 网硕互联帮助中心
网硕互联帮助中心Agent Swarm
在整个技术报告中,让我最感兴趣的部分就是 Agent Swarm,这个功能需要到官网购买199元/月的套餐才能使用,具体效果我还没测过。
现有痛点:
Agent Swarm 的方案:
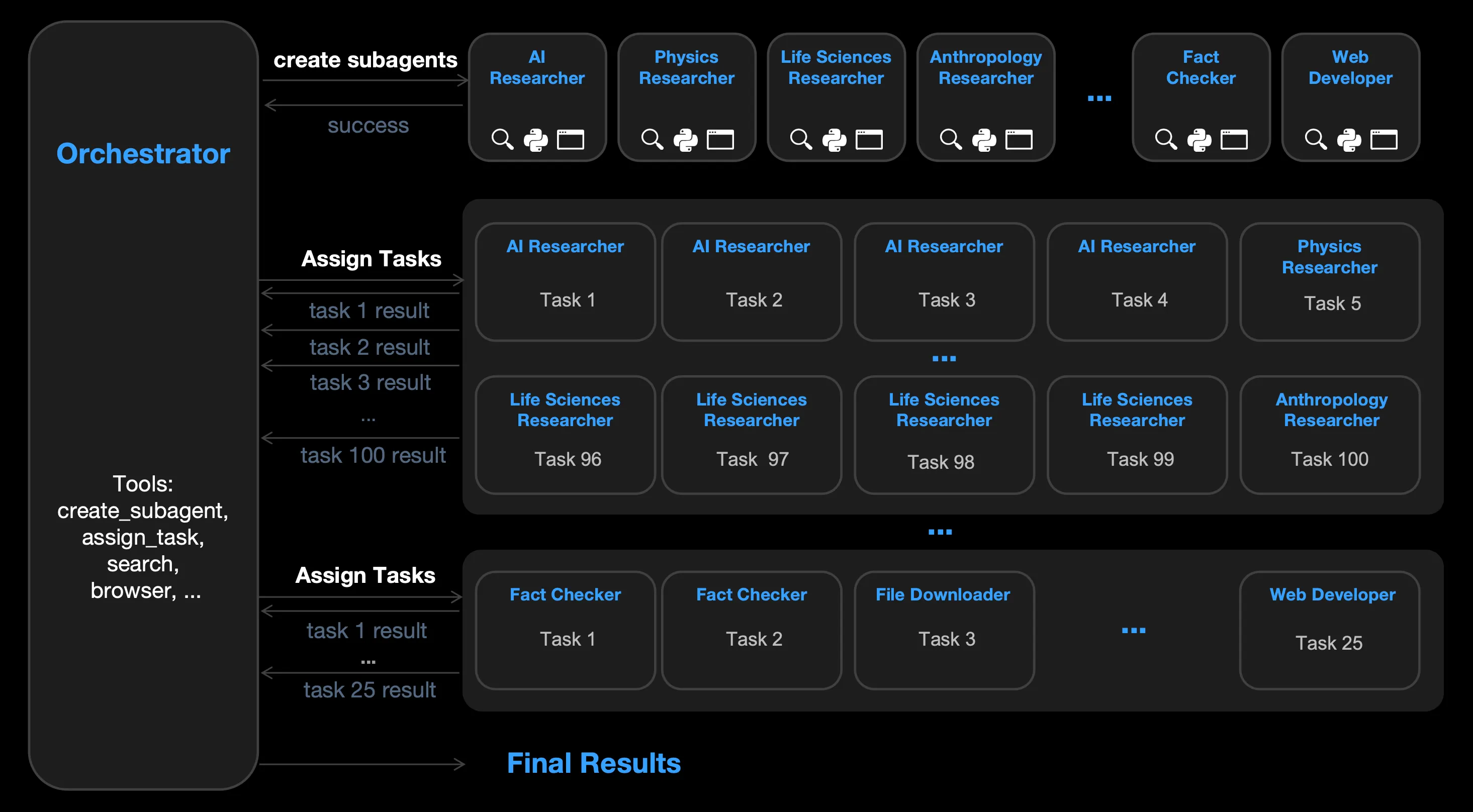
在训练中,使用 Agentic RL 的方式,让模型主动并行地发起几十上百个子 Agent 去完相应的任务,注意这里是并行执行,而不是串行地去执行一个 Todo List。其中每个子 Agent 的 Role 和分配的任务均由主 Agent 来分配。让模型学习到如何使用并行化的方式,更有效地解决问题和节省时间。训练的过程中,策略模型作为主模型,负责分配启动子 Agent 并分配任务,以及进行整合等(MapReduce),子 Agent 参数冻结。这种训练方式被 Kimi 称为 PARL(Parallel-Agent Reinforcement Learning)。

由于独立运行的子智能体提供的反馈存在延迟、稀疏和非平稳性,训练一个可靠的并行编排器极具挑战性。常见的故障模式是串行崩溃,即编排器尽管具备并行能力,却默认执行单智能体任务。为了解决这个问题,PARL 采用了分阶段奖励塑造策略,在训练初期鼓励并行性,并逐步将重点转移到任务成功上。
Rt=λaux(e)⋅rparallel+(1−λaux(e))⋅(I[success]⋅Q(τ))
R_t = \\lambda_{aux}(e)\\cdot r_{parallel} + \\left(1-\\lambda_{aux}(e)\\right)\\cdot
\\left(\\mathbb{I}[\\text{success}]\\cdot Q(\\tau)\\right)
Rt=λaux(e)⋅rparallel+(1−λaux(e))⋅(I[success]⋅Q(τ))
其中rparallelr_{parallel}rparallel可以理解为格式奖励,用于鼓励子 Agent 的实例化与并发执行;I[success]⋅Q(τ)\\mathbb{I}[\\text{success}]\\cdot Q(\\tau)I[success]⋅Q(τ)是结果质量分。
在训练的过程中 λaux(e)\\lambda_{aux}(e)λaux(e)从初始的0.1退火至0.0。
CriticalSteps=∑t=1T(Smain(t)+maxiSsub,i(t))
\\text{CriticalSteps}=\\sum_{t=1}^{T}\\left(S_{\\text{main}}^{(t)}+\\max_i S_{\\text{sub},i}^{(t)}\\right)
CriticalSteps=t=1∑T(Smain(t)+imaxSsub,i(t))
Critical Steps,通过计算时间,衡量 Agent 的延迟。其中,Smain(t)S_{main}^{(t)}Smain(t)表示编排开销,而maxiSsub,i(t)\\max_i S_{\\text{sub},i}^{(t)}maxiSsub,i(t)则反映了在每个阶段中最慢的子智能体。在该指标下,增加子任务数量只有在缩短关键路径时才会带来性能提升。这只是给出了一个用于衡量 Agent Swarm 延迟的指标,并没有参与到 Reward/Loss 的计算中。

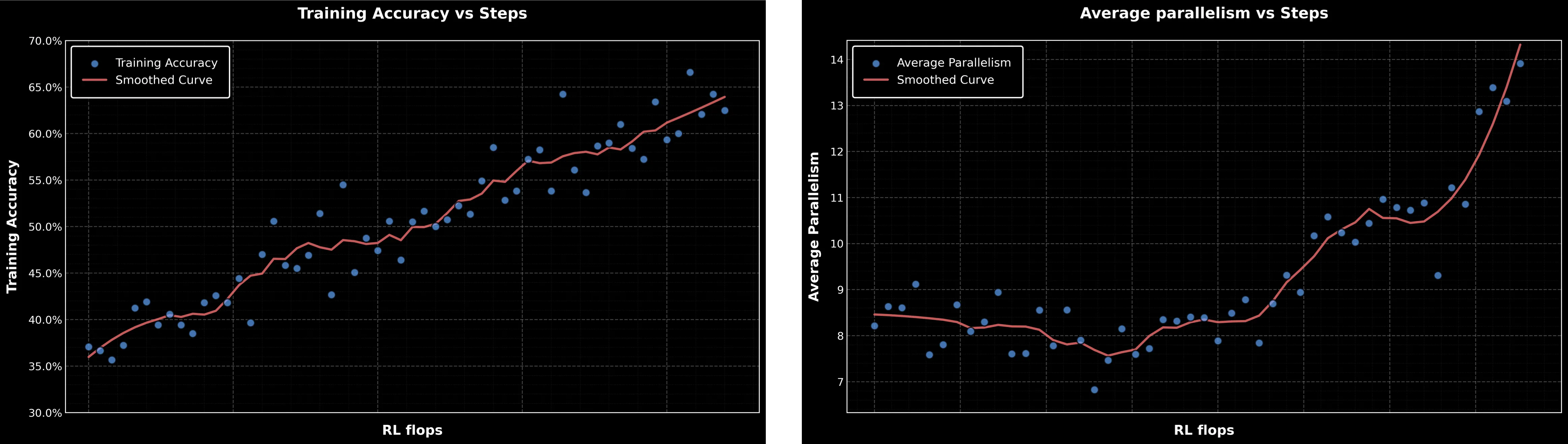
可见,随着训练step的增加,不仅ACC在稳步提升,Agent Swarm 的并行性也在显著增加。
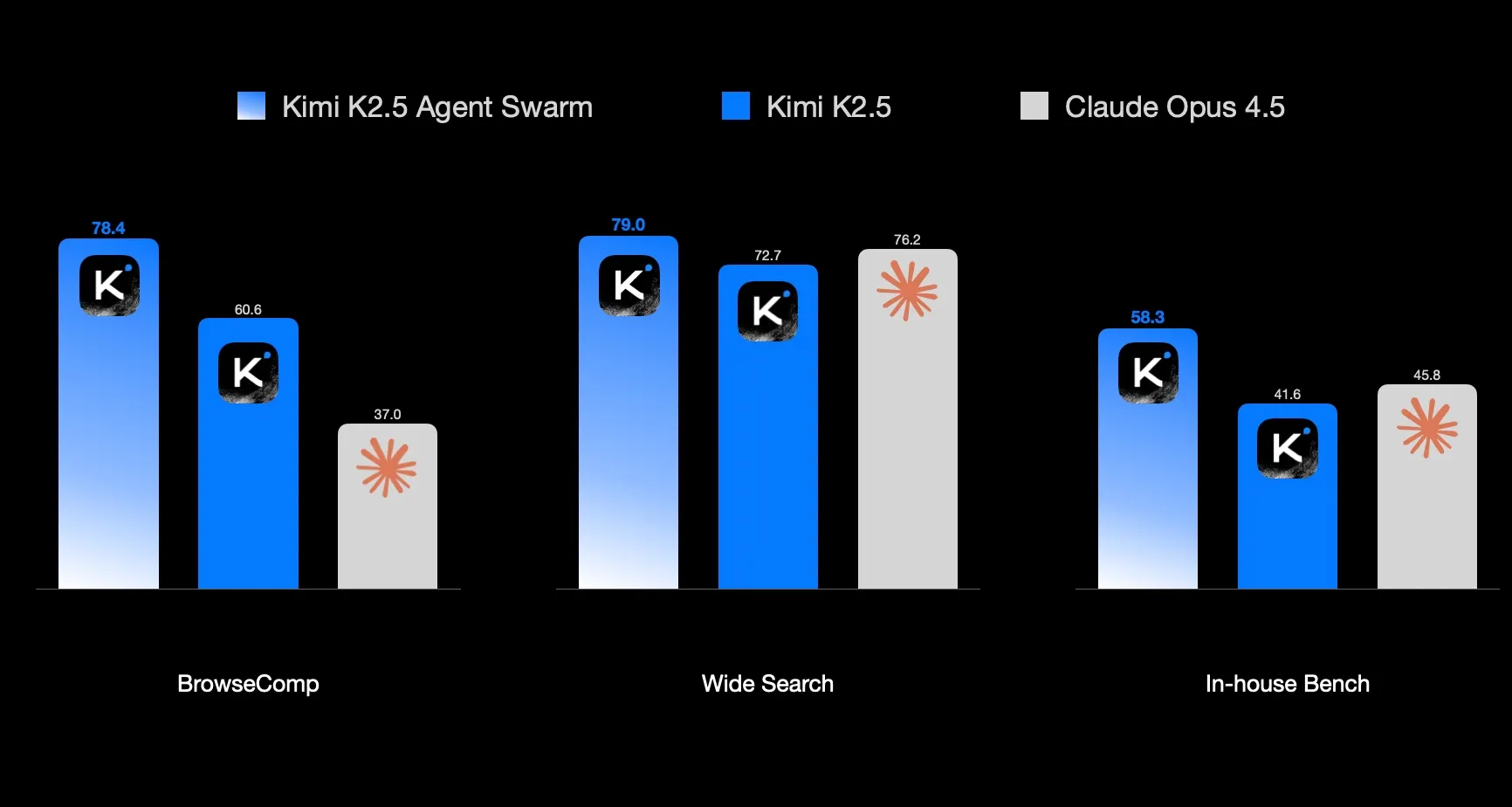
报告显示,其性能超过了 Claude Opus 4.5,但是会员会员买不起…先观望一下…







评论前必须登录!
注册