 网硕互联帮助中心
网硕互联帮助中心@4卡4090服务器GraphRAG环境部署、加载ollama向量模型及向量知识图谱构建、加载vllm本地DeepSeek 32B推理模型无缝接入及API接口调用
本人安装的硬件环境如下:
CPU:intel至强金牌6148*2主频2.5G 共40核80线程
内存:三星32G DDR4服务器内存2933 *4=128GB
显卡:英伟达4090涡轮公版 *4 = 96G
操作系统:ubuntu 24.04 LTS
conda:Anaconda 24.11.3
部署GraphRAG环境
1.创建虚拟环境,本项目由于部署GraphRAG稳定版本,经多次测试python3.10版本相对较稳定。
conda create -n graphrag python=3.10 -y
2.进入创建的GraphRAG环境
conda activate graphrag
虚拟环境创建成功如下图所示。
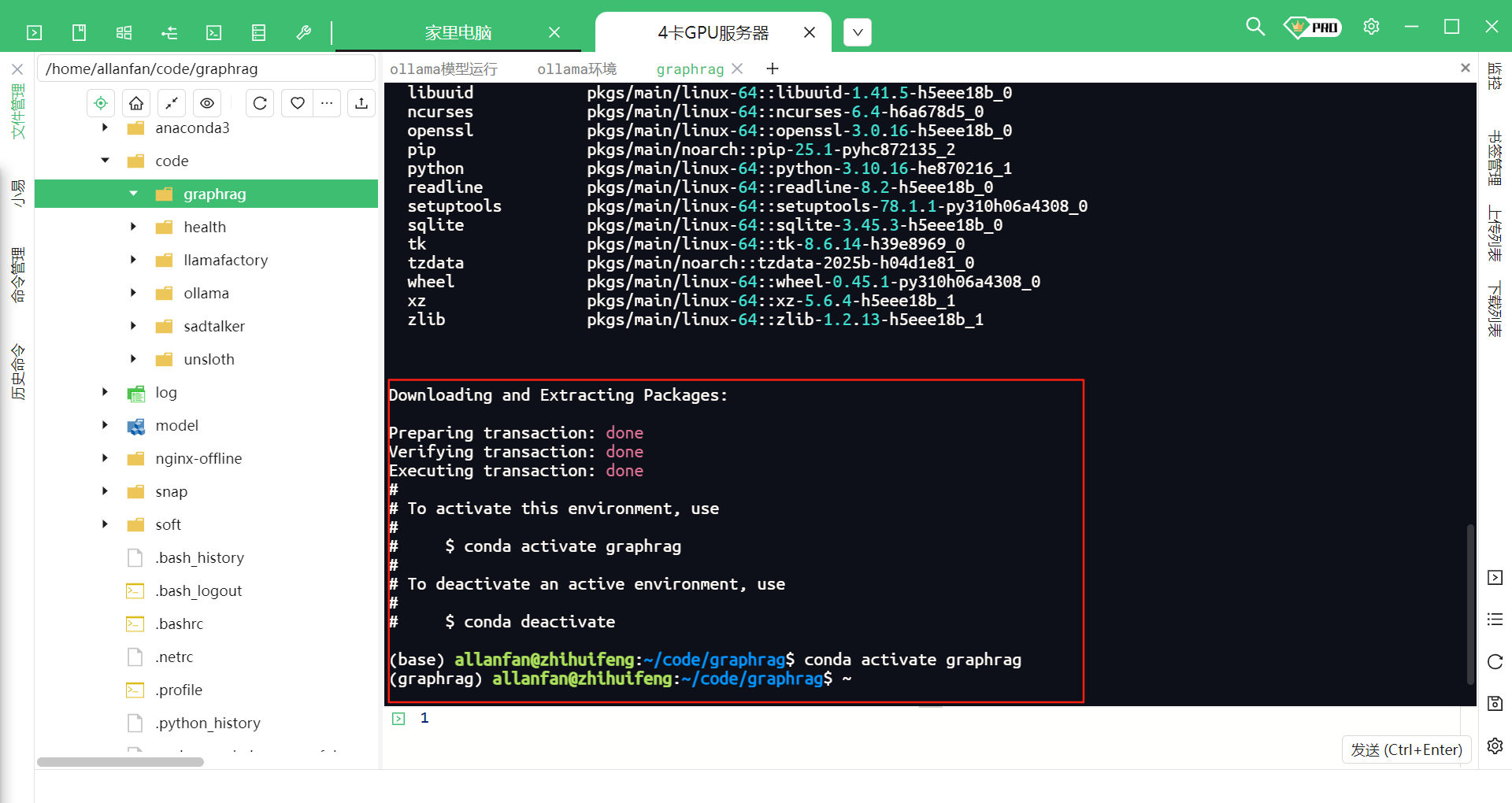
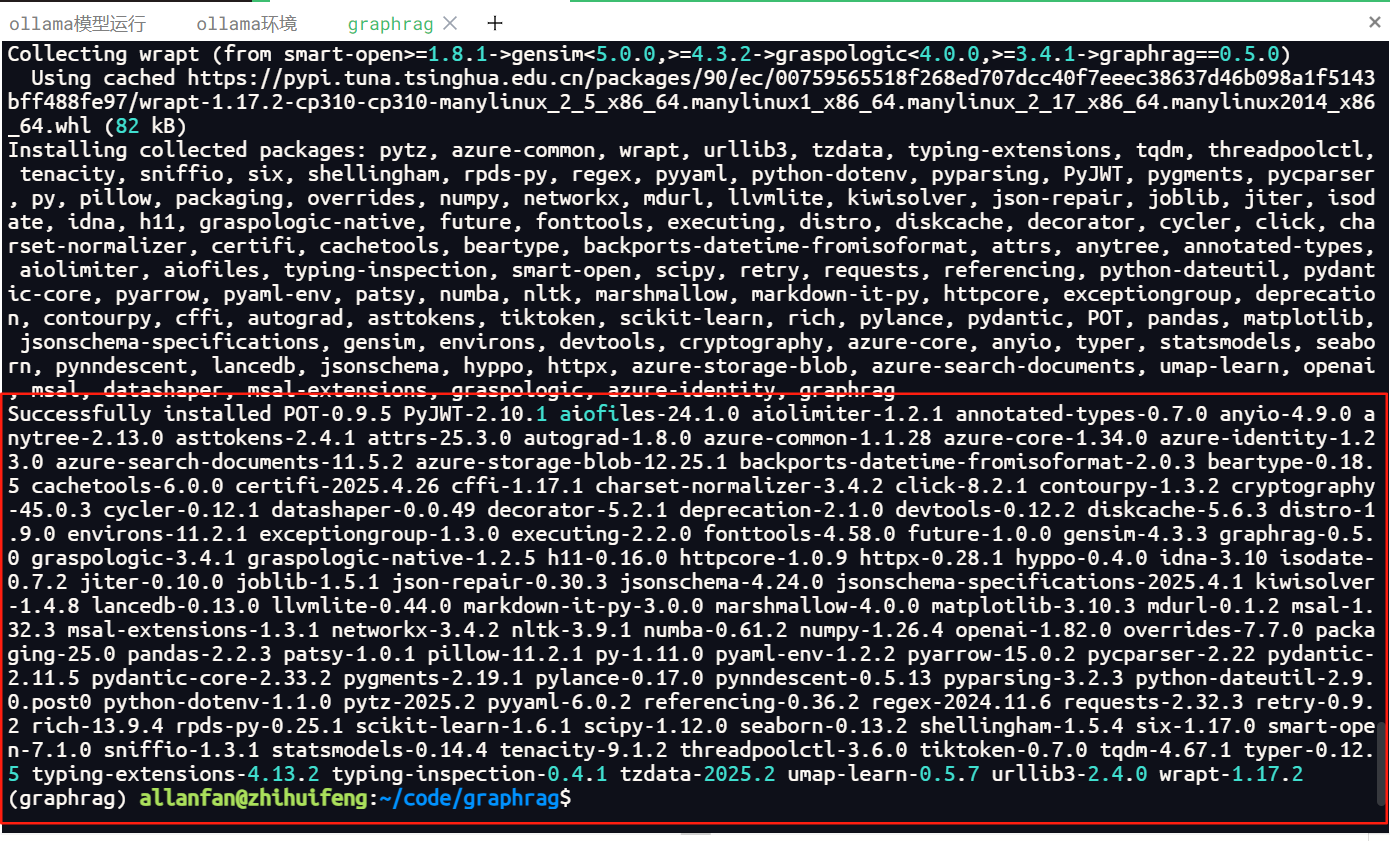
3.安装graphrag环境,本项目安装的稳定的0.5.0版本
pip install graphrag==0.5.0
安装成功如下图所示。
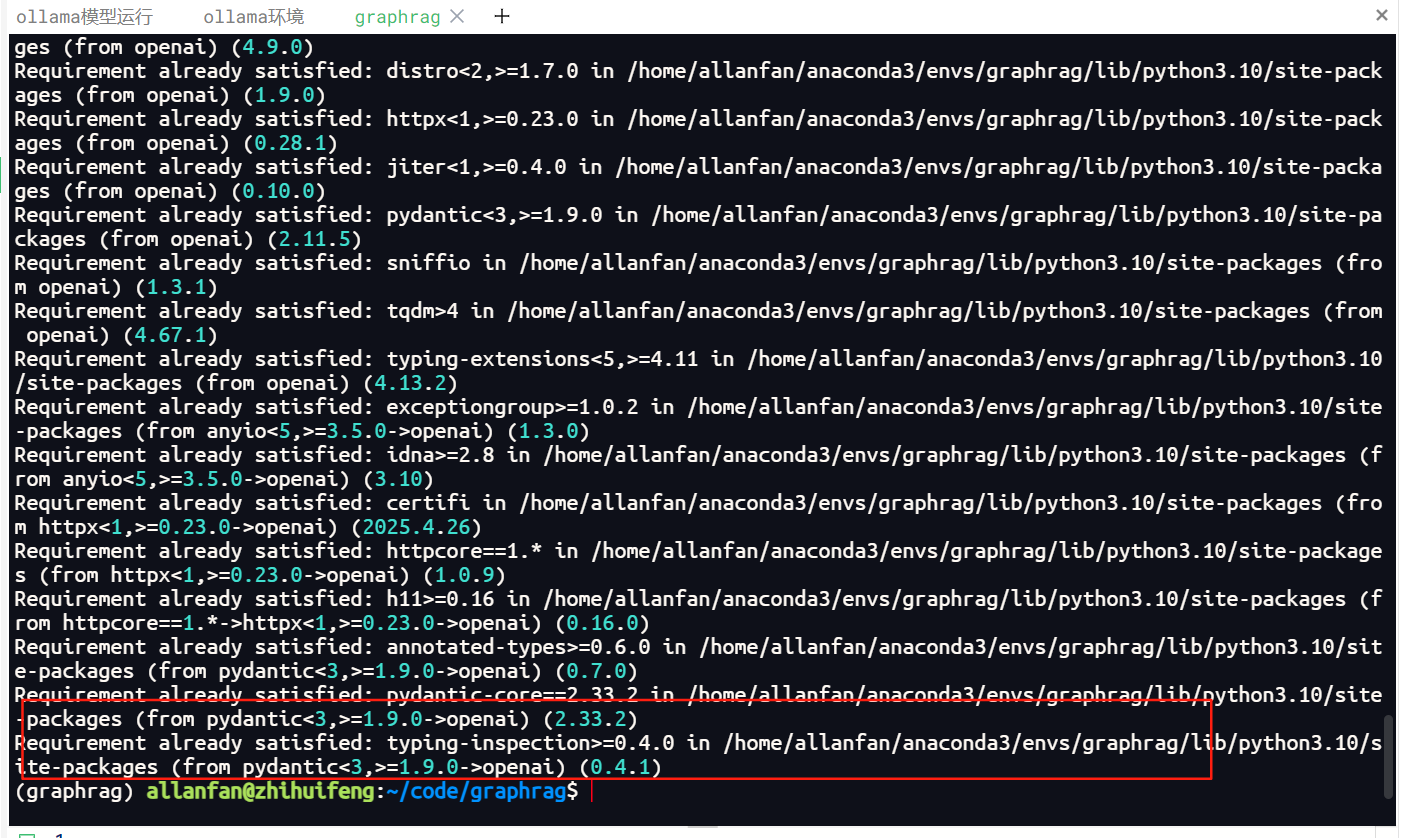
4.安装openai标准接入大模型的API协议依赖项
pip install openai
安装成功如下图所示。
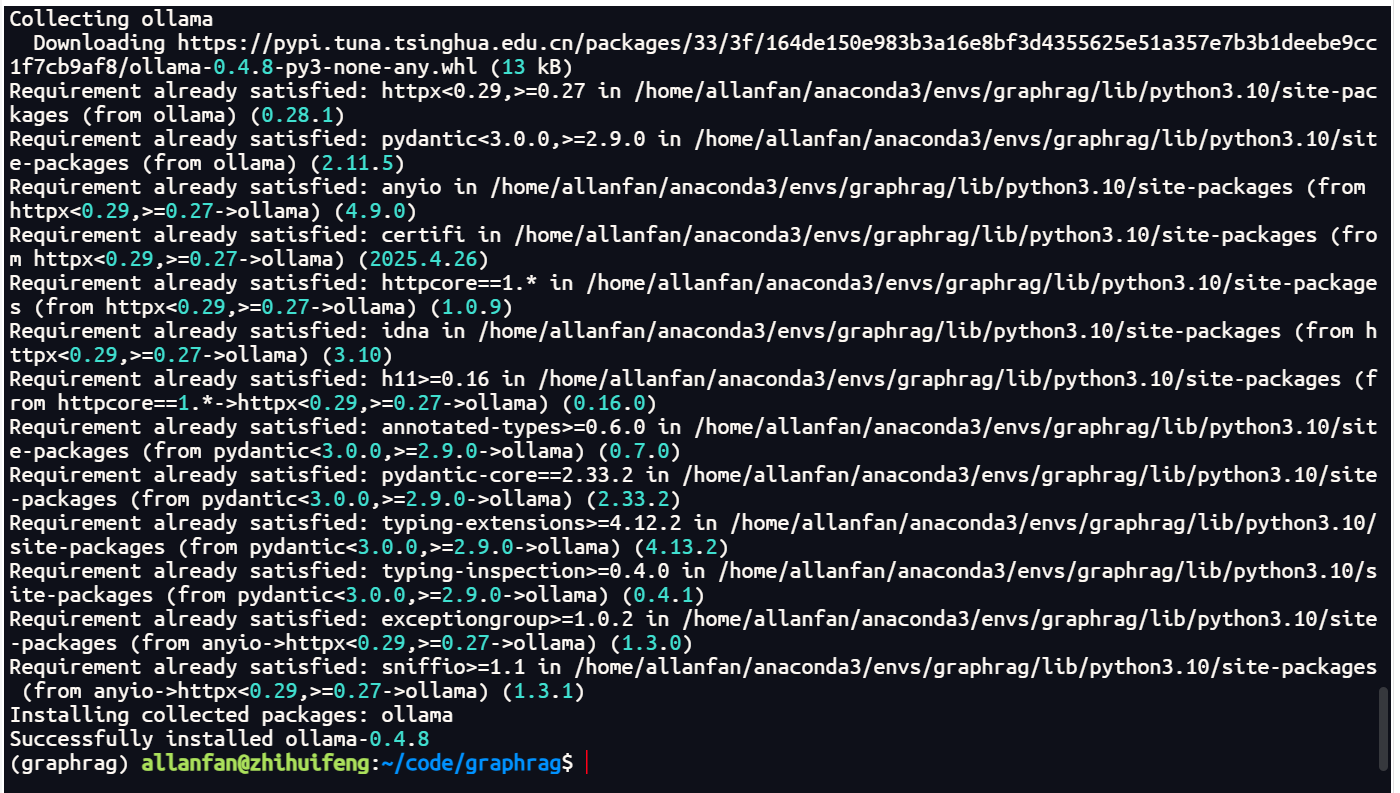
5.安装调用ollama服务的依赖项
pip install ollama
安装成功如下图所示。
6.由于graphrag发布是基于openai环境的,因此本地化部署及调用本地推理大模型,需要修改graphrag开源的配置文件,满足项目文件调用本地推理模型,支持数据保密相关业务运行;共需要修改三个Graphrag的python的源代码文件,修改简单,但是也需要会python编程技术,防止修改后格式问题报错。
6.1.修改llm/openai/openai_embeddings_llm.py的GraphRAG源代码文件,查找路径在conda系统目录下的env->当前安装环境,我当前项目名是graphrag->lib/python3.10/site-packages/graphrag目录下,当前我的项目具体目录是
/home/allanfan/anaconda3/envs/graphrag/lib/python3.10/site-packages/graphrag
当前项目找到的graphrag源代码位置目录如下图所示。
备注:大家的项目根据安装的conda环境目录,按我上面一直找下去即可,当前python环境是3.10,其它更高版本我试过,不太好用。如果大家有时间可以试一下更高版本,但是graphrag 0.5.0以上版本完全基于openai协议,个人尝试很多次无法本地化接推理模型。
通过上面目录向下找到llm/openai/openai_embeddings_llm.py源文件,用sudo nano打开文件注释掉下面代码,然后添加以下新代码。
sudo nano openai_embeddings_llm.py
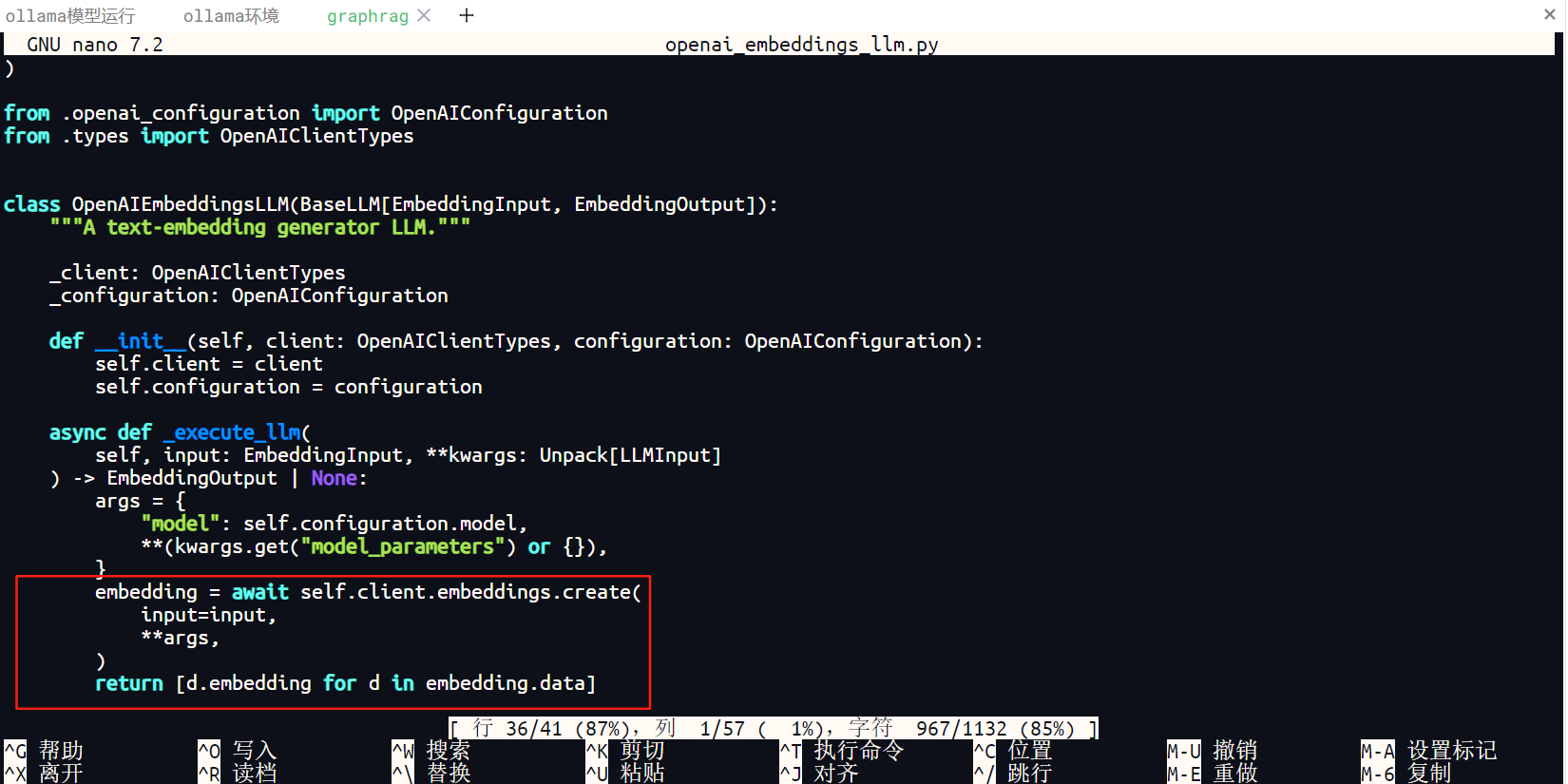
注释36行至41行,注释具体代码如下所示,行数仅供参考,具体是以下代码。
'''embedding = await self.client.embeddings.create(
input=input,
**args,
)
return [d.embedding for d in embedding.data]'''
注释代码如下图所示。
添加代码如下所示。其中,向量模型名称根据自己下载的模型命名修改,本项目测试用的是nomic-embed-text模型。
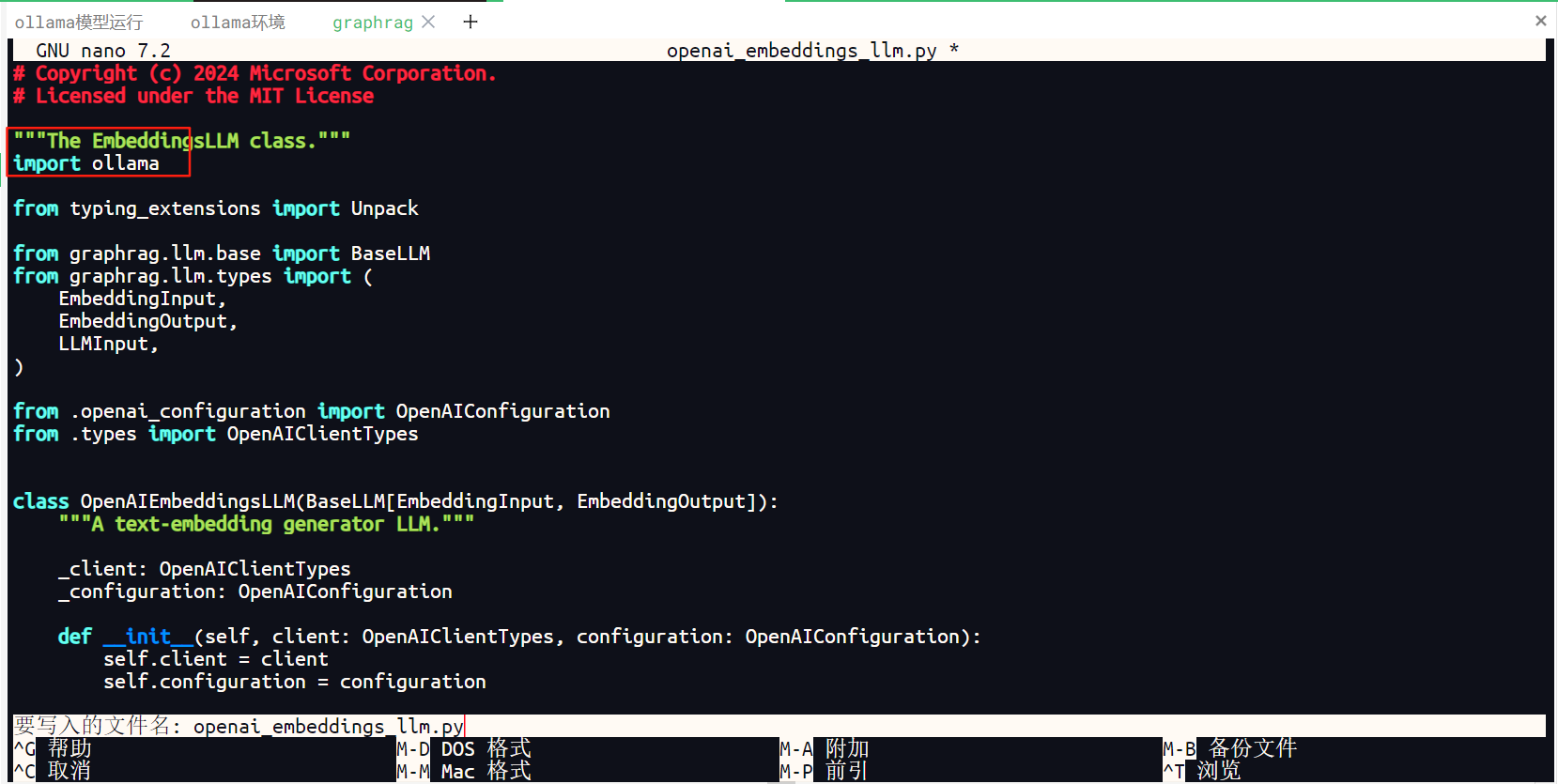
文件头部添加引用本地ollama依赖项
import ollama
如下图所示。
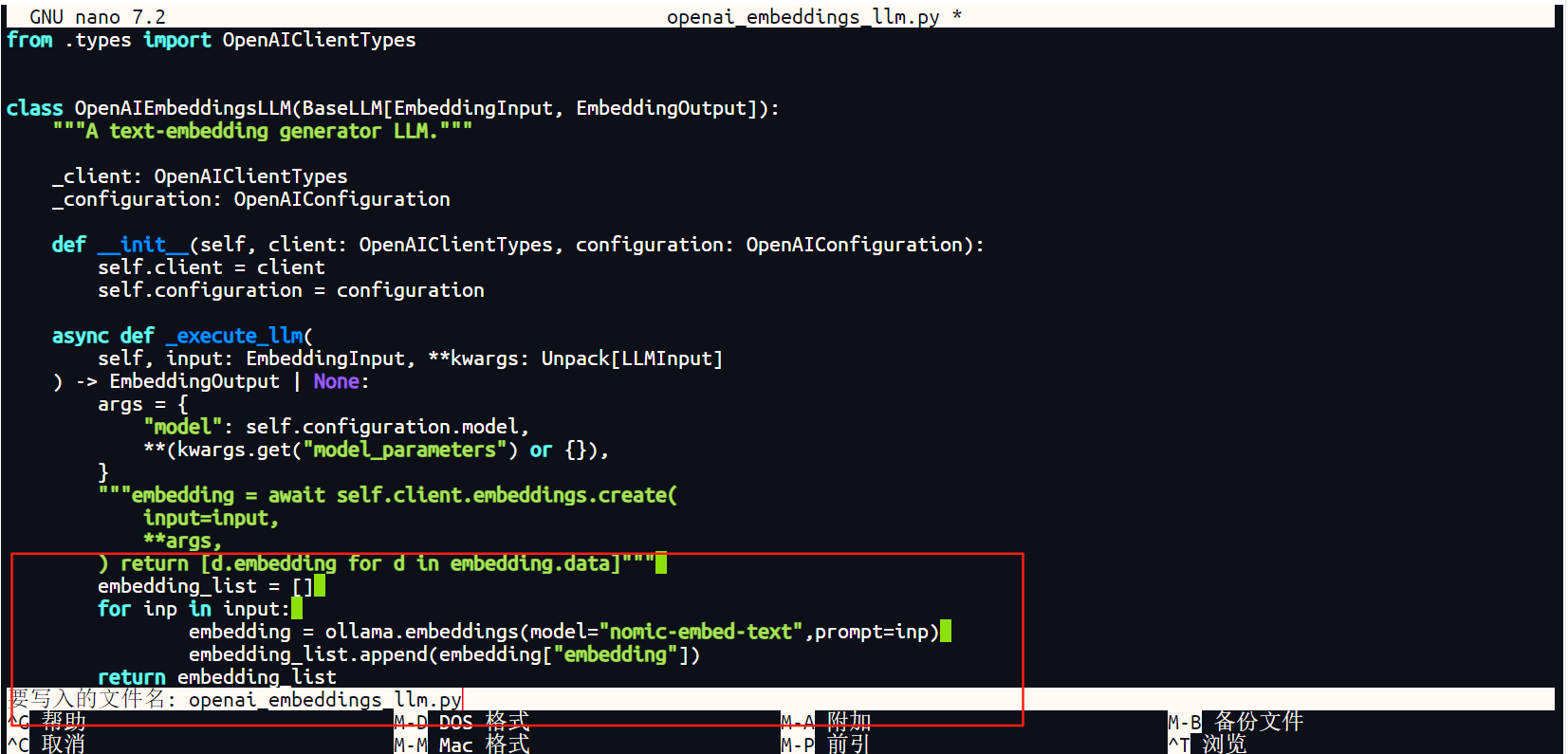
上面注释后面添加以下代码
embedding_list = []
for inp in input:
embedding = ollama.embeddings(model="nomic-embed-text",prompt=inp)
embedding_list.append(embedding["embedding"])
return embedding_list
添加新代码如下图所示。
nano保存文件按ctrl+o,保存后退出按ctrl+c。修改后整体代码参考如下所示。
# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""The EmbeddingsLLM class."""
import ollama
from typing_extensions import Unpack
from graphrag.llm.base import BaseLLM
from graphrag.llm.types import (
EmbeddingInput,
EmbeddingOutput,
LLMInput,
)
from .openai_configuration import OpenAIConfiguration
from .types import OpenAIClientTypes
class OpenAIEmbeddingsLLM(BaseLLM[EmbeddingInput, EmbeddingOutput]):
"""A text-embedding generator LLM."""
_client: OpenAIClientTypes
_configuration: OpenAIConfiguration
def __init__(self, client: OpenAIClientTypes, configuration: OpenAIConfiguration):
self.client = client
self.configuration = configuration
async def _execute_llm(
self, input: EmbeddingInput, **kwargs: Unpack[LLMInput]
) –> EmbeddingOutput | None:
args = {
"model": self.configuration.model,
**(kwargs.get("model_parameters") or {}),
}
"""embedding = await self.client.embeddings.create(
input=input,
**args,
) return [d.embedding for d in embedding.data]"""
embedding_list = []
for inp in input:
embedding = ollama.embeddings(model="nomic-embed-text",prompt=inp)
embedding_list.append(embedding["embedding"])
return embedding_list
6.2.修改qutry/llm/oai/embedding.py源代码文件,还在当前我的项目下查找该源代码文件,下面当前我项目的graphrag目录.
/home/allanfan/anaconda3/envs/graphrag/lib/python3.10/site-packages/graphrag
找到qutry/llm/oai/embedding.py,如下图所示。
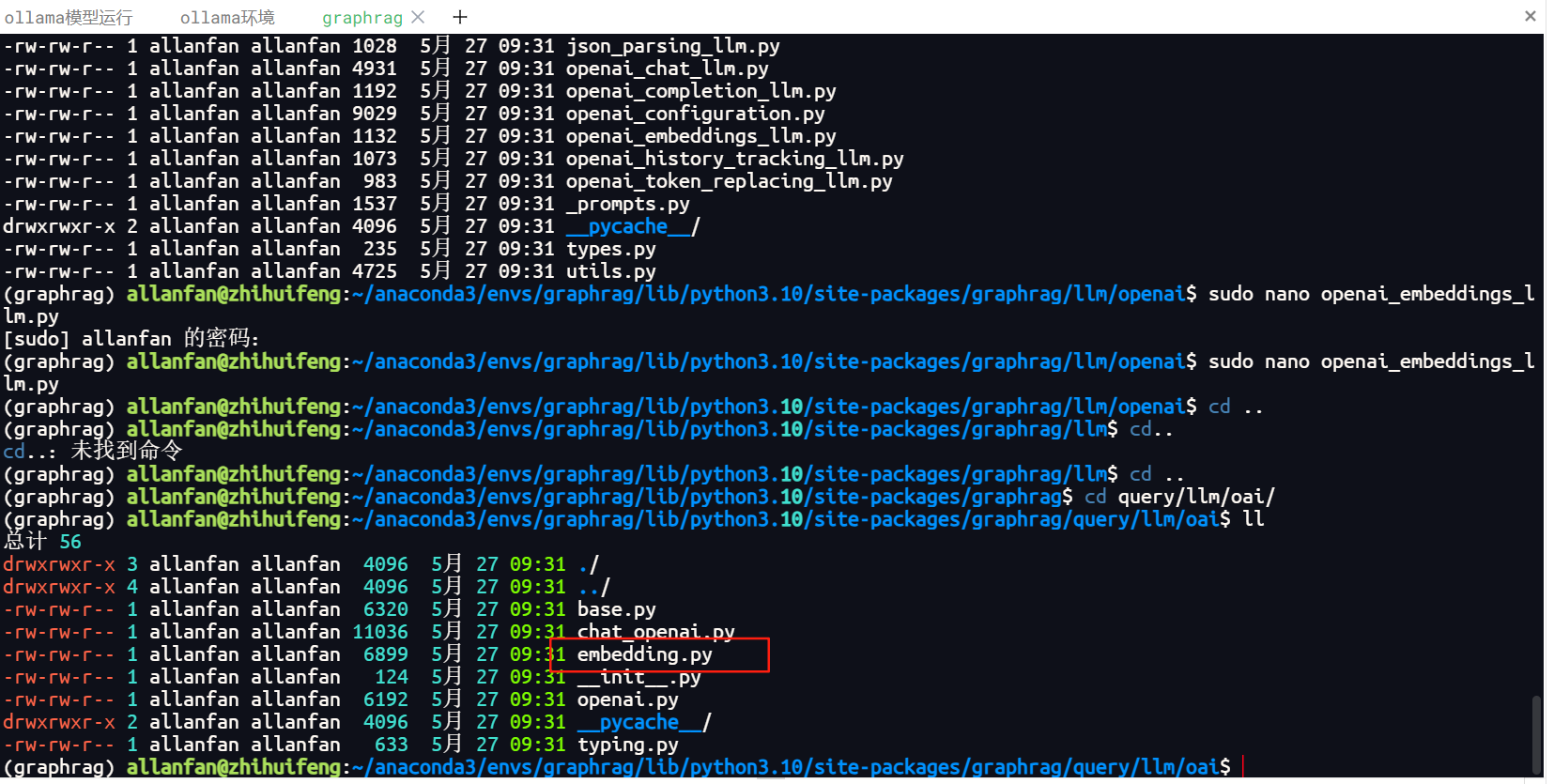
用nano命令打开文件,注释及添加以下代码。
sudo nano embedding.py
文件头部添加引用本地ollama依赖项
import ollama
如下图所示。
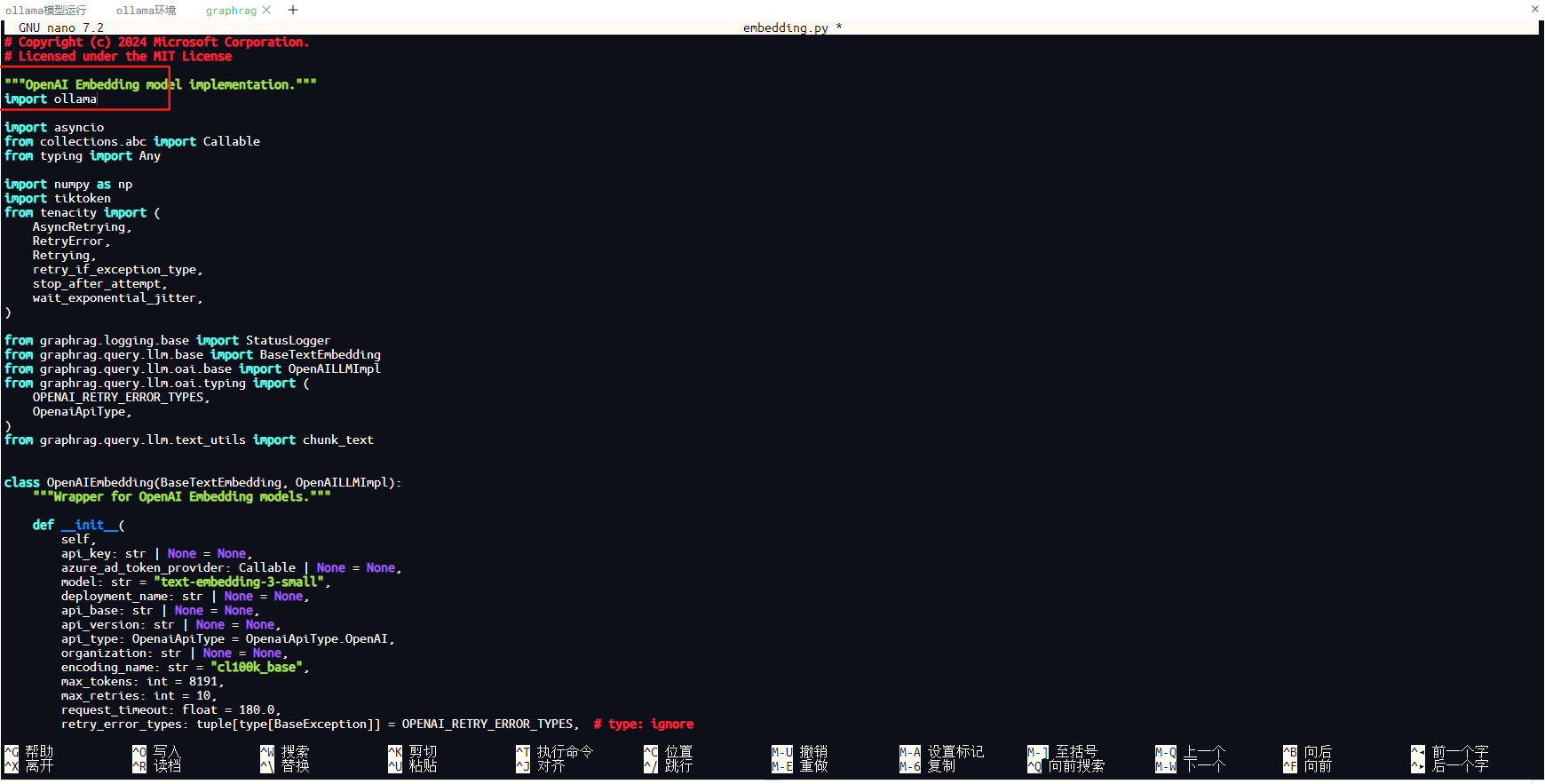
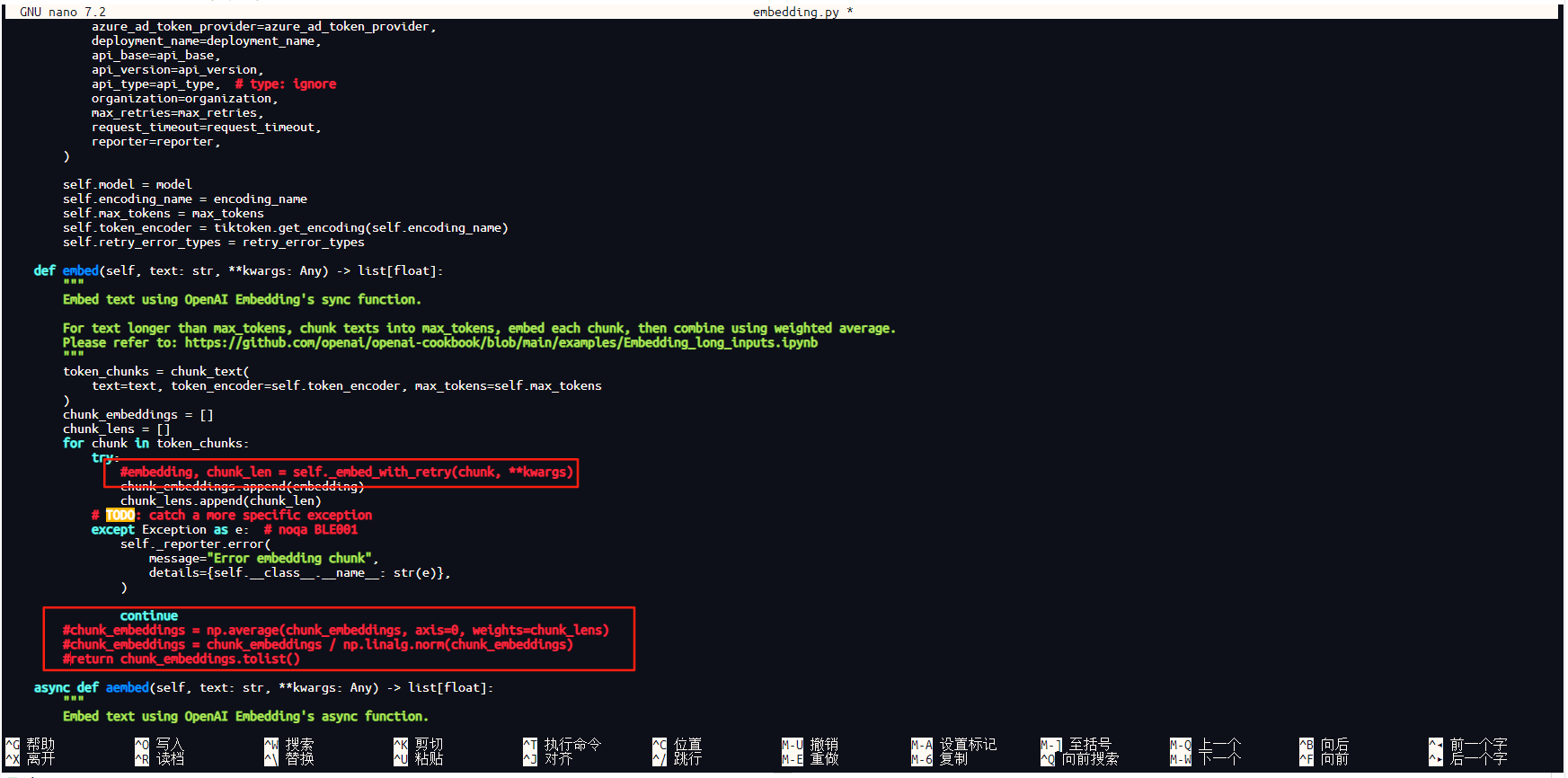
找到源代码中两处以下代码,如下所示
第一处:
embedding, chunk_len = self._embed_with_retry(chunk, **kwargs)
第二处:
chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens)
chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings)
return chunk_embeddings.tolist()
将上面两处代码添加#,注释掉,操作如下图所示。
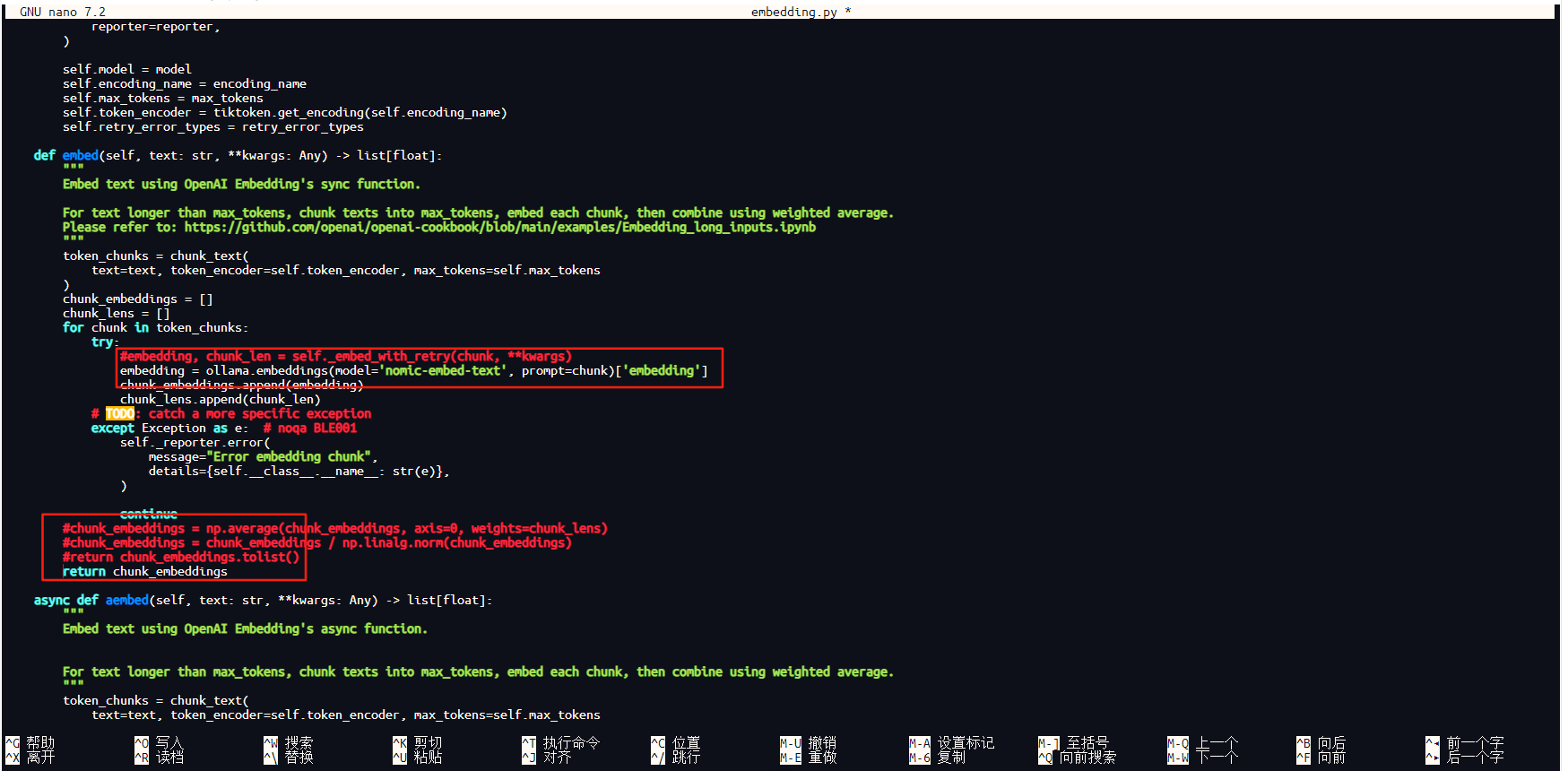
在上面两处注释后面添加以下两段新代码,其中,第一处代码模型名称根据实际模型名称修改,本项目向量模型使用的是nomic-embed-text。
第一处:
embedding = ollama.embeddings(model='nomic-embed-text', prompt=chunk)['embedding']
第二处:
return chunk_embeddings
具体添加代码后,如下图所示。
添加好新代码后按ctrl+o保存,保存后按ctrl+c退出即可。
6.3.修改qutry/llm/text_utils.py源代码文件,,还在当前我的项目下查找该源代码文件,下面当前我项目的graphrag目录.
/home/allanfan/anaconda3/envs/graphrag/lib/python3.10/site-packages/graphrag
找到qutry/llm/text_utils.py,如下图所示。
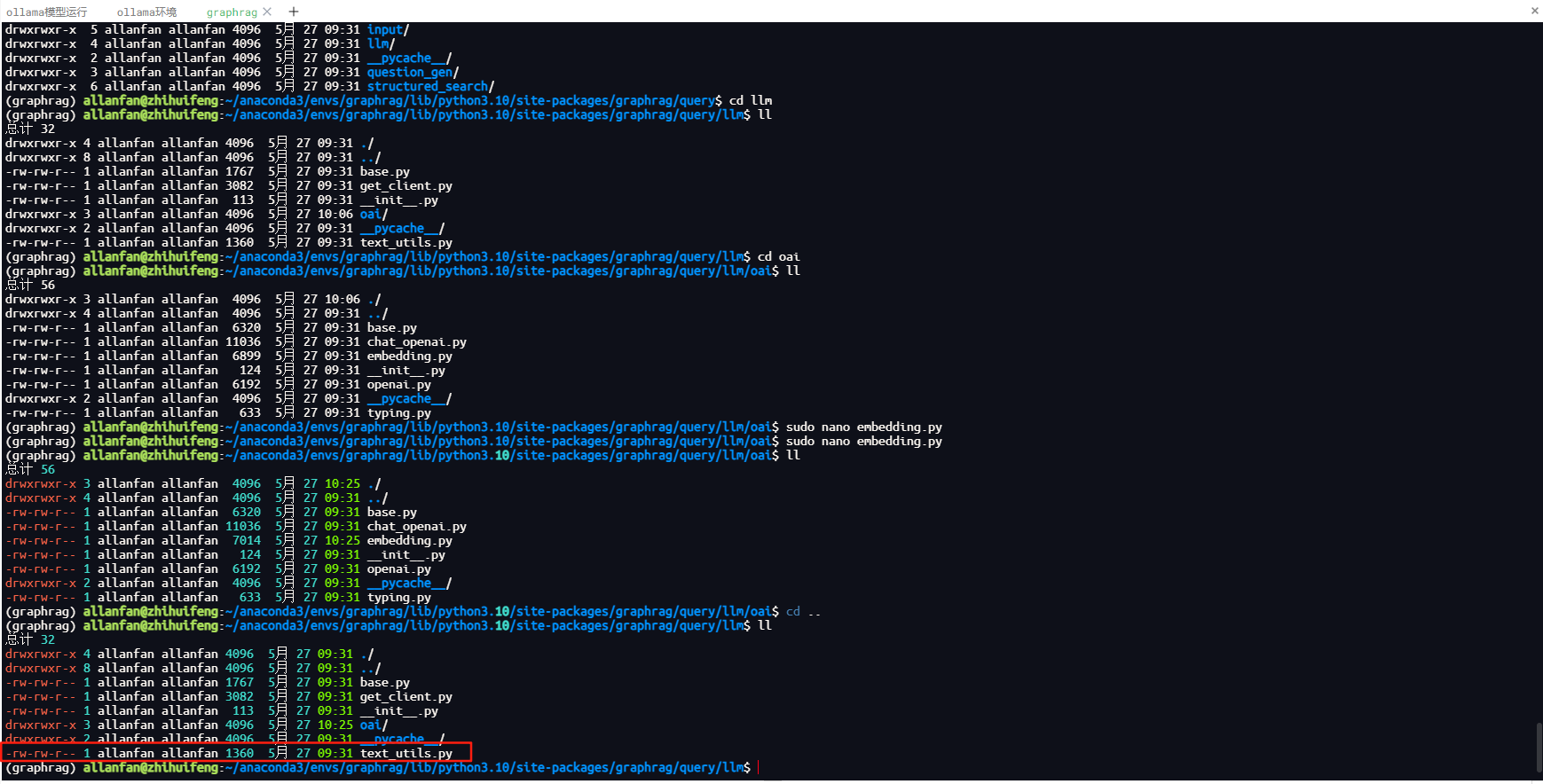
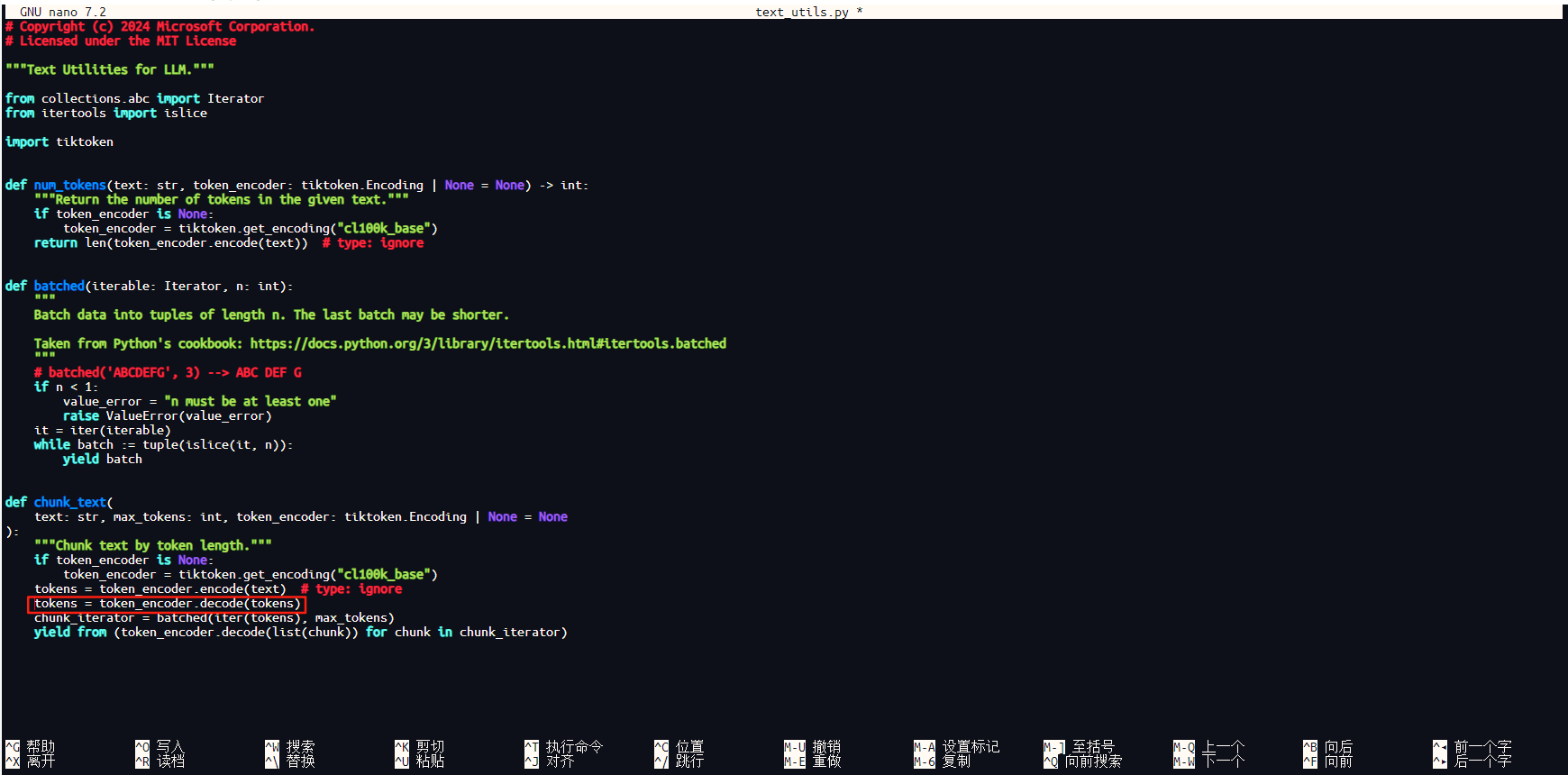
使用sudo nano打开源代码文件,添加以下一行代码即可,该代码是将tokens解码成字符串。
tokens = token_encoder.decode(tokens)
添加上面代码位置如下图所示。
添加好新代码后按ctrl+o保存,保存后按ctrl+c退出即可。
至此GraphRAG环境部署已完成,接下来开始GraphRAG的知识库索引构建、知识库查询服务等。
GraphRAG配置ollama向量模型、配置本地vllm的DeepSeek 32B推理模型、知识库构建、示例知识库的查询
1.创建知识库目录,本项目示例民政部相关文件构建知识库,个人先在民政部下载“民政部2024年11月文告”的PDF版,通过python程序将pdf转化成word,转化程序大家可以采用在线转换,或者WPS转换,这里就不做简单的python转化程序分享;在当前项目根目录下,本人创建的知识目录名称为minzheng,具体如下图所示。
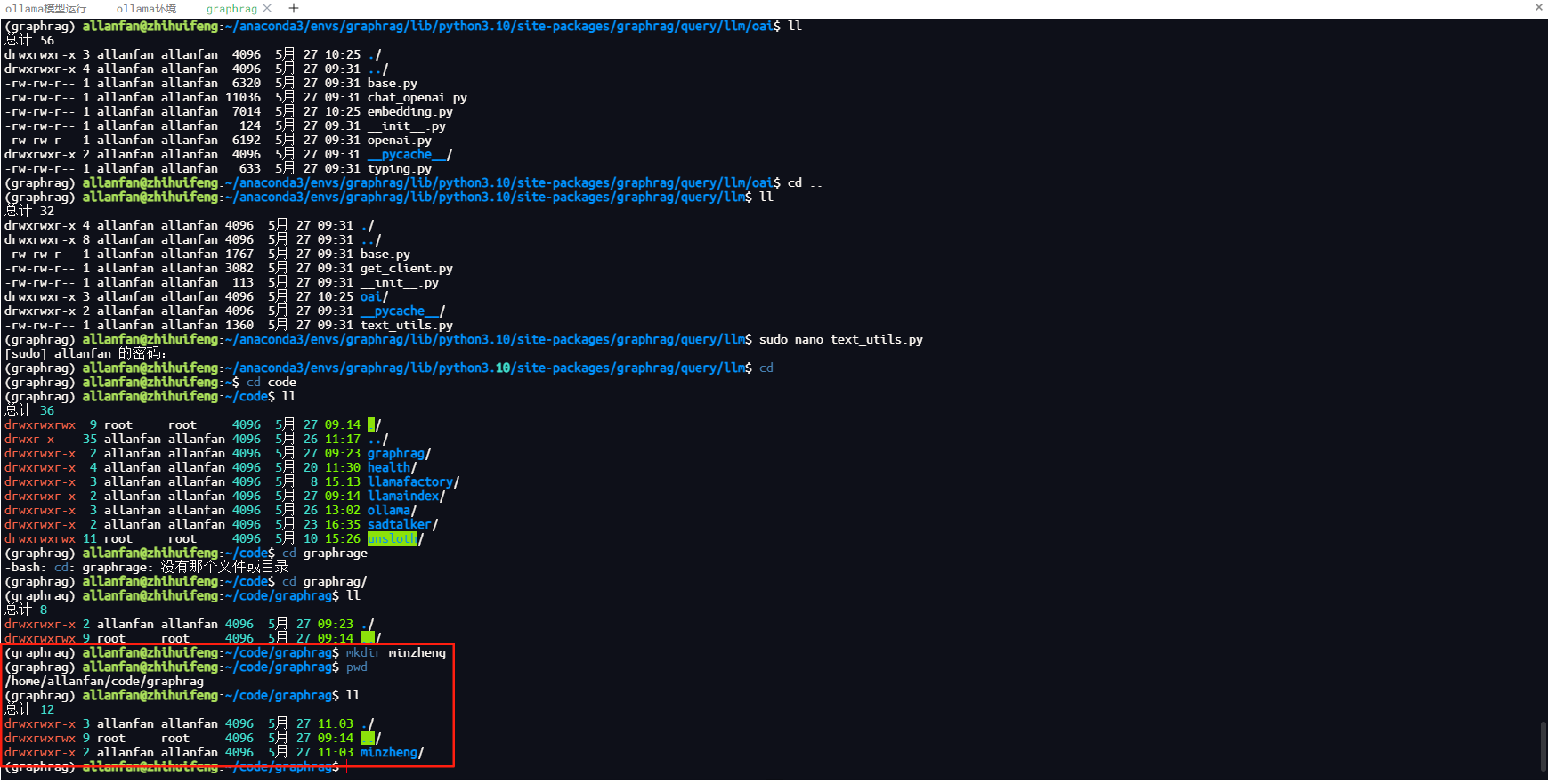
2.在项目根据下,对minzheng目录初始构建知识库索引,执行命令如下。注意:执行环境一定要在上面自己命名的CONDA环境下,本项目CONDA环境名称为graphrag,否则执行报错。
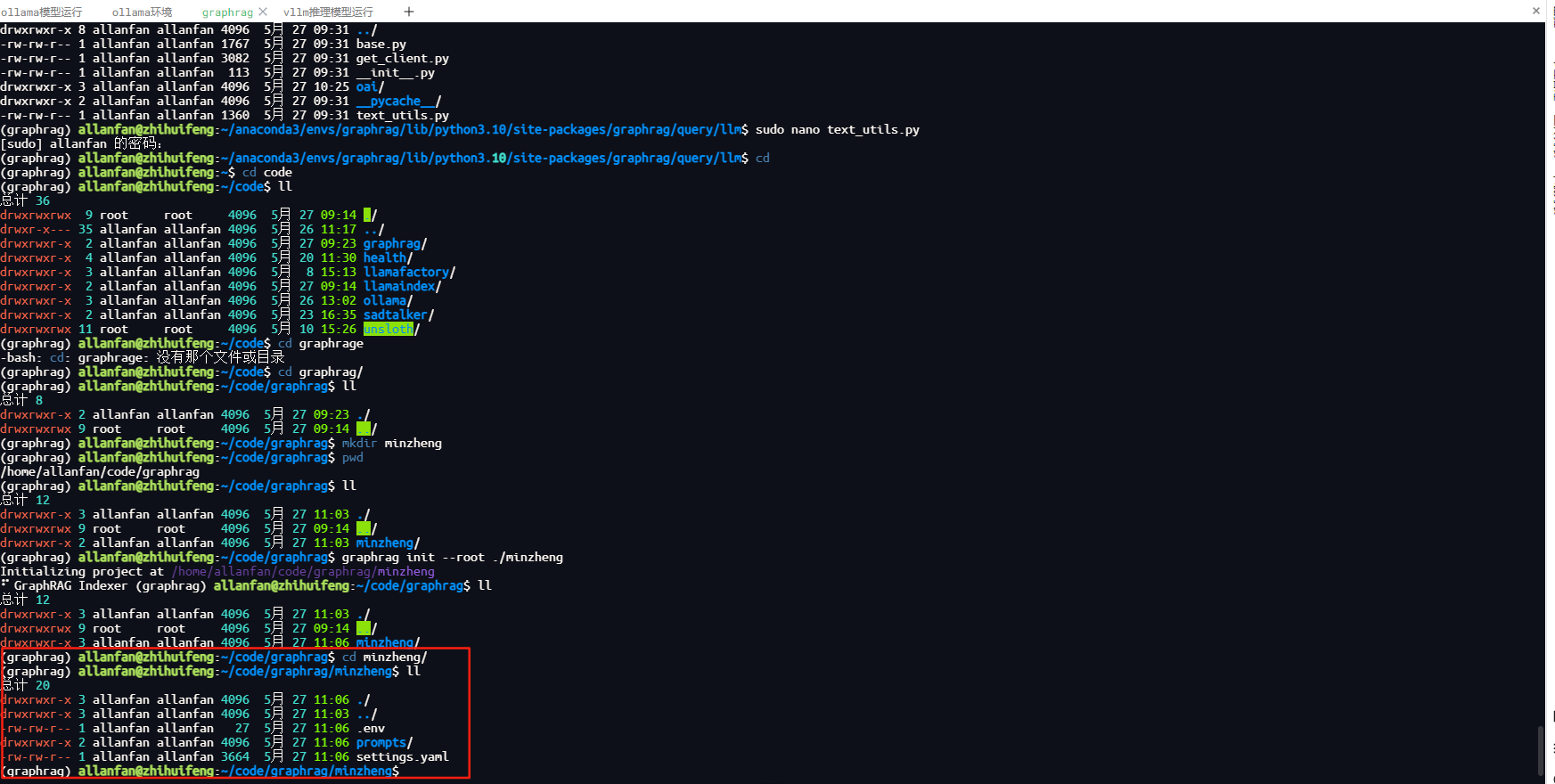
graphrag init –root ./minzheng
执行完成之后,进入minzheng目录,会看到graphrag初始化创建的目录及文件,.env项目配置文件; settings.yaml项目运行配置及依赖文件prompts项目提示词工程,这个文件很重要,他是知识图谱最核心地方,构建项目简单,但是针对业务构建符合业务的工作全在这里,一个好的知识库就看你写的提示词了。
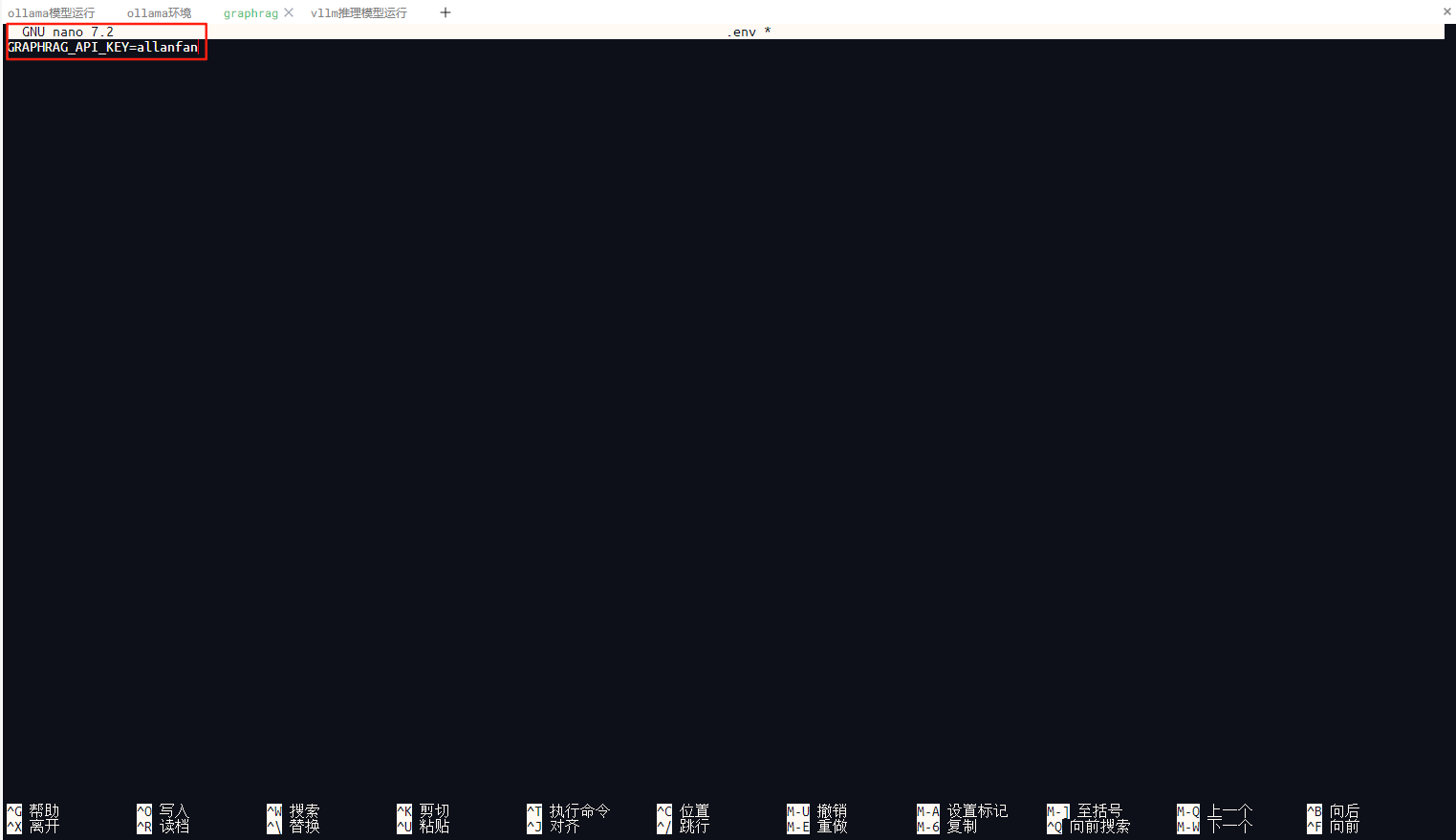
3.修改当前项目配置文件.env,当前项目采用本地ollama部署的推理模型进行知识图谱构建及查询,部署环境已修改源代码为调用本地,如果不修改,本地需要在openai申请API密钥,在该文件配置即可,由于调用本地vllm部署的DeepSeek 32B推理模型,同时本地化调用vllm启用api_key,因此本配置文件可修改为我设置的api_key即可,我设置本地部署的DeepSeek 32B的api_key是allanfan。
为了个人更好识别是调用本地,建议修改配置为
GRAPHRAG_API_KEY=allanfan
具体如下图所示。
修改好后按ctrl+o保存,保存后按ctrl+c退出即可。
4.修改当前项目配置文件settings.yaml,该文件原内容如下。
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/
### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls – check the docs.
encoding_model: cl100k_base # this needs to be matched to your model!
llm:
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
type: openai_chat # or azure_openai_chat
model: gpt-4-turbo-preview
model_supports_json: true # recommended if this is available for your model.
# audience: "https://cognitiveservices.azure.com/.default"
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
parallelization:
stagger: 0.3
# num_threads: 50
async_mode: threaded # or asyncio
embeddings:
async_mode: threaded # or asyncio
vector_store:
type: lancedb
db_uri: 'output/lancedb'
container_name: default
overwrite: true
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: text-embedding-3-small
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
### Input settings ###
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\\\.txt$"
chunks:
size: 1200
overlap: 100
group_by_columns: [id]
### Storage settings ###
## If blob storage is specified in the following four sections,
## connection_string and container_name must be provided
cache:
type: file # or blob
base_dir: "cache"
reporting:
type: file # or console, blob
base_dir: "logs"
storage:
type: file # or blob
base_dir: "output"
## only turn this on if running `graphrag index` with custom settings
## we normally use `graphrag update` with the defaults
update_index_storage:
# type: file # or blob
# base_dir: "update_output"
### Workflow settings ###
skip_workflows: []
entity_extraction:
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
enabled: false
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
embeddings: false
transient: false
### Query settings ###
## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned.
## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#query
local_search:
prompt: "prompts/local_search_system_prompt.txt"
global_search:
map_prompt: "prompts/global_search_map_system_prompt.txt"
reduce_prompt: "prompts/global_search_reduce_system_prompt.txt"
knowledge_prompt: "prompts/global_search_knowledge_system_prompt.txt"
drift_search:
prompt: "prompts/drift_search_system_prompt.txt"
上面文件我们需要关注几个地方,一个是llm配置项,一个是embeddings配置项。
首先针对settings.yaml里面的llm配置修改如下:
原文件llm代码
llm:
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
type: openai_chat # or azure_openai_chat
model: gpt-4-turbo-preview
model_supports_json: true # recommended if this is available for your model.
# audience: "https://cognitiveservices.azure.com/.default"
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
修改后llm代码
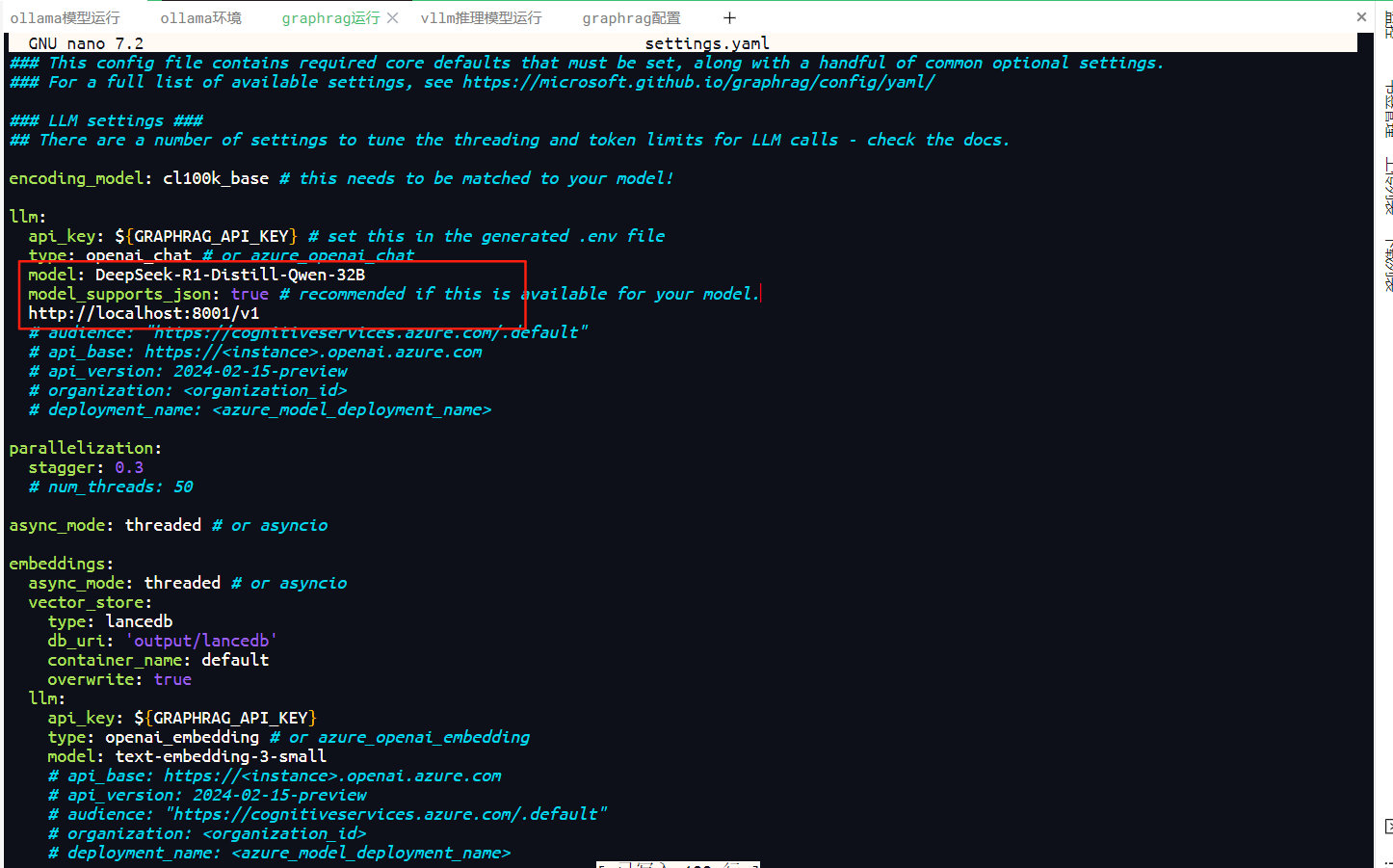
llm:
api_key: ${GRAPHRAG_API_KEY} # 取配置文件.env的APIKey,不进行修改
type: openai_chat # 当前取本地私有化部署的DeepSeek 32B,DeepSeek延用openai协议
model: DeepSeek-R1-Distill-Qwen-32B # 当前模型名称更换为本地私化部署的deepseek 32B模型名称
model_supports_json: true # recommended if this is available for your model.
api_base: http://localhost:8001/v1 # 添加本地化模型对外发布调用的地址,该地址填写自己部署的地址即可
# audience: "https://cognitiveservices.azure.com/.default"
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
修改后如下图所示。
第二步针对settings.yaml里面的embeddings配置修改如下:
原文件embeddings的代码
embeddings:
async_mode: threaded # or asyncio
vector_store:
type: lancedb
db_uri: 'output/lancedb'
container_name: default
overwrite: true
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: text-embedding-3-small
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
修改后embeddings的代码如下
embeddings:
async_mode: threaded # or asyncio
vector_store:
type: lancedb
db_uri: 'output/lancedb'
container_name: default
overwrite: true
llm:
api_key: ollama # 当前向量模型使用的是ollama部署的,ollama未启用api_key,方便认知是调用本地ollama运行的向量模型,该处填写ollama
type: openai_embedding # 模型延用openai的向量模型协议,该处不进行修改
model: nomic-embed-text # 本项目采用的向量模型名称是nomic-embed-text,该处修改为nomic-embed-text
api_base: http://localhost:11434/api # 本项目调用是本地部署的向量模型,该地址地址修改成本地部署推理的地址即可
# api_version: 2024-02-15-preview
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
修改后如下图所示。

修改好配置后按ctrl+o保存,保存后按ctrl+c退出即可。
5.在minzheng目录下创建input文件夹,用于构建知识的文本内容,本项目示例上传在民政部下载的“民政部2024年11月文告”,用于构建知识库内容。具体详见下图所示。

6.构建GraphRAG索引,在当前graphrag及上面安装的环境下执行构建索引命令,程序会根据上面配置文件自动调用本地ollama及本地vllm的向量模型及推理模型。
graphrag index –root ./minzheng –reporter rich
执行效果如下图所示。

我提供的数据量不大,执行整个过程10分钟以内完成。

上图是本地推理模型进行实体及关系的提取。
7.构建完成的GraphRAG的示例项目内容查询,例如:我查询“困境儿童”及“中国福利彩票”,看知识图谱如何准确的回答我。


剩下大家自己部署及测试吧!对了,如果你的服务器GPU资源不够,可以在配置文件中修改成你在网上申请DEEPSEEK的API地址及KEY即可,如下所示。
llm:
api_key: API_KEY # 直接填写申请的API_KEY,或者在.env里面修改也可以
type: openai_chat # 当前取本地私有化部署的DeepSeek 32B,DeepSeek延用openai协议
model: deepseek-chat # DEEPSEEK使用模型名称 deepseek-chat
model_supports_json: true # recommended if this is available for your model.
api_base: https://api.deepseek.com # Deepseek调用的地址,deepseek是延用openai地址协议,后面的v1/chat/completions默认自动补齐
# audience: "https://cognitiveservices.azure.com/.default"
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
8.使用APP构建GraphRAG对外的接口代码及示例。
8.1.对外接口路由代码
#===================================================================#
#===================================================================#
# GraphRAG对外接口应用V1.0-Allan.Fan 20250525
# 模型查询构建方法实现
#===================================================================#
#===================================================================#
import json
from datetime import datetime
from flask import Blueprint, request, g
from services.appquerymodeloutput_service import get_appquerymodeloutput
from flask_restx import Api,Namespace, Resource, reqparse
appquerymodeloutput_bp = Blueprint('querymodel_bp', __name__, url_prefix="/app/query/model")
api = Api(appquerymodeloutput_bp, doc='/doc', version='1.0', title='模型查询接口文档', description='关于企业模型文档说明')
# ————————————————————
# 创建默认命名空间
# ————————————————————
default_ns = Namespace(
name="",
path="",
description="模型查询接口文档"
)
api.add_namespace(default_ns)
# ———————————————-
# 参数解析器
# ———————————————-
parser = reqparse.RequestParser()
parser.add_argument('query', type=str, default='', required=True,
help='向企业模型提出问题', location='args')
@appquerymodeloutput_bp.before_request
def before_request():
g.client_ip = request.headers.get('X-Forwarded-For', request.remote_addr)
@default_ns.route('/output',methods=['GET'])
class AppQueryModelOutput(Resource):
@default_ns.expect(parser)
def get(self):
"""企业模型应用"""
args = parser.parse_args()
if args['query'] == None:
return {'code': 400, 'msg': '提出问题不能为空'}
query = args['query']
print (f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')} query: {query}")
if not query:
return {"success": False, "message": "提出问题不能为空!"}, 400
try:
istrue,querymodeloutput_data = get_appquerymodeloutput(query)
if istrue:
return {"success": istrue,"message": "模型请求处理成功","data": querymodeloutput_data}, 200
else:
return {"success": istrue, "message": f"模型请求处理失败!", "data": querymodeloutput_data}, 200
except Exception as e:
return {"success": False, "message": str(e)}, 500
8.2.GraphRAG获取查询问题后进行检索的业务代码。
#===================================================================#
#===================================================================#
# GraphRAG对外接口应用V1.0-Allan.Fan 20250525
# 模型查询相关API方法实现
#===================================================================#
#===================================================================#
import subprocess
def get_appquerymodeloutput(query):
result = []
taskoneoutput = {
"msg":None,
"count":0,
"data":[]
}
try:
command = ['graphrag','query','–root', '/home/allanfan/code/graphrag/minzheng','–method', 'global','–query', query]
result = subprocess.run(command, capture_output=True, text=True)
taskoneoutput["data"] = result.stdout
return True,taskoneoutput
except Exception as e:
return False,str(e)
备注:/home/allanfan/code/graphrag/minzheng这个地址是上面构建知识图谱内容的在服务器的绝对地址,请修改成自己的服务器构建的项目绝对地址即可,上面是我示例项目在服务器的绝对地址位置。
以上就是GraphRAG从环境部署,加载本地向量模型、本地推理模型、简单的知识图谱构建、简单的对外API接口开发;剩下最复杂的就是知识图谱的实体、关系如何根据业务构建,以及检索的数据召回率管理,检索数据速度及准确率的知识图谱构建,这个是除技术之外还要结合业务去整合发展。希望上面的GraphRAG能够在业务中帮助至大家;如果能够帮助到你一点,也希望你多支持支持我,给我多点击及收藏;也期望你的关注。









评论前必须登录!
注册