 网硕互联帮助中心
网硕互联帮助中心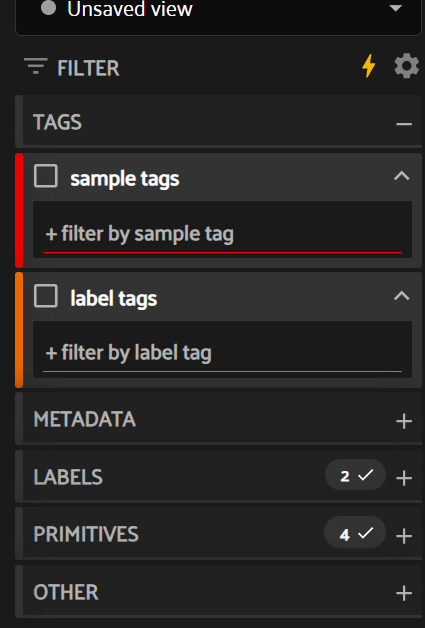
一、两个标签各是什么意思
-
sample tags(样本标签)
- 作用域:加在样本上(整张图片、整段视频)。
- 用途:划分训练/验证/测试、标记“已复核/问题样本/含遮挡”等整图级别属性。
- 存储位置:sample.tags 是一个字符串列表。
-
label tags(标注标签)
- 作用域:加在单个标注对象上(如每个检测框、每条分割、多段关键点,甚至视频的逐帧标注)。
- 用途:把某些标注打上“hard/occluded/ignore/误检/需修复”等标志,或给不同来源/阶段的标注打上来源标签。
- 存储位置:每个 Label 对象的 tags 列表(如 detections[i].tags)。
二、在 App 里怎么用
- 位置:左侧 Sidebar 的 TAGS 分组下有两块
- sample tags(红色边)用于按样本标签过滤
- label tags(橙色边)用于按标注标签过滤
- 基本操作
- 过滤
- 点击 “+ filter by sample tag” 或 “+ filter by label tag”,从下拉中选择已有标签或直接输入。
- 多选时可组合其他筛选器(如按类别、置信度、尺寸等)。
- label tags 过滤会把样本视图限制为“含有这些标签的标注”的样本;你也可以在 LABELS 面板里继续只显示被筛到的那些标注。
- 给选中对象打标签
- 在样本网格中框选/多选样本,顶部操作栏选择 “Tag samples” 输入或选择标签名称;“Remove sample tags” 可移除。
- 进入样本详情页,在标签列表面板(或用选择工具框住多个框)选择若干标注,点击 “Tag labels” / “Remove label tags”。
- 配合保存视图
- 当你用标签完成筛选后,可保存为 Saved View(右上角保存图标),以后一键复现。
三、在 Python 里怎么用(最常见而且不易出错的写法)
说明:以下都既可对 dataset 直接操作,也可对任意 view(子视图)操作;对 view 操作只影响该视图包含的样本或标注。
-
给样本打/去标签
- 给当前视图中的样本打标签
view.tag_samples(“val”) - 去掉标签
view.untag_samples(“val”) - 根据标签筛选样本
val_view = dataset.match_tags(“val”) # 含有“val”的样本
no_val_view = dataset.match_tags(“val”, bool=False) # 不含“val”的样本(老版本可用 ~ 前缀或用 exclude 选项;若报参错,改用 F() 过滤)
- 给当前视图中的样本打标签
-
给标注打/去标签(先把要操作的标注筛出来,再统一打标签,最稳妥)
-
例如给置信度低于 0.2 的预测框加标签 low_conf
import fiftyone as fo
from fiftyone import ViewField as Flow_conf = dataset.filter_labels(
“predictions”, F(“confidence”) < 0.2
)
low_conf.tag_labels(“low_conf”, label_fields=“predictions”) -
去掉某个标注标签
low_conf.untag_labels(“low_conf”, label_fields=“predictions”) -
只看带某个标注标签的标注(并把样本限制为“至少含一个这样的标注”的子集)
hard_view = dataset.filter_labels(
“predictions”, F(“tags”).contains(“low_conf”)
)
-
-
批量改名/迁移标签
-
把打错的样本标签 old 改为 new
v = dataset.match_tags(“old”)
v.tag_samples(“new”)
v.untag_samples(“old”) -
把类别为 “dog” 的预测框统一打上标签 dog_obj
dog_preds = dataset.filter_labels(“predictions”, F(“label”) == “dog”)
dog_preds.tag_labels(“dog_obj”, label_fields=“predictions”)
-
-
统计标签分布(便于清理和质检)
- 样本标签计数
counts = dataset.count_values(“tags”) # 返回 {tag: count} - 某个标注字段的标签计数(以检测为例)
counts = dataset.count_values(“predictions.detections.tags”)
- 样本标签计数
四、典型工作流示例
-
数据集切分
- 随机抽 20% 为验证集
val = dataset.take(int(0.2 * len(dataset)), seed=51)
val.tag_samples(“val”)
dataset.match_tags(“val”).export(…) # 导出验证集 - 训练时只加载非验证样本
train = dataset.match_tags(“val”, bool=False) -
评审与问题追踪
- 评审时把疑似问题样本打上 “needs_review”
session.view.tag_samples(“needs_review”) - 标注方只领取 “needs_review” 的样本进行修复
review_view = dataset.match_tags(“needs_review”) -
细粒度误差分析
- 给小目标或低置信度的框打上 “hard”
small = dataset.filter_labels(“predictions”, F(“bounding_box”)[2] * F(“bounding_box”)[3] < 0.01)
small.tag_labels(“hard”, label_fields=“predictions”) - 只看 hard 样本并叠加其它过滤器(类别、场景等)进行排查
hard_only = dataset.filter_labels(“predictions”, F(“tags”).contains(“hard”))
五、最佳实践与注意事项
- 命名规范:用简短小写、下划线或中划线,避免空格和易混义的名字,如 “val-2025-08”、“needs_review”。
- 标签是“附加信息”,不会改变原始类别或坐标;删除标签不会删掉样本/标注。
- 先用视图筛到“需要被打标签的一批对象”,再调用 tag_* 是批量标注的最高效做法。
- label tags 默认是“每个标注对象自己的列表”,同一张图里不同标注可拥有不同标签;sample tags 是“整图共享”。
- 视频同理:样本标签作用于整段视频;逐帧/时序标注对象也有各自的 label tags。
- 与保存视图配合:把常用的标签过滤保存为 Saved View,团队共享、复现分析更方便。
- 如果在老版本中某些 API 名字稍有差异,可用 ViewField F(“tags”).contains(“xxx”) 这类通用表达式组合 filter_labels 保底实现所有过滤需求。







评论前必须登录!
注册