 网硕互联帮助中心
网硕互联帮助中心深入 JVM 面试篇:OOM 与 Full GC 的终极攻防指南
作者:Weisian
发布时间:2026年2月

📌 系列导读:
在上一篇文章《不停服务修改 JVM 参数》中,我们掌握了生产环境的“微创手术”技巧。今天,我们将直面 Java 工程师最恐惧的两个噩梦——OOM (Out of Memory) 与 频繁 Full GC。
在高并发、大流量场景下,它们是压垮服务的最后一根稻草;在面试场上,它们是区分“ CRUD 工程师”与“资深架构师”的分水岭。
如果说参数调优是“术”,那么理解内存模型与 GC 行为背后的“道”,才是解决这些问题的根本。本文将从 原理认知、触发机制、规避策略、排查 SOP、面试通关 五个维度,带你彻底攻克这两座大山。
一、认知重塑:不是所有“内存不足”都叫 OOM
很多初中级工程师一遇到 OOM,第一反应就是“加内存”(-Xmx)。这是典型的治标不治本,甚至可能掩盖真正的内存泄漏,导致问题在深夜爆发。
JVM 规范定义了多种内存区域,不同的 OOM 对应完全不同的根因和解法。请务必建立以下分类认知:
📊 五大核心 OOM 类型全景图
| Java heap space | java.lang.OutOfMemoryError: Java heap space | 堆内存耗尽。对象创建速度 > GC 回收速度,或存在内存泄漏。 | ❌ (可能掩盖泄漏) | 🔴 高危 |
| GC overhead limit | java.lang.OutOfMemoryError: GC overhead limit exceeded | CPU 空转。GC 耗时 >98% 且回收内存 <2%。系统已濒临崩溃。 | ❌ (需优化代码逻辑) | 🔴 极高危 |
| Metaspace | java.lang.OutOfMemoryError: Metaspace | 元空间耗尽。动态代理类过多、加载 JAR 包过多。 | ⚠️ (临时有效,非根本) | 🟠 中高危 |
| Direct buffer | java.lang.OutOfMemoryError: Direct buffer memory | 堆外内存溢出。NIO DirectByteBuffer 分配过多且未释放。 | ❌ (需控制堆外使用) | 🟠 中高危 |
| StackOverflow | java.lang.StackOverflowError | 线程栈溢出。递归死循环或调用链过深。 | ⚠️ (可调 -Xss,但应修逻辑) | 🟡 中危 |
💡 核心洞察:
OOM 只是结果,不是原因。
- Heap Space 通常意味着对象太多或没释放。
- GC Overhead 意味着垃圾太多,GC 线程累死了。
- Metaspace 意味着类太多。
真正的高手,是在 OOM 发生前,通过监控趋势提前干预。
二、Full GC:性能杀手的触发机制与防御
Full GC 是 Stop-The-World (STW) 最严重的 GC 事件。在电商大促、支付交易等低延迟场景中,一次 Full GC = 一次 P0 级事故(接口超时、用户流失)。
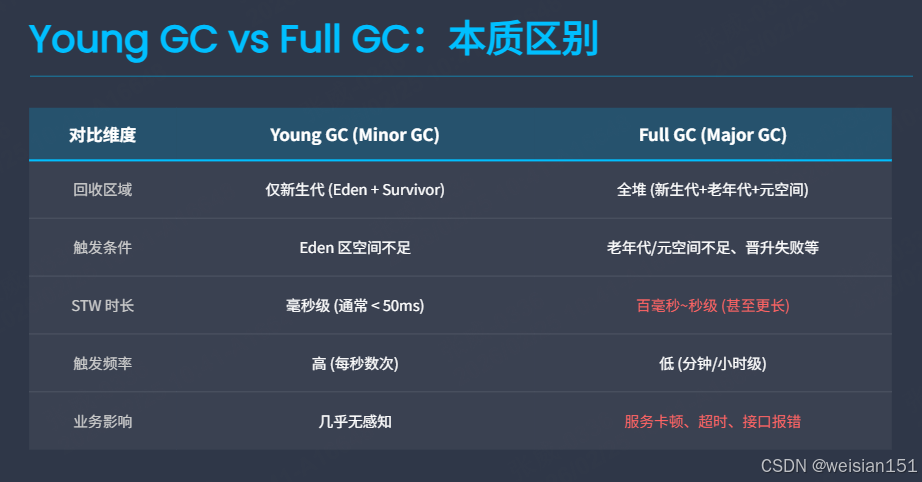
2.1 Young GC vs Full GC:本质区别
在深入之前,必须厘清两者的边界:
| 回收区域 | 仅新生代(Eden + Survivor) | 全堆(新生代+老年代+元空间) |
| 触发条件 | Eden 区满 | 老年代/元空间不足、晋升失败等 |
| STW 时长 | 毫秒级(通常 < 50ms) | 百毫秒~秒级(甚至更长) |
| 触发频率 | 高(每秒数次) | 低(分钟/小时级) |
| 业务影响 | 几乎无感知 | 服务卡顿、超时、接口报错 |
2.2 触发 Full GC 的五大“死亡场景” (面试必背)
- 现象:对象晋升过快,或大对象直接进入老年代。
- 根因:-XX:PretenureSizeThreshold 设置不当,或代码中存在长生命周期对象。
- 现象:动态生成类爆炸。
- 根因:Spring AOP/CGLib 代理过多、Groovy 脚本动态编译、热部署框架滥用。
- 现象:日志中出现 System.gc() invoked。
- 根因:第三方库(如 NIO、RMI)或不规范的业务代码主动触发。默认建议禁用。
- 现象:Young GC 时,Survivor 区放不下,试图晋升到老年代,但老年代也没有连续空间。
- 根因:内存碎片化严重,或老年代预留空间不足。
- 现象:CMS 收集器特有。并发标记/清理还没做完,老年代就满了。
- 后果:退化为 Serial Old 单线程 Full GC,STW 时间极长。
📌 注意:虽然 G1、ZGC 等现代收集器大幅减少了 Full GC,但在极端内存压力下(如堆使用率接近 100%),它们依然会触发 Full GC 作为最后的兜底手段。

三、防御工事:如何避免/减少 Full GC?
避免 Full GC 的核心思想是:控制对象进入老年代的速度,并让 GC 尽可能在新生代完成回收。
🛡️ 策略一:精细化内存参数配置
不要盲目设置 -Xmx,要关注比例和阈值:
# 1. 固定堆大小,避免运行时动态扩容带来的抖动
-Xms4g -Xmx4g
# 2. 调整新生代与老年代比例 (默认 1:2)
# 适当增大新生代,让对象多活一会儿,减少晋升
-XX:NewRatio=2
# 3. 调整 Eden 与 Survivor 比例 (默认 8:1:1)
-XX:SurvivorRatio=8
# 4. 控制对象晋升年龄 (默认 15)
# 适当降低,让疑似泄漏的对象早点暴露,或提高让短命对象多熬几轮
-XX:MaxTenuringThreshold=10
# 5. 【G1 专属】提前触发并发标记,预防 Full GC
# 当堆占用达到 45% 时就开始标记,留出缓冲时间
-XX:InitiatingHeapOccupancyPercent=45

🛡️ 策略二:关闭显式 GC (生产环境铁律)
除非你有极其特殊的理由,否则必须禁止代码中的 System.gc() 调用:
-XX:+DisableExplicitGC
⚠️ 副作用提示:这会使得 DirectByteBuffer 的清理依赖 JVM 自动触发。若大量使用堆外内存,需配合 -XX:MaxDirectMemorySize 限制,防止堆外 OOM。
🛡️ 策略三:选择合适的垃圾收集器
根据业务场景“量体裁衣”:
| 超低延迟 (<50ms) | ZGC / Shenandoah | STW 时间亚毫秒级,几乎无感知 |
| 大堆内存 (>32GB) | G1 | 可预测的停顿时间,自动分区管理 |
| 吞吐优先 (后台批处理) | Parallel GC | 吞吐量最高,但 STW 较长 |

🛡️ 策略四:代码层面的“源头治理” (最重要!)
再好的参数也救不了烂代码。
- 警惕静态集合无限增长// ❌ 错误示范:静态 Map 只增不减,永久持有引用
private static final Map<String, User> CACHE = new HashMap<>();// ✅ 正确示范:使用 LRU 缓存,限制大小
private static final Map<String, User> CACHE = new LinkedHashMap<>(1000, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 1000; // 超过阈值自动淘汰
}
}; - ThreadLocal 必须 remove()
在线程池场景下,线程复用会导致 ThreadLocal 变量无法回收,引发内存泄漏。try {
userContext.set(user);
// 业务逻辑…
} finally {
userContext.remove(); // 务必在 finally 块中清理
} - 大对象堆外化
对于超大字节数组、文件流处理,考虑使用 Netty ByteBuf 或 MappedByteBuffer 将数据移至堆外,减轻 GC 压力。

四、实战 SOP:OOM 排查标准化流程
线上发生 OOM 时,黄金 5 分钟决定事故影响范围。请严格执行以下 SOP(标准作业程序):
🚨 阶段一:现场保留 (预防胜于治疗)
确保所有生产服务启动时都包含以下参数,这是排查的“黑匣子”:
-XX:+HeapDumpOnOutOfMemoryError # OOM 时自动 Dump
-XX:HeapDumpPath=/data/logs/heap_oom.hprof # 指定 Dump 路径 (确保磁盘空间充足)
-XX:OnOutOfMemoryError="kill -9 %p" # 可选:OOM 后自杀,防止僵尸进程拖累集群

🔍 阶段二:分析与定位 (工具链闭环)
拿到 .hprof 文件后,使用 Eclipse MAT (Memory Analyzer Tool) 进行分析:
- 按 Shallow Heap (自身大小) 或 Instances (实例数量) 排序。
- 目标:找出数量异常多或占用内存最大的类(如 byte[], HashMap$Node, 业务实体类)。
- 按 Retained Heap (保留大小,即该对象回收后能释放的总内存) 排序。
- 目标:找到那个“占据高位”的根对象。
- 右键可疑对象 -> Merge Shortest Paths to GC Roots -> exclude weak/soft references。
- 目标:查看是谁(哪个静态变量、哪个线程、哪个缓存)强引用了它,导致无法回收。

🧐 阶段三:定性分析 (泄漏 vs 溢出)
| 堆内存趋势 | 锯齿状:GC 后内存不回落,持续爬升 | 阶梯状:GC 后回落,但峰值不断抬高直至填满 |
| MAT 分析结果 | 存在明显的长引用链,指向不该存在的对象 | 对象分布均匀,无明显泄漏点,单纯是业务量太大 |
| 重启表现 | 运行一段时间后再次 OOM | 重启后正常,流量高峰时复现 |
| 解决思路 | 修代码:切断引用链 | 调参数/扩容:增大 -Xmx 或优化算法 |
✅ 判断口诀:
“Young GC 后堆内存不降,十有八九是泄漏;GC 频繁且 CPU 飙高,那是 GC Overhead。”

五、面试通关:标准答案与加分项
🎯 基础版回答 (稳过线)
面试官:常见的 OOM 有哪些?怎么排查?如何避免 Full GC?
候选人:
“常见的 OOM 主要有五种:Java heap space(堆满)、GC overhead limit exceeded(GC 效率过低)、Metaspace(元空间满)、Direct buffer memory(堆外内存满)以及 StackOverflowError(栈溢出)。
排查流程我通常分三步:
避免 Full GC 的策略包括:

🚀 进阶版回答 (拿 Offer)
(在基础版之上,补充实战深度)
“除了标准流程,我想分享两个实战中的深层思考:
第一,关于‘假性’Full GC 的识别。
有一次大促前,我们发现堆内存只用到了 60% 却频繁 Full GC。通过 jstat -gcutil 监控发现 Metaspace 使用率高达 99%。根因是 Feign + Hystrix 组合产生了大量的动态代理类。这种情况下,单纯调大堆内存无效,必须增大 -XX:MaxMetaspaceSize 并优化框架配置。这提醒我们,Full GC 不一定是老年代的问题,元空间也是重灾区。
第二,关于 GC overhead limit exceeded 的特殊性。
这种 OOM 往往伴随着 CPU 100%。它本质是 JVM 的自我保护:‘与其卡死,不如报错’。解决它的核心不是加内存,而是减少短生命周期对象的创建频率。例如,避免在循环内 new 对象,或者在极端场景下谨慎使用对象池。
最后,我的运维理念是‘防患于未然’。
我们在生产环境接入了 Prometheus + Grafana 监控,对 Old Gen 增长率、Metaspace 使用率、Full GC 频率 设置斜率告警。通常在 OOM 发生前 1 小时就能发现异常趋势,从而在业务低峰期进行平滑重启或扩容,将事故扼杀在摇篮里。”

六、避坑指南 & 加分工具箱
❌ 常见误区 (千万别这么说)
| “OOM 就是内存不够,加 -Xmx 就行” | 加内存可能只是推迟了崩溃时间,泄漏不修,迟早再爆。 |
| “Young GC 越多越好” | Young GC 也有 STW,过于频繁说明新生代太小或对象存活率太高。 |
| “堆内存越大越好” | 堆越大,Full GC 时的 STW 时间越长,大堆必须配 G1/ZGC。 |
| “MAT 看到 byte[] 最多就是泄漏” | byte[] 通常是底层存储,要看是谁持有这些数组。 |
| “System.gc() 一定会触发 Full GC” | 只是建议,JVM 可忽略,但生产环境务必用 -XX:+DisableExplicitGC 禁掉。 |
✅ 加分工具箱 (展现极客精神)
在回答中提及以下工具命令,会让面试官眼前一亮:
jstat -gcutil <pid> 1000
jmap -histo:live <pid> | head -n 20
-XX:NativeMemoryTracking=summary
# 运行时查看堆外内存详情
jcmd <pid> VM.native_memory summary
heapdump –live /tmp/heap.hprof

结语
“优秀的工程师,不是不遇到 OOM,而是能在 10 分钟内定位根因,并构建起防止复发的防线。”
JVM 调优是一场永无止境的修行。
- GC 调优的核心:让短命对象死在新生代,减少进入老年代的流量。
- OOM 排查的核心:保留现场,顺藤摸瓜,区分“真缺内存”与“假性泄漏”。
- 最高境界:监控先行,预案兜底。不要等到线上救火,要在开发 Review 和测试压测阶段就消灭隐患。
记住这句心法:
“调参治标,代码治本;监控先行,预案兜底。”

💬 互动话题:
你在生产环境中遇到过最“诡异”的 OOM 是什么?是某个不起眼的静态变量,还是某个第三方库的坑?欢迎在评论区分享你的“踩坑”经历,让我们一起避雷!



评论前必须登录!
注册