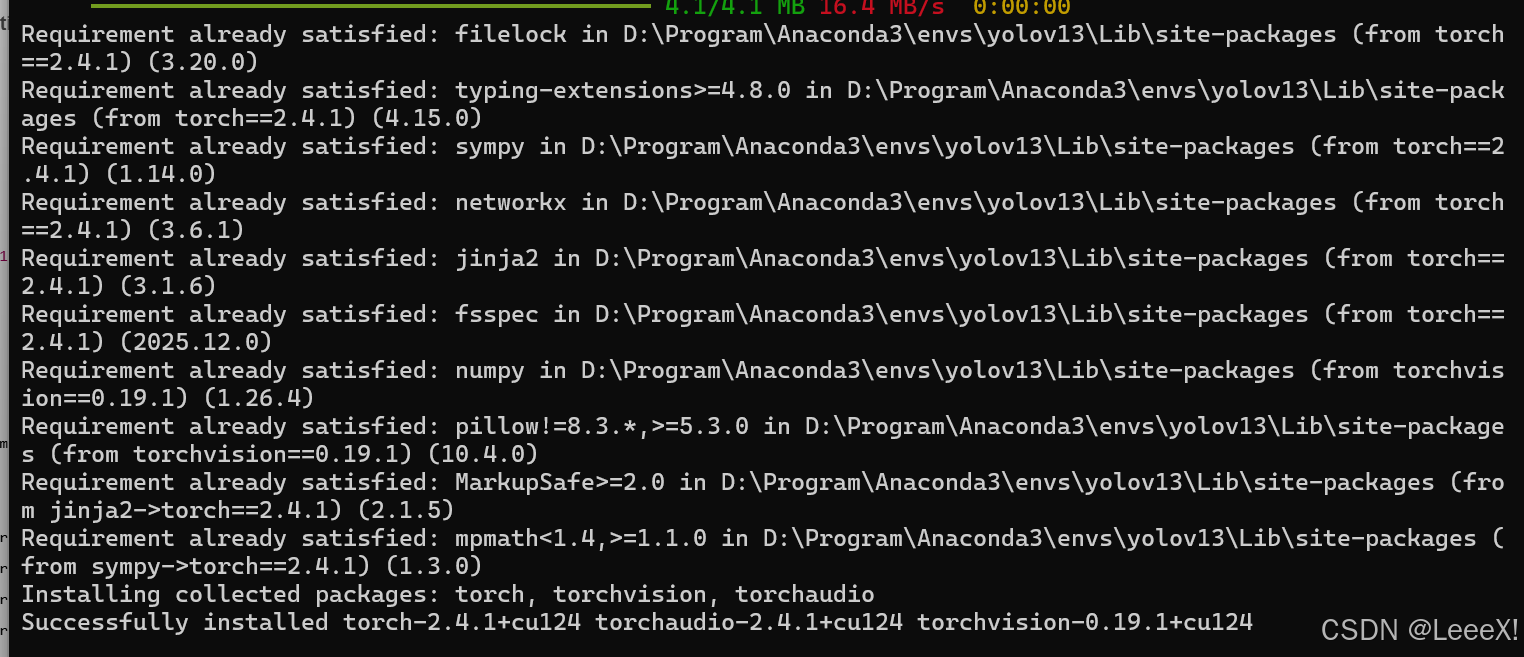
2. requirements.txt安装
进入yolov13-main 这个文件夹,将前三行给注释掉,因为torch相关的我们已经手动完成安装,以及flash_attn组件是linux版本,我们windows上的需要手动安装。 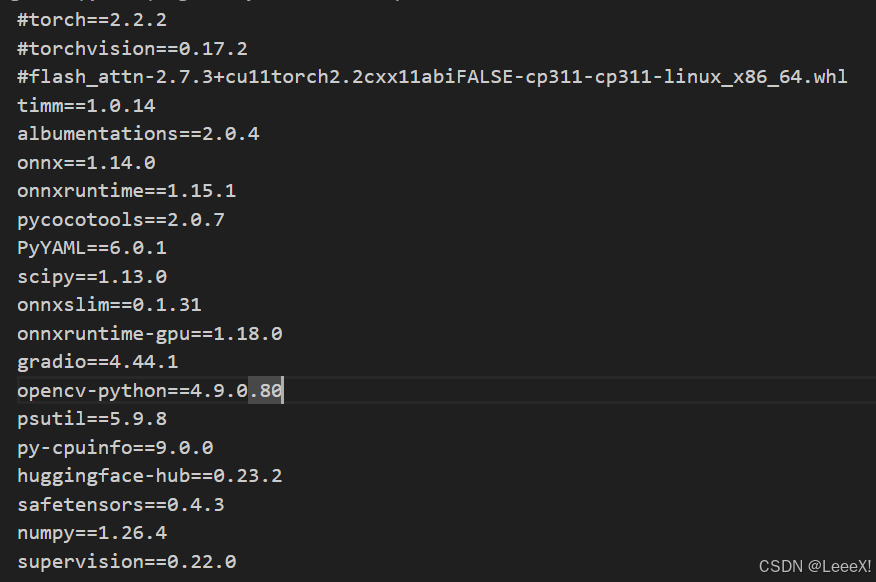 之后进行安装
之后进行安装
#下载比较慢的话,可以添加镜像源
pip install -r requirements.txt
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e .
3. 安装flash-attention
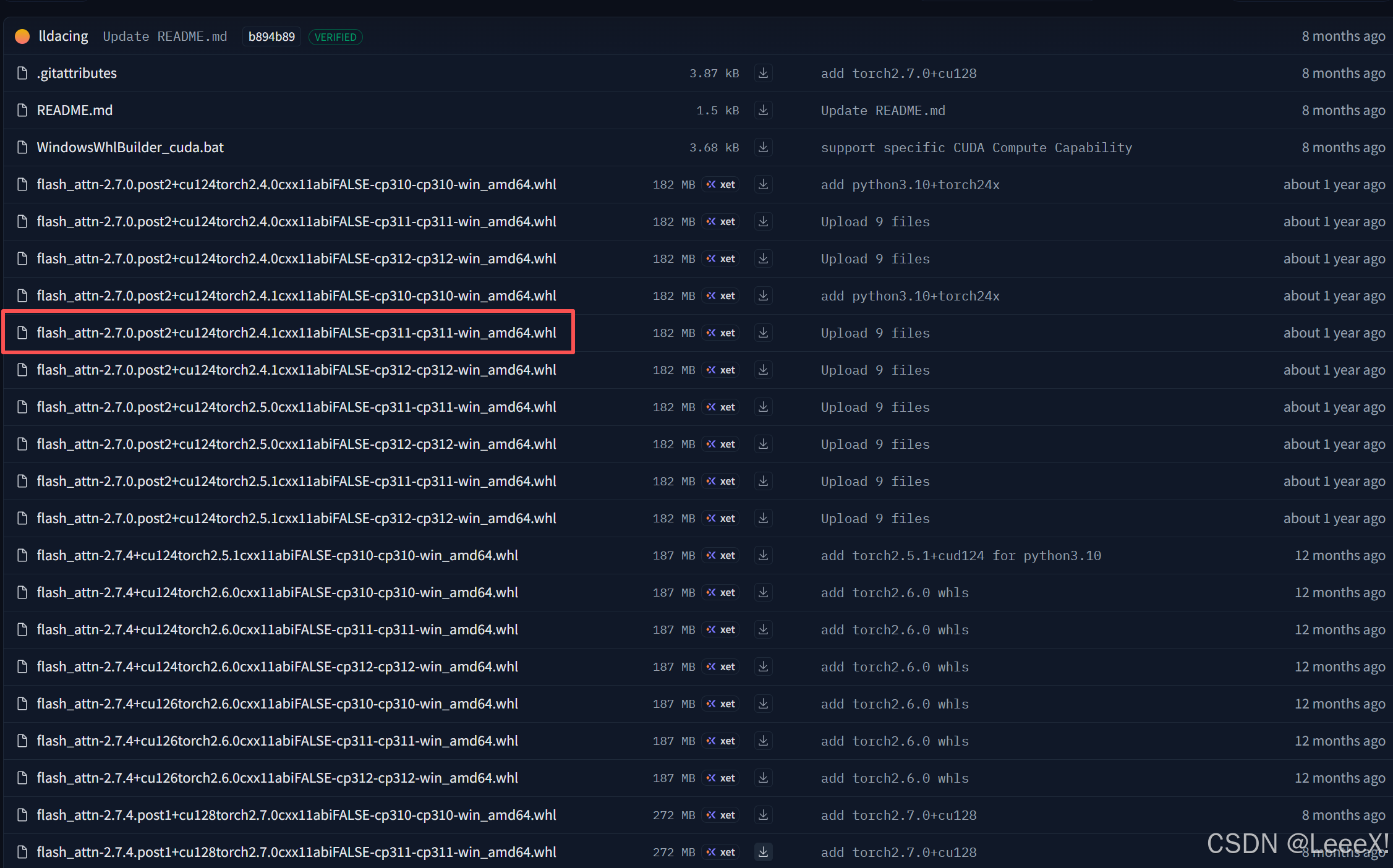
flashAttention是高效、内存优化的注意力机制的实现方式,能显著加速 Transformer 或注意力模块的计算,并降低 GPU 显存占用。 进入flash-attention,选中相对应版本,下载完成之后需要本地安装,复制到yolov13-main文件夹中,cd到yolov13-main文件夹后,进行安装。
pip install flash_attn-2.7.0.post2+cu124torch2.4.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
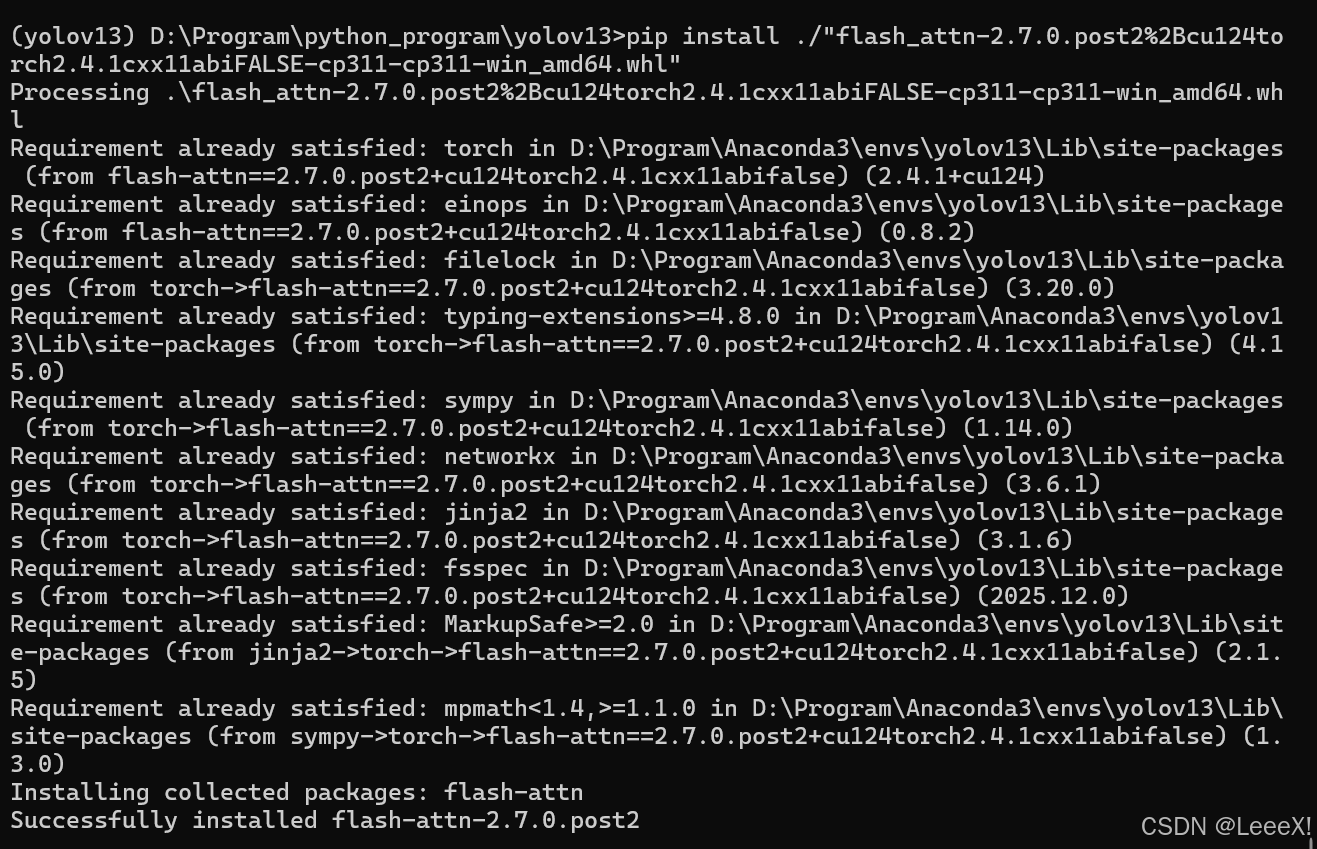 安装完成之后,我们通过下面代码来校验环境,看是否存在问题,如果都可以正常输出,则没有问题
安装完成之后,我们通过下面代码来校验环境,看是否存在问题,如果都可以正常输出,则没有问题
import torch
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
print("CUDA version used to build PyTorch:", torch.version.cuda)
from flash_attn import flash_attn_func
print("✅ flash_attn imported successfully!")
4. 环境验证
在yolov13-main文件夹中创建一个infer.py脚本,加载检测预训练权重,确保环境没有问题
from ultralytics import YOLO
model = YOLO('yolov13{n/s}.pt')
model.predict(source='bus.jpg',save=True)
 
五、量化流程
1. 在上述环境中安装量化依赖库
pip install -U pnnx ncnn
2. 导出 yolov13 torchscript
yolo export model=yolov13n.pt format=torchscript
一定要将生成的.torchscript后缀的模型单独放置文件夹,后面步骤会生成比较多的文件
3. 转换静态尺寸输入的 torchscript
pnnx yolov13n.torchscript
在进行转换时,会出现一些警告,提示强制将所有1维tensor(shape.size() == 1)的batch轴设置为233,和对于所有经过batch轴推断过程后仍然没有设置__batch_index参数的operand,作为最后的fallback,将其batch轴设置为233,经过测试,对于后面结果暂时还没有影响…  之后会生成以下多个文件
之后会生成以下多个文件 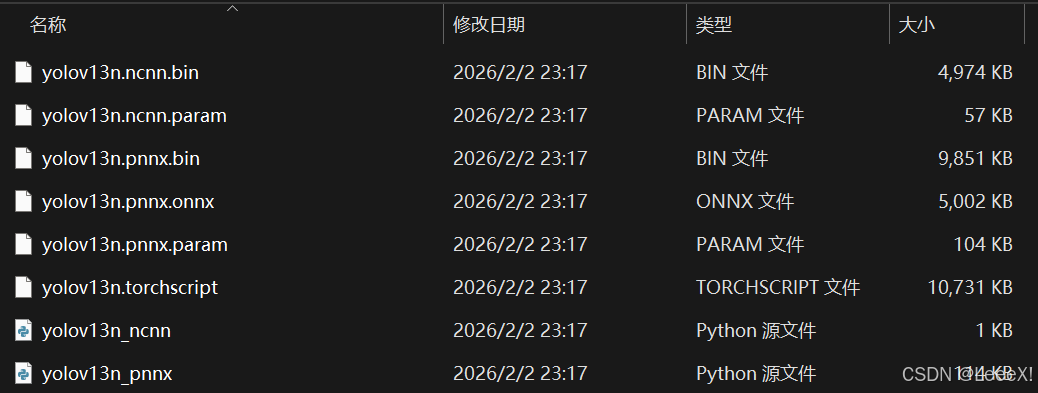
4. 修改 yolov13n_pnnx.py 模型脚本,支持动态尺寸输入
5. 注意力模块,修改支持动态尺寸输入
6. HGNN模块,修改支持动态尺寸输入
未完待续-260202–
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷






评论前必须登录!
注册