 网硕互联帮助中心
网硕互联帮助中心
📖标题:LogicReward: Incentivizing LLM Reasoning via Step-Wise Logical Supervision
🌐来源:arXiv, 2512.18196v2; ICLR 2026
🌟摘要
尽管LLM表现出强大的推理能力,但现有的训练方法在很大程度上依赖于基于结果的反馈,这种反馈可以通过有缺陷的推理产生正确的答案。之前的工作引入了对中间步骤的监督,但仍然缺乏逻辑稳健性的保证,这在逻辑一致性至关重要的高风险场景中至关重要。为了解决这个问题,我们提出了LogicReward,这是一种新颖的奖励函数,通过使用定理证明器强制执行步骤级逻辑正确性来指导模型训练。我们进一步引入了带有软统一的自动形式化,它减少了自然语言歧义并提高了形式化质量,从而能够更有效地使用定理证明器。在使用LogicReward构建的数据上训练的8B模型在自然语言推理和逻辑推理任务上以简单的训练程序超过GPT-4o和o4-mini 11.6%和2%。进一步分析表明,LogicReward增强了推理忠实性,提高了对数学和常识推理等看不见的任务的泛化性,即使没有地面真相标签也能提供可靠的奖励信号。代码和数据可在https://llm-symbol.github.io/LogicReward获得。
🛎️文章简介
🔸研究问题:如何在不依赖最终答案正确性的前提下,确保大语言模型(LLM)的每一步推理都逻辑严谨、前提忠实?
🔸主要贡献:论文提出LogicReward,一种基于自动形式化与定理证明器的步骤级逻辑有效性奖励函数,首次在NLI等模糊自然语言领域实现可验证的逻辑监督。
📝重点思路
🔸设计双维度验证机制:Premise Validity通过余弦相似度衡量推理步骤是否严格基于给定前提;Logic Validity借助Isabelle验证每步推论的逻辑有效性。
🔸提出自动形式化:利用LLM显式补全自然语言中隐含的常识性假设(如“give a speech”→“public speaking”),缓解形式化歧义,提升定理证明通过率。
🔸构建逻辑感知数据集:对LLM生成的多条推理链打LogicScore(加权平均推理有效性与结果正确性),用于SFT(选最高分)和DPO(选最高/最低分配对)。
🔸引入定理证明反馈驱动的迭代精炼:对被Isabelle判为无效的步骤,利用错误信息提示LLM优化软统一表述,生成更易验证的推理链。
🔎分析总结
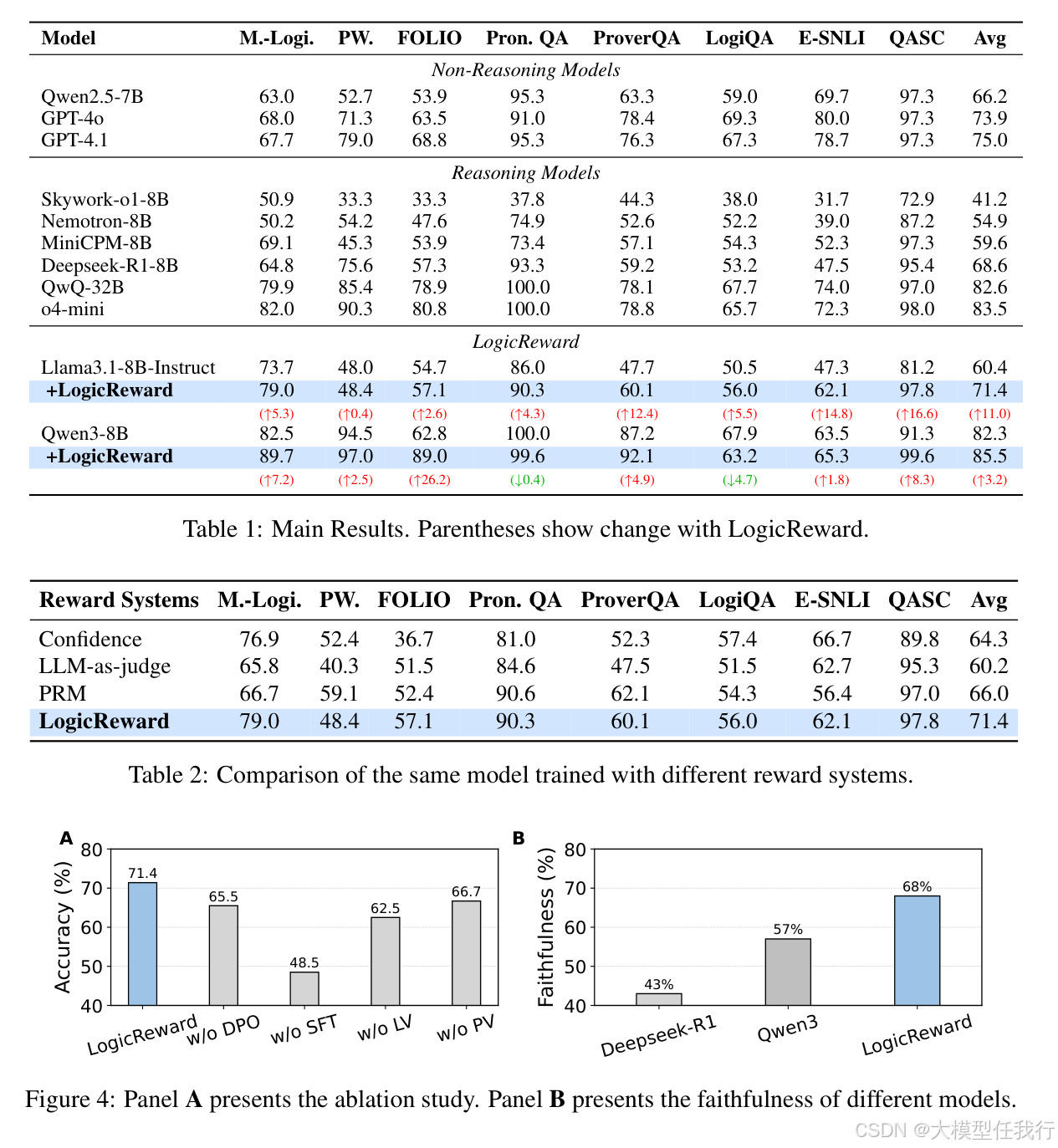
🔸LogicReward使8B模型在NLI与逻辑推理任务上超越GPT-4o和o4-mini达11.6%和2%,且在BBH、CommonsenseQA等未见任务上泛化提升达8.2%–13.6%。
🔸消融实验证明:移除Logic Validity导致性能下降8.9%,证实逻辑验证是抑制推理捷径的关键;移除Premise Validity则下降4.7%,说明前提忠实同样不可替代。
🔸在无真实标签场景下,LogicReward仍以71.4%平均准确率显著优于置信度、LLM裁判、PRM等方法,验证其不依赖答案监督的鲁棒性。
🔸软统一与精炼策略将语法有效率从13.5%提升至72.6%,逻辑有效率从11.9%升至50.8%,证明其有效弥合自然语言与形式逻辑鸿沟。
💡个人观点
论文将符号AI的确定性验证能力(定理证明)深度嵌入LLM训练闭环,它突破了传统过程监督的概率性局限。
🧩附录









评论前必须登录!
注册