 网硕互联帮助中心
网硕互联帮助中心背景意义
研究背景与意义
随着工业自动化和智能制造的迅速发展,精确的零部件识别与分类在生产流程中变得愈发重要。螺栓作为机械连接中不可或缺的基本元件,其尺寸识别对于确保产品质量和装配精度具有重要意义。传统的螺栓尺寸识别方法往往依赖于人工检测或简单的图像处理技术,这不仅效率低下,而且容易受到人为因素的影响,导致识别准确率低下。因此,基于深度学习的计算机视觉技术在螺栓尺寸识别中的应用显得尤为必要。
YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而广受欢迎。YOLOv11作为该系列的最新版本,结合了更先进的网络结构和算法优化,能够在保持高精度的同时显著提高检测速度。通过对YOLOv11进行改进,特别是在实例分割任务中的应用,可以实现对螺栓尺寸的精确识别与分割,从而为后续的自动化装配和质量控制提供有力支持。
本研究基于一个包含1500张图像的螺栓数据集,涵盖了M6和M8两种螺栓类别,旨在构建一个高效的螺栓尺寸识别实例分割系统。该数据集经过精心标注,能够为模型训练提供丰富的样本,确保模型在实际应用中的鲁棒性和准确性。通过对YOLOv11的改进,期望能够提升模型在复杂背景下的识别能力,进而推动智能制造领域的技术进步。
综上所述,基于改进YOLOv11的螺栓尺寸识别实例分割系统的研究,不仅能够提升工业生产中的自动化水平,还能为相关领域的研究提供新的思路和方法,具有重要的理论价值和实际应用意义。
图片效果
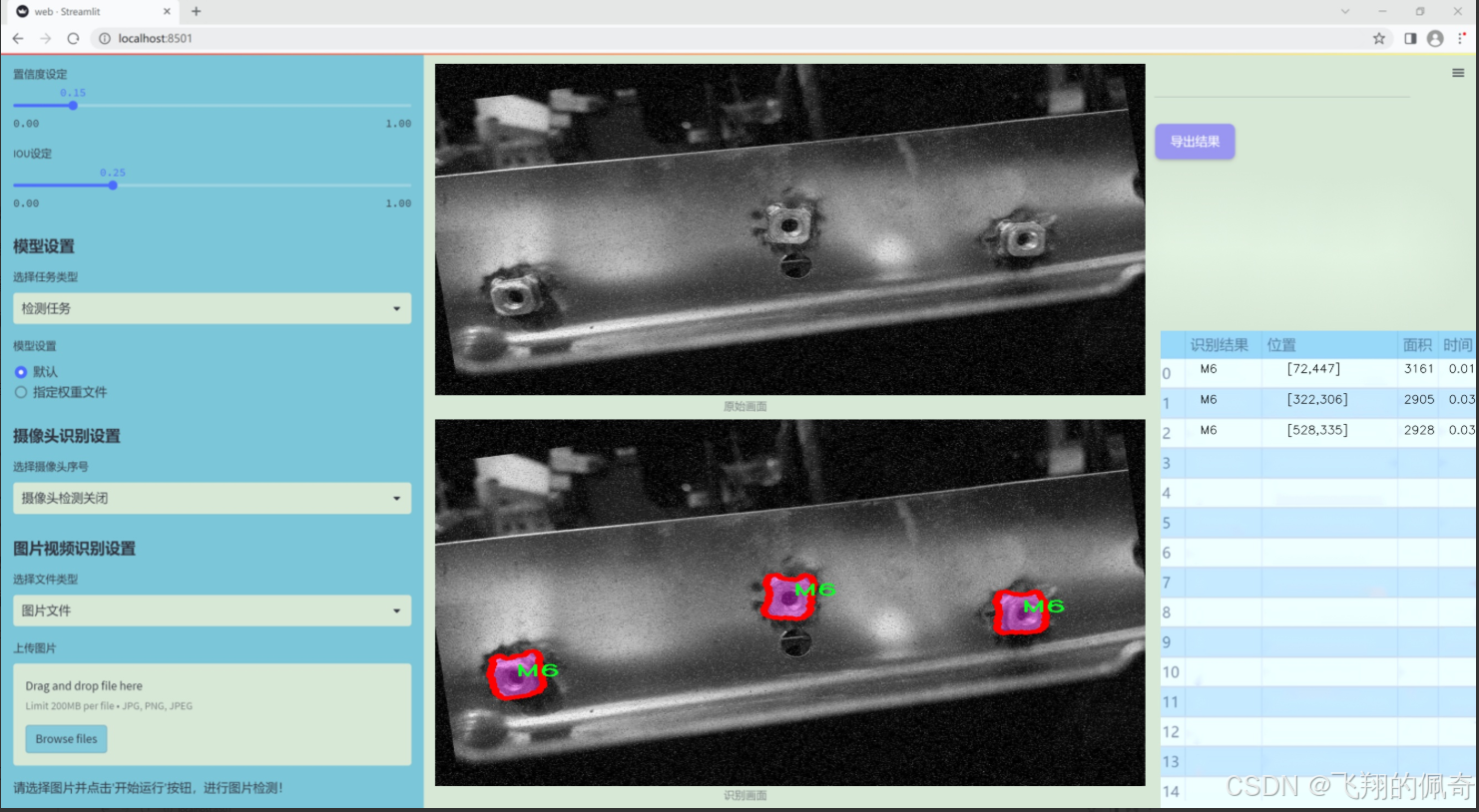
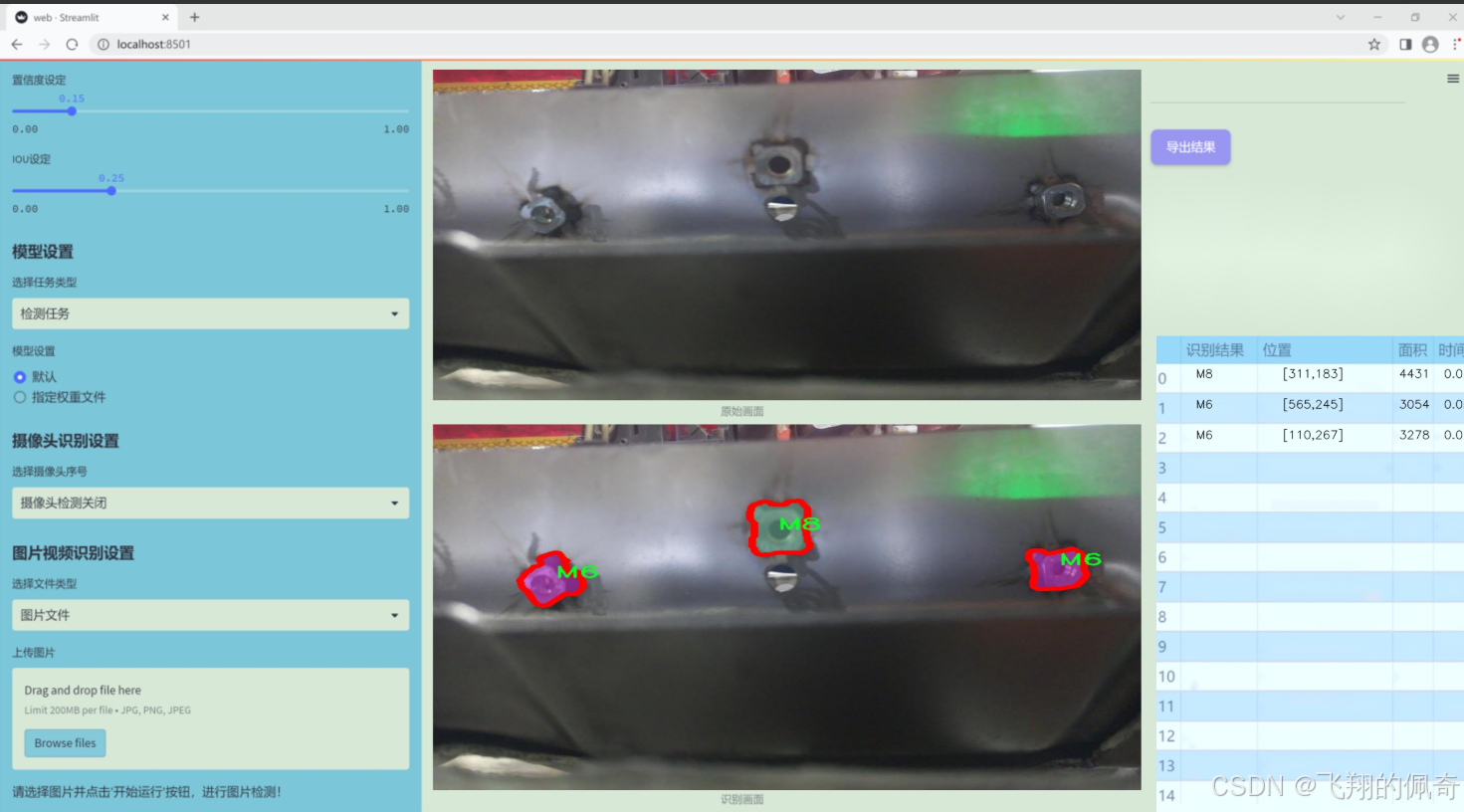
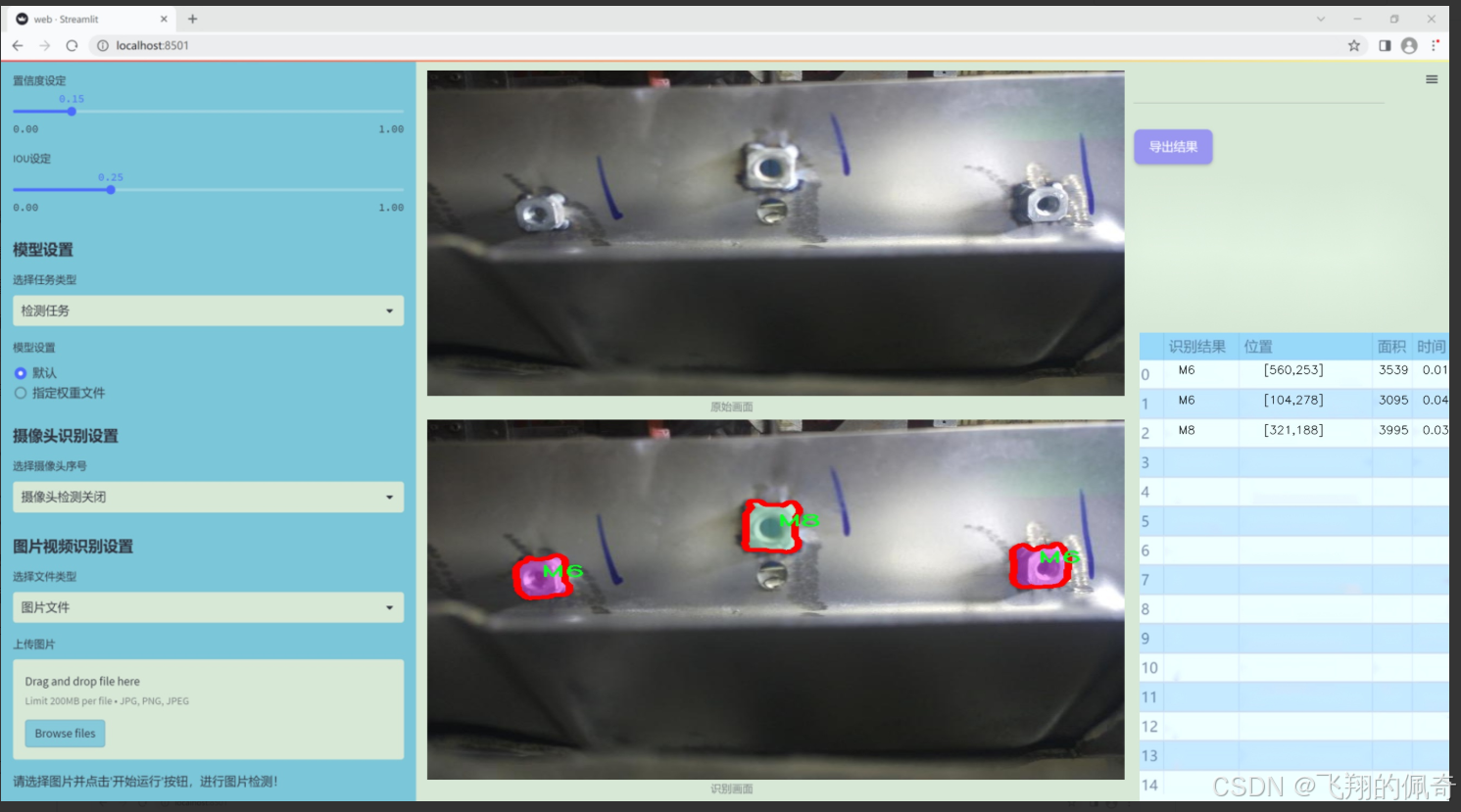
数据集信息
本项目数据集信息介绍
本项目旨在开发一个改进版的YOLOv11模型,以实现高效的螺栓尺寸识别和实例分割。为此,我们构建了一个专门的数据集,涵盖了两种主要类别的螺栓:M6和M8。这两种螺栓广泛应用于机械工程和建筑领域,因其在连接和固定结构中的重要性而备受关注。数据集的构建过程经过精心设计,确保了数据的多样性和代表性,以便模型能够在实际应用中表现出色。
数据集包含了大量的图像样本,这些样本在不同的光照条件、背景环境和角度下拍摄,力求覆盖螺栓在实际使用中可能遇到的各种情况。每个图像都经过标注,明确指出了M6和M8螺栓的位置和尺寸信息。这种细致的标注不仅有助于模型的训练,也为后续的实例分割任务提供了可靠的基础。
在数据集的构建过程中,我们特别关注了图像的质量和标注的准确性。每个类别的样本数量经过精心平衡,以避免模型在训练过程中出现偏倚现象。此外,数据集还包括了一些难度较大的样本,例如在复杂背景下的螺栓图像,这将有助于提高模型的鲁棒性和泛化能力。
通过对该数据集的训练,我们期望改进YOLOv11在螺栓尺寸识别和实例分割任务中的性能,使其能够更准确地识别和分割不同尺寸的螺栓。这将为工业自动化和智能制造提供强有力的技术支持,推动相关领域的进一步发展。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
定义一个自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# 初始化一个可学习的参数 alpha,初始值为 1
self.alpha = nn.Parameter(torch.ones(1))
# 初始化一个一维批量归一化层
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):
# 将输入的维度进行转置,交换第1维和第2维
x = x.transpose(1, 2)
# 进行批量归一化,并加上 alpha 乘以输入 x
x = self.bn(x) + self.alpha * x
# 再次转置回原来的维度
x = x.transpose(1, 2)
return x
定义一个线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册缓冲区,用于存储 warm-up 计数器
self.register_buffer(‘warm’, torch.tensor(warm))
# 注册缓冲区,用于存储迭代次数
self.register_buffer(‘iter’, torch.tensor(step))
# 注册缓冲区,用于存储总的迭代步数
self.register_buffer(‘total_step’, torch.tensor(step))
self.r0 = r0 # 初始比例因子
# 初始化两个归一化层
self.norm1 = norm1(dim)
self.norm2 = norm2(dim)
def forward(self, x):
# 如果模型处于训练模式
if self.training:
# 如果还有 warm-up 步骤
if self.warm > 0:
# 减少 warm-up 步骤计数
self.warm.copy_(self.warm – 1)
# 进行第一次归一化
x = self.norm1(x)
else:
# 计算当前的比例因子 lamda
lamda = self.r0 * self.iter / self.total_step
# 减少迭代次数
if self.iter > 0:
self.iter.copy_(self.iter – 1)
# 进行两次归一化
x1 = self.norm1(x)
x2 = self.norm2(x)
# 按照 lamda 加权合并两个归一化结果
x = lamda * x1 + (1 – lamda) * x2
else:
# 如果模型处于评估模式,直接使用第二个归一化
x = self.norm2(x)
return x
代码核心部分说明:
RepBN 类:实现了一个自定义的批量归一化层,增加了一个可学习的参数 alpha,用于调整归一化的输出。
LinearNorm 类:实现了一个线性归一化机制,支持 warm-up 和动态调整归一化的方式。根据训练的进度动态选择使用两种不同的归一化方法的加权组合。
这个程序文件定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都继承自 PyTorch 的 nn.Module 类。
RepBN 类实现了一种自定义的批量归一化(Batch Normalization)方法。它的构造函数接受一个参数 channels,表示输入数据的通道数。在构造函数中,定义了一个可学习的参数 alpha,初始值为 1,并创建了一个标准的批量归一化层 bn。在前向传播方法 forward 中,输入 x 首先进行维度转换,将通道维和时间维进行交换,然后通过批量归一化层进行处理,最后将归一化后的结果与 alpha 乘以原始输入相加,再次进行维度转换,返回处理后的结果。这种设计使得模型在进行批量归一化的同时,保留了输入信息的某些特征。
LinearNorm 类则实现了一种线性归一化的方法。它的构造函数接受多个参数,包括 dim(维度)、norm1 和 norm2(分别是两种归一化方法)、warm(预热步数)、step(当前步数)和 r0(初始比例)。在构造函数中,使用 register_buffer 方法注册了一些缓冲区,用于存储预热步数和当前步数等信息。前向传播方法 forward 中,首先检查模型是否处于训练状态。如果是训练状态且预热步数大于 0,则进行第一次归一化 norm1,并减少预热步数。如果预热结束,则根据当前步数计算一个比例 lamda,并根据这个比例对输入 x 进行两种归一化方法 norm1 和 norm2 的加权组合。如果模型不在训练状态,则直接使用 norm2 对输入进行归一化处理。这样设计的目的是在训练过程中逐步调整归一化的方式,以提高模型的性能。
整体来看,这个文件实现了两种自定义的归一化方法,分别适用于不同的场景,增强了模型的灵活性和表达能力。
10.4 afpn.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv
class BasicBlock(nn.Module):
“”“基本块,包含两个卷积层和残差连接”“”
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 第一个卷积层,使用3×3卷积
self.conv1 = Conv(filter_in, filter_out, 3)
# 第二个卷积层,使用3×3卷积,不使用激活函数
self.conv2 = Conv(filter_out, filter_out, 3, act=False)
def forward(self, x):
residual = x # 保存输入以便进行残差连接
out = self.conv1(x) # 通过第一个卷积层
out = self.conv2(out) # 通过第二个卷积层
out += residual # 添加残差
return self.conv1.act(out) # 通过激活函数返回结果
class Upsample(nn.Module):
“”“上采样模块,使用1×1卷积和双线性插值”“”
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1), # 1×1卷积
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’) # 双线性插值上采样
)
def forward(self, x):
return self.upsample(x) # 返回上采样后的结果
class Downsample_x2(nn.Module):
“”“下采样模块,使用2×2卷积”“”
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
self.downsample = Conv(in_channels, out_channels, 2, 2, 0) # 2×2卷积,步幅为2
def forward(self, x):
return self.downsample(x) # 返回下采样后的结果
class ASFF_2(nn.Module):
“”“自适应特征融合模块,融合两个输入特征图”“”
def init(self, inter_dim=512):
super(ASFF_2, self).init()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
# 用于计算权重的卷积层
self.weight_level_1 = Conv(self.inter_dim, compress_c, 1)
self.weight_level_2 = Conv(self.inter_dim, compress_c, 1)
self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)
self.conv = Conv(self.inter_dim, self.inter_dim, 3) # 最后的卷积层
def forward(self, input1, input2):
# 计算输入特征图的权重
level_1_weight_v = self.weight_level_1(input1)
level_2_weight_v = self.weight_level_2(input2)
# 合并权重并计算最终权重
levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1) # 归一化权重
# 融合特征图
fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \\
input2 * levels_weight[:, 1:2, :, :]
out = self.conv(fused_out_reduced) # 通过卷积层
return out # 返回融合后的特征图
class BlockBody_P345(nn.Module):
“”“特征块体,处理三个不同尺度的特征图”“”
def init(self, channels=[64, 128, 256, 512]):
super(BlockBody_P345, self).init()
# 初始化不同尺度的卷积块
self.blocks_scalezero1 = nn.Sequential(Conv(channels[0], channels[0], 1))
self.blocks_scaleone1 = nn.Sequential(Conv(channels[1], channels[1], 1))
self.blocks_scaletwo1 = nn.Sequential(Conv(channels[2], channels[2], 1))
# 下采样和上采样模块
self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])
self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)
# 自适应特征融合模块
self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])
self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])
# 定义更多的卷积块和下采样/上采样操作…
def forward(self, x):
x0, x1, x2 = x # 输入三个不同尺度的特征图
# 处理每个尺度的特征图
x0 = self.blocks_scalezero1(x0)
x1 = self.blocks_scaleone1(x1)
x2 = self.blocks_scaletwo1(x2)
# 融合特征图
scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))
scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)
# 返回处理后的特征图
return x0, x1, x2
class AFPN_P345(nn.Module):
“”“自适应特征金字塔网络,处理三个输入特征图”“”
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 初始化卷积层
self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)
self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)
self.conv2 = Conv(in_channels[2], in_channels[2] // factor, 1)
# 特征块体
self.body = BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor, in_channels[2] // factor])
# 输出卷积层
self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)
self.conv11 = Conv(in_channels[1] // factor, out_channels, 1)
self.conv22 = Conv(in_channels[2] // factor, out_channels, 1)
def forward(self, x):
x0, x1, x2 = x # 输入三个特征图
# 通过卷积层处理特征图
x0 = self.conv0(x0)
x1 = self.conv1(x1)
x2 = self.conv2(x2)
# 通过特征块体处理特征图
out0, out1, out2 = self.body([x0, x1, x2])
# 通过输出卷积层处理特征图
out0 = self.conv00(out0)
out1 = self.conv11(out1)
out2 = self.conv22(out2)
return [out0, out1, out2] # 返回处理后的特征图
代码说明:
BasicBlock: 这是一个基本的卷积块,包含两个卷积层和一个残差连接。
Upsample: 这个模块用于上采样特征图,使用1×1卷积和双线性插值。
Downsample_x2: 这个模块用于下采样特征图,使用2×2卷积。
ASFF_2: 自适应特征融合模块,用于融合两个输入特征图,计算它们的权重并进行加权融合。
BlockBody_P345: 处理三个不同尺度特征图的模块,包含多个卷积块和自适应特征融合模块。
AFPN_P345: 自适应特征金字塔网络,处理三个输入特征图并输出融合后的特征图。
以上是核心部分的代码和详细注释,帮助理解每个模块的功能和作用。
这个程序文件afpn.py实现了一种特征金字塔网络(FPN)的结构,主要用于计算机视觉任务,尤其是目标检测和分割。该网络通过多尺度特征融合来提高模型的性能。文件中定义了多个类,每个类实现了网络的不同部分和功能。
首先,文件导入了一些必要的库,包括torch和torch.nn,以及一些自定义的模块,如Conv和不同的块(C2f, C3, C3Ghost, C3k2)。这些模块提供了构建网络所需的基本操作。
BasicBlock类是一个基本的卷积块,包含两个卷积层和一个残差连接。通过残差连接,输入可以直接加到输出上,有助于缓解深层网络的训练问题。
Upsample和Downsample_x2, Downsample_x4, Downsample_x8类分别实现了上采样和不同倍数的下采样操作。这些操作在特征融合时非常重要,因为它们允许网络在不同的尺度上进行特征提取和融合。
ASFF_2, ASFF_3, 和 ASFF_4类实现了自适应特征融合模块(ASFF),它们根据输入特征的权重进行加权融合。每个类对应不同数量的输入特征图(2、3或4个),通过学习的权重来决定如何融合这些特征图,从而提高模型的表达能力。
BlockBody_P345和BlockBody_P2345类分别实现了包含多个卷积块和自适应特征融合模块的网络主体。它们使用不同的通道数和层次结构来处理不同数量的输入特征图(3个或4个)。在这些类中,特征图经过多个卷积块和ASFF模块的处理,最终输出融合后的特征图。
AFPN_P345和AFPN_P2345类是网络的顶层结构,负责将输入特征图进行处理并输出最终的特征图。它们首先通过卷积层降低通道数,然后将处理后的特征图传递给对应的BlockBody类进行进一步处理。最终,输出的特征图通过卷积层调整到指定的输出通道数。
此外,AFPN_P345_Custom和AFPN_P2345_Custom类允许用户自定义卷积块的类型,提供了更大的灵活性,以适应不同的任务需求。
整体来看,这个程序文件实现了一个灵活且高效的特征金字塔网络结构,能够在多尺度上提取和融合特征,适用于各种计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式







评论前必须登录!
注册