 网硕互联帮助中心
网硕互联帮助中心1、简介
最近进行了使用各种元启发式算法进行多机器人路径规划的研究。其中一种算法正弦余弦算法(SCA)不能在路径规划问题中产生令人满意的结果,由于单一的更新策略。有必要采用多种更新策略,并针对更广泛的问题提高其性能。我们提出了一种新的多策略自适应微分正弦余弦算法(sdSCA),它使用策略池,并允许更频繁地选择策略,从而导致更好的解决方案,将sdSCA应用于具有静态和动态障碍物的复杂环境中的在线多机器人路径规划。
2、基本正弦余弦算法(SCA)
SCA是Mirjalili于2016年提出的基于数学的先进元启发式算法。该算法在更新解时采用正弦和余弦函数构建的方程,这些三角函数能有效利用两个不同解之间的空间(Mirjalili, 2016)。算法流程如下:首先通过式(1)随机生成初始种群:
Xi=Xmin+(Xmax−Xmin) rand(1,D),i∈{1,2,…,PS}(1)X_i = X_{min} + (X_{max} – X_{min}) \\; rand(1, D), \\quad i \\in \\{1, 2, \\ldots, PS\\} \\tag{1}Xi=Xmin+(Xmax−Xmin)rand(1,D),i∈{1,2,…,PS}(1)
其中XiX_iXi表示候选解iii,XminX_{min}Xmin和XmaxX_{max}Xmax分别表示解的上下界,DDD和PSPSPS分别代表问题维度和种群规模。种群经适应度函数评估后开始迭代过程,解通过式(2)更新:
Xit+1={Xit+r1 sin(r2) ∣r3 Xbestt−Xit∣如果 r4<0.5Xit+r1 cos(r2) ∣r3 Xbestt−Xit∣否则(2)X^{t+1}_i =
\\begin{cases}
X^t_i + r_1 \\; \\sin(r_2) \\; |r_3 \\; X^t_{best} – X^t_i| & \\text{如果 } r_4 < 0.5 \\\\
X^t_i + r_1 \\; \\cos(r_2) \\; |r_3 \\; X^t_{best} – X^t_i| & \\text{否则}
\\end{cases} \\tag{2}Xit+1={Xit+r1sin(r2)∣r3Xbestt−Xit∣Xit+r1cos(r2)∣r3Xbestt−Xit∣如果 r4<0.5否则(2)
式中Xit+1X^{t+1}_iXit+1表示第t+1t+1t+1代候选解iii,XitX^t_iXit为第ttt代候选解iii,XbesttX^t_{best}Xbestt是第ttt代种群中的最优解。r1r_1r1通过式(3)计算:
r1=a−taT(3)r_1 = a – t \\frac{a}{T} \\tag{3}r1=a−tTa(3)
其中ttt为当前迭代次数,TTT为最大迭代次数,aaa为常数。r2r_2r2、r3r_3r3和r4r_4r4分别为[0,2π]、[0,2]和[0,1]范围内的随机数。新种群经适应度函数评估后继续迭代直至满足停止条件,最终输出最优解。最小化问题的SCA伪代码见算法1。
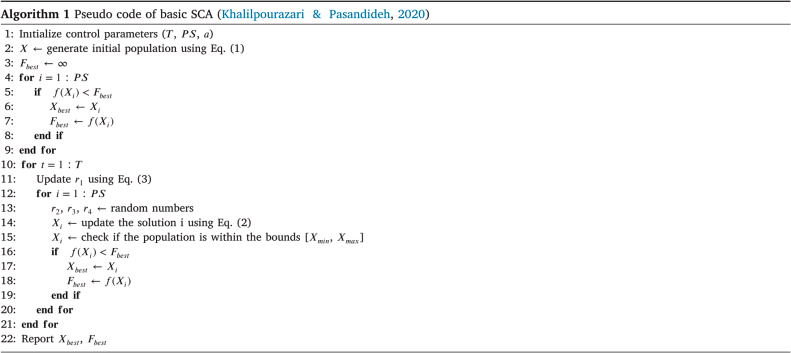
3、多策略自适应差分正弦余弦算法(sdSCA)
基于种群的元启发式算法首先生成随机初始种群,经适应度函数评估后开始迭代更新过程。多数算法中,种群候选解通常采用单一更新策略,迭代结束时输出最优解。然而单一更新策略会限制算法搜索性能。SCA作为基于种群的算法,其原始更新策略如式(2)所示。为突破这一限制,本文在SCA原有策略基础上引入差分策略,提出新型多策略自适应差分正弦余弦算法(sdSCA)。该算法中,每个候选解通过轮盘赌概率计算自主选择更新策略(非随机选择),算法自适应学习产生更优结果的策略,从而提升基础SCA的搜索性能。所提算法在基础SCA更新方程外新增三种差分策略,分别如式(4)、式(5)和式(6)所示:
Xit+1={XR1t+F(XR2t−XR3t)若rand<CRXit否则(4)X_{i}^{t+1}=\\begin{cases}
X_{R_{1}}^{t}+F\\left(X_{R_{2}}^{t}-X_{R_{3}}^{t}\\right) & \\text{若}rand<CR\\\\
X_{i}^{t} & \\text{否则}
\\end{cases} \\tag{4}Xit+1={XR1t+F(XR2t−XR3t)Xit若rand<CR否则(4)
Xit+1={Xit+F(Xbestt−Xit+XR1t−XR2t)若rand<CRXit否则(5)X_{i}^{t+1}=\\begin{cases}
X_{i}^{t}+F\\left(X_{best}^{t}-X_{i}^{t}+X_{R_{1}}^{t}-X_{R_{2}}^{t}\\right) & \\text{若}rand<CR\\\\
X_{i}^{t} & \\text{否则}
\\end{cases} \\tag{5}Xit+1={Xit+F(Xbestt−Xit+XR1t−XR2t)Xit若rand<CR否则(5)
Xit+1=Xit+L(XR1t−Xit)+F(XR2t−XR3t)(6)X_{i}^{t+1}=X_{i}^{t}+L\\left(X_{R_{1}}^{t}-X_{i}^{t}\\right)+F\\left(X_{R_{2}}^{t}-X_{R_{3}}^{t}\\right) \\tag{6}Xit+1=Xit+L(XR1t−Xit)+F(XR2t−XR3t)(6)
其中XR1tX_{R_{1}}^{t}XR1t、XR2tX_{R_{2}}^{t}XR2t和XR3tX_{R_{3}}^{t}XR3t为第ttt代随机选取的三个候选解,FFF为缩放因子,LLL为[0,1]范围内的随机数,CRCRCR为交叉率。
算法流程说明:首先由式(2)、(4)-(6)构建包含四种差分策略的策略池,初始阶段各策略选择概率均设为25%。通过式(1)随机生成初始种群后,各候选解采用轮盘赌技术选择策略。经适应度函数评估后开始迭代,候选解按各自策略更新,同时更新策略选择计数器。新种群评估后,按式(7)计算各策略更新概率:
pkt+1=ckt∑i=1NSci,k∈{1,2,…,NS}(7)p_{k}^{t+1}=\\frac{c_{k}^{t}}{\\sum_{i=1}^{NS}c_{i}}, \\quad k\\in\\{1,2,\\ldots,NS\\} \\tag{7}pkt+1=∑i=1NScickt,k∈{1,2,…,NS}(7)
式中pkt+1p_{k}^{t+1}pkt+1表示第t+1t+1t+1代策略kkk的选择概率,cktc_{k}^{t}ckt为第ttt代策略kkk的计数器,NSNSNS为策略总数。基于更新概率,候选解再次通过轮盘赌调整策略选择,直至满足停止条件。最小化问题的sdSCA流程图见算法2和图2。

4、多机器人在线路径规划建模
多机器人在线路径规划是一个最小化问题,旨在使机器人在复杂环境中逐步到达目标点,同时以最小成本避免与静态/动态障碍物及其他机器人碰撞(Toufan & Nitzade, 2020)。本文针对圆形同构多机器人系统进行在线路径规划仿真,机器人下一位置可通过式(8)-(9)计算:
xin=xic+vicos(θi)(8)x_{i}^{n} = x_{i}^{c}+v_{i}\\cos\\left(\\theta_{i}\\right) \\tag{8}xin=xic+vicos(θi)(8)
yin=yic+visin(θi)(9)y_{i}^{n} = y_{i}^{c}+v_{i}\\sin\\left(\\theta_{i}\\right) \\tag{9}yin=yic+visin(θi)(9)
其中(xin,yin)(x_{i}^{n},y_{i}^{n})(xin,yin)表示机器人iii的下一位置坐标,(xic,yic)(x_{i}^{c},y_{i}^{c})(xic,yic)为当前位置坐标,viv_{i}vi和θi\\theta_{i}θi分别为机器人iii的速度和角度。速度定义为单步移动距离,通过每步优化确定机器人下一位置,该优化基于所有机器人的速度和角度参数。首先在速度范围[vmin,vmax][v_{min},v_{max}][vmin,vmax]和角度范围[θmin,θmax][\\theta_{min},\\theta_{max}][θmin,θmax]内创建局部搜索空间,然后确定该空间中最可行下一位置的速度和角度。机器人持续移动至目标点,所有机器人的速度和角度作为整体进行优化。由于优化基于这两个运动特性,问题维度DDD与机器人数量NRN^{R}NR成正比,即D=NR×2D=N^{R}\\times2D=NR×2。主适应度函数如式(10)所示:
KaTeX parse error: Invalid delimiter type 'ordgroup' at position 61: …_{i}\\right)\\big{̲|̲}̲i\\in \\left\\{1,\\…
主适应度函数评估以下四个准则:
- F1F_1F1: 最短路径;F2F_2F2: 避让静态障碍物;F3F_3F3: 避让动态障碍物 ; F4F_4F4: 避让其他机器人
各子函数数学表达如下:
4.1 最短路径函数
F1=∑i=1NR(fi+gi)(11)F_{1}=\\sum_{i=1}^{N^{R}}\\left(f_{i}+g_{i}\\right) \\tag{11}F1=i=1∑NR(fi+gi)(11)
其中:
fi=(xin−xic)2+(yin−yic)2(12)f_{i} =\\sqrt{\\left(x_{i}^{n}-x_{i}^{c}\\right)^{2}+\\left(y_{i}^{n}-y_{i}^{c}\\right)^{2}} \\tag{12}fi=(xin−xic)2+(yin−yic)2(12)
gi=(xig−xin)2+(yig−yin)2(13)g_{i} =\\sqrt{\\left(x_{i}^{g}-x_{i}^{n}\\right)^{2}+\\left(y_{i}^{g}-y_{i}^{n}\\right)^{2}} \\tag{13}gi=(xig−xin)2+(yig−yin)2(13)
(xig,yig)(x_{i}^{g},y_{i}^{g})(xig,yig)为机器人iii的目标坐标。
4.2 静态避障函数
F2={c若 dis≤disafe0若 dis>disafe(14)F_{2}=\\begin{cases}c & \\text{若 }d_{i}^{s}\\leq d_{i}^{safe}\\\\0 & \\text{若 }d_{i}^{s}>d_{i}^{safe}\\end{cases} \\tag{14}F2={c0若 dis≤disafe若 dis>disafe(14)
其中c∈R+c\\in\\mathbb{R}^{+}c∈R+为大数惩罚项,disd_{i}^{s}dis为机器人iii到所有静态障碍物的距离和:
dis=∑j=1Ns(xin−xjs)2+(yin−yjs)2(15)d_{i}^{s}=\\sum_{j=1}^{N^{s}}\\sqrt{\\left(x_{i}^{n}-x_{j}^{s}\\right)^{2}+\\left(y_{i}^{n}-y_{j}^{s}\\right)^{2}} \\tag{15}dis=j=1∑Ns(xin−xjs)2+(yin−yjs)2(15)
NsN^{s}Ns为静态障碍物数量,(xjs,yjs)(x_{j}^{s},y_{j}^{s})(xjs,yjs)为静态障碍物jjj的坐标。
4.3 动态避障函数\\
F3={c若 did≤disafe0若 did>disafe(16)F_{3}=\\begin{cases}c & \\text{若 }d_{i}^{d}\\leq d_{i}^{safe}\\\\0 & \\text{若 }d_{i}^{d}>d_{i}^{safe}\\end{cases} \\tag{16}F3={c0若 did≤disafe若 did>disafe(16)
动态障碍物距离和:
did=∑j=1Nd(xin−xjd)2+(yin−yjd)2(17)d_{i}^{d}=\\sum_{j=1}^{N^{d}}\\sqrt{\\left(x_{i}^{n}-x_{j}^{d}\\right)^{2}+\\left(y_{i}^{n}-y_{j}^{d}\\right)^{2}} \\tag{17}did=j=1∑Nd(xin−xjd)2+(yin−yjd)2(17)
4.4 机器人避碰函数
F4={c若 dir≤disafe0若 dir>disafe(18)F_{4}=\\begin{cases}c & \\text{若 }d_{i}^{r}\\leq d_{i}^{safe}\\\\0 & \\text{若 }d_{i}^{r}>d_{i}^{safe}\\end{cases} \\tag{18}F4={c0若 dir≤disafe若 dir>disafe(18)
机器人间距离和:
dir=∑j=1,j≠iNR(xin−xjc)2+(yin−yjc)2(19)d_{i}^{r}=\\sum_{j=1,j\\neq i}^{N^{R}}\\sqrt{\\left(x_{i}^{n}-x_{j}^{c}\\right)^{2}+\\left(y_{i}^{n}-y_{j}^{c}\\right)^{2}} \\tag{19}dir=j=1,j=i∑NR(xin−xjc)2+(yin−yjc)2(19)
总适应度函数为各子函数之和:
Fit=F1+F2+F3+F4(20)Fit=F_{1}+F_{2}+F_{3}+F_{4} \\tag{20}Fit=F1+F2+F3+F4(20)
动态障碍物运动模型由式(21)-(22)描述:
xjd=xjd+vjdcos(αj)(21)x_{j}^{d} =x_{j}^{d}+v_{j}^{d}\\cos\\left(\\alpha_{j}\\right) \\tag{21}xjd=xjd+vjdcos(αj)(21)
yjd=yjd+vjdsin(αj)(22)y_{j}^{d} =y_{j}^{d}+v_{j}^{d}\\sin\\left(\\alpha_{j}\\right) \\tag{22}yjd=yjd+vjdsin(αj)(22)
其中vjdv_{j}^{d}vjd为动态障碍物jjj的速度,αj\\alpha_{j}αj为其相对于目标点的角度。路径规划算法伪代码见算法3。

5、算法性能评估指标
本文通过步数、移动距离、路径偏差误差、未达目标距离、总适应度和执行时间等指标评估算法性能。下面对路径偏差误差和未达目标距离进行详细说明。
5.1 平均路径偏差误差(APDE)
在迭代开始前,路径规划算法会为每个机器人计算数学上的理想路径(起点到目标的直线)。路径偏差误差(PDE)指算法实际路径与理想路径的距离差,第kkk次运行的PDE计算如式(23):
PDEk=∑i=1NR(TDik−IDi)(23)PDE_{k}=\\sum_{i=1}^{N^{R}}\\left(TD_{i}^{k}-ID_{i}\\right) \\tag{23}PDEk=i=1∑NR(TDik−IDi)(23)
其中TDikTD_{i}^{k}TDik表示第kkk次运行时机器人iii的实际移动距离,IDiID_{i}IDi为机器人iii的理想路径距离。平均路径偏差误差(APDE)计算如式(24),RRR为总运行次数:
APDE=1R∑k=1RPDEk(24)APDE=\\frac{1}{R}\\sum_{k=1}^{R}PDE_{k} \\tag{24}APDE=R1k=1∑RPDEk(24)
5.2 平均未达目标距离(AUGD)
当步数最多的机器人到达目标点时算法终止运行。在此过程中记录每个机器人每步到目标点的距离,欧氏距离计算如式(25):
Hij,k=∥Pij,k−Gi∥(25)H_{i}^{j,k}=\\left\\|P_{i}^{j,k}-G_{i}\\right\\| \\tag{25}Hij,k=Pij,k−Gi(25)
其中Hij,kH_{i}^{j,k}Hij,k表示第kkk次运行第jjj步时机器人iii到目标的距离,Pij,kP_{i}^{j,k}Pij,k为优化得到的新位置,GiG_{i}Gi为目标点坐标。第kkk次运行的未达目标距离(UGDk)(UGD_{k})(UGDk)计算如式(26):
UGDk=∑j=1MS∑i=1NRHij,k(26)UGD_{k}=\\sum_{j=1}^{MS}\\sum_{i=1}^{N^{R}}H_{i}^{j,k} \\tag{26}UGDk=j=1∑MSi=1∑NRHij,k(26)
MSMSMS为最大步数机器人的总步数。平均未达目标距离(AUGD)计算如式(27):
AUGD=1R∑k=1RUGDk(27)AUGD=\\frac{1}{R}\\sum_{k=1}^{R}UGD_{k} \\tag{27}AUGD=R1k=1∑RUGDk(27)
6、多机器人路径规划求解算法
提出的算法被应用于多机器人在线路径规划。仿真中机器人均为圆形、同构且尺寸统一,动态障碍物以恒定速度在两特定点间线性移动。研究构建了三个包含静态和动态障碍物的场景(单位:厘米):
场景1:100×100100\\times100100×100 cm区域,部署6个机器人(R1-R6)、7个不同半径的静态障碍物和3个同构动态障碍物(D1-D3)。静态障碍物为灰色圆形,动态障碍物为黑色圆形(D1-D3),其移动速度分别为0.5 cm/步(D1)、0.45 cm/步(D2)和1.2 cm/步(D3)。机器人理想路径用彩色虚线表示,目标点用对应颜色的十字标记;动态障碍物路径用黑色点划线表示,目标点用黑色方框标记(如图5所示)。
场景2:100×100100\\times100100×100 cm区域,部署7个机器人(R1-R7)、7个静态障碍物(2圆形+2三角形+3方形)和3个动态障碍物(1圆形+1三角形+1方形)。动态障碍物速度分别为0.5 cm/步(D1)、0.1 cm/步(D2)和1.1 cm/步(D3)。静态障碍物为灰色几何体,动态障碍物为黑色几何体(如图6所示)。
场景3:200×200200\\times200200×200 cm区域,部署12个机器人(R1-R12)、14个圆形静态障碍物和6个圆形动态障碍物(D1-D6)。动态障碍物速度分别为0.5(D1)、0.5(D2)、0.6(D3)、0.3(D4)、0.4(D5)和0.25 cm/步(D6)(如图7所示)。
参数设置:
- 机器人半径:111 cm
- 动态障碍物半径:1.51.51.5 cm
- 优化参数范围:
速度 v∈[1,1.5]v\\in[1,1.5]v∈[1,1.5] cm/步
角度 θ∈[0,2π]\\theta\\in[0,2\\pi]θ∈[0,2π] rad - 适应度函数F2F_2F2、F3F_3F3和F4F_4F4的惩罚系数:c=105c=10^5c=105
动态障碍物的速度设计旨在限制机器人运动并增加问题复杂度。各场景中机器人理想路径用彩色虚线表示,目标点用同色十字标记;动态障碍物路径用黑色点划线表示,目标点用黑色方框标记。
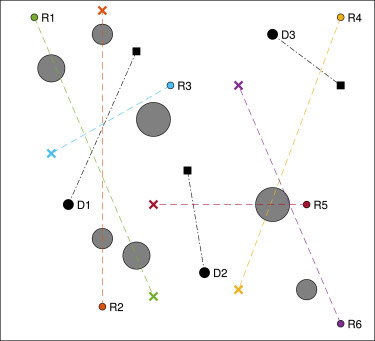
图1 场景1
% data of scenario 1
% ===================================================================
totalRobot = 6; % number of robot
robotRadius = ones(1, totalRobot); % radius of robot
robotStart.x = [5 25 45 95 85 95]; % start positions (x) of robots
robotStart.y = [95 10 75 95 40 5]; % start positions (y) of robots
robotGoal.x = [40 25 10 65 40 65]; % goal positions (x) of robots
robotGoal.y = [13 97 55 15 40 75]; % goal positions (y) of robots
totalStatic = 7; % number of static obstacles
staticRadius = [4 3 3 5 4 5 3]; % radius of static obstacles
static.x = [10 25 25 40 35 75 85]; % positions (x) of static obstacles
static.y = [80 90 30 65 25 40 15]; % positions (y) of static obstacles
totalDynamic = 3; % number of dynamic obstacles
dynamicRadius = 1.5 * ones(1, totalDynamic); % radius of dynamic obstacles
dynamicStart.x = [15 55 75]; % start positions (x) of dynamic obstacles
dynamicStart.y = [40 20 90]; % start positions (y) of dynamic obstacles
dynamicGoal.x = [35 50 95]; % goal positions (x) of dynamic obstacles
dynamicGoal.y = [85 50 75]; % goal positions (y) of dynamic obstacles
dynamicVelocity = [0.5 0.45 1.2]; % velocities of dynamic obstacles
axisParameter = 100; % visualization scale (100 x 100)
% ===================================================================
% initial visualization
% ===================================================================
figure
alpha = linspace(0, 2*pi, 100);
set(gcf, 'Position', [500, 20, 950, 950]);
ax = gca;
ax.Units = 'normalized';
ax.Position = [0.05 0 0.9 1];
plt1 = plot(–7,–7,'o','MarkerFaceColor',[0.5 0.5 0.5],'MarkerEdgeColor','k','MarkerSize',12);
hold on;
plt2 = plot(–8,–8,'o','MarkerFaceColor',[0.5 0.7 0.8],'MarkerEdgeColor','k','MarkerSize',12);
plt3 = plot(–9,–9,'o','MarkerFaceColor',[0.1 0.2 0.9],'MarkerEdgeColor','k','MarkerSize',12);
for i = 1 : totalStatic
if i == 2 || i == 4
x_square = [static.x(i) – staticRadius(i), static.x(i) + staticRadius(i), static.x(i) + staticRadius(i), static.x(i) – staticRadius(i)];
y_square = [static.y(i) – staticRadius(i), static.y(i) – staticRadius(i), static.y(i) + staticRadius(i), static.y(i) + staticRadius(i)];
plt10 = fill(x_square, y_square, [0.5 0.5 0.5]);
elseif i == 3 || i == 5
x_tri = [static.x(i), static.x(i) – staticRadius(i) * sqrt(3) / 2, static.x(i) + staticRadius(i) * sqrt(3) / 2, static.x(i)];
y_tri = [static.y(i) + staticRadius(i), static.y(i) – staticRadius(i) / 2, static.y(i) – staticRadius(i) / 2, static.y(i) + staticRadius(i)];
plt10 = fill(x_tri, y_tri, [0.5 0.5 0.5]);
else
plt10 = fill(static.x(i) + staticRadius(i) * cos(alpha), static.y(i) + staticRadius(i) * sin(alpha), [0.5 0.5 0.5]);
end
end
for i = 1 : totalRobot
plt11(i) = fill(robotStart.x(i) + robotRadius(i) * cos(alpha), robotStart.y(i) + robotRadius(i) * sin(alpha), [0.5 0.7 0.8]);
plt4 = plot(robotGoal.x(i), robotGoal.y(i),'x','MarkerFaceColor','k','MarkerEdgeColor','k','MarkerSize',10,'LineWidth',2);
plt5 = line([robotStart.x(i) robotGoal.x(i)], [robotStart.y(i) robotGoal.y(i)],'Color','black','LineStyle','–');
end
for i = 1 : totalDynamic
plt12(i) = fill(dynamicStart.x(i) + dynamicRadius(i) * cos(alpha), dynamicStart.y(i) + dynamicRadius(i) * sin(alpha), [0.1 0.2 0.9]);
plt6 = plot(dynamicGoal.x(i), dynamicGoal.y(i),'x','MarkerFaceColor','b','MarkerEdgeColor','b','MarkerSize',10,'LineWidth',2);
plt7 = line([dynamicStart.x(i) dynamicGoal.x(i)], [dynamicStart.y(i) dynamicGoal.y(i)],'Color','blue','LineStyle','–');
end
legend([plt2 plt1 plt3], {'(6) Robots','(7) Static obstacles', '(3) Dynamic obstacles'},'FontSize',14,'Location','north');
axis equal;
axis([–5 (axisParameter+5) 0 (axisParameter)]);
pause(1);
% ===================================================================
saveas(gcf,'scenario\\scenario1.emf');
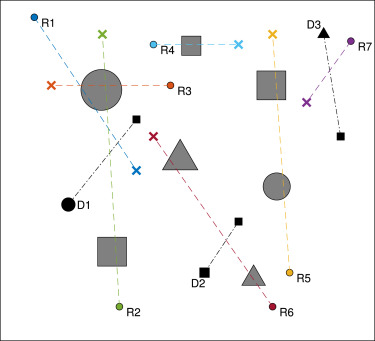
图2 场景2
% data of scenario 2
% ===================================================================
totalRobot = 12; % number of robot
robotRadius = ones(1, totalRobot); % radius of robot
robotStart.x = [8 13 29 34 39 50 60 60 60 66 97 97]; % start positions (x) of robots
robotStart.y = [31 11 78 31 89 63 31 84 94 63 42 86]; % start positions (y) of robots
robotGoal.x = [18 13 29 18 39 76 102 81 87 34 97 97]; % goal positions (x) of robots
robotGoal.y = [47 90 16 31 47 26 58 94 73 5 79 94]; % goal positions (y) of robots
totalStatic = 9; % number of static obstacles
staticRadius = [2 2 1 3 2 2 3 2 4]; % radius of static obstacles
static.x = [13 25 34 29 29 58 85 68 13]; % positions (x) of static obstacles
static.y = [40 31 31 45 65 50 47 88 70]; % positions (y) of static obstacles
totalDynamic = 5; % number of dynamic obstacles
dynamicRadius = 1.5 * ones(1, totalDynamic); % radius of dynamic obstacles
dynamicStart.x = [40 24 34 66 92]; % start positions (x) of dynamic obstacles
dynamicStart.y = [40 47 84 26 63]; % start positions (y) of dynamic obstacles
dynamicGoal.x = [60 34 45 76 100]; % goal positions (x) of dynamic obstacles
dynamicGoal.y = [15 68 63 52 65]; % goal positions (y) of dynamic obstacles
dynamicVelocity = rand(1,totalDynamic) + 0.2; % velocities of dynamic obstacles
axisParameter = 100; % visualization scale (100 x 100)
% ===================================================================
% initial visualization
% ===================================================================
figure
alpha = linspace(0, 2*pi, 100);
set(gcf, 'Position', [500, 20, 950, 950]);
ax = gca;
ax.Units = 'normalized';
ax.Position = [0.05 0 0.9 1];
plt1 = plot(–7,–7,'o','MarkerFaceColor',[0.5 0.5 0.5],'MarkerEdgeColor','k','MarkerSize',12);
hold on;
plt2 = plot(–8,–8,'o','MarkerFaceColor',[0.5 0.7 0.8],'MarkerEdgeColor','k','MarkerSize',12);
plt3 = plot(–9,–9,'o','MarkerFaceColor',[0.1 0.2 0.9],'MarkerEdgeColor','k','MarkerSize',12);
for i = 1 : totalStatic
if i == 2 || i == 5 || i == 7
x_square = [static.x(i) – staticRadius(i), static.x(i) + staticRadius(i), static.x(i) + staticRadius(i), static.x(i) – staticRadius(i)];
y_square = [static.y(i) – staticRadius(i), static.y(i) – staticRadius(i), static.y(i) + staticRadius(i), static.y(i) + staticRadius(i)];
plt10 = fill(x_square, y_square, [0.5 0.5 0.5]);
elseif i == 3 || i == 5 || i == 8
x_tri = [static.x(i), static.x(i) – staticRadius(i) * sqrt(3) / 2, static.x(i) + staticRadius(i) * sqrt(3) / 2, static.x(i)];
y_tri = [static.y(i) + staticRadius(i), static.y(i) – staticRadius(i) / 2, static.y(i) – staticRadius(i) / 2, static.y(i) + staticRadius(i)];
plt10 = fill(x_tri, y_tri, [0.5 0.5 0.5]);
else
plt10 = fill(static.x(i) + staticRadius(i) * cos(alpha), static.y(i) + staticRadius(i) * sin(alpha), [0.5 0.5 0.5]);
end
end
for i = 1 : totalRobot
plt11(i) = fill(robotStart.x(i) + robotRadius(i) * cos(alpha), robotStart.y(i) + robotRadius(i) * sin(alpha), [0.5 0.7 0.8]);
plt4 = plot(robotGoal.x(i), robotGoal.y(i),'x','MarkerFaceColor','k','MarkerEdgeColor','k','MarkerSize',10,'LineWidth',2);
plt5 = line([robotStart.x(i) robotGoal.x(i)], [robotStart.y(i) robotGoal.y(i)],'Color','black','LineStyle','–');
end
for i = 1 : totalDynamic
plt12(i) = fill(dynamicStart.x(i) + dynamicRadius(i) * cos(alpha), dynamicStart.y(i) + dynamicRadius(i) * sin(alpha), [0.1 0.2 0.9]);
plt6 = plot(dynamicGoal.x(i), dynamicGoal.y(i),'x','MarkerFaceColor','b','MarkerEdgeColor','b','MarkerSize',10,'LineWidth',2);
plt7 = line([dynamicStart.x(i) dynamicGoal.x(i)], [dynamicStart.y(i) dynamicGoal.y(i)],'Color','blue','LineStyle','–');
end
legend([plt2 plt1 plt3], {'(12) Robots', '(9) Static obstacles', '(5) Dynamic obstacles'},'FontSize',14,'Location','southeast');
axis equal;
axis([–5 (axisParameter+5) 0 (axisParameter)]);
pause(1);
% ===================================================================
saveas(gcf,'scenario\\scenario2.emf');
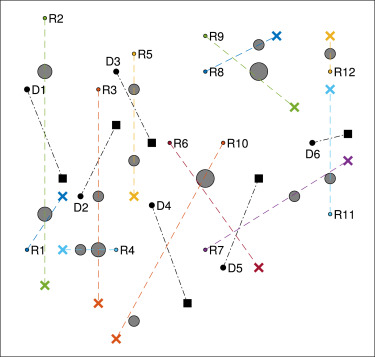
图3 场景3
% data of scenario 3
% ===================================================================
totalRobot = 20; % number of robot
robotRadius = ones(1, totalRobot); % radius of robot
robotStart.x = [5 5 25 25 10 85 40 60 45 72 60 105 145 145 145 100 100 50 100 120] ; % start positions (x) of robots
robotStart.y = [135 100 5 100 5 85 40 80 45 72 60 130 145 110 80 20 125 15 100 25]; % start positions (y) of robots
robotGoal.x = [25 25 5 75 15 40 70 80 5 120 90 120 145 145 145 125 125 75 130 140]; % goal positions (x) of robots
robotGoal.y = [135 125 25 125 85 125 140 80 70 72 30 110 120 90 30 60 125 15 80 25]; % goal positions (y) of robots
totalStatic = 13; % number of static obstacles
staticRadius = [5 3 5 4 3 3 3 3 4 4 5 5 3]; % radius of static obstacles
static.x = [12 100 43 55 30 110 50 145 145 145 145 115 107]; % positions (x) of static obstacles
static.y = [45 72 60 90 55 120 70 50 65 100 130 90 32]; % positions (y) of static obstacles
totalDynamic = 7; % number of dynamic obstacles
dynamicRadius = 1.5 * ones(1, totalDynamic); % radius of dynamic obstacles
dynamicStart.x = [15 50 30 60 17 100 75]; % start positions (x) of dynamic obstacles
dynamicStart.y = [145 140 80 30 5 60 55] ; % start positions (y) of dynamic obstacles
dynamicGoal.x = [15 70 60 63 25 135 60]; % goal positions (x) of dynamic obstacles
dynamicGoal.y = [100 70 75 5 15 40 40]; % goal positions (y) of dynamic obstacles
dynamicVelocity = rand(1,totalDynamic) + 0.2; % velocities of dynamic obstacles
axisParameter = 150; % visualization scale (150 x 150)
% ===================================================================
% Robots path's colors
% ===================================================================
Colors = jet(totalRobot);
% Colors = (Colors+[1 1 1])./2;
% ===================================================================
% initial visualization
% ===================================================================
figure
alpha = linspace(0, 2*pi, 150);
set(gcf, 'Position', [500, 20, 950, 950]);
ax = gca;
ax.Units = 'normalized';
ax.Position = [0.05 0 0.9 1];
plt1 = plot(–7,–7,'o','MarkerFaceColor',[0.5 0.5 0.5],'MarkerEdgeColor','k','MarkerSize',12);
hold on;
plt2 = plot(–8,–8,'o','MarkerFaceColor',[0.5 0.7 0.8],'MarkerEdgeColor','k','MarkerSize',12);
plt3 = plot(–9,–9,'o','MarkerFaceColor',[0.1 0.2 0.9],'MarkerEdgeColor','k','MarkerSize',12);
for i = 1 : totalStatic
if i == 2 || i == 7 || i == 10 || i == 13 || i == 17
x_square = [static.x(i) – staticRadius(i), static.x(i) + staticRadius(i), static.x(i) + staticRadius(i), static.x(i) – staticRadius(i)];
y_square = [static.y(i) – staticRadius(i), static.y(i) – staticRadius(i), static.y(i) + staticRadius(i), static.y(i) + staticRadius(i)];
plt10 = fill(x_square, y_square, [0.5 0.5 0.5]);
elseif i == 3 || i == 8 || i == 11 || i == 14 || i == 18
x_tri = [static.x(i), static.x(i) – staticRadius(i) * sqrt(3) / 2, static.x(i) + staticRadius(i) * sqrt(3) / 2, static.x(i)];
y_tri = [static.y(i) + staticRadius(i), static.y(i) – staticRadius(i) / 2, static.y(i) – staticRadius(i) / 2, static.y(i) + staticRadius(i)];
plt10 = fill(x_tri, y_tri, [0.5 0.5 0.5]);
else
plt10 = fill(static.x(i) + staticRadius(i) * cos(alpha), static.y(i) + staticRadius(i) * sin(alpha), [0.5 0.5 0.5]);
end
end
for i = 1 : totalRobot
plt11(i) = fill(robotStart.x(i) + robotRadius(i) * cos(alpha), robotStart.y(i) + robotRadius(i) * sin(alpha), [0.5 0.7 0.8]);
plt4 = plot(robotGoal.x(i), robotGoal.y(i),'x','MarkerFaceColor','k','MarkerEdgeColor','k','MarkerSize',10,'LineWidth',2);
plt5 = line([robotStart.x(i) robotGoal.x(i)], [robotStart.y(i) robotGoal.y(i)],'Color','black','LineStyle','–');
end
for i = 1 : totalDynamic
plt12(i) = fill(dynamicStart.x(i) + dynamicRadius(i) * cos(alpha), dynamicStart.y(i) + dynamicRadius(i) * sin(alpha), [0.1 0.2 0.9]);
plt6 = plot(dynamicGoal.x(i), dynamicGoal.y(i),'x','MarkerFaceColor','b','MarkerEdgeColor','b','MarkerSize',10,'LineWidth',2);
plt7 = line([dynamicStart.x(i) dynamicGoal.x(i)], [dynamicStart.y(i) dynamicGoal.y(i)],'Color','blue','LineStyle','–');
end
legend([plt2 plt1 plt3], {'(20) Robots', '(13) Static obstacles', '(7) Dynamic obstacles'},'FontSize',14,'Location','southeast');
axis equal;
axis([–5 (axisParameter+5) 0 (axisParameter)]);
pause(1);
% ===================================================================
saveas(gcf,'scenario\\scenario3.emf');
6.1 实验结果
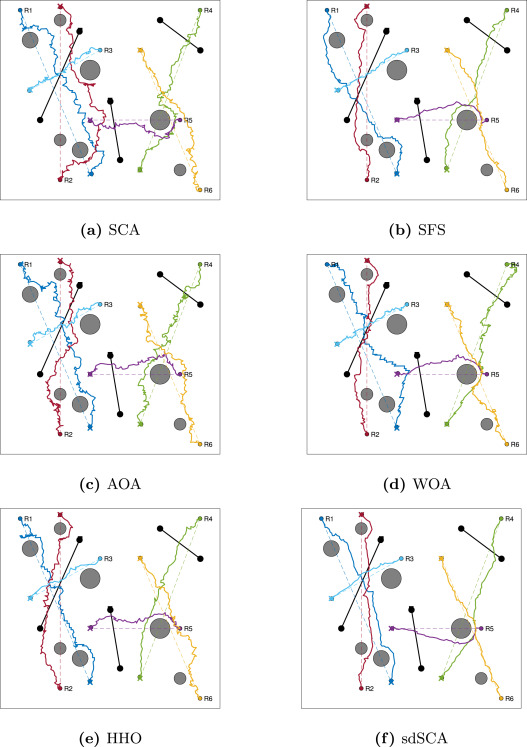
图9.场景1中算法获得的示例路径
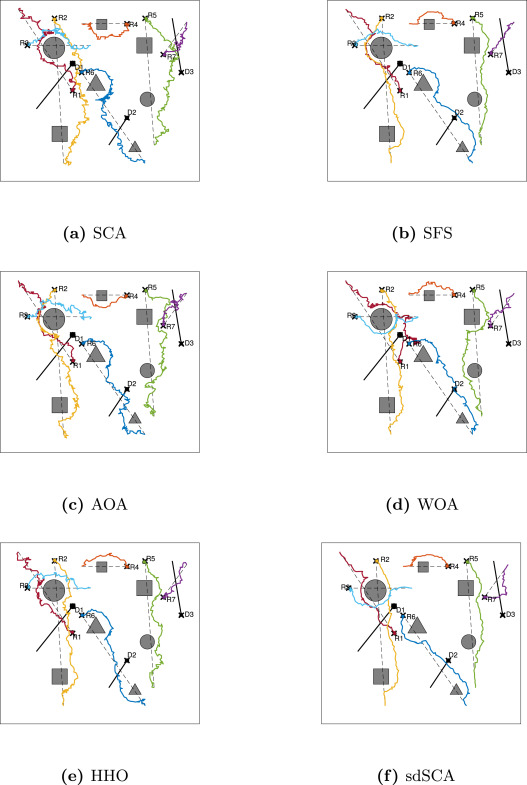
图10.场景2中算法获得的示例路径
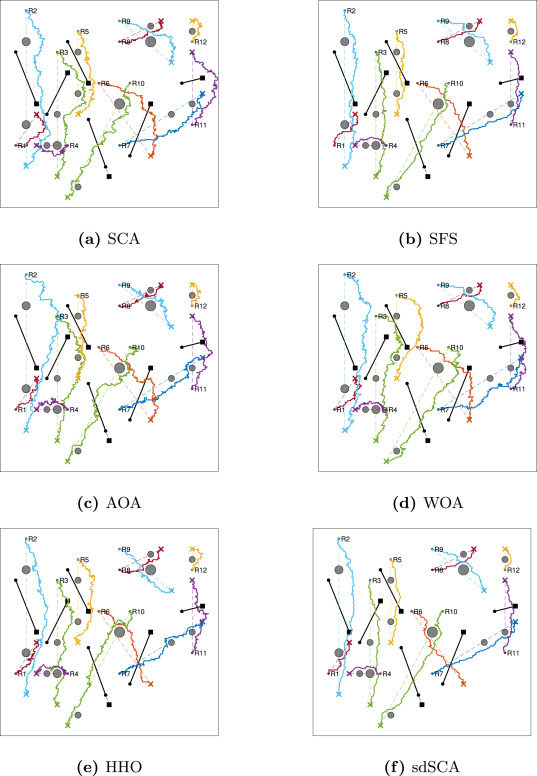
图11.场景3中算法获得的示例路径
【1】Albay Rustem, Yildirim Mustafa Yusuf. Multi-strategy and self-adaptive differential sine–cosine algorithm for multi-robot path planning[J]. Expert Systems with Applications, 2023, 232: 120849.
【2】Zhu, Lun, et al. “Self-adaptive differential evolution-based coati optimization algorithm for multi-robot path planning.” Robotica (2025): 1-38.



评论前必须登录!
注册