 网硕互联帮助中心
网硕互联帮助中心目录
引言
一、逻辑架构
🖥️ 客户端层
🧠 MySQL Server 层
🛢️ 存储引擎层
📁 文件系统层
二、SQL查询与修改底层执行逻辑
第一阶段:MySQL Server层处理
1、客户端请求:
2、连接器:
3、查询缓存(MySQL8已移除):
4、解析器:
5、预处理器:
6、优化器:
7、执行器:
第二阶段:InnoDB存储引擎层处理(事务性更新)
1、读取数据到Buffer Pool
2、写入Undo Log(旧值记录)
3、更新Buffer Pool中的数据
4、写入Redo Log Buffer(内存缓存区)
5、Redo Log刷盘(Prepare阶段)
6、写入Binlogo
7、Redo Log commit标记
8、后台IO线程刷脏页
9、返回结果给客户端
三大核心日志:保证数据一致性和恢复性
三、InnoDB与MyISAM:存储引擎选型指南
1、核心区别对比
2、选型建议
四、MySQL索引:从设计到避坑
1、索引分类(多维度拆解)
2、核心原理:回表与覆盖索引实战
3、索引设计最佳实践(避坑指南)
五、MySQL事务:ACID与隔离实战
1、事务的ACID原则
2、并发事务常见的三大问题
3、事务隔离级别(从低到高)
4、实战技巧
六、MySQL锁机制:避免并发冲突
1、锁的分类
2、锁机制实战建议
七、MySQL性能优化:从基础到分布式
1、基础优化:SQL与表设计
2、进阶优化:索引与分页
3、架构优化:主从复制与读写分离
4、分布式优化:分库分表
5、监控与诊断
引言
在云原生时代,MySQL 作为最主流的关系型数据库之一,被广泛应用于电商、金融、互联网等各类业务场景。无论是数据查询的效率优化、事务的一致性保障,还是分布式架构下的主从复制、分库分表,掌握 MySQL 的核心原理都是开发者和运维人员的必备技能。本文将从查询流程、存储引擎、索引设计、事务隔离、锁机制到性能优化,全面拆解 MySQL 关键知识点,并结合实际应用场景补充实战技巧,助力大家在生产环境中高效使用 MySQL。
一、逻辑架构
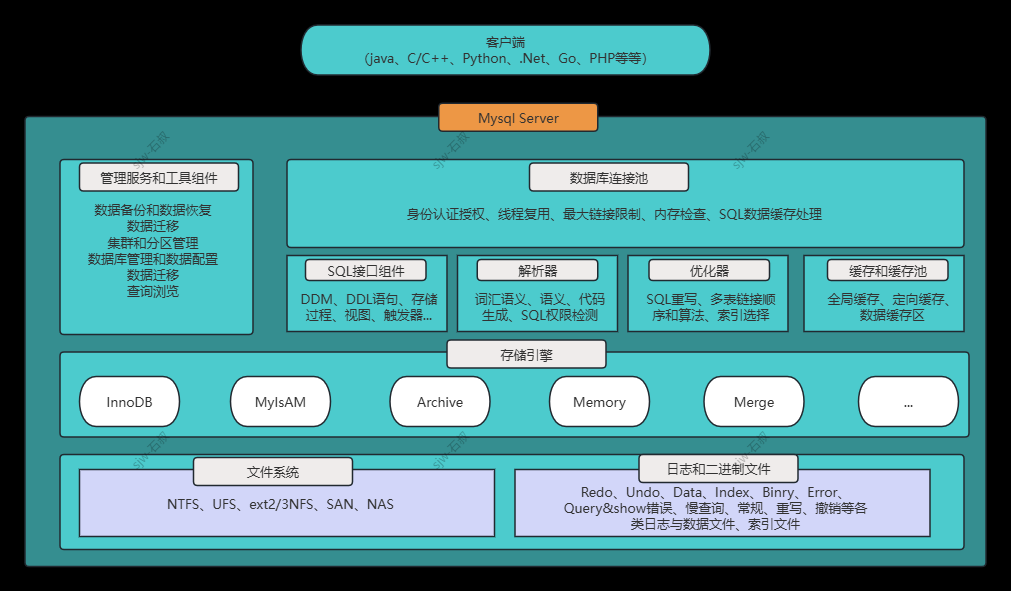
上面的Mysql架构图展示了Mysql服务器的整体架构与核心组件,从客户端到文件系统的完整处理流程。以下是其结构化整理和说明:
🖥️ 客户端层
支持多种编程语言进行数据库操作:Java、C/C++、Python、.Net、Go、PHP等
🧠 MySQL Server 层
1、管理服务与工具组件: 数据库连接池、数据库备份与恢复、身份认证与授权、线程复用、最大
连接限制、内存检查、SQL数据缓存处理数据迁移、集群与分页管理、数据库管理与配置。
2、SQL接口组件:DDM、DD语句、存储过程、视图、触发器的支持,以及查询浏览和SQL权限
检测。
3、解析器:负责SQL语句的词汇语法解析、语义分析、代码生成。
4、优化器:对SQL语句进行优化处理,比如SQL重写、多表连接顺序优化、连接算法选择、索引
选择。
5、缓存与缓存池:全局缓存、定向缓存、数据缓存区
🛢️ 存储引擎层
支持多种引擎操作,比如Innodb(事务安全)、MyIsAM(查询性能高)、Archive(压缩存储)、Memory(内存存储)
📁 文件系统层
支持文件系统类型:NTFS、UFS、ext2/3、NFS、SAM、NAS
日志与数据文件:Redo、Undo、数据文件(Data)、索引文件(Index)、二进制日志(Binary Log)、错
误日志(Error Log)、慢查询日志
二、SQL查询与修改底层执行逻辑
这里只讲Innodb引擎的流程,废话不多说直接上图:
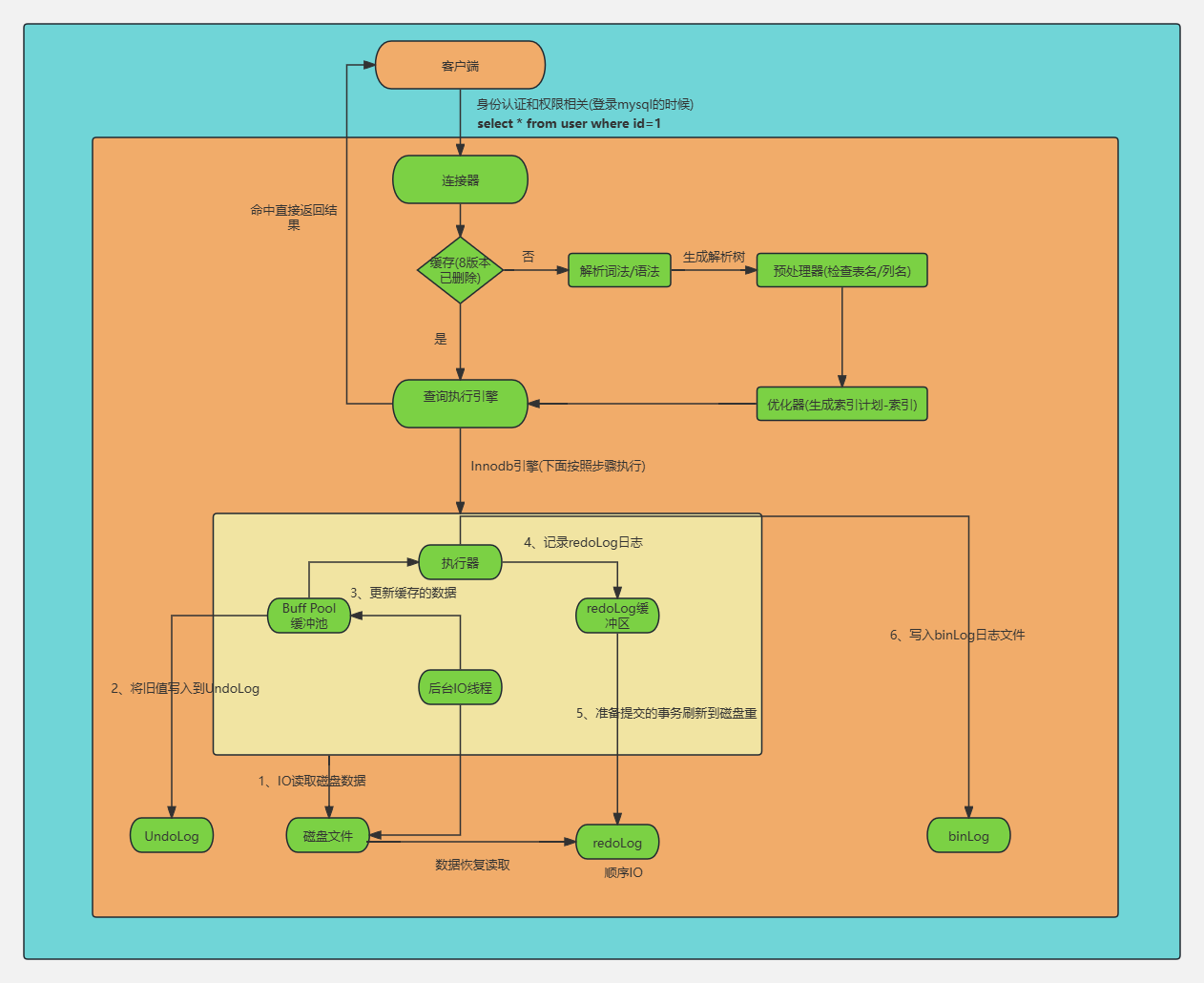
完整执行链路:
应用程序 → API接口调用 → 缓存 → 词法/语法解析 → 预处理器(检查表名列名)→ 语义解析(生成解析树)→ 优化器(生成执行计划)→ 查询执行引擎 → 存储引擎(InnoDB/MyISAM)→ 存储数据
第一阶段:MySQL Server层处理
1、客户端请求:
● 应用程序用过MySQL客户端(比如JDBC、命令行、ORM框架等)发送SQL语句
● 例如:UPDATE users SET balance = balance – 100 WHERE id = 1
2、连接器:
● 作用:管理客户端的连接,验证身份和权限
● 流程:
○ 验证用户名和密码
○ 检查该用户对数据库、表的操作
○ 建立连接(如果是新连接)
○ 连接池优化:如果使用连接池,可以复用已有连接,避免重复创建和销毁
3、查询缓存(MySQL8已移除):
● 历史作用:缓存查询结果,key为SQL语句的hash,value为结果集
● 为何移除:
○ 缓存命中率低(表有更新就会失效)
○ 维护缓存有额外开销
○ 在8.0版本中已正式移除
4、解析器:
● 词法分析:讲SQL语句拆分为一个个token(关键词、表名、列名)
● 语法分析:检查SQL语法是否正确,生成抽象语法树(AST)
● 示例:检查UPDATE、SET、WHERE等关键词使用是否正确
5、预处理器:
● 语义检查:
○ 检查表名列名是否存在
○ 检查用户是否存在
○ 检查数据类型是否匹配
● 视图展开:如果有视图,展开为实际表操作
6、优化器:
● 核心作用:选择最优执行计划,决定如何高效的执行顺序(可以通过explan查询,下面会介
绍)。
● 决策内容:
○ 选择使用哪个索引(或全表扫描)
○ 多表连接时的连接顺序和连接方式
○ 子查询优化等
● 示例:对WHERE id = 1,优化器会选择主键索引
7、执行器:
● 作用:按照优化器的执行计划,调用存储引擎接口
● 流程:
○ 打开相关表
○ 调用InnoDB接口获取数据
○ 循环处理符合条件的行
第二阶段:InnoDB存储引擎层处理(事务性更新)
1、读取数据到Buffer Pool
磁盘文件→通过IO读取→Buffer Pool(内存缓冲池)
● Buffer Pool:InnoDB的内存缓存区,存放数据页的拷贝
● 流程:
○ 检查所需数据页是否存在Buffer Pool
○ 如果不在(未命中),从磁盘中读取到Buffer Pool
○ 数据以“页”为单位(默认16K)
2、写入Undo Log(旧值记录)
● 作用:记录数据修改前的值,用于
○ 事务回滚(Rollback)
○ 实现MVCC(多版本并发控制)
● 内容:记录id = 1这行数据的旧值(修改之前的balance)
● 持久化:Undo Log也会写入磁盘的Undo空间
3、更新Buffer Pool中的数据
● 内存中的更新:在Buffer Pool中修改数据页
● 状态变化:数据页变为“脏页”(已磁盘不一致)
● 延迟写入:此时不会立即写回磁盘,而是等待后续刷脏
4、写入Redo Log Buffer(内存缓存区)
● Redo Log作用:记录物理修改,用于故障恢复
● 格式:"在表空间X的页面Y的偏移Z处写入值W"(此处不做详细介绍,可以网上查找下资
料)
● 特点:
○ 顺序写入,性能高
○ 循环覆盖(固定大小,写满后覆盖旧的记录)
○ Write-Ahead Logging(WAL)原则:先写日志,后写数据
5、Redo Log刷盘(Prepare阶段)
Redo Log Buffer →Redo Log文件(磁盘)
● 时机:根据innodb_flush_log_at_trx_commit 设置
○ =1:每次事务提交都刷盘(最安全,性能较低)
○ =2:每秒刷盘(性能较好,可能丢失1秒数据)
○ =0:依赖 OS 刷新(不推荐)
● 状态:此时Redo Log标记为Prepare(两阶段提交的第一步)
6、写入Binlogo
● Binlog作用:Mysql Server层的逻辑日志,用于
○ 主从复制(Replication)
○ 数据恢复(Point-in-Time Recovery)
● 内容:记录逻辑操作"UPDATE users SET balance=… WHERE id=1"
● 与Redo Log的区别:
○ Redo Log:物理日志,InnoDB引擎层,循环写
○ Binlog:逻辑日志,Server层,追加下
7、Redo Log commit标记
● 两阶段提交(2PC)的第二阶段
● 在Redo Log中写入Commit标记
● 目的:保证Redo Log和Binlog的一致性
● 崩溃修复:
○ 如果 Redo Log 有 Prepare 无 Commit,检查 Binlog 是否完整
○ 如果 Binlog 完整,则提交事务;否则回滚
8、后台IO线程刷脏页
● 异步操作:不阻塞事务提交
● 触发时机:
○ Buffer Pool空间不足
○ 后台线程定时刷新
○ 脏页比例过高时
○ 数据库空闲时
● Checkpoint:标记哪些脏页已刷新到磁盘
9、返回结果给客户端
● 执行器收到存储引擎的完成通知
● 向客户端返回执行结果(如:Query OK, 1 row affected)
三大核心日志:保证数据一致性和恢复性
|
日志类型 |
所属组件 |
核心作用 |
应用场景 |
|
Redo Log (重做日志) |
InnoDB |
记录数据页的修改,支持崩溃修复 |
Mysql宕机后,重启时通过Redo Log恢复未写入磁盘的修改,保障持久性 |
|
Undo Log(回滚日志) |
InnoDB |
记录事务执行的原始数据,支持事务回滚 |
事务执行失败时,通过Undo Log撤销已做修改,保障原子性;同时支撑MVCC实现 |
|
Binlog(二进制日志) |
Mysql服务器 |
记录所有数据的变更(DDL/DML),支持增量同步 |
主从复制、数据备份、集群同步(核心日志) |
关键区别:
○ Redo Log和Undo Log是InnoDB存储引擎自带,仅针对InnoDB生效
○ Binlog是MySQL服务器层日志,对所有存储引擎生效
三、InnoDB与MyISAM:存储引擎选型指南
MySQL支持多种存储引擎,其中InnoDB和MyISAM是最常见的两种,二者在事务、锁机制、索引结构等方面差异显著,选型直接影响系统性能和稳定性,如下所示
1、核心区别对比
|
对比维度 |
InnoDB(MySQL5.5+默认) |
MyISAM |
|
事务支持 |
支持ACID事务 |
不支持事务 |
|
锁机制 |
行级锁(粒度细,高并发友好) |
表级锁(粒度粗,并发性能差) |
|
索引结构 |
B+树,叶子节点存储索引+数据(聚集索引) |
B + 树,叶子节点存储索引 + 数据指针 |
|
存储文件 |
数据和索引存于同一文件(.ibd) |
数据文件(.MYD)和索引文件(.MYI)分离 |
|
行数统计 |
不存储表行数,select count(*)需全表扫描 |
内置行数计数器,select count(*)秒级返回 |
|
崩溃修复 |
支持(依赖 Redo/Undo Log) |
不支持,崩溃后可能丢失数据 |
|
使用场景 |
电商订单、金融交易等需要事务、高并发的场景 |
博客、静态数据查询、只读统计等场景 |
2、选型建议
● 生产环境优先选择InnoDB:除非是纯只读、无事务需求的简单场景,否则InnoDB的事务支持、行级锁、崩溃恢复能力更能保障业务的稳定性。
● 腾讯云MySQL优化:腾讯云 MySQL 默认使用 InnoDB 引擎,并优化了日志刷盘策略、锁等待超时设置,适配云环境下的高可用需求(如主从自动切换、故障自愈)。
四、MySQL索引:从设计到避坑
索引是 MySQL 提升查询性能的核心,好的索引设计能让查询效率提升 10 倍以上。但不合理的索引反而会拖慢写入性能,因此需要深入理解索引的类型、原理和最佳实践。
1、索引分类(多维度拆解)
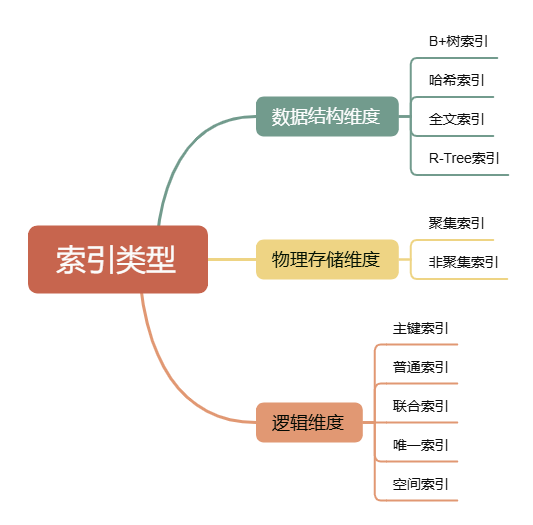
(1) 按照数据结构划分:
● B+树索引:MySQL默认索引类型,支持范围查询、排序,适合绝大多数场景(主键、普通索引、联合索引均基于 B + 树)。B+树的规定是小于往左走,大于往右走
● 哈希索引:基于哈希表,仅支持等值查询(=、in),不支持范围查询和排序,适用于高频等值查询场景(如缓存键值映射)。
● 全文索引:针对文本内容(如文章正文)的关键词检索,支持MATCH AGAINST查询,不适合精确匹配。
● R-Tree索引:用于空间数据类型(如 GIS 地理信息),支持空间范围查询。
(2) 按存储物理划分:
● 聚集索引(聚簇索引):数据与索引存储在一起,叶子节点直接存储行数据(一张表有且仅有
一个)
○ 优先级:主键索引 → 第一个唯一索引 → InnoDB 自动生成的隐藏 rowid(无主键 / 唯一索
引时)
○ 优势:查询主键时无需回表,直接获取数据
● 二级索引(非聚簇索引):数据与索引分离,叶子节点存储主键值(一张表可多个)
(3) 按照逻辑功能划分:
● 主键索引:唯一标识行数据,不可为空,一张表仅有一个
● 唯一索引:避免列值重复(允许为空,但最多一个 NULL)
● 普通索引:自定义索引,无唯一性约束
● 联合索引:多列组合的索引(如idx_name_age (name, age)),遵循 “最左前缀原则”
● 覆盖索引:查询列完全包含在索引中,无需回表(如select name from user where
name='石',若name是二级索引,则直接返回结果)
2、核心原理:回表与覆盖索引实战
— 表结构:user(id int primary key, name varchar(20), age int),idx_name(name)为二级索引
— 案例1:非覆盖索引(需要回表)
select * from user where name='石';
— 执行流程:idx_name找到name='石'对应的主键id → 聚集索引通过id查询行数据(回表)
— 案例2:覆盖索引(无需回表)
select name from user where name='石';
— 执行流程:idx_name的叶子节点直接存储name值,无需回表,效率提升50%+
总结:就是表直接设置二级索引,则直接返回结果,如果没有设置索引;那么会找到对应的id再进行查询,也就是回表
3、索引设计最佳实践(避坑指南)
● 遵循 “最左前缀原则”:联合索引idx_a_b_c,仅支持a、a+b、a+b+c查询,不支持b、b+c
查询。
● 避免索引失效:
○ 不使用函数操作索引列(如where date(create_time)='2024-01-01')
○ 不使用模糊查询前缀 %(如where name like '%石',会导致全表扫描)
○ 避免隐式类型转换(如where id='1',字符串转数字导致索引失效)
● 控制索引失效:索引越多,写入(insert/update/delete)越慢(需维护索引结构),单表索
引建议不超过 5 个。
● 覆盖索引:
○ 如果查询的列都包含在索引中,那么就不需要回表查询,这称为索引覆盖
○ 例如,有一个索引(name, age),查询SELECT name, age FROM user WHERE name =
'John'就可以使用索引覆盖。
● 索引下推:MySQL 5.6引入,可以在索引遍历过程中,对索引中包含的字段先做判断,直接
过滤掉不满足条件的记录,减少回表次数。
五、MySQL事务:ACID与隔离实战
事务是数据库保证数据一致性的核心机制,尤其是在电商下单、金融转账等场景中,必须深入理解事务的 ACID 特性、隔离级别及并发问题。
1、事务的ACID原则
● 原子性(Atomicity):事务是不可分割的最小单位,要么全部执行成功,要么全部回滚(如
转账:扣款和到账必须同时成功或失败)。
● 一致性(Consistency):事务执行前后,数据总状态保持一致(如转账前 A 有 100 元、B
有 50 元,转账后总和仍为 150 元)。
● 隔离性(Isolation):多个事务并发执行时,相互不干扰,每个事务都感觉不到其他事务的
存在。
● 持久性(Durability):事务提交后,数据永久写入磁盘,即使系统崩溃也不会丢失
2、并发事务常见的三大问题
|
问题类型 |
定义 |
场景示例 |
|
脏读 |
事务 A 读取到事务 B 未提交的修改 |
事务 B 修改用户余额但未提交,事务 A 读取到该余额,随后事务 B 回滚,A 读取的是 “脏数据” |
|
不可重复读 |
事务 A 多次读取同一数据,结果不一致(因事务 B 修改并提交) |
事务 A 第一次读取余额为 100 元,事务 B 修改为 80 元并提交,A 再次读取为 80 元 |
|
幻读 |
事务 A 读取符合条件的记录后,事务 B 插入新记录,A 再次读取时多了 “幻影” 记录 |
事务 A 查询 “年龄> 20” 的用户有 10 人,事务 B 插入 1 个年龄 25 的用户,A 再次查询变为 11 人 |
3、事务隔离级别(从低到高)
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
性能 |
适用场景 |
|
读未提交 |
允许 |
允许 |
允许 |
最高 |
无(数据一致性无法保障) |
|
读已提交 |
禁止 |
允许 |
允许 |
较高 |
大部分互联网场景(如新闻、论坛) |
|
可重复读 |
禁止 |
禁止 |
部分禁止(MVCC) |
中等 |
电商、金融等需要一致性的场景(MySQL 默认级别) |
|
串行化 |
禁止 |
禁止 |
禁止 |
最低 |
数据一致性要求极高的场景(如银行核心交易) |
4、实战技巧
● 隔离级别设置:
— 全局级(重启生效)
set global transaction isolation level repeatable read;
— 会话级(当前连接生效)
set session transaction isolation level read committed;
● MVCC机制:MySQL 默认的 “可重复读” 级别通过 MVCC(多版本并发控制)避免幻读。核心原
理是:事务开启时生成 Read View(读视图),查询时通过 Undo Log 版本链找到符合条件的历
史数据,实现 “不加锁非阻塞读”。
● 腾讯云MySQL优化:默认隔离级别为可重复读,同时优化了 MVCC 的版本链清理策略,避免
Undo Log 膨胀导致的性能问题。
六、MySQL锁机制:避免并发冲突
锁是 MySQL 实现事务隔离的基础,不同的锁粒度和类型对应不同的并发场景。理解锁机制能帮助我们避免死锁、锁等待超时等问题。
1、锁的分类
(1) 按照操作类型划分
● 读锁(共享锁,S 锁):多个事务可同时持有,互不干扰(读 – 读兼容)
○ 语法:select * from user where id=1 lock in share mode;
● 写锁(排他锁,X 锁):同一时间仅一个事务持有,阻塞其他读锁和写锁(读 – 写、写 – 写
互斥)
○ 语法:select * from user where id=1 for update;(事务提交 / 回滚后释放)
(2) 按锁粒度划分
● 表锁:锁定整张表,开销小、速度快,但并发性能差(MyISAM 默认锁机制)
○ 触发场景:InnoDB 在索引失效时,行锁会升级为表锁(如where name like '%石'无索
引,导致全表扫描 + 表锁)
● 行锁:锁定单行数据,开销大、速度慢,但并发性能好(InnoDB 默认锁机制)
○ 注意:行锁是基于索引的,无索引时会退化为表锁
2、锁机制实战建议
● 避免行级锁升级为表锁:确保查询语句使用索引,避免全表扫描
● 小表驱动大表:多表 join 时,用小表作为驱动表(减少锁等待时间)
● 避免死锁:确保查询语句使用索引,避免全表扫描
○ 统一事务内的表访问顺序(如先访问 A 表再访问 B 表)
○ 减少长事务(长事务会持有锁更久,增加死锁概率)
● 腾讯云MySQL监控:通过腾讯云数据库控制台查看锁等待次数、死锁日志,及时优化 SQL
七、MySQL性能优化:从基础到分布式
MySQL 优化是一个系统工程,涉及 SQL 编写、索引设计、架构设计等多个层面。以下是生产环境中最实用的优化方案:
1、基础优化:SQL与表设计
● 优化查询语句:确保查询语句使用索引,避免全表扫描
○ 用EXPLAIN分析 SQL 执行计划(重点关注key(是否命中索引)、type(访问类型)、Extra
(回表、全表扫描等))
○ 避免select *,优先使用覆盖索引
○ 多表 join 时优先使用内连接(inner join),避免左 / 右连接(可能导致全表扫描)
○ 聚合查询用union all替代union(union会去重,性能开销大)
● 表结构设计:
○ 数值类型优先用tinyint、int、bigint(避免varchar存数字)
○ 字符串类型:固定长度用char,可变长度用varchar(text仅用于大文本)
○ 避免过度设计(如拆分过多字段、冗余字段)
2、进阶优化:索引与分页
● 超大分页优化:数据量超过 10 万条时,避免limit 10000, 20(全表扫描后丢弃前 10000 条),改用覆盖索引 + 子查询
— 优化前(慢)
select * from user limit 10000, 20;
— 优化后(快):先查主键,再关联详情
select u.* from user u join (select id from user limit 10000, 20) t on u.id = t.id;
● 联合索引优化:高频查询字段组合成联合索引(如where name='石' and age=25,建立idx_name_age)
3、架构优化:主从复制与读写分离
当单库性能达到瓶颈时,主从复制 + 读写分离是首选方案,腾讯云 MySQL 已内置该能力
(1) 主从复制原理
● 主库(Master)提交事务时,将数据变更记录到 Binlog
● 从库(Slave)通过 IO 线程读取主库 Binlog,写入本地中继日志(Relay Log)
● 从库 SQL 线程重放中继日志中的事件,同步主库数据
(2) 读写分离优势
● 读请求分流到从库,减轻主库压力(如查询、统计操作走从库)
● 主库专注于写操作(如插入、更新、删除),提升写入性能
● 高可用:主库故障时,从库可快速切换为主库,避免业务中断
4、分布式优化:分库分表
当单库数据量超过 1000 万条、单表超过 500 万条时,需进行分库分表,常用方案如下:
● 中间件选择:MyCat(开源)、腾讯云 TDSQL(分布式 MySQL,无需手动分库分表)
● 分片策略:按主键 id 取模(如id % 4分 4 个库),适用于均匀分布的场景。
● 注意事项:
○ 避免跨分片查询(如where id in (1,5,9)可能涉及多个分片)。
○ 全局主键生成:使用自增 id + 分片偏移量(如分片 1 的 id 为 1-1000 万,分片 2 为 1000 万
+ 1-2000 万)。
5、监控与诊断
● 慢查询日志:开启慢查询日志(slow_query_log=1,long_query_time=1秒),记录执行时
间超过 1 秒的 SQL,定期分析优化。
● 可视化监控:使用 Skywalking、Prometheus+Grafana 监控 SQL 执行时间、索引命中率、锁等
待等指标。
● 腾讯云工具:通过腾讯云数据库性能分析工具,自动识别慢 SQL、索引优化建议,一键优化。





评论前必须登录!
注册