 网硕互联帮助中心
网硕互联帮助中心目录
1、数据来源
2、数据集分类
3、数据集统计
4、数据集结构
5、数据集配置文件
6、数据分割策略
7、数据预处理
8、数据集展示
9、YOLO11训练模型
9.1、模型评估
9.2、模型验证
9.3、模型测试
10、YOLOv8s训练模型
10.1、模型评估
10.2、模型验证
10.3、模型测试
11、链接
1、数据来源
本项目使用的公开的CCPD数据集进行筛选转换成YOLO训练的数据集。
有关CCPD数据集可以查看文章【数据集 02】车牌CCPD命名规则及下载地址-CSDN博客,文章详细介绍了CCPD数据集的命名规则以及下载地址
在此特别提醒,CCPD数据集标注有错误的地方,尤其是CCPD2019车牌的标注,很多车牌标注的框都不是对应的车牌,因此需要手动筛选,不然会影响训练效果。
下面编写的python代码是把CCPD数据集转成YOLO数据集的脚本
搜集绿牌和蓝牌除了CCPD数据集还有CRPD,CRPD与CCPD不同之处在于CRPD分成三类车牌集、单车牌、双车牌、多车牌,而CCPD只有单车牌场景,因此他们的拍摄环境是不一样,可以根据具体应用项目进行选择。
因为CCPD、CRPD没有黄牌数据因此通过其他方式搜集黄牌。根据经验数据集在1万张以上YOLO模型训练可实现较好的检测效果,因此本项目最终制成包含蓝牌、绿牌、黄牌的YOLO数据集1.5万张,具体如下。
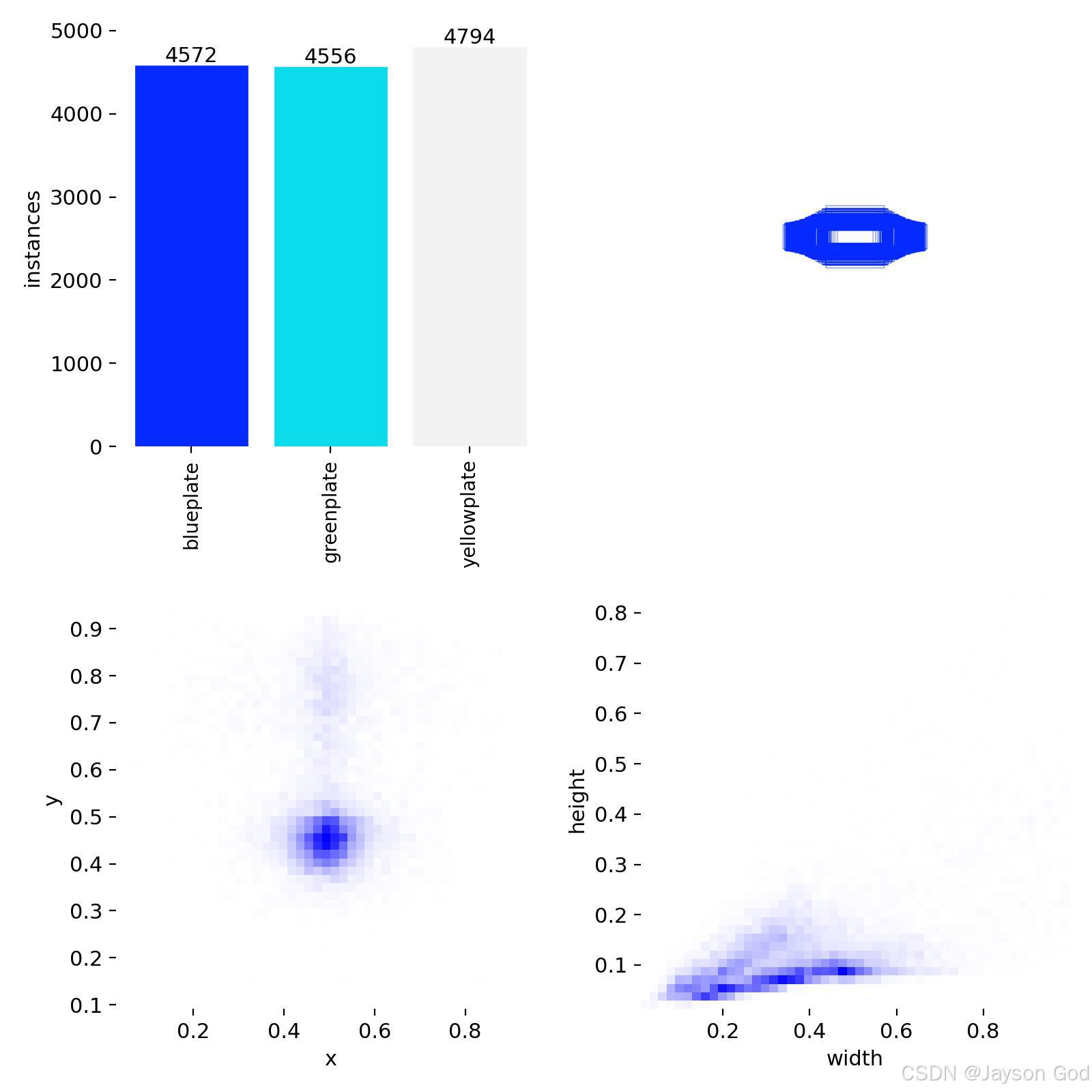
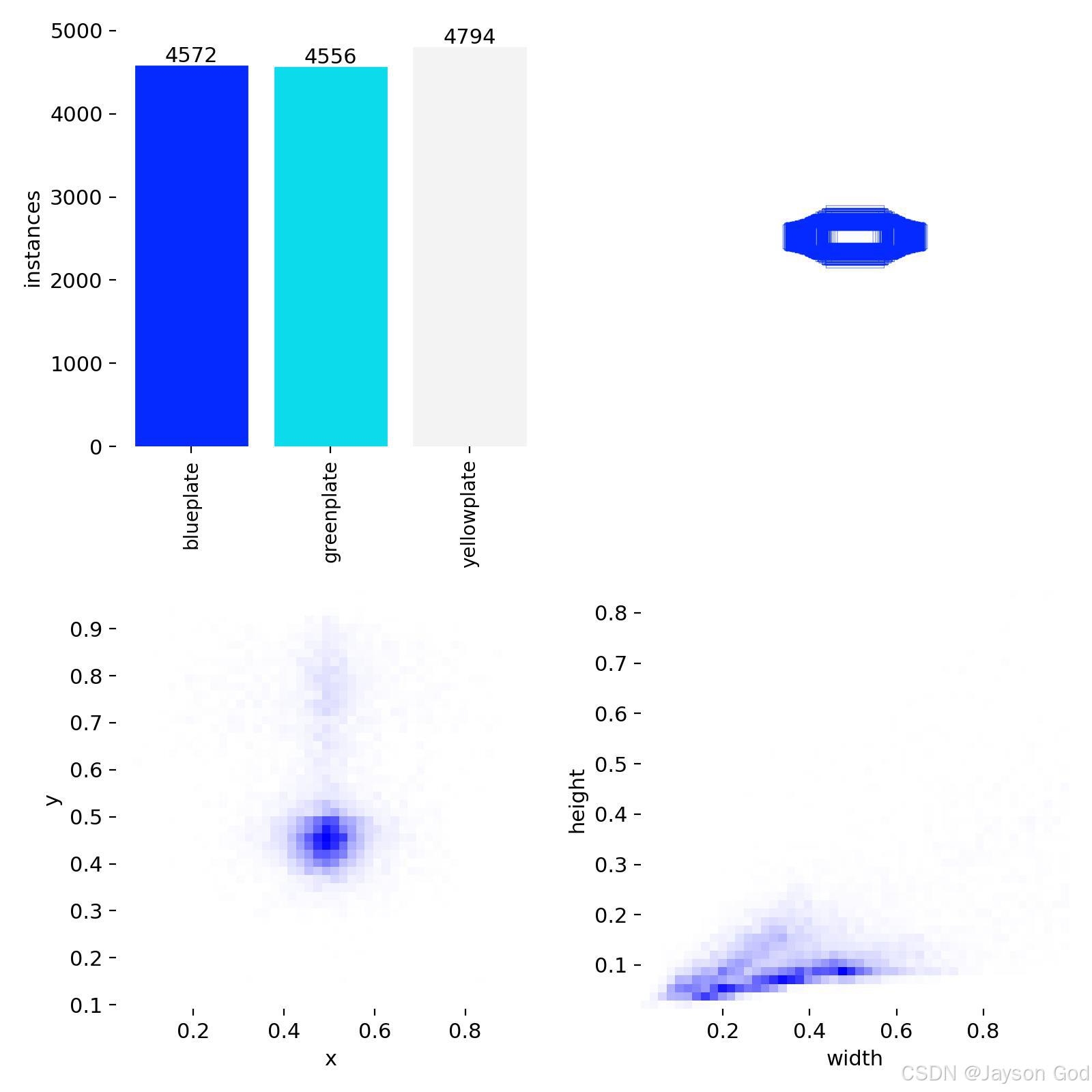
2、数据集分类
| 0 | blueplate | 蓝牌 | 5,072 |
| 1 | greenplate | 绿牌 | 5,045 |
| 2 | yellowplate | 黄牌 | 5,247 |
3、数据集统计
| 训练集(train) | 13,827 张 | 90% | 模型训练 |
| 验证集(val) | 1,383 张 | 9% | 模型验证 |
| 测试集(test) | 154 张 | 1% | 性能评估 |
| 总计 | 15,364 张 | 100% | – |
4、数据集结构
dataset/
├── train/
│ ├── images/
│ │ ├── blue_plate_00001.jpg
│ │ └── …
│ └── labels/
│ ├── blue_plate_00001.txt
│ └── …
├── valid/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/
5、数据集配置文件
data.yaml
train: D:/work/my/datasets/BlueGreenYellowPlate/train/images
val: D:/work/my/datasets/BlueGreenYellowPlate/valid/images
test: D:/work/my/datasets/BlueGreenYellowPlate/test/images
nc: 3
names: ['blueplate', 'greenplate', 'yellowplate']
labelfast:
version: 1.3
路径使用绝对路径,如果训练自己的数据集可以改成自己的数据集路径。
6、数据分割策略
数据集采用科学的分割策略,确保训练、验证和测试集之间的数据分布均衡:
分割原则:
按比例分割:训练集90%,验证集9%,测试集1% 类别平衡:确保每个类别在各数据集中都有代表性样本 场景多样性:包含不同角度、不同光照条件下的图像 难度分布:从简单到复杂的检测场景都有涵盖
7、数据预处理
为了提高模型的训练效果和泛化能力,数据集经过了全面的预处理:
预处理步骤: 数据增强:通过旋转、翻转、缩放等方式增加数据多样性 标注验证:检查标注文件的准确性和完整性 质量筛选:移除模糊、损坏或标注错误的图像 格式转换:转换为模型训练所需的格式 数据增强策略:
几何变换:旋转、翻转、缩放、平移 颜色变换:亮度、对比度、饱和度调整 噪声添加:高斯噪声、椒盐噪声 混合增强:Mosaic、MixUp等技术
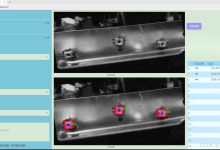
8、数据集展示
部分训练图:
部分验证图:

部分测试图:
9、YOLO11训练模型
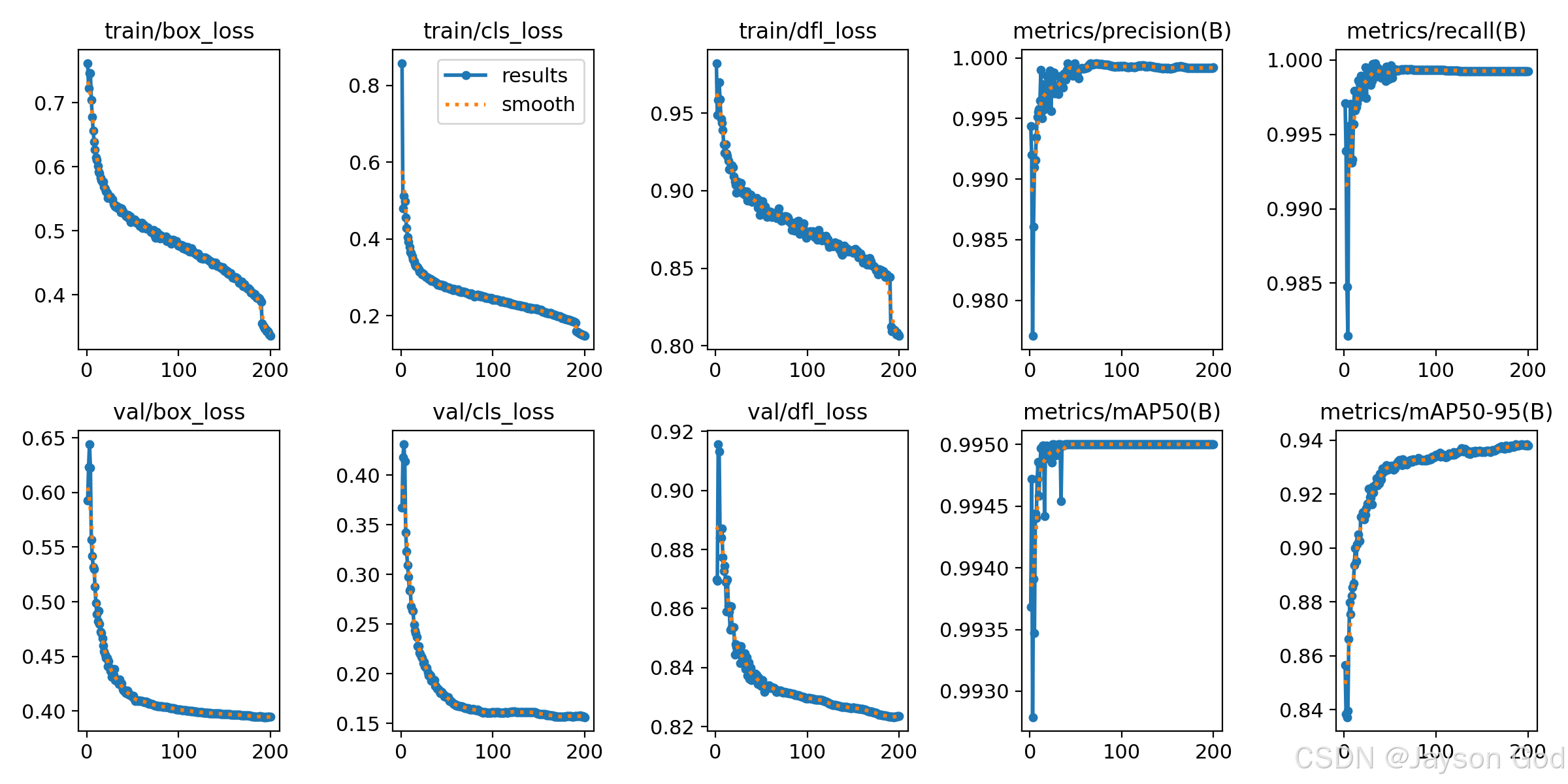
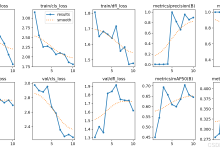
9.1、模型评估
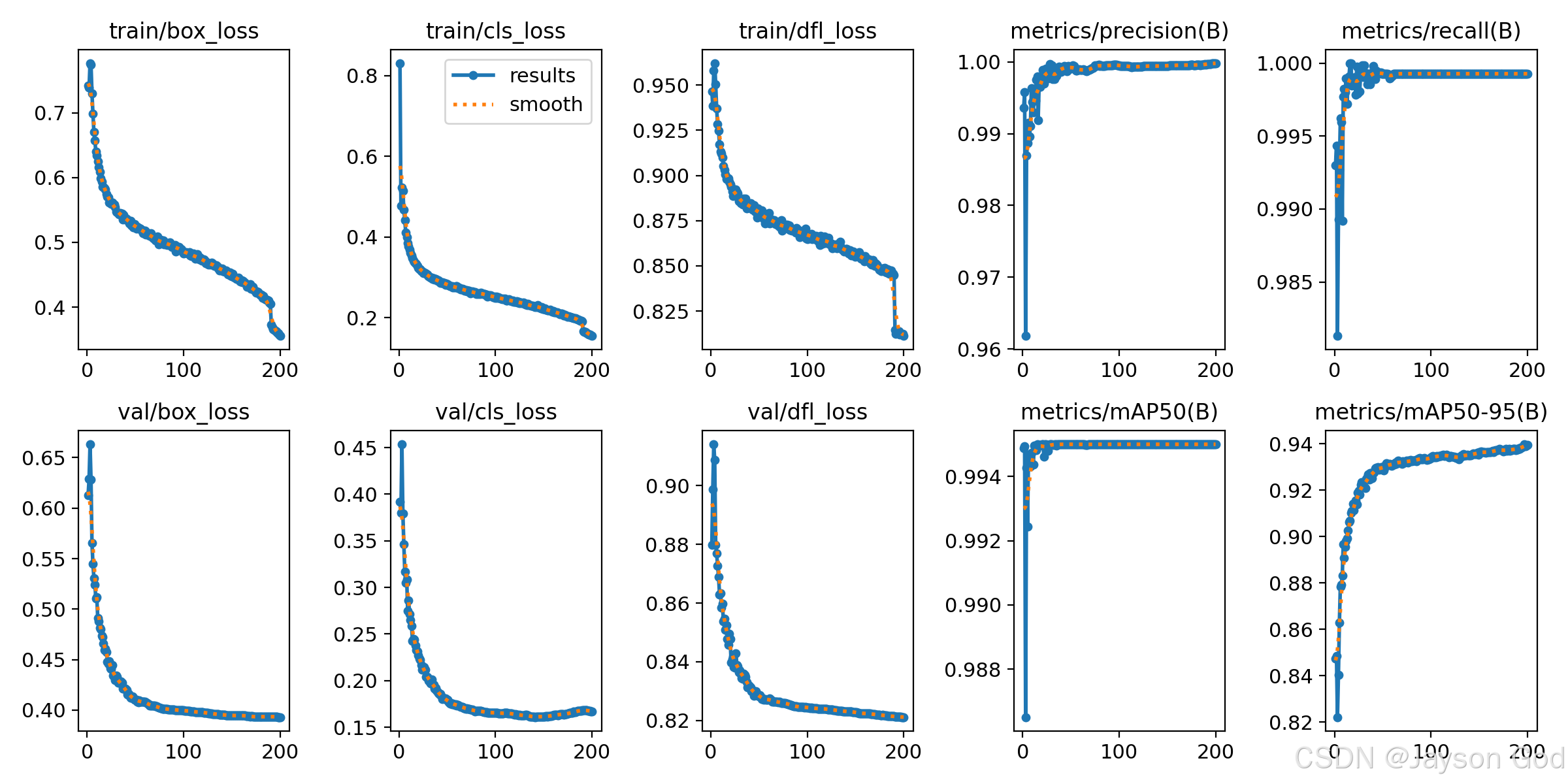
模型评估分析
| train/box_loss | 损失 | 所有训练样本 | 定位不准的平均代价 | 0.35565 | 持续平稳下降至极低水平 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.8 较差:1.8–2.5 差:> 2.5 | 优秀 |
| train/cls_loss | 损失 | 所有训练样本 | 分类错误的平均代价 | 0.15506 | 持续大幅下降至极低水平 | 优秀:< 0.5 良好:0.5–1.0 一般:1.0–1.8 较差:1.8–3.0 差:> 3.0 | 优秀 |
| train/dfl_loss | 损失 | 所有训练样本 | 坐标估计粗糙的代价 | 0.81125 | 平稳下降至较低水平 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.6 较差:1.6–2.0 差:> 2.0 | 优秀 |
| val/box_loss | 损失 | 所有验证样本 | 泛化定位误差 | 0.39308 | 持续下降且低于训练集水平 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.8 较差:1.8–2.5 差:> 2.5 | 优秀 |
| val/cls_loss | 损失 | 所有验证样本 | 泛化分类误差 | 0.16706 | 极低且整体稳定 | 优秀:< 0.5 良好:0.5–1.0 一般:1.0–1.8 较差:1.8–3.0 差:> 3.0 | 优秀 |
| val/dfl_loss | 损失 | 所有验证样本 | 泛化坐标误差 | 0.82111 | 与训练损失接近且稳定 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.6 较差:1.6–2.0 差:> 2.0 | 良好 |
| metrics/precision(B) | 指标 | 所有验证样本 | 整体查准率 | 0.99983 | 极高且稳定在 0.99+ | 优秀:≥ 0.85 良好:0.75–0.84 一般:0.60–0.74 较差:0.40–0.59 差:< 0.40 | 顶尖 |
| metrics/recall(B) | 指标 | 所有验证样本 | 整体查全率 | 0.99927 | 极高且趋于饱和 | 优秀:≥ 0.80 良好:0.70–0.79 一般:0.55–0.69 较差:0.35–0.54 差:< 0.35 | 顶尖 |
| metrics/mAP50(B) | 指标 | 每类 AP 平均 | 中等 IoU 下综合能力 | 0.995 | 极高且饱和 | 顶尖:≥ 0.85 优秀:0.75–0.84 良好:0.65–0.74 可用:0.50–0.64 较差:0.30–0.49 差:< 0.30 | 顶尖 |
| metrics/mAP50-95(B) | 指标 | 每类 AP@[0.5:0.95] 平均 | 严苛 IoU 下鲁棒性 | 0.93942 | 极高且持续提升 | 顶尖:≥ 0.50 优秀:0.40–0.49 良好:0.30–0.39 一般:0.20–0.29 较差:0.10–0.19 差:< 0.10 | 顶尖 |
总体评价
模型表现非常出色,在200个epochs的训练过程中各项指标持续优化,最终达到顶尖水平:
-
训练与验证损失均极低且平稳,未出现过拟合迹象;
-
所有关键性能指标(Precision、Recall、mAP50、mAP50-95)均接近或超过 0.99,说明模型在数据集上几乎完美地完成了检测任务;
-
模型泛化能力强,验证集性能与训练集几乎一致。
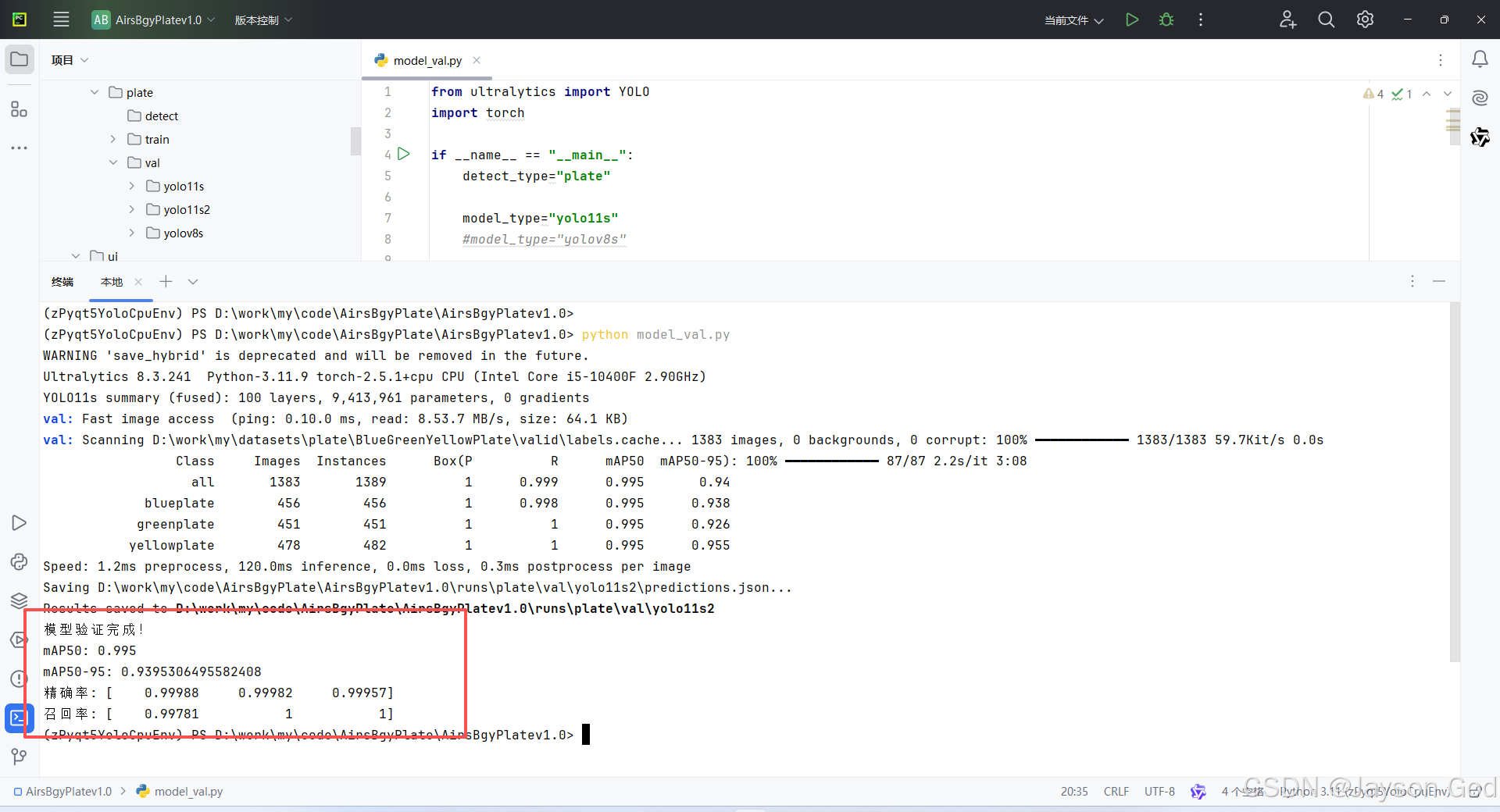
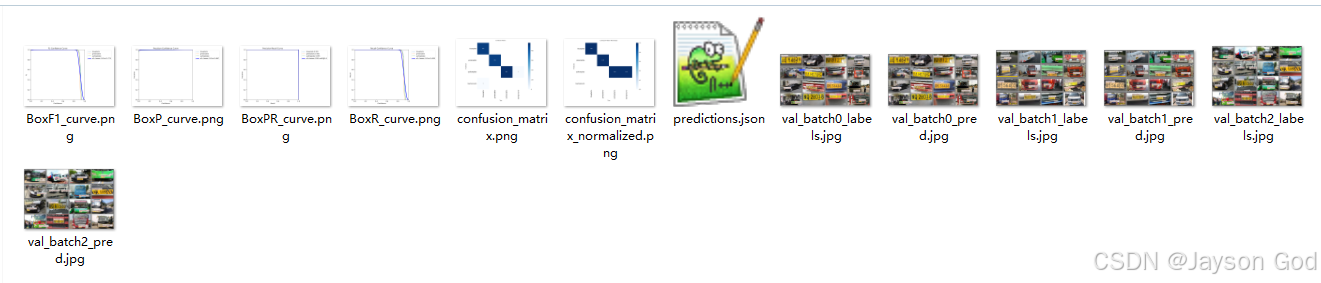
9.2、模型验证
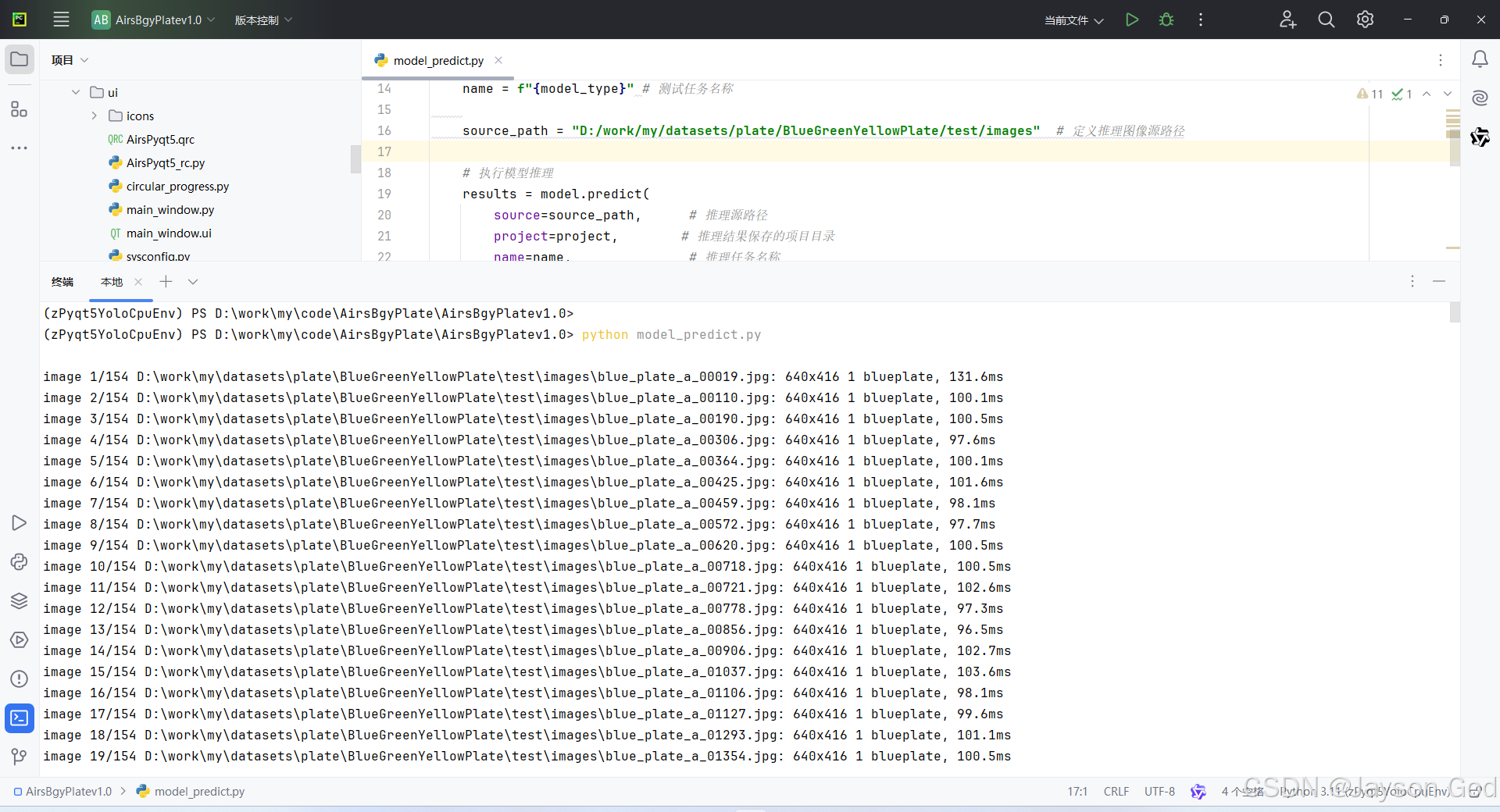
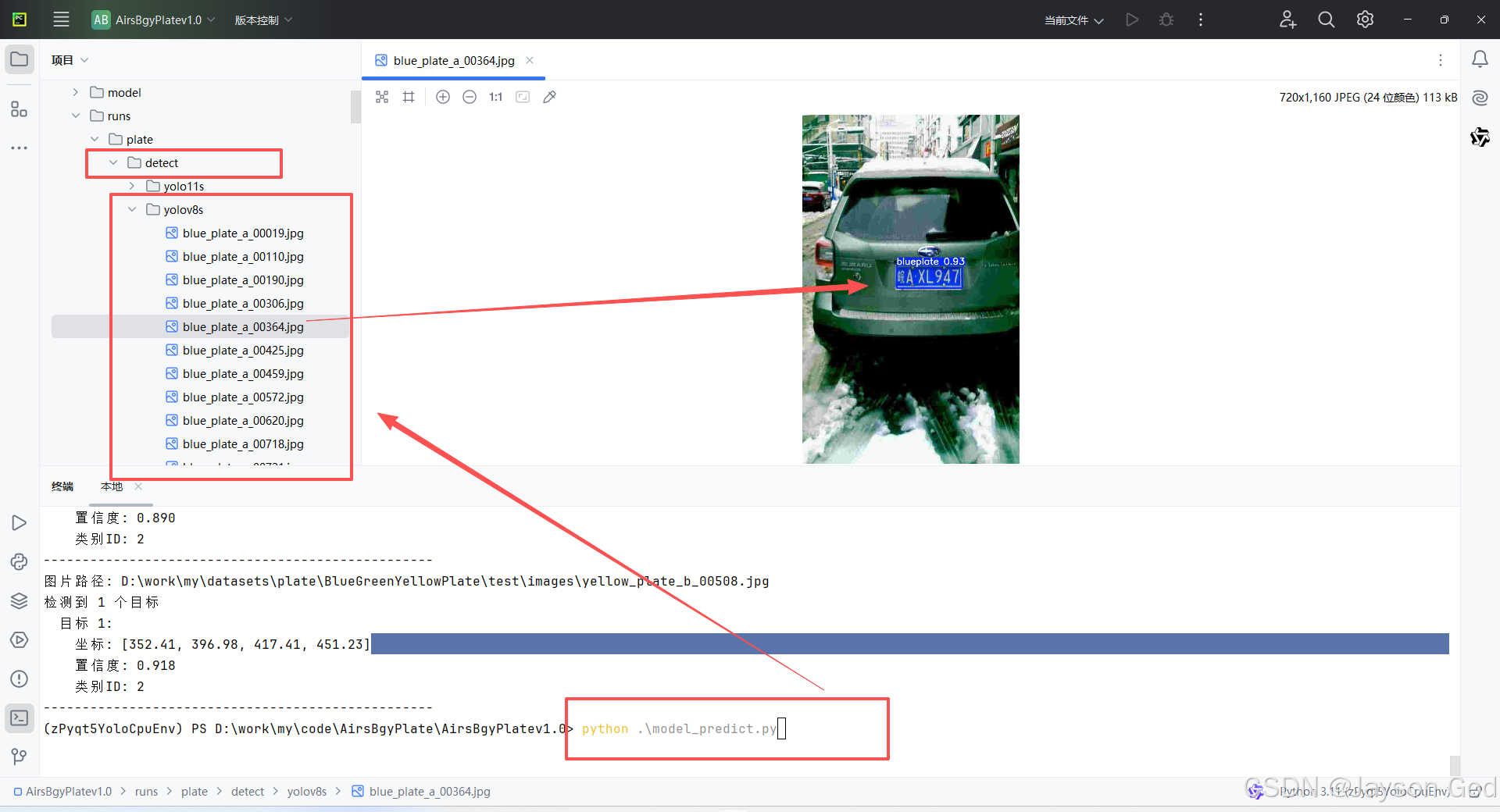
9.3、模型测试
10、YOLOv8s训练模型
10.1、模型评估
模型评估分析
| train/box_loss | 损失 | 所有训练样本 | 定位不准的平均代价 | 0.33578 | 持续下降至极低水平 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.8 较差:1.8–2.5 差:> 2.5 | 优秀 |
| train/cls_loss | 损失 | 所有训练样本 | 分类错误的平均代价 | 0.14739 | 快速下降至极低水平 | 优秀:< 0.5 良好:0.5–1.0 一般:1.0–1.8 较差:1.8–3.0 差:> 3.0 | 优秀 |
| train/dfl_loss | 损失 | 所有训练样本 | 坐标估计粗糙的代价 | 0.8064 | 平稳下降至优秀水平 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.6 较差:1.6–2.0 差:> 2.0 | 优秀 |
| val/box_loss | 损失 | 所有验证样本 | 泛化定位误差 | 0.39454 | 持续下降且稳定 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.8 较差:1.8–2.5 差:> 2.5 | 优秀 |
| val/cls_loss | 损失 | 所有验证样本 | 泛化分类误差 | 0.15627 | 极低且稳定 | 优秀:< 0.5 良好:0.5–1.0 一般:1.0–1.8 较差:1.8–3.0 差:> 3.0 | 优秀 |
| val/dfl_loss | 损失 | 所有验证样本 | 泛化坐标误差 | 0.82368 | 与训练损失接近 | 优秀:< 0.8 良好:0.8–1.2 一般:1.2–1.6 较差:1.6–2.0 差:> 2.0 | 良好 |
| metrics/precision(B) | 指标 | 所有验证样本 | 整体查准率 | 0.9992 | 极高且稳定在0.999+ | 优秀:≥ 0.85 良好:0.75–0.84 一般:0.60–0.74 较差:0.40–0.59 差:< 0.40 | 顶尖 |
| metrics/recall(B) | 指标 | 所有验证样本 | 整体查全率 | 0.99927 | 极高且饱和 | 优秀:≥ 0.80 良好:0.70–0.79 一般:0.55–0.69 较差:0.35–0.54 差:< 0.35 | 顶尖 |
| metrics/mAP50(B) | 指标 | 每类 AP 平均 | 中等 IoU 下综合能力 | 0.995 | 极高且稳定 | 顶尖:≥ 0.85 优秀:0.75–0.84 良好:0.65–0.74 可用:0.50–0.64 较差:0.30–0.49 差:< 0.30 | 顶尖 |
| metrics/mAP50-95(B) | 指标 | 每类 AP@[0.5:0.95] 平均 | 严苛 IoU 下鲁棒性 | 0.9381 | 极高且持续优化 | 顶尖:≥ 0.50 优秀:0.40–0.49 良好:0.30–0.39 一般:0.20–0.29 较差:0.10–0.19 差:< 0.10 | 顶尖 |
总体评价
这是一个训练非常成功、表现接近完美的模型,在200个epochs的训练过程中表现出以下特点:
损失持续下降且收敛良好:
-
所有训练和验证损失均稳步下降至极低水平
-
训练与验证损失差距极小,无过拟合迹象
-
在约190epochs后损失显著下降,显示模型学习能力持续增强
性能指标达到顶尖水平:
-
Precision、Recall、mAP50均接近1.0,说明模型几乎能准确识别并覆盖所有目标
-
mAP50-95高达0.9381,表明模型在严苛的IoU要求下仍保持极强鲁棒性
训练过程稳定:
-
学习率按计划逐步下降,训练稳定
-
各项指标在后期保持平稳,无明显波动
10.2、模型验证
10.3、模型测试

11、链接
| 描述 | 链接 |
| 数据集链接 | 中国蓝/黄/绿车牌检测数据集(按比例划分训练、验证、测试)包含训练好的yolo11/yolov8模型 |
| 配套测试软件 | 【目标检测软件 04】基于 YOLO 目标检测与 LPRNet/OCR 车牌识别的一体化系统 (含 PyQt5 可视化界面、25 万张标注数据集、完整训练模型及 Python 源码-毕设推荐项目)-CSDN博客 |
| 往期回顾 | 链接 |
| 标注工具 | 【标注工具 01】labelfast标注工具使用指南(支持YOLO\\COCO\\VOC格式)-CSDN博客 |
| 通用版检测软件1 | 【目标检测软件 01】YOLO识别软件功能与操作指南_yolo软件-CSDN博客 |
| 通用版检测软件2 | 【目标检测软件 02】AirsPy 目标检测系统操作指南-CSDN博客 |
| 烟火检测 | 【目标检测软件 03】基于yolo的室内烟火识别系统(含Python源码、UI界面、数据集、训练模型与代码-毕设推荐项目)_火焰识别数据集-CSDN博客 |
| 【数据集 01】家庭室内烟火数据集(按比例划分训练、验证、测试)包含训练好的yolo11/yolov8模型_yolo烟火训练集-CSDN博客 | |
| 参考 | 链接 |
| 详细介绍YOLO | 【深度学习02】YOLO模型的数据集、训练、验证、预测、导出_yolomap计算公式使用验证集还是训练集-CSDN博客 |




评论前必须登录!
注册