 网硕互联帮助中心
网硕互联帮助中心背景意义
研究背景与意义
眼底图像分析在医学影像学中扮演着至关重要的角色,尤其是在早期诊断和监测眼科疾病方面。随着人口老龄化的加剧,眼科疾病的发病率逐年上升,尤其是糖尿病视网膜病变、黄斑变性等疾病,给患者的视力健康带来了严重威胁。因此,开发高效、准确的眼底图像分析系统,尤其是层次分割技术,显得尤为重要。层次分割能够帮助医生清晰地识别和定位眼底图像中的各个结构,进而提高诊断的准确性和效率。
本研究旨在基于改进的YOLOv11模型,构建一个高效的眼底图像层次分割系统。该系统将利用oct5k_new_new数据集,该数据集包含4600幅眼底图像,涵盖了6个不同的类别,包括内界膜(ILM)、视网膜色素上皮(RPE)、外层(OPL)等。这些类别的准确分割对于疾病的诊断和治疗方案的制定至关重要。通过对这些图像进行深度学习训练,系统将能够自动识别和分割出眼底图像中的关键结构,减轻医生的工作负担,提高诊断效率。
此外,数据集经过多种数据增强处理,极大地丰富了训练样本的多样性,提升了模型的泛化能力。这种方法不仅可以提高模型在实际应用中的表现,还能为后续的研究提供坚实的数据基础。随着深度学习技术的不断进步,基于YOLOv11的眼底图像层次分割系统将为眼科医学提供新的解决方案,推动眼底疾病的早期诊断和治疗进程,具有重要的临床应用价值和社会意义。
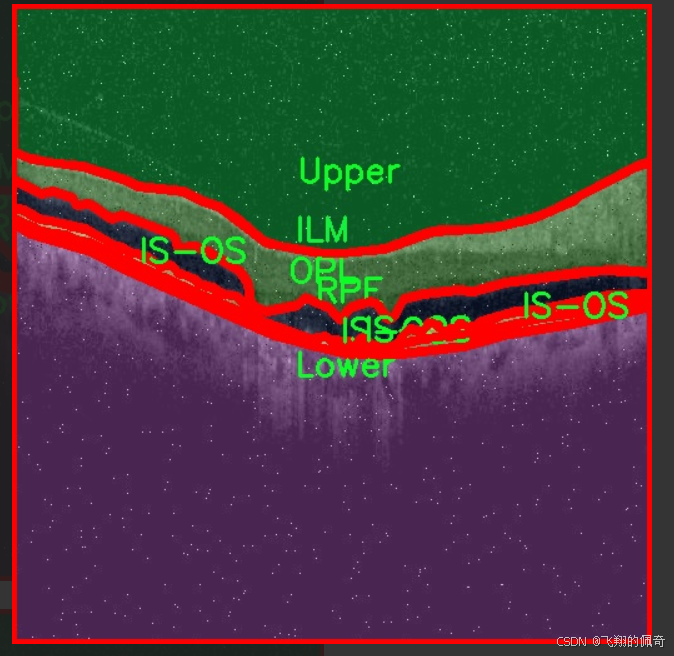
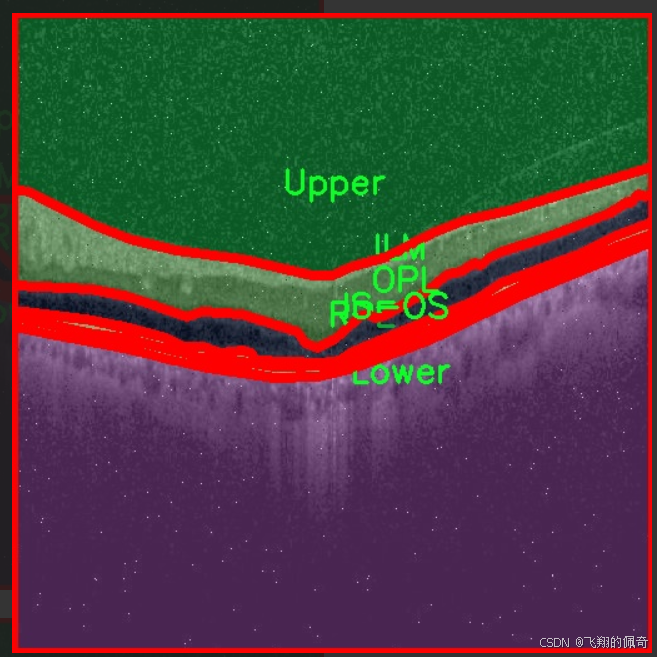
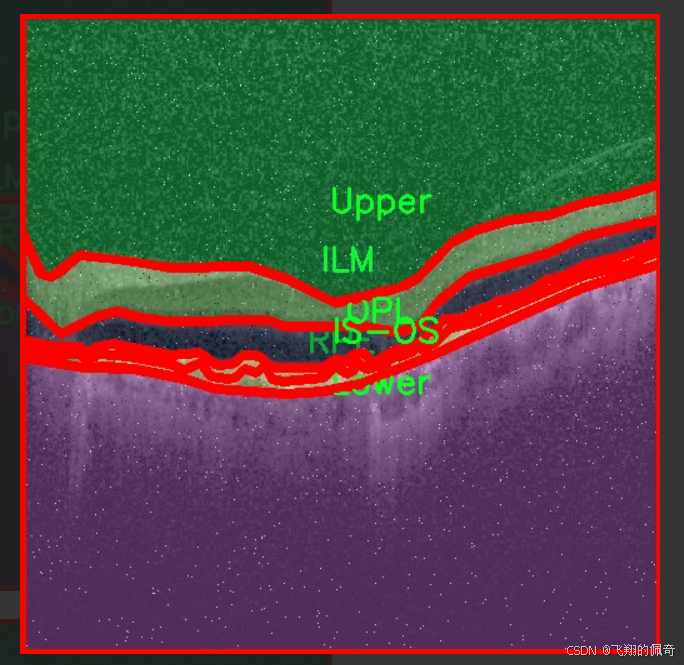
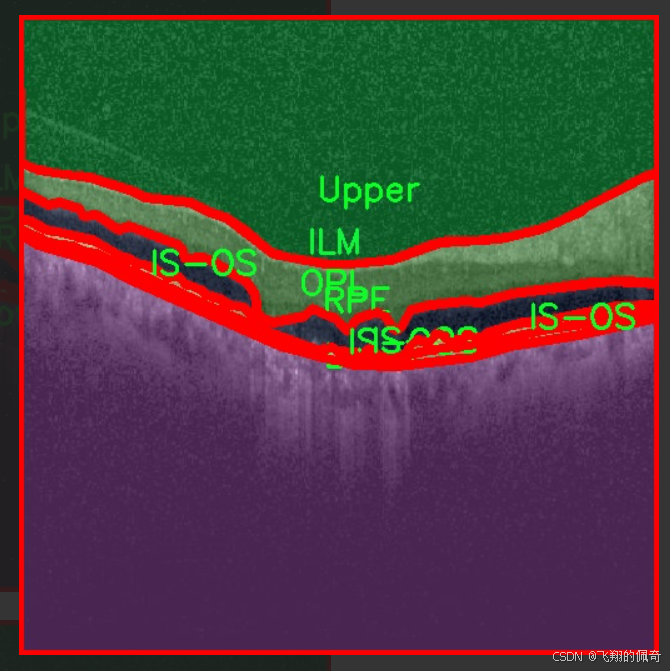
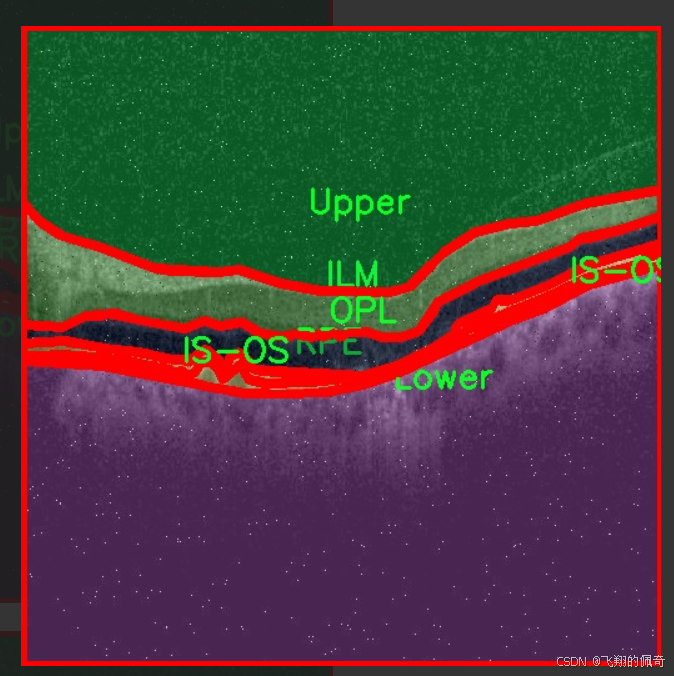
图片效果
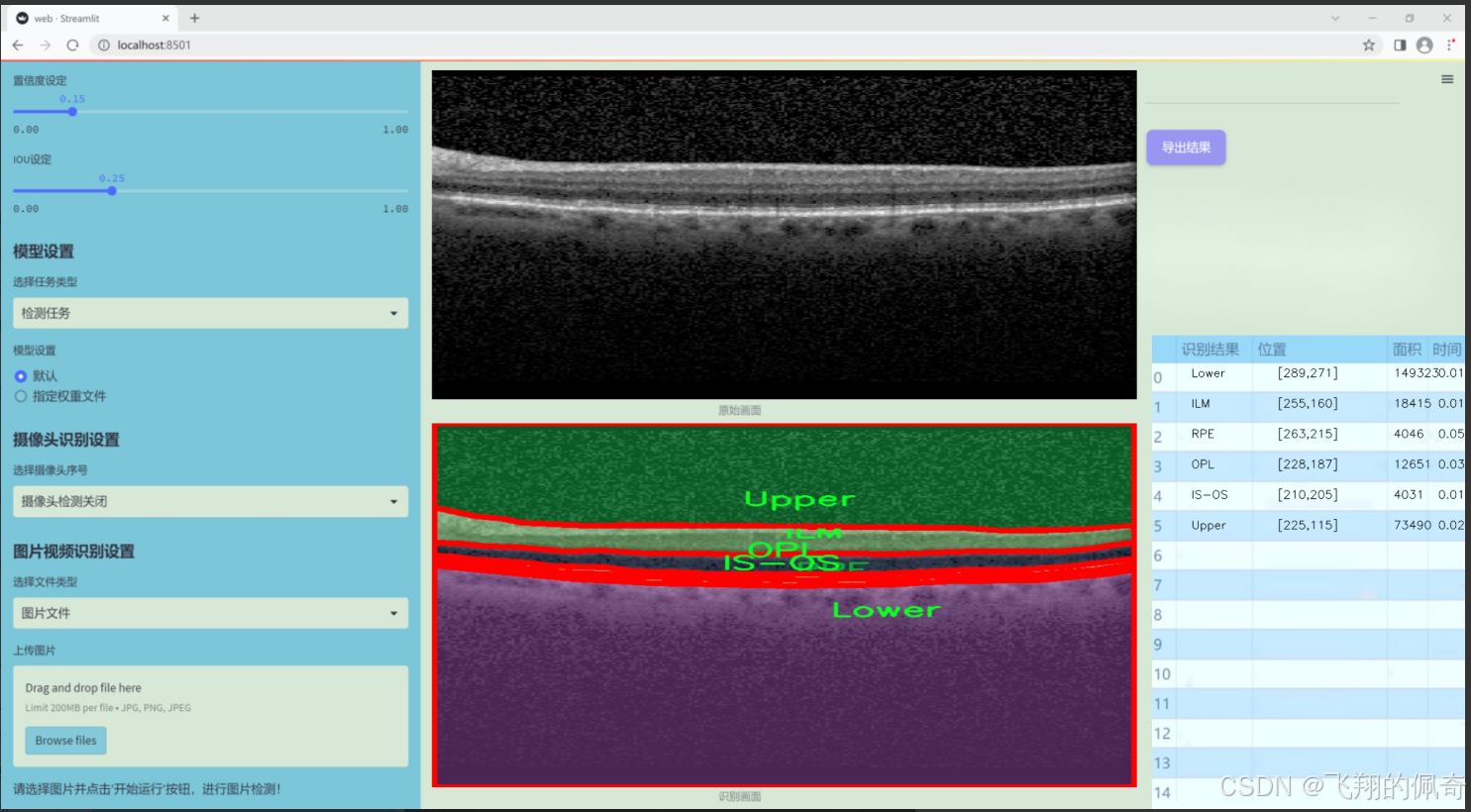
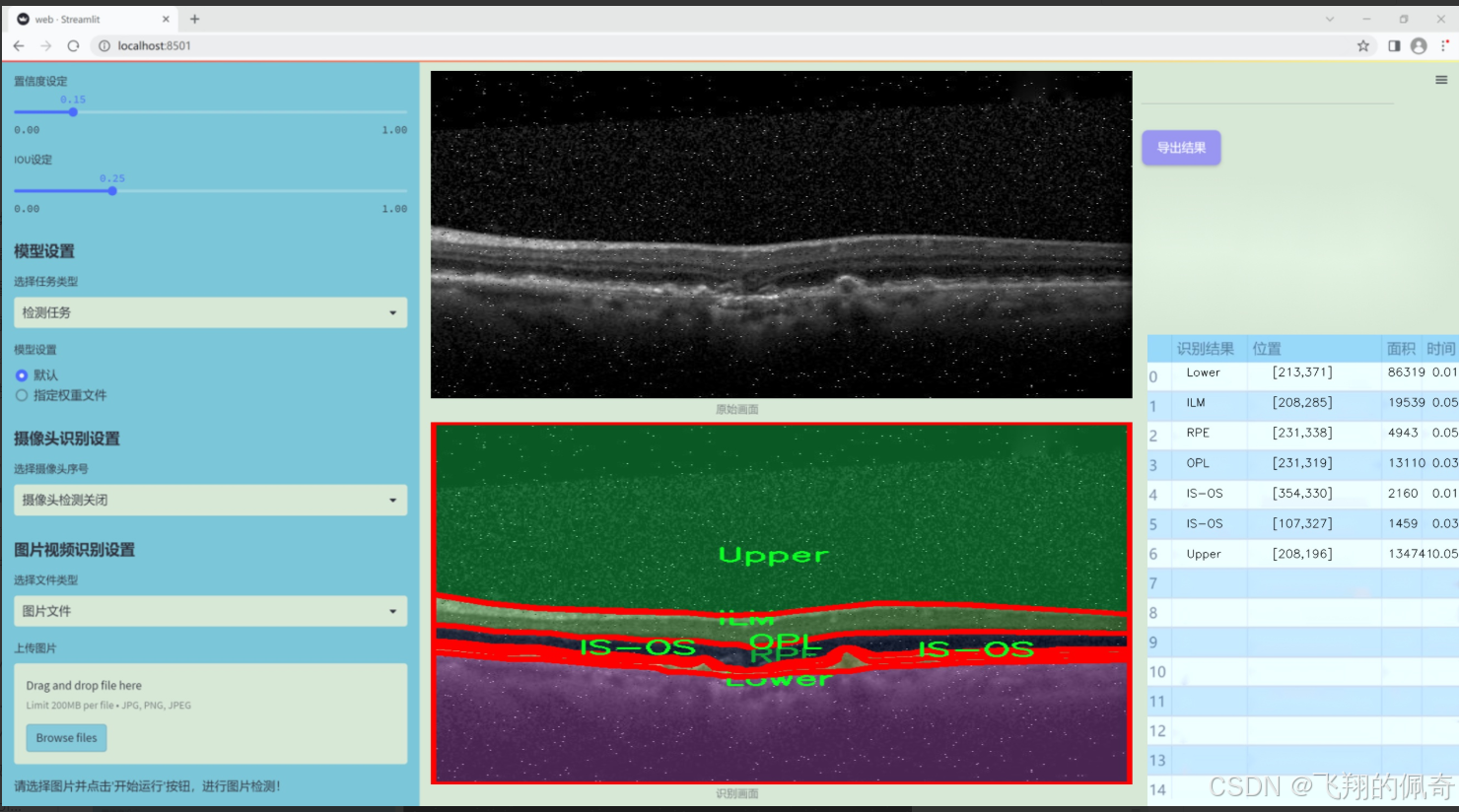
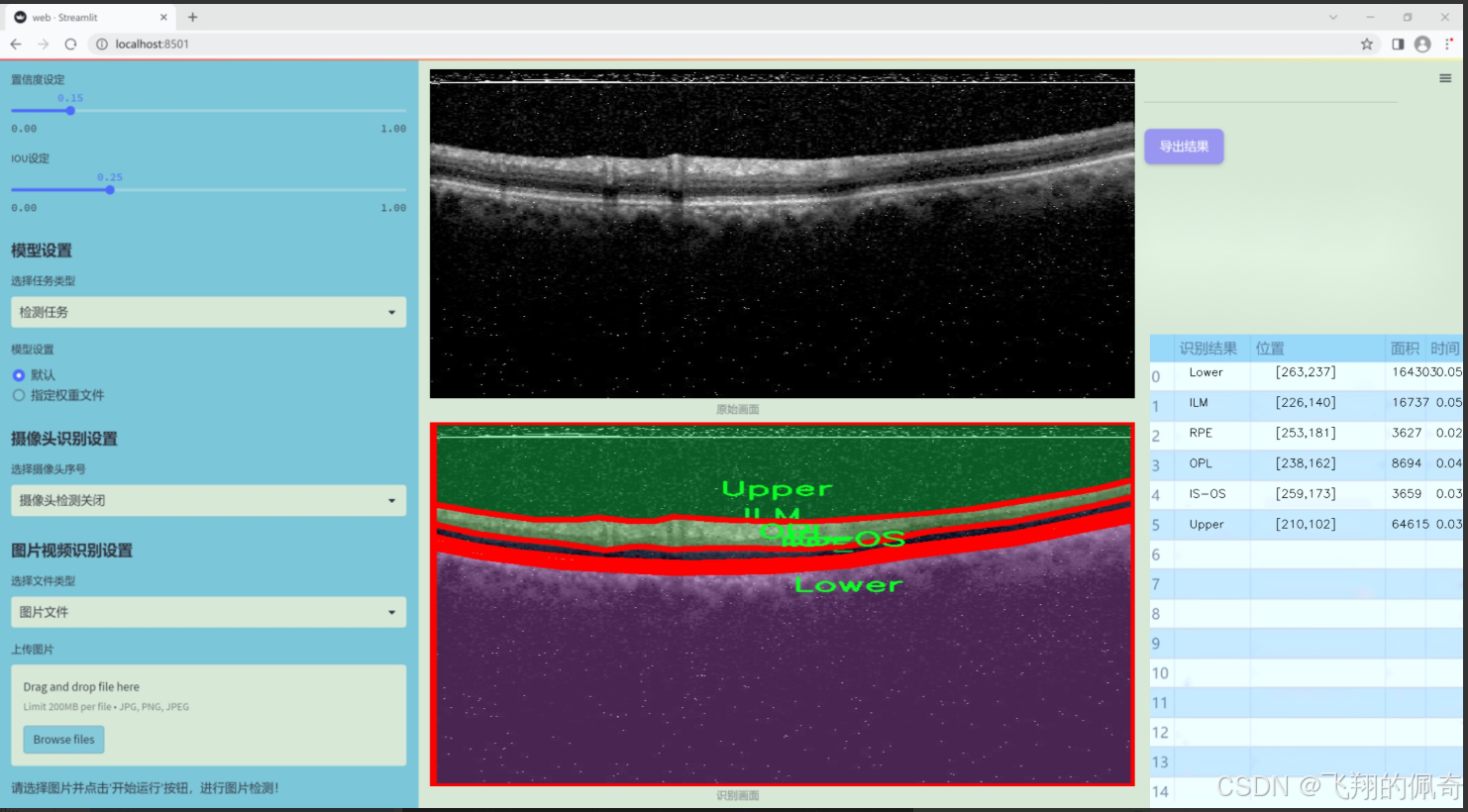
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“oct5k_new_new”,旨在为改进YOLOv11的眼底图像层次分割系统提供高质量的训练数据。该数据集专注于眼底图像的分割任务,包含了六个主要类别,分别为内界膜(ILM)、光感受器层与视网膜色素上皮层(IS-OS)、下层(Lower)、外核层(OPL)、视网膜色素上皮层(RPE)以及上层(Upper)。这些类别涵盖了眼底图像中重要的解剖结构,对于眼科疾病的诊断和治疗具有重要意义。
在数据集的构建过程中,所有图像均经过精心标注,以确保每个类别的分割边界清晰且准确。这种高质量的标注不仅提高了模型训练的有效性,也为后续的验证和测试提供了可靠的基础。数据集中的图像样本来自多种不同的眼底扫描,涵盖了不同年龄段和病理状态的患者,从而增强了模型的泛化能力和适应性。
此外,数据集的多样性使得模型能够学习到不同解剖结构在不同条件下的表现,进一步提升了分割精度。通过使用“oct5k_new_new”数据集,研究人员希望能够推动眼底图像分析技术的发展,尤其是在自动化分割和疾病检测方面的应用。最终目标是实现更为精准的眼底图像分析,以辅助临床医生进行早期诊断和个性化治疗方案的制定。数据集的设计和实施为本项目的成功奠定了坚实的基础,期待通过这一研究为眼科领域带来新的突破。
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import SqueezeExcite
定义卷积层和批归一化的组合
class Conv2d_BN(torch.nn.Sequential):
def init(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bn_weight_init=1):
super().init()
# 添加卷积层
self.add_module(‘c’, torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False))
# 添加批归一化层
self.add_module(‘bn’, torch.nn.BatchNorm2d(out_channels))
# 初始化批归一化的权重
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def switch_to_deploy(self):
# 将训练模式的卷积和批归一化层融合为一个卷积层
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5 # 计算新的权重
w = c.weight * w[:, None, None, None] # 融合权重
b = bn.bias – bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5 # 计算新的偏置
# 创建新的卷积层
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w) # 复制权重
m.bias.data.copy_(b) # 复制偏置
return m
定义EfficientViT的基本模块
class EfficientViTBlock(torch.nn.Module):
def init(self, embed_dim, key_dim, num_heads=8, window_resolution=7):
super().init()
# 定义卷积层和前馈网络
self.dw0 = Residual(Conv2d_BN(embed_dim, embed_dim, 3, 1, 1, groups=embed_dim))
self.ffn0 = Residual(FFN(embed_dim, int(embed_dim * 2)))
self.mixer = Residual(LocalWindowAttention(embed_dim, key_dim, num_heads, window_resolution=window_resolution))
self.dw1 = Residual(Conv2d_BN(embed_dim, embed_dim, 3, 1, 1, groups=embed_dim))
self.ffn1 = Residual(FFN(embed_dim, int(embed_dim * 2)))
def forward(self, x):
# 前向传播
return self.ffn1(self.dw1(self.mixer(self.ffn0(self.dw0(x)))))
定义EfficientViT模型
class EfficientViT(torch.nn.Module):
def init(self, img_size=400, patch_size=16, embed_dim=[64, 128, 192], depth=[1, 2, 3], num_heads=[4, 4, 4], window_size=[7, 7, 7]):
super().init()
# 定义图像嵌入层
self.patch_embed = torch.nn.Sequential(
Conv2d_BN(3, embed_dim[0] // 8, 3, 2, 1),
nn.ReLU(),
Conv2d_BN(embed_dim[0] // 8, embed_dim[0] // 4, 3, 2, 1),
nn.ReLU(),
Conv2d_BN(embed_dim[0] // 4, embed_dim[0] // 2, 3, 2, 1),
nn.ReLU(),
Conv2d_BN(embed_dim[0] // 2, embed_dim[0], 3, 1, 1)
)
# 定义多个EfficientViTBlock
self.blocks = []
for i in range(len(depth)):
for _ in range(depth[i]):
self.blocks.append(EfficientViTBlock(embed_dim[i], key_dim=16, num_heads=num_heads[i], window_resolution=window_size[i]))
self.blocks = torch.nn.Sequential(*self.blocks)
def forward(self, x):
# 前向传播
x = self.patch_embed(x) # 图像嵌入
x = self.blocks(x) # 通过多个EfficientViTBlock
return x
创建EfficientViT模型实例
if name == ‘main’:
model = EfficientViT(img_size=224, patch_size=16)
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码注释说明:
Conv2d_BN类:该类封装了卷积层和批归一化层,并提供了一个方法来将其融合为一个卷积层,以提高推理速度。
EfficientViTBlock类:这是EfficientViT的基本构建块,包含了卷积层、前馈网络和局部窗口注意力机制。
EfficientViT类:定义了整个EfficientViT模型,包括图像嵌入层和多个EfficientViTBlock的堆叠。
前向传播:模型的前向传播过程,首先将输入图像嵌入,然后通过多个块进行处理,最终输出特征。
这个程序文件实现了一个高效的视觉变换器(EfficientViT)模型架构,适用于各种下游任务。文件中包含多个类和函数,构成了模型的整体结构和功能。
首先,文件引入了必要的库,包括PyTorch及其相关模块。接着定义了一个名为Conv2d_BN的类,该类是一个包含卷积层和批归一化层的顺序容器。这个类在初始化时设置了卷积层的参数,并对批归一化层的权重和偏置进行了初始化。它还提供了一个switch_to_deploy方法,用于在推理阶段将批归一化层转换为卷积层。
接下来,replace_batchnorm函数用于遍历网络中的所有子模块,将批归一化层替换为恒等映射,以便在推理时提高效率。
PatchMerging类实现了对输入特征图的合并操作,使用多个卷积层和激活函数来处理输入数据。Residual类则实现了残差连接的功能,可以在训练时随机丢弃部分输入,以增强模型的鲁棒性。
FFN类实现了前馈神经网络,包含两个卷积层和一个ReLU激活函数。CascadedGroupAttention和LocalWindowAttention类实现了不同类型的注意力机制,用于处理输入特征图中的信息。它们通过分组卷积和注意力机制来提取特征。
EfficientViTBlock类是高效视觉变换器的基本构建块,结合了卷积层、前馈网络和注意力机制。EfficientViT类则是整个模型的主类,负责构建模型的不同阶段,包括图像嵌入、多个EfficientViT块的堆叠等。
在模型的初始化过程中,用户可以设置图像大小、补丁大小、嵌入维度、深度、注意力头数等参数。模型的前向传播方法返回了多个阶段的输出,便于下游任务的使用。
最后,文件定义了一些不同配置的EfficientViT模型(如EfficientViT_m0到EfficientViT_m5),并提供了相应的构建函数。这些函数允许用户加载预训练权重,并选择是否融合批归一化层。
在__main__部分,示例代码展示了如何实例化一个EfficientViT模型,并对随机输入进行前向传播,输出各个阶段的特征图大小。整体上,这个文件实现了一个灵活且高效的视觉变换器架构,适用于多种计算机视觉任务。
10.4 cfpt.py
以下是保留的核心代码部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import to_2tuple, trunc_normal_
class CrossLayerPosEmbedding3D(nn.Module):
def init(self, num_heads=4, window_size=(5, 3, 1), spatial=True):
super(CrossLayerPosEmbedding3D, self).init()
self.spatial = spatial # 是否使用空间位置嵌入
self.num_heads = num_heads # 注意力头的数量
self.layer_num = len(window_size) # 层数
# 初始化相对位置偏置表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] – 1) * (2 * window_size[0] – 1), num_heads))
)
# 计算相对位置索引
self.register_buffer(“relative_position_index”, self.calculate_relative_position_index(window_size))
trunc_normal_(self.relative_position_bias_table, std=.02) # 初始化相对位置偏置
# 初始化绝对位置偏置
self.absolute_position_bias = nn.Parameter(torch.zeros(len(window_size), num_heads, 1, 1, 1))
trunc_normal_(self.absolute_position_bias, std=.02)
def calculate_relative_position_index(self, window_size):
# 计算相对位置索引
coords_h = [torch.arange(ws) – ws // 2 for ws in window_size]
coords_w = [torch.arange(ws) – ws // 2 for ws in window_size]
coords = [torch.stack(torch.meshgrid([coord_h, coord_w])) for coord_h, coord_w in zip(coords_h, coords_w)]
coords_flatten = torch.cat([torch.flatten(coord, 1) for coord in coords], dim=-1)
relative_coords = coords_flatten[:, :, None] – coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += window_size[0] – 1
relative_coords[:, :, 1] += window_size[0] – 1
relative_coords[:, :, 0] *= 2 * window_size[0] – 1
return relative_coords.sum(-1)
def forward(self):
# 计算位置嵌入
pos_indicies = self.relative_position_index.view(-1)
pos_indicies_floor = torch.floor(pos_indicies).long()
pos_indicies_ceil = torch.ceil(pos_indicies).long()
value_floor = self.relative_position_bias_table[pos_indicies_floor]
value_ceil = self.relative_position_bias_table[pos_indicies_ceil]
weights_ceil = pos_indicies – pos_indicies_floor.float()
weights_floor = 1.0 – weights_ceil
pos_embed = weights_floor.unsqueeze(-1) * value_floor + weights_ceil.unsqueeze(-1) * value_ceil
pos_embed = pos_embed.reshape(1, 1, self.num_token, -1, self.num_heads).permute(0, 4, 1, 2, 3)
return pos_embed + self.absolute_position_bias
class CrossLayerSpatialAttention(nn.Module):
def init(self, in_dim, layer_num=3, num_heads=4):
super(CrossLayerSpatialAttention, self).init()
self.num_heads = num_heads # 注意力头的数量
self.hidden_dim = in_dim // 4 # 隐藏维度
self.qkv = nn.Conv2d(in_dim, self.hidden_dim * 3, kernel_size=1) # 线性变换
self.softmax = nn.Softmax(dim=-1) # softmax层
self.pos_embed = CrossLayerPosEmbedding3D(num_heads=num_heads) # 位置嵌入
def forward(self, x_list):
q_list, k_list, v_list = [], [], []
for x in x_list:
qkv = self.qkv(x) # 计算Q, K, V
q, k, v = qkv.chunk(3, dim=1) # 分割Q, K, V
q_list.append(q)
k_list.append(k)
v_list.append(v)
# 将Q, K, V堆叠在一起
q_stack = torch.cat(q_list, dim=1)
k_stack = torch.cat(k_list, dim=1)
v_stack = torch.cat(v_list, dim=1)
# 计算注意力
attn = F.normalize(q_stack, dim=-1) @ F.normalize(k_stack, dim=-1).transpose(-1, -2)
attn = attn + self.pos_embed() # 加入位置嵌入
attn = self.softmax(attn) # 归一化
out = attn @ v_stack # 计算输出
return out # 返回输出
代码核心部分说明:
CrossLayerPosEmbedding3D: 该类用于计算跨层的3D位置嵌入,包括相对位置偏置和绝对位置偏置的初始化和计算。
CrossLayerSpatialAttention: 该类实现了跨层空间注意力机制,包含Q、K、V的计算和注意力的计算逻辑。
forward方法: 在这两个类中,forward方法定义了如何处理输入数据并计算输出。对于CrossLayerSpatialAttention,它将输入分为Q、K、V,并计算注意力输出。
以上代码展示了跨层注意力机制的核心逻辑,注释详细解释了每个部分的功能和作用。
这个程序文件 cfpt.py 实现了两个主要的神经网络模块:CrossLayerChannelAttention 和 CrossLayerSpatialAttention,它们都基于深度学习框架 PyTorch。文件中还定义了一些辅助类和函数,用于实现特定的功能,如位置编码、卷积操作和窗口划分等。
首先,文件导入了必要的库,包括 PyTorch、数学库、einops(用于张量重排)、以及一些 PyTorch 的模块和功能。接着,定义了一个 LayerNormProxy 类,该类封装了 PyTorch 的层归一化功能,并在前向传播中调整输入张量的维度。
接下来,CrossLayerPosEmbedding3D 类用于生成跨层位置嵌入。它根据给定的窗口大小和头数初始化相对位置偏置表,并计算相对位置索引。该类的前向方法生成位置嵌入,用于后续的注意力计算。
ConvPosEnc 类实现了卷积位置编码,使用深度可分离卷积来增强特征图,并可选择性地添加激活函数。DWConv 类则实现了深度卷积操作,用于处理输入特征图。
Mlp 类实现了一个简单的多层感知机(MLP),包含两个线性层和一个激活函数。
接下来的几个函数实现了窗口划分和逆操作,主要用于处理输入特征图的重组和恢复,支持重叠窗口的处理。
CrossLayerSpatialAttention 类实现了空间注意力机制。它通过多层卷积、归一化和注意力计算来处理输入特征图。该类的前向方法接收多个输入特征图,计算查询、键、值,并通过注意力机制生成输出特征图。它还使用了之前定义的卷积位置编码和位置嵌入。
CrossLayerChannelAttention 类实现了通道注意力机制,结构与空间注意力类似,但处理方式不同。它使用通道划分和逆操作来实现对输入特征图的处理。该类同样在前向方法中接收多个输入特征图,计算注意力并生成输出。
整体来看,这个文件实现了一个复杂的注意力机制,旨在提高深度学习模型在处理图像或其他高维数据时的性能。通过跨层的通道和空间注意力,模型能够更好地捕捉特征之间的关系,从而提升特征表示的能力。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式







评论前必须登录!
注册