 网硕互联帮助中心
网硕互联帮助中心1.KNN算法的介绍与流程
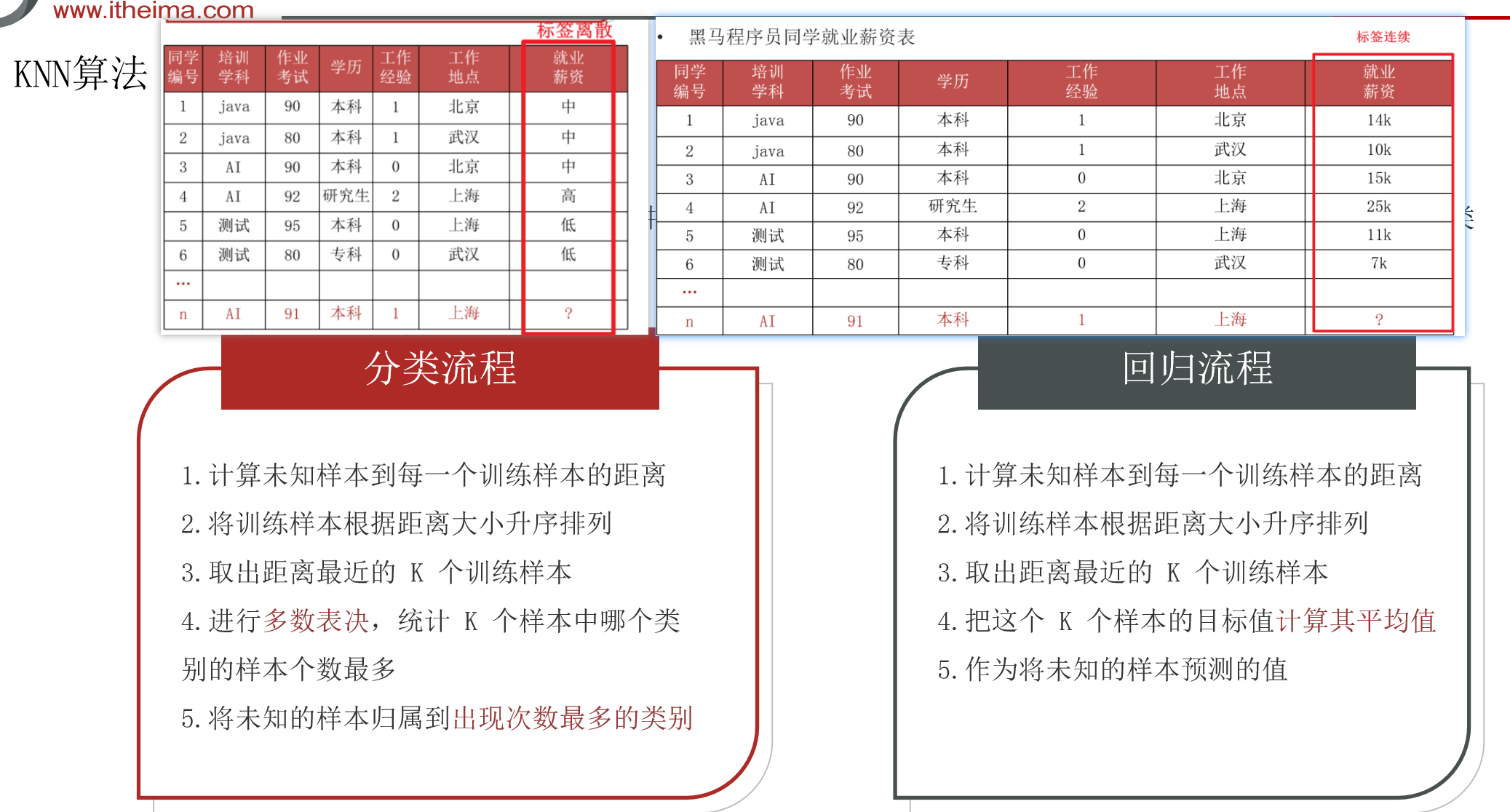
knn算法也叫K近邻算法,顾名思义,是寻找距离目标预测点最近的K个点,其可以用于解决分类问题与回归问题,一般用于分类问题较多。
knn算法的流程:
1.计算各个点到预测点的距离(一般使用欧式距离)
2.对距离进行排序
3.找出距离最近的k个点(即排序后前k个点)
4.对于分类问题,将k个点中数量最多的标签作为预测点的标签;对于回归问题,将k个点的标签的平均值作为预测值。
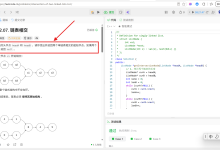
其效果如下图:
2.相关API介绍(即所需要导入的包)
knn分类:from sklearn.neighbors import Kneighbors.Classifier
knn回归:from sklearn.neighbors import Kneighbors.Regressor
3.相关距离的介绍
刚刚提到,在knn算法中涉及到距离的计算,接下来我们就来具体介绍一下几种常见的距离:
欧氏距离:也叫欧几里得距离,用于计算空间中两点的线段距离,公式为:
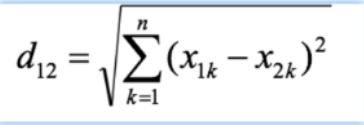
曼哈顿距离:也叫城市街区距离,其核心要素是横平竖直,即只能横向或纵向行走,其距离公式为:
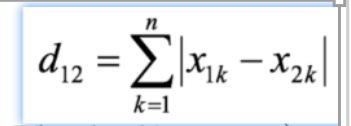
切比雪夫距离:类似国际象棋,只能横竖或对角线行走,其距离计算的其实是步数,横竖走与对角线走,都算一步。其实相当于,求最大的坐标差。其计算公式是:
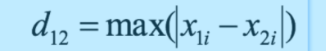
闵氏距离:也叫闵可夫斯基距离,是对于上述距离的一个归纳,其公式为:
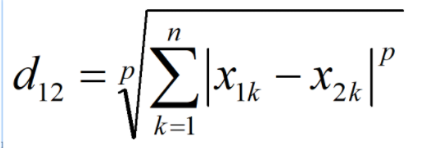
当p=1时,就变成了曼哈顿距离。
当p=2时,就变成了欧式距离。
当p=无穷时,就变成了切比雪夫距离。
3.特征规范化操作
这一般放在特征工程的特征预处理中,对于特征数据,可能出现有的特征数值很大,有的特征数值很小,存在明显量级差异,这时候,大数值对模型影响过大,可能会使得模型偏向这个特征,为了消除量纲对于模型的影响,我们通常要对数据进行放缩,常用的方法有两种:归一化与标准化。
归一化: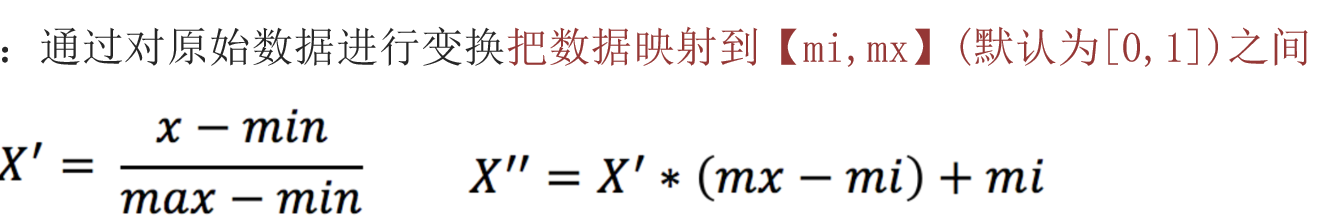
归一化API:from sklearn.preprocessing import MinMaxScaler
标准化: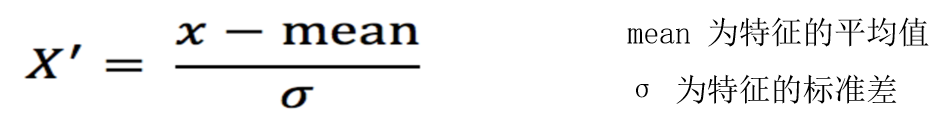
标准化API:from sklearn.preprocessing import StandardScaler
注意,我们平常一般使用标准化,因为归一化容易受极值异常值的影响。
4.KNN分类算法对鸢尾花分类案例
下面是对上述内容的应用,一个经典的鸢尾花案例代码:
from sklearn.datasets import load_iris
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split #用于分隔训练集与数据集
from sklearn.preprocessing import StandardScaler #用于数据标准化
from sklearn.neighbors import KNeighborsClassifier #KNN算法分类对象
from sklearn.neighbors import KNeighborsRegressor #KNN算法回归对象
from sklearn.metrics import accuracy_score #用于模型预测
# def loadIris():
# #加载鸢尾花数据集
# iris_data=load_iris()
# return iris_data
# def showIris():
# iris_data=load_iris()
# #将鸢尾花数据封装成dataframe对象
# iris_df=pd.DataFrame(iris_data.data,columns=iris_data.feature_names)
# #为df对象添加标签列
# iris_df['label']=iris_data.target
# #通过Seaborn绘制散点图
# sns.lmplot(data=iris_df,x='sepal length (cm)',y='sepal width (cm)',hue='label',fit_reg=True)
# #设置标题显式(紧凑模式)
# plt.title('iris_data')
# plt.show()
# def split_train_test():
# iris_data=load_iris()
# x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,test_size=0.2,random_state=19)
# print('训练集特征:',x_train,'训练集标签:',y_train)
def iris_evaluate_test():
#加载数据,数据来自于sklearn.datasets自带的load_iris
iris_data=load_iris()
#数据预处理,划分训练集与测试集,比例为2:8
x_train,x_test,y_train,y_test=train_test_split(iris_data.data,iris_data.target,test_size=0.2,random_state=19)
#特征工程,特征预处理-标准化
#创建标准化对象
std=StandardScaler()
#fit_transform用于训练并转换,fit用于训练,transform用于转换,只有第一次需要训练
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
#创建KNN分类对象
estimator=KNeighborsClassifier(n_neighbors=3)
#训练模型
estimator.fit(x_train,y_train)
#模型预测
y_pre=estimator.predict(x_test)
print('预测结果:',y_pre)
#自定义数据集进行测试
my_data=[[5.1,3.5,1.4,0.2]]
my_data=std.transform(my_data)
print('预测结果:',estimator.predict(my_data))
#查看上述数据集,每种分类的预测概率
print('预测概率:',estimator.predict_proba(my_data))
# print('准确率:',accuracy_score(y_test,y_pre))
#直接进行评分,基于训练集特征与训练集标签
print('准确率:',estimator.score(x_train,y_train))
#基于训练集标签与预测结果进行评分
print('准确率:',accuracy_score(y_test,y_pre))
if __name__ == '__main__':
# showIris()
# split_train_test()
iris_evaluate_test()


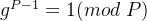

评论前必须登录!
注册