 网硕互联帮助中心
网硕互联帮助中心强化学习——马尔可夫过程
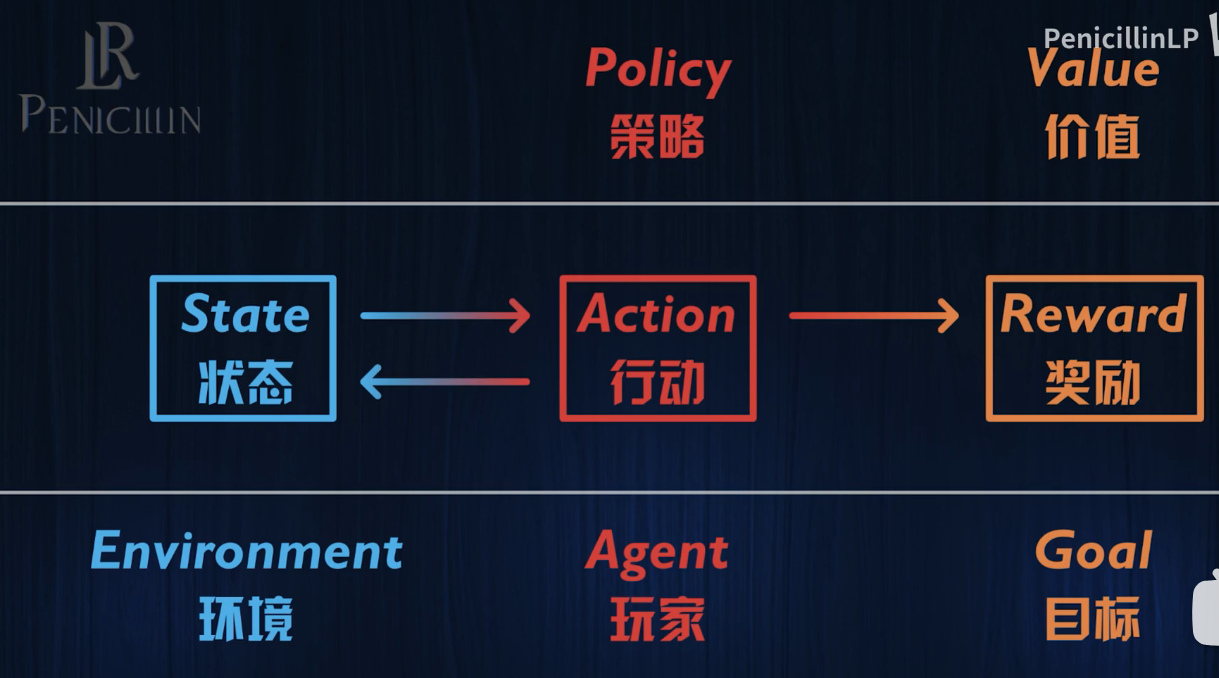
环境 智能体 目标

玩家和环境是如何互动的呢?这就是强化学习的主要元素
强化学习就是要求智能体知道在某种状态下,采取什么样的行动能获得最大的价值(价值=∫奖励dt)
那么如何决策呢?这就涉及到RL的核心元素——策略和价值。
我们可以把强化学习的对象描述为一个马尔可夫过程
状态 行动 奖励
不同状态下的行动空间是不同的,智能体做出动作后会获得奖励,同时影响状态进入St+1
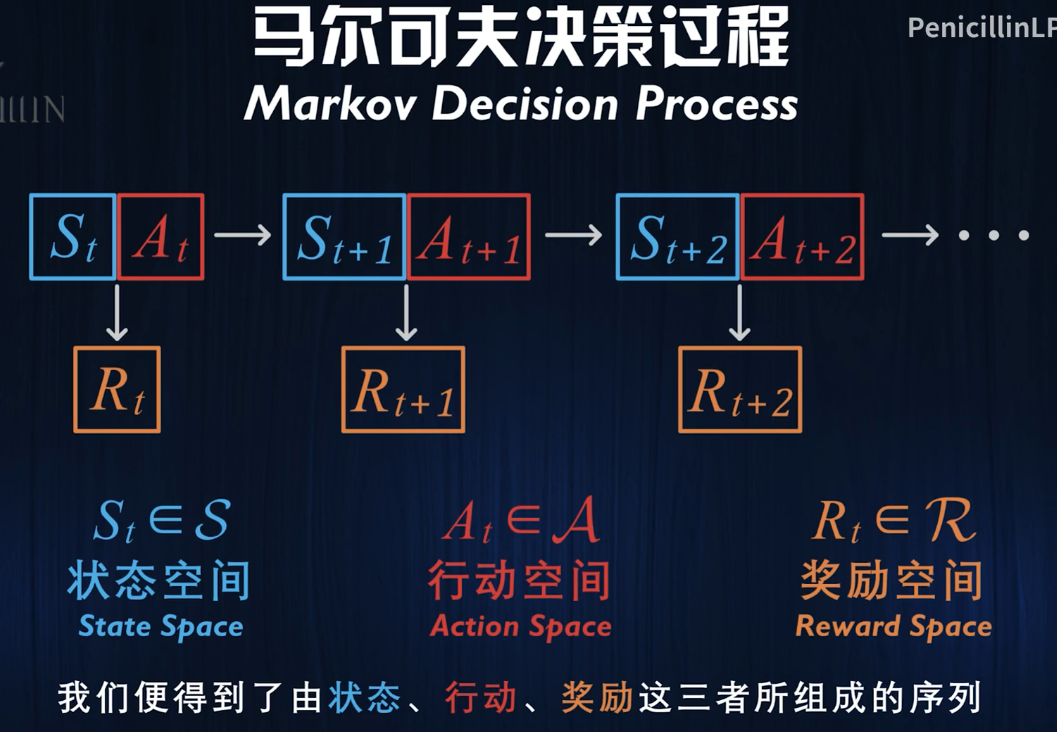
也就是说,玩家获得的奖励和下一刻的状态St+1完全取决于当前的状态St以及采取的动作At
然而,在现实中,这个未来的状态和可能得到的奖励是随机的,因此我们需要引入一个转移概率函数p,其定义是: 在状态为St,选择动作为At,获得奖励为r,并且转移到下一个状态是s'的概率

我们一般研究离散的马尔可夫过程,离散的马尔可夫是指状态、行动、奖励空间是有限的。

而“离散”是指时间上的离散。(也就是我们用CV按帧截图,是离散的)
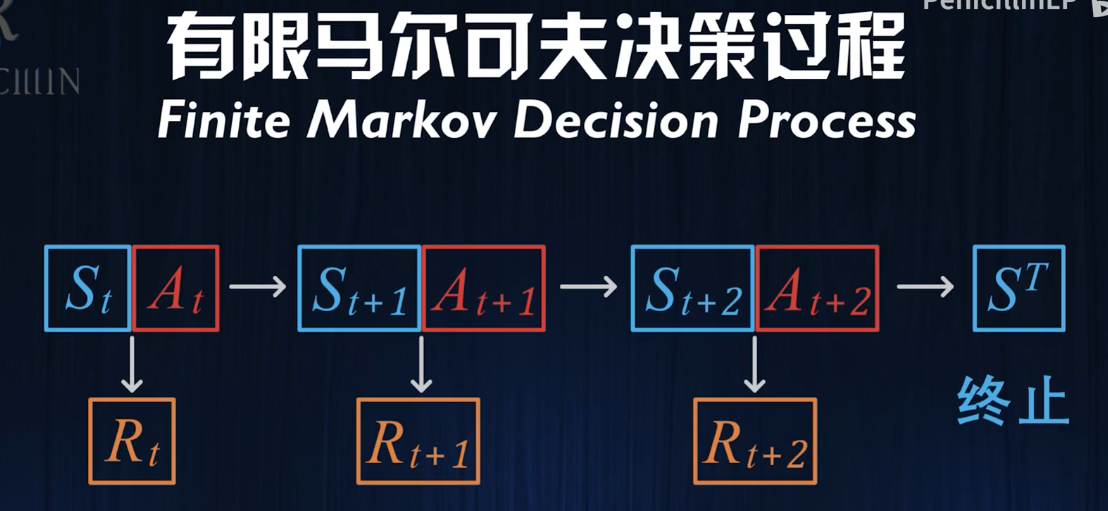
而实际是否有限对应着两种强化学习问题:
一种问题存在一个特殊的终止状态ST:
这种马尔可夫过程被称为“Episode”分段的马尔可夫。
另一种是无线持续的:
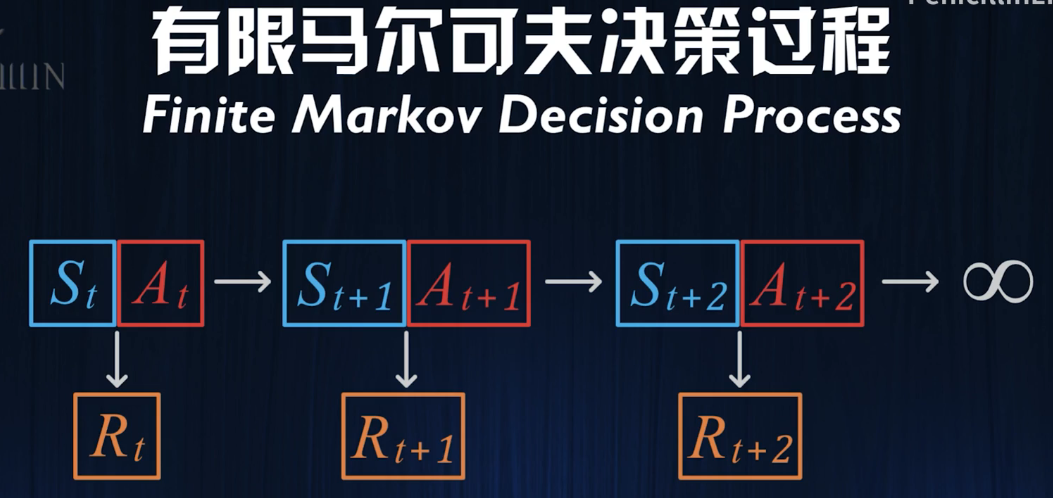
由此,我们明确了状态 行动 奖励三者的数学定义,并通过马尔可夫状态转义函数描述了他们之间的动态关系。
目标 测量 价值
接下来我们对目标 策略 价值做出定义
目标是使将来获得的所有奖励最大化,对于有限马尔可夫:
价值是对未来所有时刻的获取奖励求和
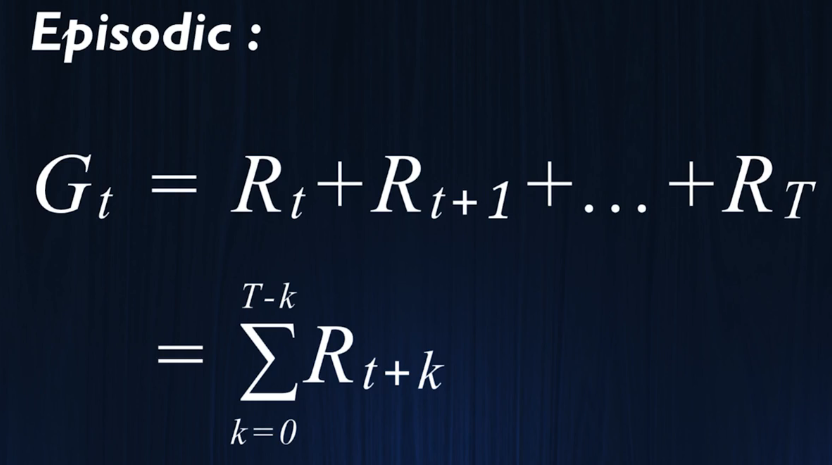 】
】
对于无线马尔可夫:
我们需要引入discountingfactor,折扣因此,否则无法积分,会积出无线。
这意味着,获取即时奖励比未来画的大饼更重要。
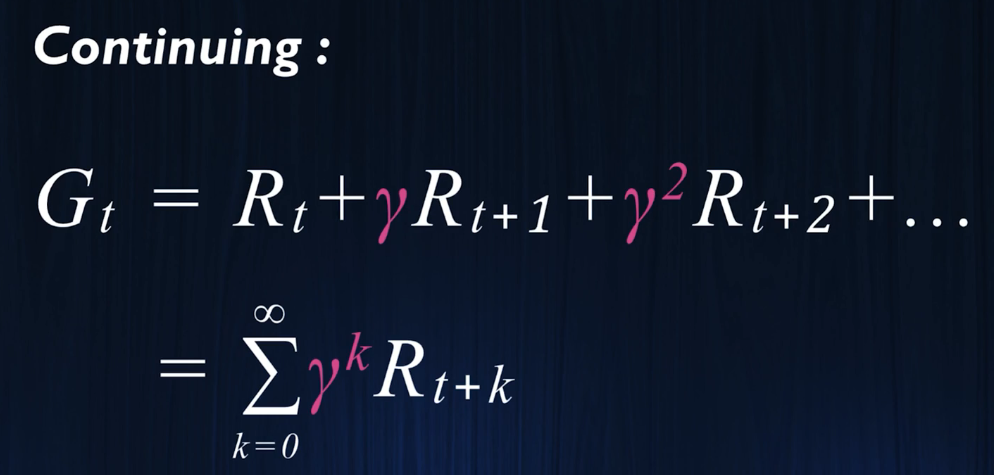
我们可以推导出两个马尔可夫过程的迭代式:
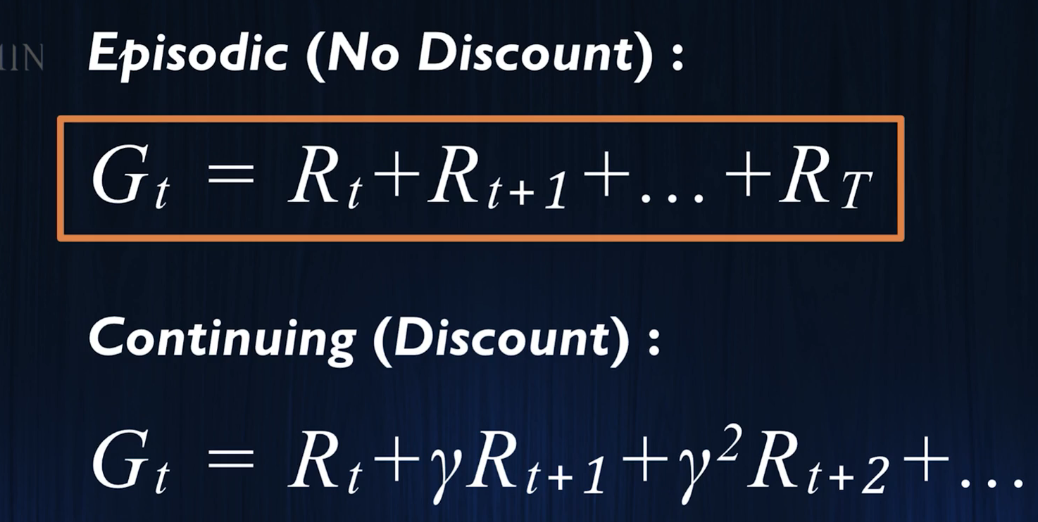
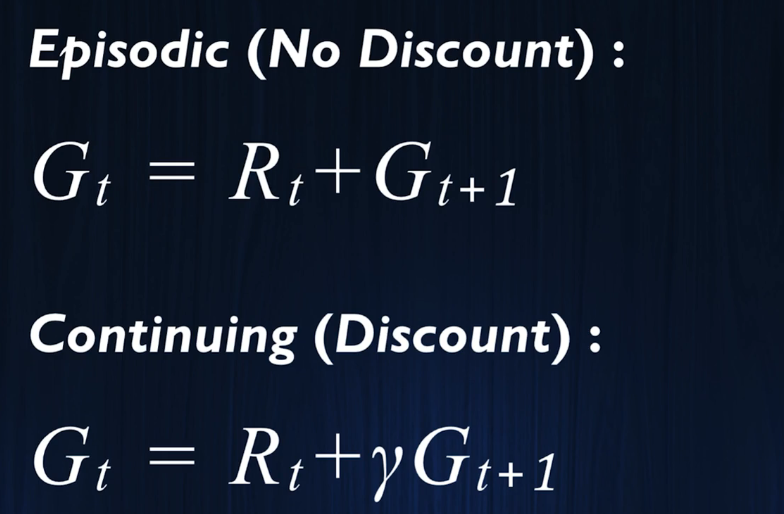
策略是告诉玩家在一个状态下应该采取什么行动.
在一个状态下,智能体可能有不同的行动空间,因此有不同的概率选择不同的行动,因此我们映入行动概率函数Π,代表了在状态s下采取动作a的概率
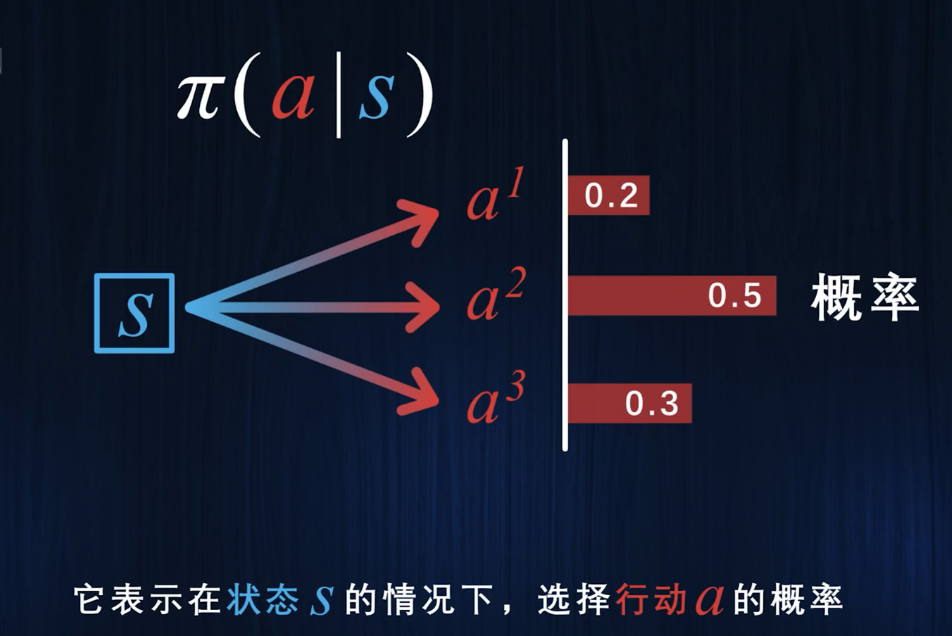
价值是未来所能获得的奖励之和的期望值,因此可以通过回报定义价值
首先是状态价值,在处于状态S时,将来所能获得的奖励之和的期望值(状态价值):

状态行动价值是处于S并采取a时,未来的获得的奖励之和(后果价值):

往往策略发生改变,价值也会改变。
总结:
马尔可夫过程由状态s 行动 a 奖励r构成,其如何选择动作就是策略,策略指当前状态s下采取动作ai的概率,而采取这个ai会获得什么样的奖励,则是状态转移函数所描述的问题。其刻画了在状态s0下采取动作ai,获得奖励r,且转移到下一个状态s’的概率。我们一般通过这个转移函数来估计价值,从而构造策略,我们常用的策略有动态规划DP等。
马尔可夫分为有限和无限两种,
强化学习的目标是使得奖励之和,也就是回报,最大化。而由于无限的马尔可夫奖励积分可能无穷,因此考虑增加一个折扣因子,这意味着,智能体会更关注当下的即时奖励。
因此我们可以得到两种马尔可夫过程的价值迭代函数。
奖励之和就是回报,回报正比于价值,价值是奖励之后的期望值。
价值分为两种,一种是状态价值,也就是当前状态的价值,另一种是状态-行动1价值,也就是执行完某个动作后后果的价值,也被称为后果价值。










评论前必须登录!
注册