 网硕互联帮助中心
网硕互联帮助中心查找,就是给定一个关键字,我们去寻找库里面是否有相同的数据,返回其位置即可
而查找,我们今天学习两种,一种是顺序查找,一种是二分查找
顺序查找不要求数据元素从小到大有序排列,顾名思义,顺序查找内部数据可以是无序的
我们从顺序表的表尾依次往前遍历
我们要判断是否有越界的情况,即比如没找到该数据,一直循环的遍历,所以我们需要多一步,就是判断是否从尾遍历到表头

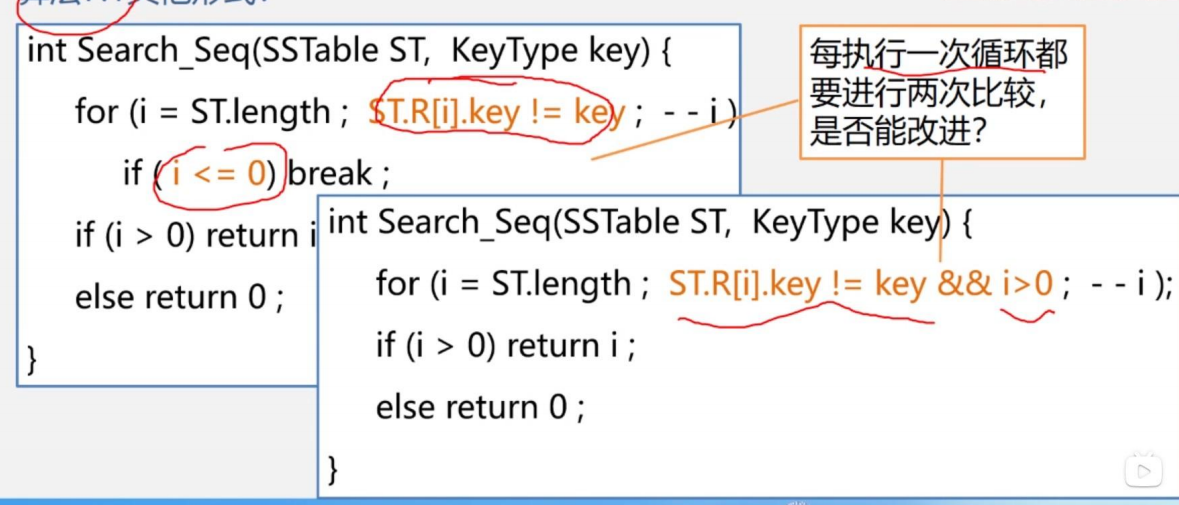
如何改进?增加哨兵
把关键字key存入表头,可以免去每一次都要判断是否遍历完成,因为怎么样都能输出一个与关键字相同的数据的地址,只不过地址如果是表头,那就说明表中没有相同的数据元素

n是11个数据元素,i是下标
顺序查找的ASL(平均查找长度)=(n+1)/2
时间复杂度O(n)
空间复杂度O(1)
记录的查找概率不相等时如何提高查找效率?
查找表存储记录原则——按查找概率高低存储:
1) 查找概率越高,比较次数越少;
2) 查找概率越低,比较次数较多。
记录的查找概率无法测定时如何提高查找效率?
方法——按查找概率动态调整记录顺序:
1) 在每个记录中设一个访问频度域;
2) 始终保持记录按非递增有序的次序排列;
3) 每次查找后均将刚查到的记录直接移至表头。
顺序查找
优点:算法简单,逻辑次序无要求,且不同存储结构均适用。
缺点:ASL太长,时间效率太低。
为了提高效率,我们引入二分查找
折半查找:每次将待查记录所在区间缩小一半。并且数据必须从小到大有序排列
我们引入两个指针,low和high,分别指向表头和表尾
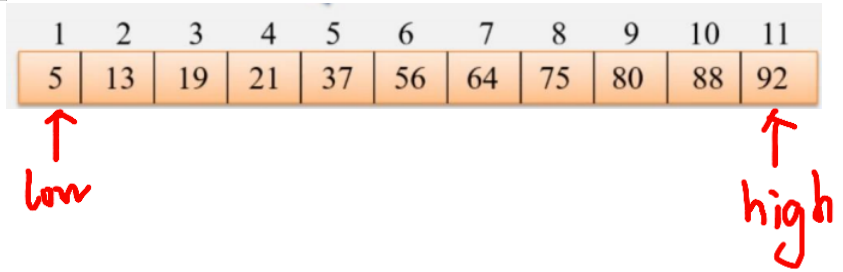
比如查找21,mid=(1+11)/2=6,下标为6的数据是56,比21大,所以我们从前边开始继续找,此时high指针指向mid-1,也就是5,然后继续mid=(1+5)/2=3,21与下标为3的19比较,比19大,我们将low指针移到mid+1也就是4上,发现4的元素21与21相等,找到了!


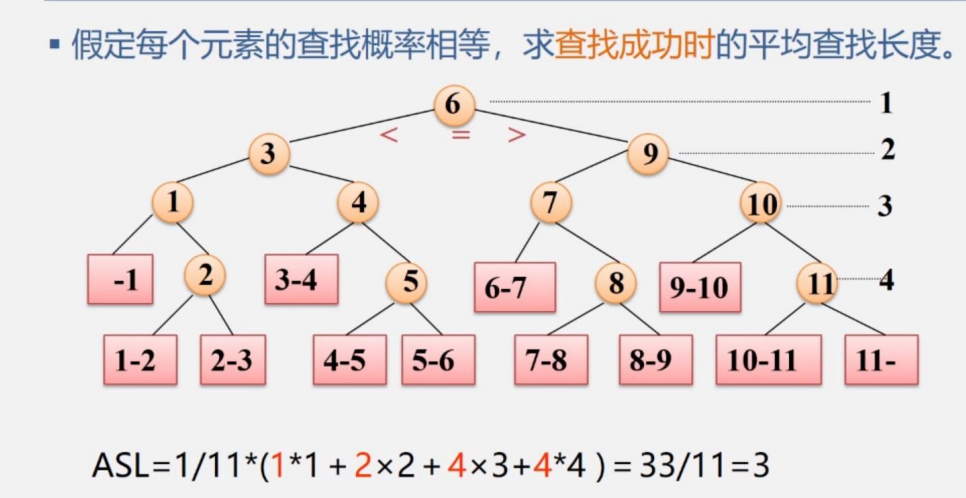
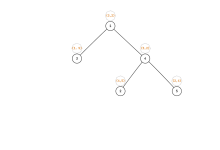
判定树:

我们根据查找的次数,一次作为根,两次的作为根6的子树,以此类推




评论前必须登录!
注册