 网硕互联帮助中心
网硕互联帮助中心背景意义
研究背景与意义
在现代电气设备的设计与维护中,部件的准确识别与分类是确保系统安全性和可靠性的关键环节。随着电气设备的复杂性不断增加,传统的人工识别方法已难以满足高效性和准确性的要求。因此,基于深度学习的计算机视觉技术逐渐成为解决这一问题的重要手段。YOLO(You Only Look Once)系列模型因其实时性和高精度的特点,已广泛应用于目标检测和识别任务中。尤其是YOLOv11的改进版本,凭借其在特征提取和处理速度上的优势,为电气设备部件的自动识别提供了新的可能性。
本研究旨在基于改进的YOLOv11模型,构建一个高效的电气设备部件识别系统。该系统将利用一个包含1162张图像的数据集,涵盖了八类电气部件,包括Bushing、Disc、Disc-Pin、Isolating、La、Others、Pin和wall等。这些部件在电气设备的运行中扮演着重要角色,准确识别它们不仅有助于设备的故障诊断和维护,还能为设备的设计优化提供数据支持。
通过对数据集的深入分析与处理,研究将采用实例分割技术,以实现对电气部件的精确定位和分类。数据集中的图像经过预处理,确保了在不同环境条件下的鲁棒性。尽管未采用图像增强技术,但通过高分辨率的图像输入,系统仍能有效提取出关键特征,提升识别的准确性。
本研究的意义在于推动电气设备智能化管理的发展,提升设备维护的效率与安全性。通过构建基于YOLOv11的识别系统,能够为电气行业提供一种新型的智能解决方案,助力于实现更高水平的自动化与智能化管理。
图片效果

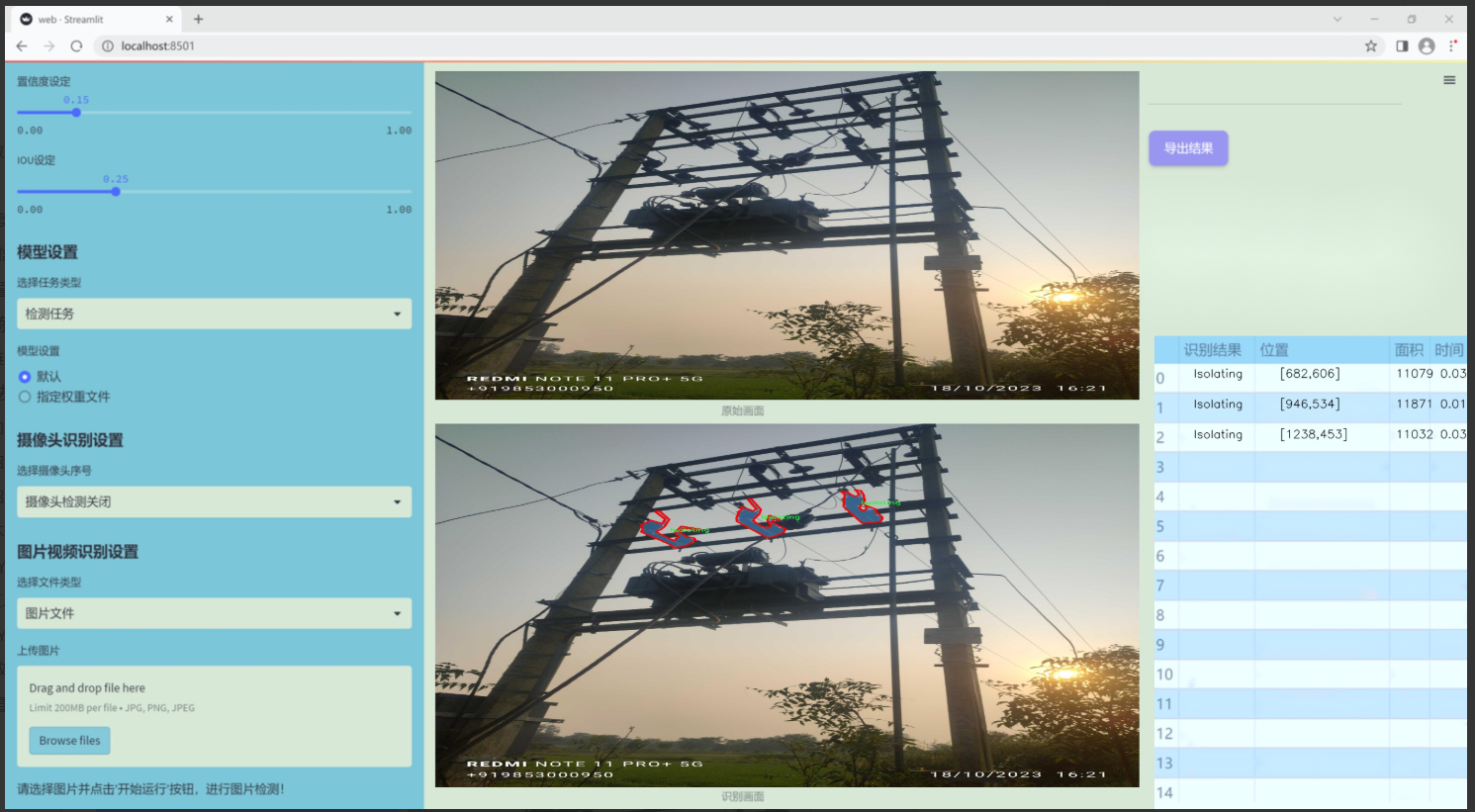

数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11模型在电气设备部件识别系统中的应用,所使用的数据集围绕“Object_identification_Isolating”主题构建,专注于电气设备中的关键部件识别。该数据集包含8个类别,分别为:Bushing、Disc、Disc-Pin、Isolating、La、Others、Pin和wall。这些类别涵盖了电气设备中常见的部件,能够为模型提供丰富的训练样本,以提高其识别精度和效率。
在数据集的构建过程中,我们特别注重样本的多样性和代表性,以确保模型能够在各种环境和条件下进行有效识别。每个类别的样本均经过精心挑选,涵盖了不同的视角、光照条件和背景,从而增强模型的泛化能力。例如,Bushing和Pin类样本展示了不同类型和尺寸的绝缘子和连接件,而Disc和Disc-Pin类则提供了多种形状和材料的电气接触部件。这种多样性不仅提升了模型的训练效果,也为后续的实际应用奠定了坚实的基础。
此外,数据集中的“Isolating”类别专门针对电气设备中隔离部件的识别,具有重要的实用价值。通过对该类别的深入学习,模型能够更准确地识别和分类隔离装置,从而在电气安全和维护中发挥更大作用。总之,本项目的数据集为改进YOLOv11模型提供了丰富的训练素材,旨在提升电气设备部件的自动识别能力,推动智能电气设备的进一步发展与应用。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
“”“自动填充以确保输出形状与输入形状相同。”“”
if d > 1:
# 计算实际的卷积核大小
k = d * (k – 1) + 1 if isinstance(k, int) else [d * (x – 1) + 1 for x in k]
if p is None:
# 如果没有提供填充,则自动计算填充
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
“”“标准卷积层,包含卷积、批归一化和激活函数。”“”
default_act = nn.SiLU() # 默认激活函数
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""初始化卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组、扩张和激活函数。"""
super().__init__()
# 定义卷积层
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# 定义批归一化层
self.bn = nn.BatchNorm2d(c2)
# 根据输入参数选择激活函数
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""前向传播:应用卷积、批归一化和激活函数。"""
return self.act(self.bn(self.conv(x)))
class DWConv(Conv):
“”“深度可分离卷积,使用深度卷积。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):
"""初始化深度卷积,参数包括输入通道数、输出通道数、卷积核大小、步幅、扩张和激活函数。"""
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DSConv(nn.Module):
“”“深度可分离卷积模块。”“”
def __init__(self, c1, c2, k=1, s=1, d=1, act=True) -> None:
"""初始化深度可分离卷积模块,包含深度卷积和逐点卷积。"""
super().__init__()
self.dwconv = DWConv(c1, c1, 3) # 深度卷积
self.pwconv = Conv(c1, c2, 1) # 逐点卷积
def forward(self, x):
"""前向传播:先通过深度卷积,再通过逐点卷积。"""
return self.pwconv(self.dwconv(x))
class ConvTranspose(nn.Module):
“”“转置卷积层。”“”
default_act = nn.SiLU() # 默认激活函数
def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
"""初始化转置卷积层,参数包括输入通道数、输出通道数、卷积核大小、步幅、填充、是否使用批归一化和激活函数。"""
super().__init__()
self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""前向传播:应用转置卷积、批归一化和激活函数。"""
return self.act(self.bn(self.conv_transpose(x)))
class ChannelAttention(nn.Module):
“”“通道注意力模块。”“”
def __init__(self, channels: int) -> None:
"""初始化通道注意力模块,设置基本配置。"""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 1×1卷积
self.act = nn.Sigmoid() # 激活函数
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播:计算通道注意力并应用于输入。"""
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
“”“空间注意力模块。”“”
def __init__(self, kernel_size=7):
"""初始化空间注意力模块,设置卷积核大小。"""
super().__init__()
assert kernel_size in {3, 7}, "卷积核大小必须为3或7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 卷积层
self.act = nn.Sigmoid() # 激活函数
def forward(self, x):
"""前向传播:计算空间注意力并应用于输入。"""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
“”“卷积块注意力模块。”“”
def __init__(self, c1, kernel_size=7):
"""初始化CBAM模块,设置输入通道和卷积核大小。"""
super().__init__()
self.channel_attention = ChannelAttention(c1) # 通道注意力
self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力
def forward(self, x):
"""前向传播:依次应用通道注意力和空间注意力。"""
return self.spatial_attention(self.channel_attention(x))
代码核心部分说明:
autopad:用于自动计算填充,以确保卷积操作后输出的形状与输入形状相同。
Conv:标准卷积层,包含卷积、批归一化和激活函数的组合。
DWConv:深度卷积,适用于深度可分离卷积的实现。
DSConv:深度可分离卷积模块,包含深度卷积和逐点卷积。
ConvTranspose:转置卷积层,通常用于上采样。
ChannelAttention:通道注意力机制,通过对通道进行加权来增强特征。
SpatialAttention:空间注意力机制,通过对空间位置进行加权来增强特征。
CBAM:结合通道和空间注意力的模块,提升特征表达能力。
这个程序文件 conv.py 定义了一系列用于卷积操作的模块,主要用于深度学习中的卷积神经网络(CNN)。文件中使用了 PyTorch 框架,并实现了多种卷积层和注意力机制。以下是对代码的详细说明。
首先,文件导入了必要的库,包括 math、numpy 和 torch 以及 torch.nn。接着,定义了一个名为 autopad 的函数,该函数用于自动计算卷积操作所需的填充,以确保输出的形状与输入的形状相同。
接下来,定义了多个卷积类。Conv 类实现了标准的卷积操作,包含卷积层、批归一化层和激活函数。构造函数中接受多个参数,如输入通道数、输出通道数、卷积核大小、步幅、填充、分组卷积和扩张等。forward 方法实现了卷积、批归一化和激活的顺序操作。
Conv2 类是 Conv 类的简化版本,增加了一个 1×1 的卷积层,以便在前向传播中融合两个卷积的输出。LightConv 类实现了一种轻量级卷积,结合了标准卷积和深度卷积(DWConv),用于提高计算效率。
DWConv 类实现了深度卷积,适用于每个输入通道独立进行卷积操作。DSConv 类则实现了深度可分离卷积,结合了深度卷积和逐点卷积的特点。
DWConvTranspose2d 类实现了深度转置卷积,而 ConvTranspose 类则实现了标准的转置卷积层,支持批归一化和激活函数。
Focus 类用于将空间信息聚焦到通道维度,通过对输入张量进行特定的切片和拼接,增加了卷积的输入通道数。GhostConv 类实现了 Ghost 卷积,通过主卷积和廉价操作来提高特征学习的效率。
RepConv 类是一个基础的重复卷积模块,支持训练和推理阶段的不同操作。它通过融合卷积和批归一化的参数来优化模型。
接下来,定义了几个注意力机制模块。ChannelAttention 类实现了通道注意力机制,通过对输入特征图进行全局平均池化和全连接层操作,生成通道权重。SpatialAttention 类实现了空间注意力机制,通过对输入特征图进行平均和最大池化,生成空间权重。
CBAM 类结合了通道注意力和空间注意力,形成一个完整的卷积块注意力模块,用于特征的重校准。
最后,Concat 类实现了张量的拼接操作,可以在指定的维度上将多个张量连接起来。
整体来看,这个文件实现了多种卷积和注意力机制模块,为构建复杂的卷积神经网络提供了基础组件。这些模块可以灵活组合,适用于各种计算机视觉任务。
10.4 prepbn.py
以下是经过简化并注释的核心代码部分:
import torch
import torch.nn as nn
自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# alpha 是一个可学习的参数,初始化为1
self.alpha = nn.Parameter(torch.ones(1))
# 使用一维批量归一化
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):
# 将输入的维度进行转置,以适应 BatchNorm1d 的输入格式
x = x.transpose(1, 2)
# 进行批量归一化,并加上 alpha 乘以原始输入
x = self.bn(x) + self.alpha * x
# 再次转置回原来的维度
x = x.transpose(1, 2)
return x
自定义的线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册一些缓冲区,用于训练过程中的状态管理
self.register_buffer(‘warm’, torch.tensor(warm)) # 预热步数
self.register_buffer(‘iter’, torch.tensor(step)) # 当前迭代步数
self.register_buffer(‘total_step’, torch.tensor(step)) # 总步数
self.r0 = r0 # 初始比例
self.norm1 = norm1(dim) # 第一个归一化层
self.norm2 = norm2(dim) # 第二个归一化层
def forward(self, x):
if self.training: # 训练模式
if self.warm > 0: # 如果还有预热步数
self.warm.copy_(self.warm – 1) # 减少预热步数
x = self.norm1(x) # 进行第一次归一化
else:
# 计算当前的 lambda 值,用于线性插值
lamda = self.r0 * self.iter / self.total_step
if self.iter > 0:
self.iter.copy_(self.iter – 1) # 减少迭代步数
x1 = self.norm1(x) # 第一次归一化
x2 = self.norm2(x) # 第二次归一化
# 线性插值
x = lamda * x1 + (1 – lamda) * x2
else: # 测试模式
x = self.norm2(x) # 只进行第二次归一化
return x
代码说明:
RepBN 类:
该类实现了一种自定义的批量归一化方法,允许通过一个可学习的参数 alpha 来调整归一化的输出。
在 forward 方法中,输入数据的维度被转置,以适应 BatchNorm1d 的要求,经过归一化后,再加上 alpha 乘以原始输入。
LinearNorm 类:
该类实现了一种线性归一化方法,结合了两个不同的归一化层(norm1 和 norm2)。
在训练过程中,使用预热阶段逐步引入 norm1,然后根据当前的迭代步数计算一个线性插值系数 lambda,在 norm1 和 norm2 之间进行加权。
在测试模式下,只使用 norm2 进行归一化。
这个程序文件定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都是基于 PyTorch 框架构建的。
RepBN 类是一个自定义的批量归一化层,继承自 nn.Module。在初始化方法中,它接受一个参数 channels,用于指定输入数据的通道数。该类定义了一个可学习的参数 alpha,初始值为 1,并创建了一个标准的批量归一化层 bn。在前向传播方法 forward 中,输入张量 x 首先进行维度转置,将通道维移到最后,然后通过批量归一化层进行处理。处理后,结果与 alpha 乘以原始输入 x 相加,最后再进行一次维度转置以恢复原来的形状。这个模块的设计目的是在标准的批量归一化基础上引入一个可调的加权项,以增强模型的表达能力。
LinearNorm 类同样继承自 nn.Module,它的构造函数接受多个参数,包括 dim(输入的维度)、norm1 和 norm2(两个归一化函数)、warm(预热步数)、step(当前步数)和 r0(初始权重)。在初始化过程中,使用 register_buffer 方法注册了一些缓冲区变量,这些变量在模型训练过程中会保持其状态。前向传播方法 forward 的逻辑较为复杂:如果模型处于训练状态且预热步数大于 0,则执行第一次归一化 norm1,并将预热步数减一;否则,计算一个权重 lamda,它与当前迭代步数和总步数有关。接着,分别对输入 x 应用两个归一化操作 norm1 和 norm2,并根据计算出的权重将这两个结果进行线性组合。若模型不在训练状态,则直接使用 norm2 对输入进行归一化处理。
总体而言,这两个模块通过自定义的归一化方法和动态调整的权重,旨在提高神经网络的训练效果和稳定性。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式







评论前必须登录!
注册