 网硕互联帮助中心
网硕互联帮助中心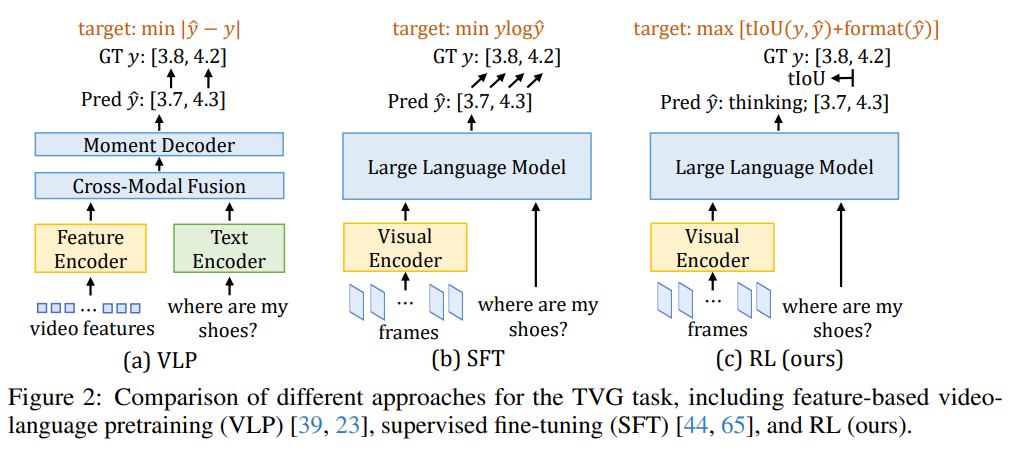
文章核心总结与创新点
主要内容
该研究聚焦长视频理解中的核心任务——时间视频定位(TVG),即根据自然语言查询定位视频中特定片段。针对现有大型视觉语言模型(LVLMs)在TVG任务中因监督微调(SFT)过惩罚合理预测导致泛化能力不足的问题,提出了基于强化学习(RL)的后训练框架Time-R1,配套设计了数据高效的微调策略TimeRFT和专用基准测试集TVGBench,最终在多个数据集上实现了最先进(SoTA)性能,同时提升了模型在长短视频问答任务中的通用理解能力。
该研究聚焦长视频理解中的核心任务——时间视频定位(TVG),即根据自然语言查询定位视频中特定片段。针对现有大型视觉语言模型(LVLMs)在TVG任务中因监督微调(SFT)过惩罚合理预测导致泛化能力不足的问题,提出了基于强化学习(RL)的后训练框架Time-R1,配套设计了数据高效的微调策略TimeRFT和专用基准测试集TVGBench,最终在多个数据集上实现了最先进(SoTA)性能,同时提升了模型在长短视频问答任务中的通用理解能力。









评论前必须登录!
注册