 网硕互联帮助中心
网硕互联帮助中心前言
学习他人,提升自己。超越他人,实现创新。
本文将展现 如何一步一步的复现他人的文章。没有废话,全是实操。详细展示论文代码复现的流程。
本文复现的文章来自:
袁媛, 陈明惠, 柯舒婷, 等. 基于集成卷积神经网络和 Vit 的眼底图像分类研究[J]. Chinese Journal of Lasers, 2022, 49(20): 2007205-2007205-9.
标题
(相关领域,想复现的文章,请发在评论区,可帮复现。点个关注先)
观看本文,要有一定CNN基础。没有可跳链接:
小白快速上手实操CNN图像分类(pytorch)。看完秒变大神。_cnn图像编程怎么学-CSDN博客
1.通读论文
“本文提出一种基于EfficientNet-Vit集成模型的眼底图像分类方法,此 方法将卷积神经网络模型EfficientNetV2-S和Vit模型相结合,分别使用两种完全不同的方法提取眼底图像的特 征,通过自适应加权融合算法计算得到最优加权因子0.6和0.4,利用加权软投票法进行模型集成,从而获得更好 的分类结果。”
也就是说,此文借鉴了2中模型EfficientNet和Vit,然后通过一种所谓的加权软投票法进行模型集成,
这么高大上的词:加权软投票法
说白了就是2个模型输出的类别概率 加起来。

例如,
类别 A,B,C,D,E。
样本X,
在model1 上的 5个类别的概率分别是:0.1 ,0.2, 0.3 ,0.15 ,0.25,所以X在model1上的类别 为C。
在model2 上的 5个类别的概率分别是:0.15 ,0.35, 0.1 ,0.1 ,0.3,所以X在model2上的类别 为B。
通过加权软投票法得到:样本X,5个类别的概率分别是:
0.1×0.6+0.15×0.4 0.2×0.6+0.35×0.4 0.3×0.6+0.1×0.4 0.15×0.6+0.1×0.4 0.25×0.6+0.3×0.4
即,0.12 0.26 0.22 0.13 0.27
所以最终输出的类别 为D。
另外,最优加权因子0.6和0.4,通过自适应加权融合算法计算得到。

大概是通过 概率的分布 计算方差,来得到的。
为了增加创新点,文章 还对EfficientNet,做了改进。
改进如下:
本研究使用一种无参数注意力模块SimAM,替换Fused-MBConv的SE模块
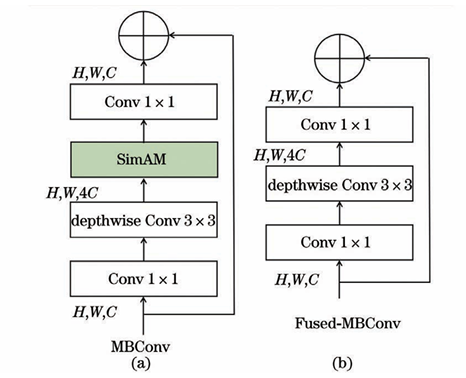

2.关键技术-加权软投票法
EfficientNet和Vit都可以在torchvision.models中直接调用。
model1 = torchvision.models.vit_b_16(pretrained=True)
model1.heads.head = nn.Linear(model1.heads.head.in_features, 5)
model2 = torchvision.models.efficientnet_v2_m(pretrained=True)
model2.classifier[1] = nn.Linear(in_features=1280, out_features=5)
但需要注意修改,类别数量。
用pytorch的torchvision.models调用各种cnn模型,训练自己的数据集时,怎么手动改分类数num_classes。_torchvision 常见模型调用-CSDN博客
完整代码如下:
import torch.nn as nn
import torch
from torchvision import transforms
import torchvision
from PIL import Image
import torch.nn.functional as F
label_dic = {0:"A",1:"B",2:"C",3:"D",4:"E"}
def usemodel_singleimg(model, test_image):
transformer = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])
])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
test_image = test_image.convert("RGB")
processed_image = transformer(test_image).unsqueeze(dim=0)
processed_image = processed_image.to(device)
model.eval()
with torch.no_grad():
output = model(processed_image)
# 新增概率计算部分
probabilities = F.softmax(output, dim=1) # 沿类别维度做softmax
probabilities = probabilities.cpu().numpy()[0] # 转为numpy数组并去掉batch维度
_, predicted = torch.max(output.data, 1)
class_id = predicted.item()#预测类别ID
return probabilities.tolist()
def add(model1,model2,img):
probabilities1 = usemodel_singleimg(model1, img)
probabilities2 = usemodel_singleimg(model2, img)
sum_probabilities = []
for i in range(5):
sum_probabilities.append(probabilities1[i]*0.6+probabilities2[i]*0.4)
return sum_probabilities
def label_sum_probabilities(lst):
max_val = max(lst)
label = label_dic[lst.index(max_val)]
return label
if __name__ == "__main__":
model1 = torchvision.models.vit_b_16(pretrained=True)
model1.heads.head = nn.Linear(model1.heads.head.in_features, 5)
model2 = torchvision.models.efficientnet_v2_m(pretrained=True)
model2.classifier[1] = nn.Linear(in_features=1280, out_features=5)
# 加载测试图片
img = Image.open("cat.png")
result = add(model1,model2,img)
print(result)
label = label_sum_probabilities(result)
print(label)
运行后,输出

3. 关键技术-SimAM
问问ai,什么是 simam

SimAM:轻量级注意力机制,解锁卷积神经网络新潜力【原理讲解及代码!!!】_simam注意力-CSDN博客
import torch.nn as nn
import torch
class SimAM(nn.Module):
def __init__(self, lambda_param=1e-5):
super().__init__()
self.lambda_param = lambda_param
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
n = h * w – 1
mean = torch.mean(x, dim=[2,3], keepdim=True)
var = torch.sum((x – mean)**2, dim=[2,3], keepdim=True) / n
e_t = (x – mean)**2 / (4*(var + self.lambda_param)) + 0.5
return x * self.sigmoid(e_t)
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
simam = SimAM().to(device)
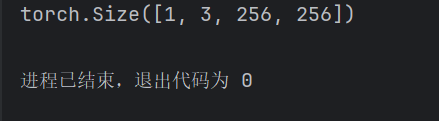
input_images = torch.randn(1, 3, 256, 256).to(device)
output = simam(input_images)
print(output.shape)
运行,
然后,我们要找到efficient_v2的源码,用simam代替,Fused-MBConv层中的SE模块
efficient_v2的源码:
经典CNN模型(十三):EfficientNetV2(PyTorch详细注释版)-CSDN博客
发现Fused-MBConv并没有所谓的SE模块
但没关系,直接给他加上SimAM。
完整代码
from collections import OrderedDict
from functools import partial
from typing import Callable, Optional
import torch.nn as nn
import torch
from torch import Tensor
#===========================SimAM===========================
class SimAM(nn.Module):
def __init__(self, lambda_param=1e-5):
super().__init__()
self.lambda_param = lambda_param
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
n = h * w – 1
mean = torch.mean(x, dim=[2,3], keepdim=True)
var = torch.sum((x – mean)**2, dim=[2,3], keepdim=True) / n
e_t = (x – mean)**2 / (4*(var + self.lambda_param)) + 0.5
return x * self.sigmoid(e_t)
#========================efficient===========================
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
This function is taken from the rwightman.
It can be seen here:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 – drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim – 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class ConvBNAct(nn.Module):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[…, nn.Module]] = None,
activation_layer: Optional[Callable[…, nn.Module]] = None):
super(ConvBNAct, self).__init__()
padding = (kernel_size – 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
self.conv = nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False)
self.bn = norm_layer(out_planes)
self.act = activation_layer()
def forward(self, x):
result = self.conv(x)
result = self.bn(result)
result = self.act(result)
return result
class SqueezeExcite(nn.Module):
def __init__(self,
input_c: int, # block input channel
expand_c: int, # block expand channel
se_ratio: float = 0.25):
super(SqueezeExcite, self).__init__()
squeeze_c = int(input_c * se_ratio)
self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1)
self.act1 = nn.SiLU() # alias Swish
self.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1)
self.act2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = x.mean((2, 3), keepdim=True)
scale = self.conv_reduce(scale)
scale = self.act1(scale)
scale = self.conv_expand(scale)
scale = self.act2(scale)
return scale * x
class MBConv(nn.Module):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer: Callable[…, nn.Module]):
super(MBConv, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.has_shortcut = (stride == 1 and input_c == out_c)
activation_layer = nn.SiLU # alias Swish
expanded_c = input_c * expand_ratio
# 在EfficientNetV2中,MBConv中不存在expansion=1的情况所以conv_pw肯定存在
assert expand_ratio != 1
# Point-wise expansion
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)
# Depth-wise convolution
self.dwconv = ConvBNAct(expanded_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
groups=expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else nn.Identity()
# Point-wise linear projection
self.project_conv = ConvBNAct(expanded_c,
out_planes=out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity) # 注意这里没有激活函数,所有传入Identity
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self, x: Tensor) -> Tensor:
result = self.expand_conv(x)
result = self.dwconv(result)
result = self.se(result)
result = self.project_conv(result)
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class FusedMBConv(nn.Module):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer: Callable[…, nn.Module]):
super(FusedMBConv, self).__init__()
assert stride in [1, 2]
assert se_ratio == 0
self.has_shortcut = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
self.simam = SimAM() # 新增SimAM模块
activation_layer = nn.SiLU # alias Swish
expanded_c = input_c * expand_ratio
# 只有当expand ratio不等于1时才有expand conv
if self.has_expansion:
# Expansion convolution
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.project_conv = ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity) # 注意没有激活函数
else:
# 当只有project_conv时的情况
self.project_conv = ConvBNAct(input_c,
out_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer) # 注意有激活函数
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self, x: Tensor) -> Tensor:
if self.has_expansion:
result = self.expand_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
result = self.simam(result) # 新增:应用SimAM注意力
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class EfficientNetV2(nn.Module):
def __init__(self,
model_cnf: list,
num_classes: int = 1000,
num_features: int = 1280,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2):
super(EfficientNetV2, self).__init__()
for cnf in model_cnf:
assert len(cnf) == 8
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
stem_filter_num = model_cnf[0][4]
self.stem = ConvBNAct(3,
stem_filter_num,
kernel_size=3,
stride=2,
norm_layer=norm_layer) # 激活函数默认是SiLU
total_blocks = sum([i[0] for i in model_cnf])
block_id = 0
blocks = []
for cnf in model_cnf:
repeats = cnf[0]
op = FusedMBConv if cnf[-2] == 0 else MBConv
for i in range(repeats):
blocks.append(op(kernel_size=cnf[1],
input_c=cnf[4] if i == 0 else cnf[5],
out_c=cnf[5],
expand_ratio=cnf[3],
stride=cnf[2] if i == 0 else 1,
se_ratio=cnf[-1],
drop_rate=drop_connect_rate * block_id / total_blocks,
norm_layer=norm_layer))
block_id += 1
self.blocks = nn.Sequential(*blocks)
head_input_c = model_cnf[-1][-3]
head = OrderedDict()
head.update({"project_conv": ConvBNAct(head_input_c,
num_features,
kernel_size=1,
norm_layer=norm_layer)}) # 激活函数默认是SiLU
head.update({"avgpool": nn.AdaptiveAvgPool2d(1)})
head.update({"flatten": nn.Flatten()})
if dropout_rate > 0:
head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})
head.update({"classifier": nn.Linear(num_features, num_classes)})
self.head = nn.Sequential(head)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.stem(x)
x = self.blocks(x)
x = self.head(x)
return x
def efficientnetv2_s(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 300, eval_size: 384
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[2, 3, 1, 1, 24, 24, 0, 0],
[4, 3, 2, 4, 24, 48, 0, 0],
[4, 3, 2, 4, 48, 64, 0, 0],
[6, 3, 2, 4, 64, 128, 1, 0.25],
[9, 3, 1, 6, 128, 160, 1, 0.25],
[15, 3, 2, 6, 160, 256, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.2)
return model
def efficientnetv2_m(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[3, 3, 1, 1, 24, 24, 0, 0],
[5, 3, 2, 4, 24, 48, 0, 0],
[5, 3, 2, 4, 48, 80, 0, 0],
[7, 3, 2, 4, 80, 160, 1, 0.25],
[14, 3, 1, 6, 160, 176, 1, 0.25],
[18, 3, 2, 6, 176, 304, 1, 0.25],
[5, 3, 1, 6, 304, 512, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.3)
return model
def efficientnetv2_l(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[4, 3, 1, 1, 32, 32, 0, 0],
[7, 3, 2, 4, 32, 64, 0, 0],
[7, 3, 2, 4, 64, 96, 0, 0],
[10, 3, 2, 4, 96, 192, 1, 0.25],
[19, 3, 1, 6, 192, 224, 1, 0.25],
[25, 3, 2, 6, 224, 384, 1, 0.25],
[7, 3, 1, 6, 384, 640, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.4)
return model
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
simam = efficientnetv2_m(num_classes = 5).to(device)
input_images = torch.randn(1, 3, 256, 256).to(device)
output = simam(input_images)
print(output.shape)
运行后 




评论前必须登录!
注册