 网硕互联帮助中心
网硕互联帮助中心第四章:大模型(LLM)
第五部分:LLM实战: 实现GPT2
第六节:模型训练与微调

1. 前置回顾
在上一节中,我们已经完成了:
-
Token → Embedding
-
分词器(Tokenizer)
-
Attention 与 Multi-Head Attention
-
残差(Residual)与前馈网络(FFN)
-
输出层(logits 生成)
-
采样方法(贪婪、temperature、top-k/top-p)
现在,我们的 GPT-2 模型架构已经搭好,接下来要让它学会语言模式,必须通过 训练 或 微调(fine-tuning)。
2. 模型训练的目标
训练过程的核心思想:
让模型根据上下文预测下一个 token,并不断调整参数以降低预测错误率(loss)。
数学形式:
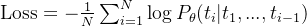
-
N — token 序列长度
-
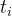 — 真实 token
— 真实 token -
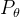 — 模型参数下的预测概率分布
— 模型参数下的预测概率分布
GPT-2 的训练实际上就是一个大规模 自回归语言建模 任务。
3. 数据准备
3.1 语料来源
-
预训练:使用大规模公开数据集(Wiki, WebText, Books)。
-
微调:使用领域数据(法律、医疗、金融、对话数据等)。
3.2 分词 & 编码
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
text = "今天是个好日子。"
tokens = tokenizer.encode(text, return_tensors='pt') # shape: (1, seq_len)
注意:
-
GPT-2 分词器是 BPE(Byte Pair Encoding),中英文都能处理。
-
返回是 token ID 张量,用于模型输入。
4. 训练流程
4.1 核心步骤
批量化数据(batching)
前向传播(forward pass)
计算损失(loss)
反向传播(backpropagation)
优化器更新参数(optimizer step)
重复多个 epoch
4.2 代码示例(PyTorch)
from torch.optim import AdamW
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 1. 加载模型与分词器
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.pad_token = tokenizer.eos_token
# 2. 数据
texts = ["今天是个好日子。", "机器学习正在改变世界。"]
encodings = tokenizer(texts, return_tensors='pt', padding=True, truncation=True)
# 3. 优化器
optimizer = AdamW(model.parameters(), lr=5e-5)
# 4. 训练循环
model.train()
for epoch in range(3):
optimizer.zero_grad()
outputs = model(**encodings, labels=encodings['input_ids'])
loss = outputs.loss
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1} Loss: {loss.item():.4f}")
运行结果
Epoch 1 Loss: 5.1916
Epoch 2 Loss: 3.5485
Epoch 3 Loss: 2.6843
5. 微调(Fine-tuning)
5.1 与预训练的区别
-
预训练:从零开始,参数随机初始化,需要巨量数据和算力。
-
微调:在已有的预训练模型上继续训练,数据规模小得多,但能快速适应特定任务/领域。
5.2 微调策略
-
全参数微调:更新所有权重(适合算力充足)
-
部分层微调:仅训练最后几层
-
参数高效微调(PEFT):如 LoRA、Prefix-Tuning,只更新少量参数
5.3 LoRA 示例
from peft import get_peft_model, LoraConfig
config = LoraConfig(
r=8, lora_alpha=32, target_modules=["c_attn"],
lora_dropout=0.1, bias="none", task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
6. 超参数选择
| batch_size | 每次梯度更新的样本数 | 8~64 |
| learning_rate | 学习率 | 5e-51e-4(微调),1e-45e-4(预训练) |
| max_seq_len | 序列最大长度 | 512~1024 |
| epochs | 训练轮数 | 3~10(视数据量) |
| warmup_steps | 学习率预热步数 | 总步数的 1~5% |
7. 训练技巧
-
梯度累积(gradient accumulation):显存不够时,将多个小 batch 的梯度累积起来再更新。
-
混合精度(FP16)训练:提升速度、降低显存。
-
梯度裁剪(clip gradients):避免梯度爆炸。
-
定期保存检查点(checkpoint):防止中途训练中断丢失进度。
8. 推理(Inference)
微调完成后,即可用模型生成文本:
model.eval()
prompt = "人工智能的未来是"
inputs = tokenizer(prompt, return_tensors='pt')
output_ids = model.generate(
**inputs,
max_length=50,
temperature=0.7,
top_k=50,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
9. 可视化 & 监控
-
loss 曲线:观察收敛情况
-
生成样例:每隔 N step 输出模型生成文本
-
权重变化:可用 TensorBoard 监控梯度分布
10. 本节总结
-
GPT-2 训练目标:最小化下一个 token 的负对数似然损失
-
微调是让通用语言模型快速适配特定任务的高效方式
-
训练过程需注意数据准备、超参数设置、优化策略
-
推理阶段可用采样策略(temperature、top-k、top-p)控制生成多样性









评论前必须登录!
注册