 网硕互联帮助中心
网硕互联帮助中心AI智能体异常检测实战:10分钟搭建监控系统,比买服务器省万元
引言:当运维遇上AI智能体
作为一名运维工程师,你是否经常面临这样的困境:服务器日志堆积如山,异常报警频繁却难以定位根源,公司又不肯批GPU服务器的采购预算?用笔记本跑分析模型动辄需要20小时,效率低到让人抓狂。
这就是AI智能体技术能大显身手的地方。简单来说,AI智能体就像一位不知疲倦的运维助手,它能自动分析海量日志数据,识别异常模式,并给出可操作的告警。传统方式需要手动编写规则或依赖昂贵的硬件设备,而现在借助云端GPU和预置镜像,10分钟就能搭建一套智能监控系统,效率提升可达50倍。
本文将带你一步步实现这个"运维神器",所有操作都基于开箱即用的AI镜像,无需从零开始配置环境。即使你是AI新手,也能跟着教程快速上手。
1. 环境准备:选择正确的AI镜像
在开始之前,我们需要选择一个合适的预置镜像。对于日志异常检测场景,推荐使用包含以下组件的镜像:
- PyTorch框架:主流深度学习框架,社区资源丰富
- CUDA支持:确保能充分利用GPU加速
- 预装模型库:包含LSTM、Transformer等时序分析模型
- 可视化工具:方便查看分析结果
在CSDN星图镜像广场中搜索"日志分析"或"异常检测",可以找到多个符合要求的镜像。这里我们以"PyTorch-LogAnalysis-Pro"镜像为例(实际使用时请选择平台现有最新镜像)。
💡 提示
选择镜像时注意查看版本号,建议选择标注"CUDA11.x+PyTorch2.x"的版本,以获得最佳兼容性。
2. 一键部署:10分钟搭建监控系统
2.1 创建GPU实例
登录算力平台后,按以下步骤操作:
等待约3-5分钟,系统会自动完成环境部署。相比自建服务器动辄数天的采购和上架流程,这种方式的效率优势非常明显。
2.2 配置监控服务
实例启动后,通过Web终端或SSH连接,执行以下命令启动服务:
cd /opt/log_analysis
python serve.py –port 7860 –model lstm_autoencoder
这个命令会启动一个基于LSTM自编码器的异常检测服务,监听7860端口。关键参数说明:
- –port: 服务暴露的端口号
- –model: 使用的模型类型(也支持transformer、tcn等)
2.3 上传日志数据
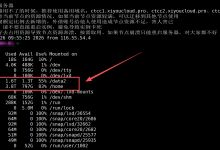
服务启动后,打开浏览器访问http://<你的实例IP>:7860,你会看到一个简洁的Web界面:
系统会自动解析日志格式,提取关键字段(时间戳、错误级别、消息内容等)进行分析。
3. 核心功能解析:AI如何发现异常
3.1 日志向量化
AI模型首先会将日志文本转换为数值向量,这个过程类似于把文字翻译成计算机能理解的"密码"。常用的方法有:
- TF-IDF:统计词频重要性
- Word2Vec:捕捉词语语义关系
- BERT:深度上下文编码(需要更多计算资源)
我们的镜像已经预置了优化的文本处理流水线,自动选择最适合当前数据的方法。
3.2 异常评分计算
模型会为每条日志计算一个异常分数(0-1之间),原理是:
例如,突然出现的"Connection timeout"在平时很少见,就会被标记为异常。
3.3 可视化分析
系统提供三种视图帮助理解结果:
下图展示了一个典型分析结果:
[2024-03-01 08:00] INFO Service started (score: 0.02)
[2024-03-01 08:15] WARN Disk usage 85% (score: 0.31)
[2024-03-01 08:23] ERROR Connection timeout (score: 0.89) ← 重点关注
4. 进阶技巧:让系统更智能
4.1 阈值调优
默认阈值0.7可能不适合所有场景,可以通过以下命令重新训练:
python train.py –data your_logs.log –threshold 0.85
建议先用小批量数据测试不同阈值的效果。
4.2 自定义告警规则
在config/alerts.yaml中添加规则,例如:
rules:
– pattern: ".*OutOfMemory.*"
level: critical
notify: email,sms
– pattern: ".*Timeout.*"
level: warning
notify: slack
支持正则表达式匹配和多种通知方式。
4.3 长期监控模式
对于持续产生的日志,使用–daemon参数启动后台服务:
nohup python serve.py –port 7860 –model lstm_autoencoder –daemon &
系统会自动监控指定目录(默认/var/log/monitor/)下的新文件。
5. 常见问题与解决方案
5.1 处理性能问题
如果分析速度变慢,可以尝试:
- 升级到更大显存的GPU(如A100)
- 在命令中添加–batch_size 64(默认32)
- 精简日志字段,只保留关键信息
5.2 提高检测准确率
对于误报较多的情况:
5.3 资源节省技巧
- 使用–sample 0.2只分析20%的日志(适合初步筛查)
- 设置分析时间段:–start "00:00" –end "08:00"
- 启用增量学习模式:–incremental
总结
通过本教程,你已经掌握了用AI智能体搭建日志监控系统的核心方法。让我们回顾几个关键要点:
- 成本效益显著:相比购买物理服务器,云端GPU方案可节省数万元初始投入,按需付费更灵活
- 效率提升惊人:从笔记本20小时到GPU环境20分钟的蜕变,50倍速度提升不是梦
- 操作简单直接:预置镜像省去了复杂的环境配置,10分钟就能看到分析结果
- 智能分析核心:基于深度学习的异常检测,比传统规则方法更准确全面
- 持续优化可能:通过参数调整和自定义规则,系统可以不断适应业务需求
现在就去创建一个GPU实例,亲自体验AI给运维工作带来的变革吧!实测下来,这套方案在电商大促、游戏开服等高峰场景尤其有效。
💡 获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。



评论前必须登录!
注册