 网硕互联帮助中心
网硕互联帮助中心第四章:大模型(LLM)
第五部分:LLM实战: 实现GPT2
第一节:文本token到Embedding的代码实现
本节目标:
-
理解 GPT-2 在接收输入时如何将自然语言文本转化为模型可处理的张量(Tensor)表示。
-
熟悉 Tokenizer 与 Embedding Layer 的配合方式。
-
编写简易的 GPT-2 风格文本输入处理代码。
1. 从自然语言到 Token
在 GPT-2 中,自然语言需要被分词器(Tokenizer)处理为离散 token id。
示例文本:
text = "Hello, how are you?"
使用 HuggingFace 的 GPT-2 Tokenizer:
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
token_ids = tokenizer.encode(text, return_tensors="pt")
print("Token IDs:", token_ids)
print("解码结果:", tokenizer.decode(token_ids[0]))
输出(示意):
Token IDs: tensor([[15496, 11, 703, 389, 345]])
解码结果: Hello, how are you?
GPT-2 使用的是 Byte Pair Encoding(BPE) 分词方式,将词语分成子词或字符级别的单位,更利于处理罕见词和拼写变体。
2. 将 Token IDs 转换为 Embedding
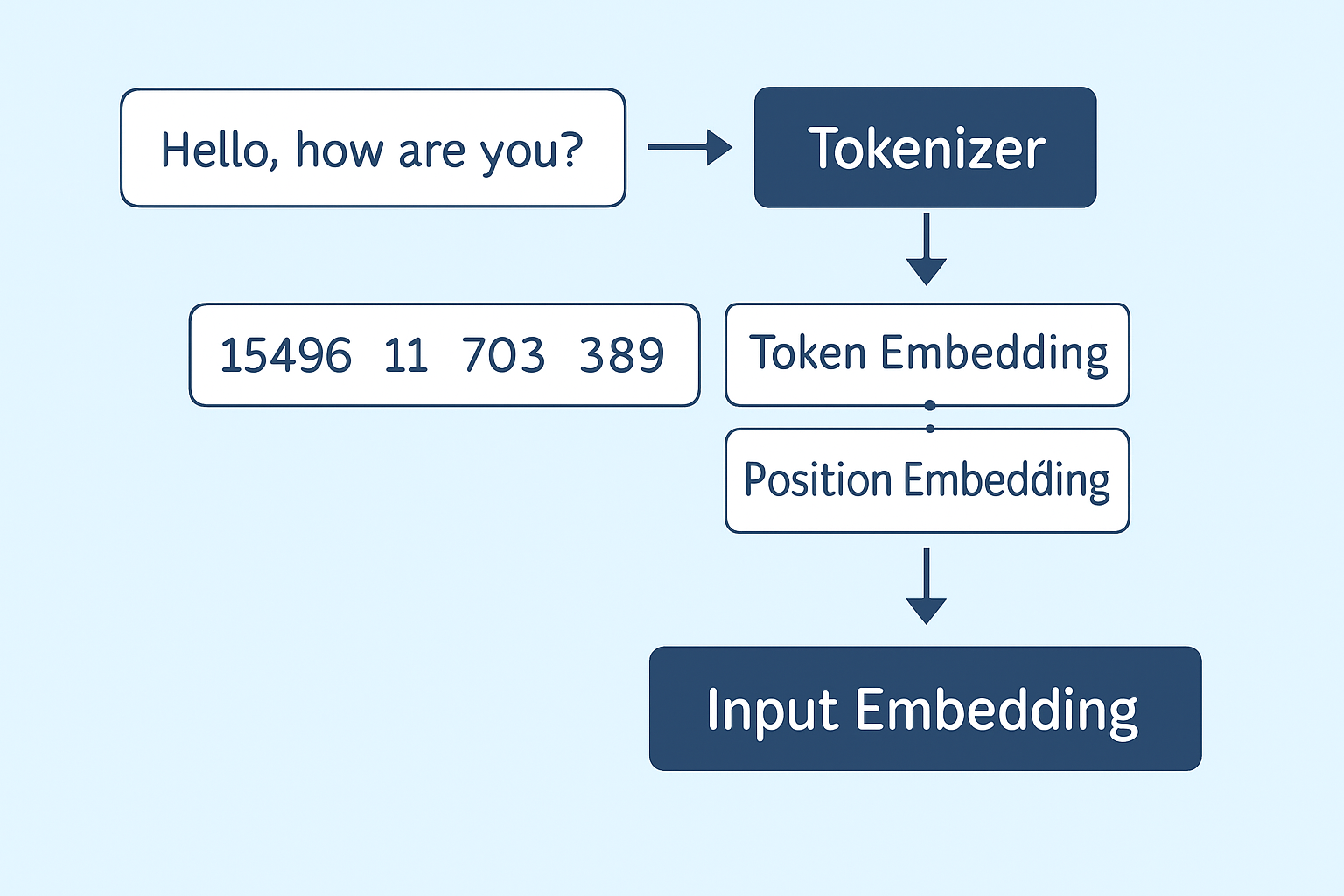
GPT-2 模型的输入是一个张量(tensor),需要用 embedding 层将 token ids 转换为连续向量。
GPT-2 的输入嵌入层包括两部分:
-
词嵌入(token embedding)
-
位置嵌入(position embedding)
用 PyTorch 自定义实现:
import torch
import torch.nn as nn
vocab_size = tokenizer.vocab_size # 词表大小
embedding_dim = 768 # GPT-2 small 模型的默认维度
max_position_embeddings = 1024 # 支持的最大序列长度
# 定义词嵌入和位置嵌入
token_embedding = nn.Embedding(vocab_size, embedding_dim)
position_embedding = nn.Embedding(max_position_embeddings, embedding_dim)
# 输入 token
input_ids = token_ids # 形状: [batch_size, seq_len]
seq_len = input_ids.size(1)
# 生成位置索引
position_ids = torch.arange(seq_len, dtype=torch.long).unsqueeze(0) # [1, seq_len]
# 获取嵌入向量
token_embeds = token_embedding(input_ids)
position_embeds = position_embedding(position_ids)
# 最终输入嵌入(两者相加)
input_embeddings = token_embeds + position_embeds
print("Input Embedding shape:", input_embeddings.shape) # [1, seq_len, embedding_dim]
总结:本节核心要点
| 文本分词 | 使用 GPT2Tokenizer 将文本编码为 token ids | 离散化 |
| 词嵌入 | 将 token id 映射到 dense vector | 表示 token 含义 |
| 位置嵌入 | 编码 token 在序列中的位置信息 | 保留顺序信息 |
| 叠加嵌入 | token_embed + position_embed | 构成输入层向量 |
小贴士:
-
GPT-2 的 Tokenizer 是 无空白区分的,因此多个词可能被拆成子词。
-
所有嵌入层参数是可训练的,会在训练过程中被更新。
-
若手动构建模型,需确保 embedding 的 shape 与 Transformer 模块匹配。




评论前必须登录!
注册