 网硕互联帮助中心
网硕互联帮助中心在 Java 后端开发中,JVM 调优往往被视为“黑魔法”或“高级技能”。很多同学在面试中能背诵参数,但遇到线上 OOM 或卡顿时却无从下手。
本文将剥离复杂的术语外壳,从最基础的 GC 定义讲起,通过三个真实的大厂生产案例,带你理解为什么要调优、怎么调优。
一、 必知必会:核心背景知识
在谈“调优”之前,我们必须先对齐几个核心概念。JVM 的内存区域就像一个巨大的仓库,而垃圾回收器(GC)就是不知疲倦的保洁员。
1. 垃圾回收的几种姿势
-
Young GC (YGC / Minor GC)
-
定义:只清理年轻代 (Young Gen) 的垃圾回收。
-
特点:发生的非常频繁,速度也很快。因为年轻代的对象大多是“朝生夕死”的(如 HTTP 请求中的临时对象)。
-
-
Old GC (Major GC)
-
定义:只清理老年代 (Old Gen) 的垃圾回收。
-
注意:只有 CMS 收集器会有单独的 Old GC 阶段。
-
-
Full GC
-
定义:“全场大扫除”。它会同时清理 年轻代 + 老年代 + 方法区(元空间)。
-
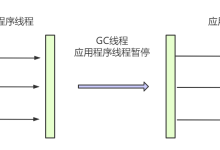
特点:它是我们调优的“头号敌人”。因为涉及范围太广,通常会导致长时间的 STW (Stop The World),即全场暂停,业务停摆。
-
-
Serial Old
-
定义:最古老的、单线程的垃圾回收器,采用 标记-整理 算法。
-
地位:它是 CMS 和 G1(JDK8)的兜底方案。当这些先进的并发收集器“搞不定”时(比如内存碎片太多、分配失败),JVM 会强制退化为 Serial Old,单线程慢慢整理内存。这是系统卡死的主要原因。
-
2. 什么是 JVM 调优?
所谓的调优,并不是去修改 Java 代码逻辑,而是通过调整 JVM 的启动参数,来平衡内存空间与响应时间。
我们手里能调节的“旋钮”主要包括:
-
定地盘:堆内存大小 (-Xms, -Xmx)。
-
分比例:年轻代/老年代比例 (-XX:NewRatio),Eden/Survivor 比例 (-XX:SurvivorRatio)。
-
选工具:指定使用哪种回收器(CMS, G1, ZGC 等)。
-
定目标:设置最大停顿时间 (-XX:MaxGCPauseMillis,G1 专用)。
3. 为什么要调优?
JVM 默认参数是通用的,但业务场景是多变的。不做调优,可能会导致以下问题:
Eden 区太小:导致 Young GC 极其频繁,业务吞吐量下降。
Survivor 区太小:导致对象过早“偷渡”到老年代,诱发 Full GC。
Full GC 频繁:老年代堆积了太多本该死在年轻代的对象,导致系统经常性卡顿。
调优的核心目的只有两个:
吞吐量优先:让 CPU 更多时间在干业务,而不是在收垃圾。
响应时间优先:极力避免 Full GC,缩短 STW 时间,不让用户感觉到卡。
4. 什么是吞吐量 (Throughput)?
在 JVM 的语境下,吞吐量的定义非常硬核:
吞吐量 = ( 用户代码运行时间 ) / ( 用户代码运行时间 + 垃圾回收时间 )
简单来说:吞吐量就是CPU 在单位时间内,有多少时间是在干正事(跑业务),有多少时间是在摸鱼(收垃圾)。
二、 实战演练:从案例看调优逻辑
如果在面试中,你不敢说自己亲自调过参数,那么深入理解以下三个基于真实生产环境的案例,也能证明你具备调优的思维。
案例一:反直觉的优化——内存扩大了,GC 耗时反而没变?(重点)
(注:这是经典的低延迟服务优化案例)

-
服务环境:JDK 8 + ParNew (年轻代) + CMS (老年代)
-
问题现象: 某个对延迟要求极高的服务,监控报警显示:
-
Young GC 极其频繁:每分钟高达 50 次,每次耗时约 25ms。
-
Old GC 也不消停:每隔几分钟就来一次,每次耗时 200ms。
-
-
原因分析:
-
初始配置问题:为了追求 Young GC “快”(减少 STW),开发人员故意将年轻代设置得比较小。
-
连锁反应:年轻代太小 -> 也就是盘子太小,很快就装满了 -> 触发 YGC。
-
过早晋升:因为 YGC 频率太高,很多对象还没来得及释放,S 区可能也放不下,被迫提前晋升到了老年代。老年代一满,就触发 Old GC。
-
结论:年轻代太小是万恶之源。
-
优化策略:
-
将年轻代内存扩大为原来的 3倍。
-
-
优化效果:
-
YGC 频率降低了 60%(盘子大了,装满的时间变长了)。
-
Old GC 频率降为几小时 1 次(对象在年轻代有足够的时间“自然死亡”,不再去老年代捣乱)。
-
关键点:单次 YGC 的耗时仅仅增加了 5%(从 25ms 变成 26ms 左右)。
-
-
深度原理解析:
-
很多人会问:“内存扩大 3 倍,扫地时间不应该也变成 3 倍吗?”
-
答案是不会。因为年轻代使用的是 复制算法。
-
复制算法的耗时,只取决于 “活着的对象有多少”,而不取决于 “垃圾有多少”。
-
扩容后,虽然垃圾变多了,但存活的对象数量基本不变(甚至因为存活时间够长,有些对象直接死在 Eden 了,不用复制了)。所以耗时几乎没变,但频率大幅降低。
-
案例二:CMS 的“碎片”之殇与“半夜偷袭”战术
(注:这是大厂处理 C 端核心业务的真实案例)
-
服务环境:JDK 8 + ParNew + CMS
-
问题现象: C 端核心业务接口,平时响应很快(<100ms)。但在业务高峰期,服务器偶尔会发生 Full GC,耗时甚至超过 1 秒,导致大量请求超时报错。
-
原因分析:
-
算法缺陷:CMS 采用的是 “标记-清除” 算法。这种算法只负责清除垃圾,不负责整理内存。
-
碎片累积:就像吃饭不擦桌子,时间久了,老年代全是内存碎片。
-
分配失败:高峰期突然来了很多对象,老年代虽然总空间够,但找不到一块连续的空间来存放。JVM 判定 CMS 失败,触发 Full GC。
-
优化策略:
-
战术:在业务低峰期(例如凌晨 4 点),通过定时任务调用 System.gc()。
-
原理:在 CMS 模式下,触发 Full GC 会退化为 Serial Old(或配置 CMS 进行整理),它会使用 “标记-整理” 算法,把内存碎片整理得干干净净。
-
-
优化效果:
-
每天凌晨 4 点“主动”进行一次大扫除(这时候没用户,卡顿也没事)。
-
第二天白天高峰期时,内存是整齐的,基本不再出现 Full GC。
-
案例三:G1 的“好心办坏事”
-
服务环境:JDK 8 + G1
-
问题现象: 服务切换到 G1 后,发现 Young GC 频率异常高,导致整体吞吐量下降。
-
原因分析:
-
参数误用:运维为了追求极致低延迟,将 -XX:MaxGCPauseMillis(最大暂停时间)设置得非常小(例如 50ms)。
-
G1 的反应:G1 非常听话,为了保证 50ms 内扫完,它只能拼命缩小年轻代的大小(Region 数量减少)。
-
恶性循环:年轻代变小 -> 很快满了 -> 疯狂 GC。
-
优化策略:
-
方案 A:调大 -XX:MaxGCPauseMillis(例如改为 200ms),给 G1 喘息的空间。
-
方案 B:将年轻代大小设置为固定值,不让 G1 自动瞎调整。
-
三、 总结
JVM 调优的本质,就是一场 “空间换时间” 或 “频率换单次耗时” 的博弈。
不要为了调优而调优:大多数情况下,默认参数配合良好的代码质量已经足够。
核心目标:想尽一切办法,让短期存活的对象留在年轻代,不要让它们去污染老年代。
兜底思维:理解 CMS 和 G1 的退化机制(Serial Old),避免内存碎片或担保失败导致的长时间停顿。
掌握了这些原理和案例,下次面对“JVM 调优”的问题时,你就能从容应对了。


评论前必须登录!
注册