 网硕互联帮助中心
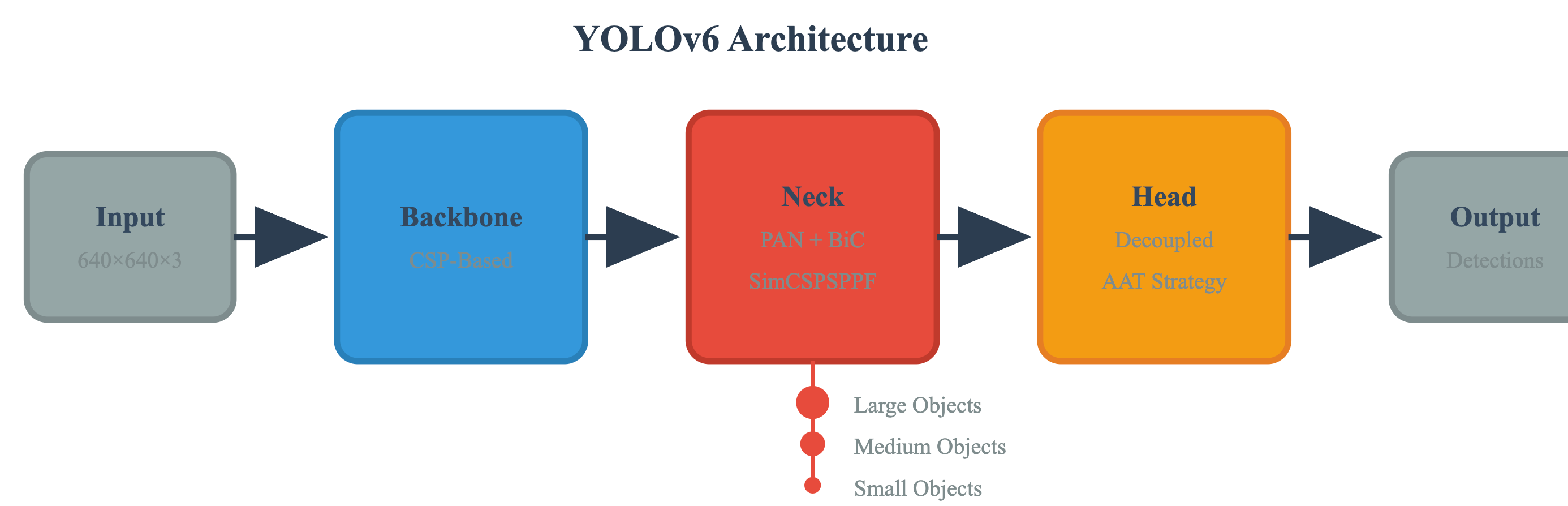
网硕互联帮助中心在计算机视觉领域,目标检测一直是最具挑战性的任务之一。如何在保证检测精度的同时实现实时推理,是工业界和学术界共同关注的核心问题。美团团队推出的YOLOv6在这一平衡点上取得了重大突破,不仅在COCO数据集上刷新了最先进的精度记录,更在推理速度上实现了显著提升,为实时应用场景提供了强有力的技术支撑。
一、YOLOv6的技术革新与架构设计
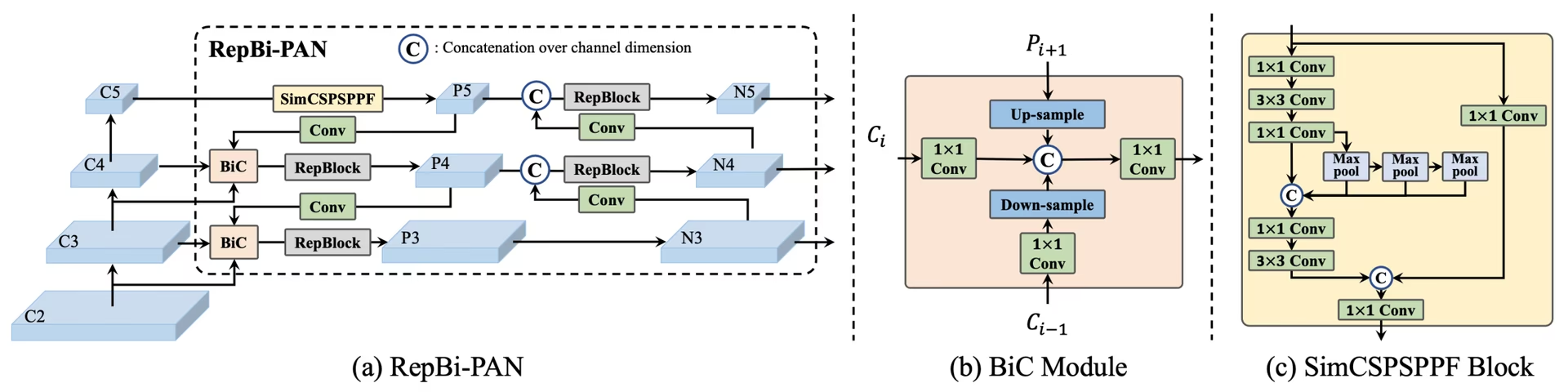
(a) YOLOv6 的颈部(图中为 N 和 S)。(b) BiC 模块的结构。© SimCSPSPPF 模块:
1. 整体架构的重新思考
YOLOv6并非简单的版本迭代,而是对整个检测框架的系统性重构。美团团队从骨干网络、特征融合层到检测头都进行了深度优化,形成了一套完整的技术解决方案。这种全方位的设计理念确保了各个组件之间的协同效应,而非局部优化。
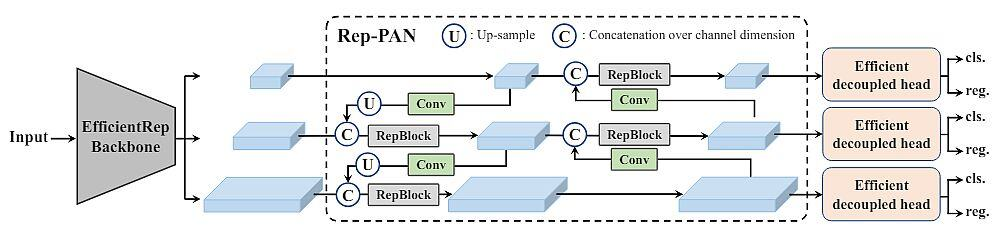
传统的YOLO系列模型往往专注于某一特定方面的改进,YOLOv6则采用了holistic approach,统筹考虑了精度、速度、内存占用等多维度因素。这种设计哲学使得YOLOv6能够在复杂的实际应用场景中表现出色。
# YOLOv6核心网络结构示例
class YOLOv6(nn.Module):
def __init__(self, num_classes=80, anchors=None):
super().__init__()
# 骨干网络采用CSP结构优化
self.backbone = CSPBepBackbone()
# 颈部网络集成BiC模块
self.neck = RepPANNeck(channels=[256, 512, 1024])
# 检测头支持anchor-free和anchor-based混合
self.head = EffiDeHead(num_classes, anchors)
def forward(self, x):
features = self.backbone(x)
neck_features = self.neck(features)
predictions = self.head(neck_features)
return predictions
2. 双向级联模块的创新应用
BiC(Bidirectional Concatenation)模块是YOLOv6的核心创新之一,它在特征融合阶段引入了双向信息流机制。传统的FPN结构虽然能够实现多尺度特征融合,但信息传递往往是单向的,这限制了特征表达的丰富性。
BiC模块通过构建双向连接通道,让高层语义信息和低层细节信息能够更充分地交互融合。这种设计不仅提升了小目标的检测能力,还增强了模型对复杂场景的理解能力。更重要的是,BiC模块的计算开销极小,几乎不增加推理时间,体现了美团团队在工程优化方面的深厚功底。
class BiCModule(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.reduce_conv = nn.Conv2d(in_channels, in_channels // 2, 1)
self.split_conv_1 = nn.Conv2d(in_channels // 2, in_channels // 4, 3, padding=1)
self.split_conv_2 = nn.Conv2d(in_channels // 2, in_channels // 4, 3, padding=1)
self.concat_conv = nn.Conv2d(in_channels, in_channels, 1)
def forward(self, x):
reduced = self.reduce_conv(x)
split1 = self.split_conv_1(reduced)
split2 = self.split_conv_2(reduced)
# 双向信息融合
fused = torch.cat([split1, split2, reduced], dim=1)
return self.concat_conv(fused)
这段代码展示了BiC模块的基本实现原理。通过降维、分割、融合的三步操作,实现了特征的双向流动,同时控制了计算复杂度。
如上图所示,YOLOv6采用了模块化的设计理念,每个组件都经过精心优化以实现最佳的精度-速度平衡。
二、锚点辅助训练策略的突破性进展
1. AAT策略的设计理念
Anchor Assisted Training(AAT)策略是YOLOv6的另一项重要创新。这一策略巧妙地结合了anchor-based和anchor-free两种检测范式的优势,在训练阶段引入锚点机制来稳定学习过程,而在推理阶段则去除锚点依赖以提升效率。
传统的检测器往往需要在两种范式中做出选择,anchor-based方法虽然训练稳定但推理复杂,anchor-free方法虽然推理高效但训练困难。AAT策略通过分离训练和推理阶段的处理方式,实现了两种范式优势的有机结合。
2. 训练过程中的动态平衡
在AAT策略中,训练过程被设计为一个动态平衡的过程。初期阶段,锚点机制发挥主导作用,帮助模型快速收敛到合理的参数空间;随着训练的深入,anchor-free分支的权重逐渐增加,最终在推理阶段完全接管检测任务。
class AATLoss(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
self.anchor_weight = nn.Parameter(torch.tensor(1.0))
self.anchor_free_weight = nn.Parameter(torch.tensor(0.1))
def forward(self, predictions, targets, epoch):
# 动态调整两种机制的权重
alpha = min(epoch / 100.0, 1.0)
anchor_loss = self.compute_anchor_loss(predictions, targets)
anchor_free_loss = self.compute_anchor_free_loss(predictions, targets)
total_loss = (1 – alpha) * anchor_loss + alpha * anchor_free_loss
return total_loss
这种动态权重调整机制确保了训练过程的平滑过渡,避免了突然的策略切换可能带来的性能损失。
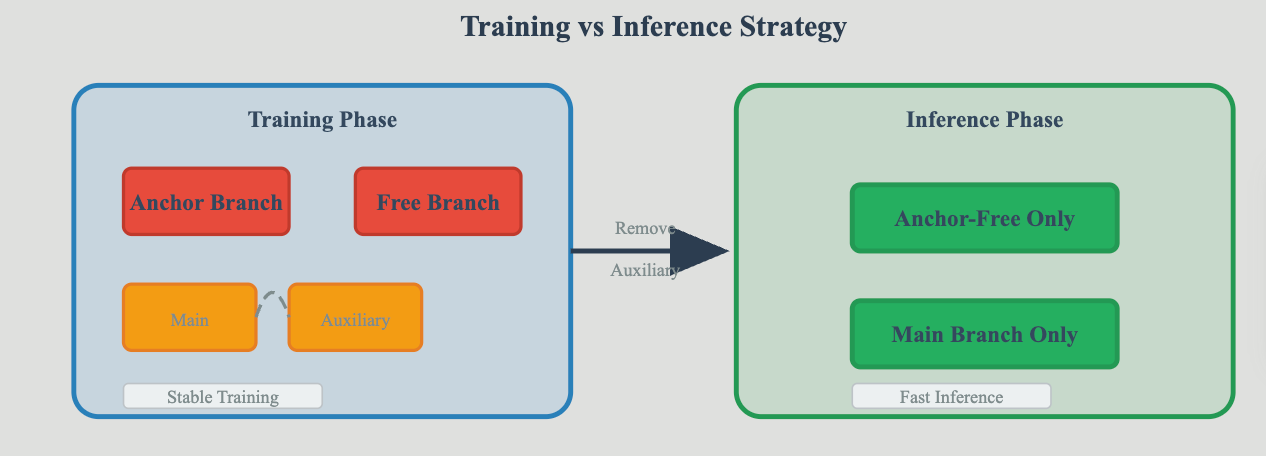
训练策略流程图清晰地展示了YOLOv6如何在训练和推理阶段采用不同的处理方式,实现了效果与效率的完美平衡。
三、骨干网络与颈部设计的深度优化
1. CSP架构的演进与改良
YOLOv6在骨干网络设计上延续了CSPNet的核心思想,但进行了针对性的改良。新的CSP结构不仅保持了原有的梯度流优化特性,还通过重新设计的连接方式提升了特征表达能力。
骨干网络的深化是YOLOv6的重要特征,通过增加额外的处理阶段,模型能够更好地处理高分辨率输入。这种设计对于精细化检测任务特别有效,能够显著提升小目标和密集目标的检测精度。
2. SimCSPSPPF模块的集成应用
SimCSPSPPF模块是YOLOv6颈部网络的核心组件,它集成了CSP结构的梯度优化特性和SPPF的多尺度池化能力。这种设计既保证了特征的丰富性,又控制了计算成本,实现了效率与效果的双重优化。
class SimCSPSPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.conv1 = Conv(c1, c_, 1, 1)
self.conv2 = Conv(c1, c_, 1, 1)
self.conv3 = Conv(c_, c_, 3, 1)
self.conv4 = Conv(c_, c_, 1, 1)
self.maxpool = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.conv5 = Conv(4 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.conv4(self.conv3(self.conv1(x)))
# 多尺度特征提取
y1 = self.maxpool(x1)
y2 = self.maxpool(y1)
y3 = self.maxpool(y2)
# 特征融合
return self.conv5(torch.cat([x1, y1, y2, y3], 1))
该模块通过串联多个最大池化操作实现多尺度感受野,同时利用CSP结构优化梯度传播,这种设计在保持计算效率的同时显著提升了特征表达能力。
四、自蒸馏策略与模型压缩技术
1. 知识蒸馏的创新实现
YOLOv6引入的自蒸馏策略是一种新颖的模型优化方法,特别针对轻量级模型的性能提升。与传统的师生蒸馏不同,自蒸馏策略让模型内部的不同分支相互学习,实现了自我提升的效果。
在训练阶段,模型会同时输出主预测分支和辅助预测分支的结果,两个分支之间通过知识蒸馏机制相互促进。这种设计不仅提升了最终的检测精度,还增强了模型的泛化能力。推理阶段则只保留主预测分支,确保了推理速度不受影响。
2. 渐进式蒸馏训练策略
自蒸馏的实施采用了渐进式策略,初期阶段两个分支独立训练,随着训练的深入逐步引入蒸馏损失。这种渐进式的方法避免了训练初期的不稳定性,确保了蒸馏过程的有效性。
class SelfDistillationLoss(nn.Module):
def __init__(self, temperature=3.0):
super().__init__()
self.temperature = temperature
self.kl_loss = nn.KLDivLoss(reduction='batchmean')
def forward(self, main_output, aux_output, targets, epoch):
# 标准检测损失
detection_loss = compute_detection_loss(main_output, targets)
# 蒸馏损失逐步增加权重
distill_weight = min(epoch / 50.0, 0.5)
if distill_weight > 0:
# 软标签蒸馏
soft_main = F.softmax(main_output / self.temperature, dim=–1)
soft_aux = F.log_softmax(aux_output / self.temperature, dim=–1)
distill_loss = self.kl_loss(soft_aux, soft_main)
total_loss = detection_loss + distill_weight * distill_loss
else:
total_loss = detection_loss
return total_loss
这种自蒸馏机制特别适用于资源受限的场景,能够在不增加推理成本的前提下显著提升模型性能。
五、多尺度模型族的性能表现与应用场景
1. 全方位的性能评估体系
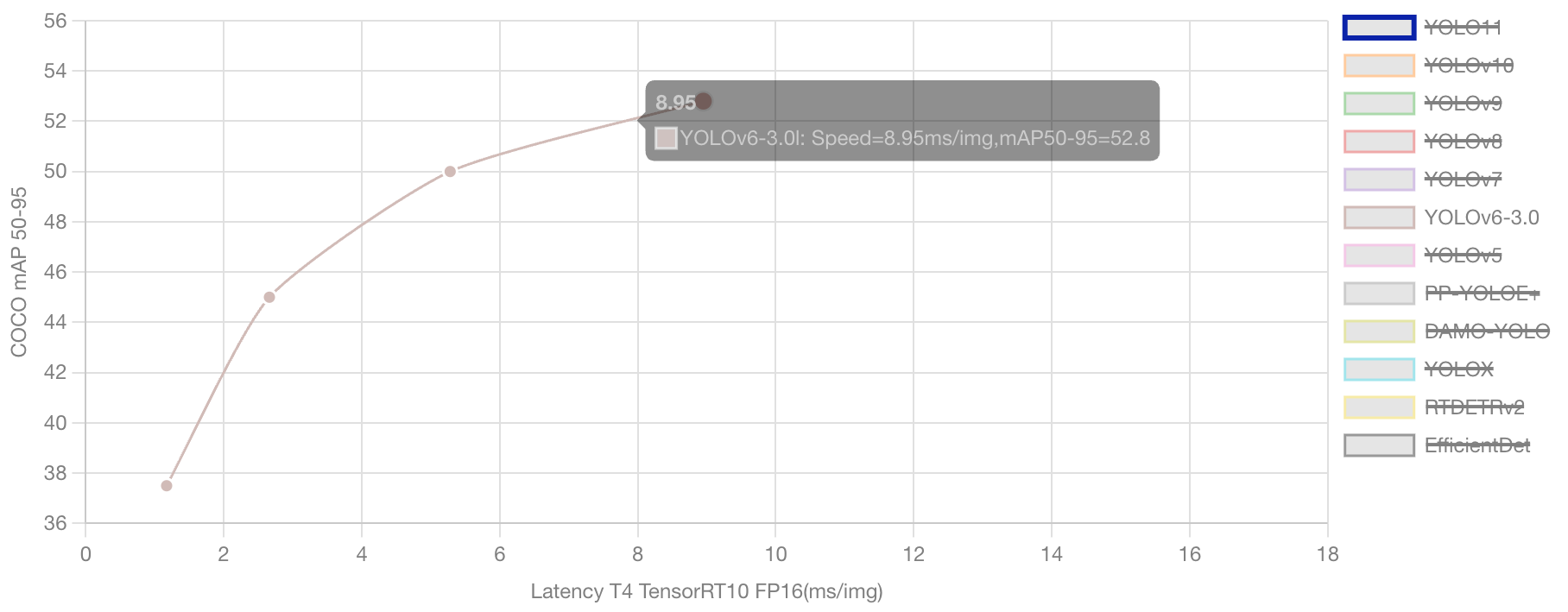
YOLOv6提供了从nano到large6的完整模型族,覆盖了从移动端到服务器端的全部应用场景。每个模型都经过精心调优,在其对应的资源约束下实现了最优的精度-速度平衡。
YOLOv6-N作为系列中最轻量的模型,在NVIDIA T4 GPU上能够达到1187 FPS的惊人速度,同时保持37.5% AP的检测精度。这种性能表现使其非常适合实时性要求极高的应用场景,如自动驾驶、无人机导航等。
YOLOv6-S在速度和精度之间取得了很好的平衡,45.0% AP的精度配合484 FPS的速度,使其成为大多数工业应用的首选方案。无论是智能安防、工业质检还是零售分析,YOLOv6-S都能提供稳定可靠的检测服务。
2. 高精度模型的突破性表现
YOLOv6-L和YOLOv6-L6代表了系列中精度最高的模型,特别是YOLOv6-L6在COCO数据集上实现了当时最先进的实时检测精度。这些高精度模型虽然速度相对较慢,但仍然能够满足实时应用的需求,为追求极致精度的场景提供了理想的解决方案。
3. 量化优化与移动端适配
除了标准的浮点模型,YOLOv6还提供了经过量化优化的版本,这些模型能够在保持检测精度的同时大幅降低模型大小和推理时间。量化版本特别适合移动设备和边缘计算场景,为AI技术的普及提供了有力支撑。
# 模型量化示例
def quantize_model(model, calibration_loader):
# 准备量化配置
quantization_config = torch.quantization.get_default_qconfig('fbgemm')
model.qconfig = quantization_config
# 融合操作以提高量化效率
torch.quantization.fuse_modules(model, [['conv', 'bn', 'relu']], inplace=True)
# 准备量化
torch.quantization.prepare(model, inplace=True)
# 校准
model.eval()
with torch.no_grad():
for data, _ in calibration_loader:
model(data)
# 转换为量化模型
quantized_model = torch.quantization.convert(model, inplace=False)
return quantized_model
YOLOv6在设计之初就充分考虑了部署的便利性,采用了多种推理优化策略。模型的网络结构对主流的推理框架都很友好,无论是TensorRT、ONNX还是OpenVINO,都能实现高效的推理加速。推理过程中的内存管理也经过了精心优化,通过合理的内存分配策略和中间结果复用,最大限度地降低了内存占用。这种优化对于资源受限的边缘设备特别重要。
美团团队通过YOLOv6向我们展示了如何将学术研究的深度与工业应用的广度有机结合,这种结合不仅推动了技术的进步,更为实际应用场景提供了强有力的支撑。









评论前必须登录!
注册