 网硕互联帮助中心
网硕互联帮助中心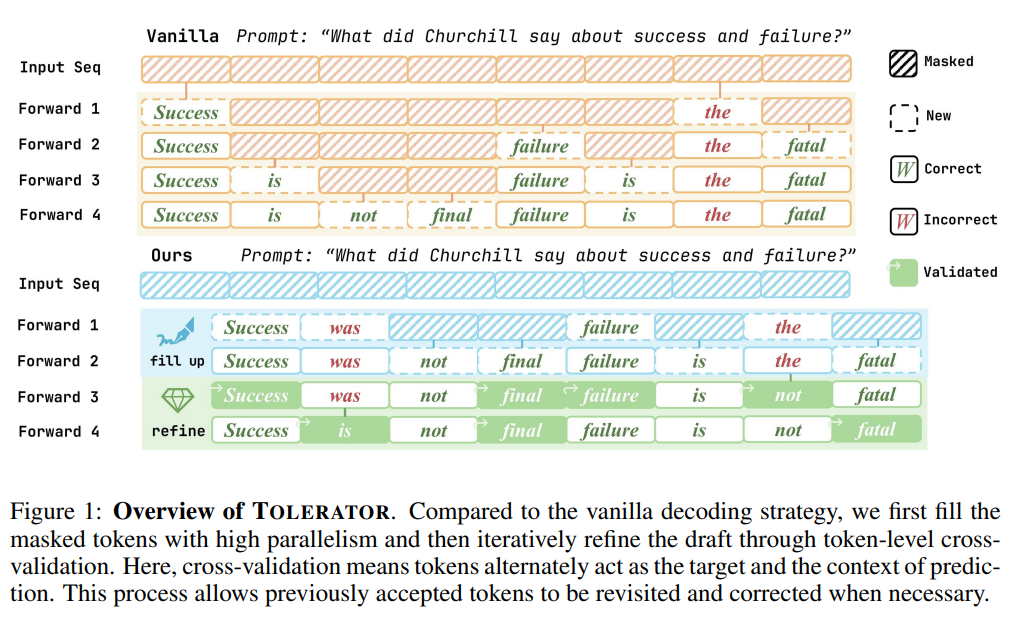 该文章提出了一种名为TOLERATOR的无训练解码策略,旨在解决离散扩散大型语言模型(dLLMs)解码中“令牌一旦被接受便无法修改”的核心问题,通过两阶段流程提升模型生成质量,且在多任务基准测试中表现优于现有方法。
该文章提出了一种名为TOLERATOR的无训练解码策略,旨在解决离散扩散大型语言模型(dLLMs)解码中“令牌一旦被接受便无法修改”的核心问题,通过两阶段流程提升模型生成质量,且在多任务基准测试中表现优于现有方法。
一、文章主要内容总结
- dLLMs作为自回归(AR)模型的替代方案,具备并行解码加速和双向上下文建模优势,但现有离散dLLMs的普通解码策略存在缺陷:令牌一旦被接受,后续步骤无法修改,导致早期错误持续传播,影响生成质量。
- 现有改进方法(如ReMDM、RCR、GIDD)或改进效果有限,或需额外训练,未能完全解决问题。
- 采用“填充-优化”两阶段无训练解码流程,无需对模型进行额外训练,仅优化解码环节。
- 阶段一:序列填充(Sequence Fill-Up):遵循普通dLLM解码策略填充掩码令牌,同时引入文本结束(EoT)令牌的对数惩罚,避免生成过短序列,为后续优化提供更完整的初始草稿。
- 阶段二:交叉验证优化(Cross-Validation Refinement):迭代对部分令牌重新掩码并解码,剩余令牌作为上下文;采用余弦退火调度优化率,









评论前必须登录!
注册