 网硕互联帮助中心
网硕互联帮助中心看这一篇就够了。本文内含YOLOv13网络结构图 + yaml配置文件详细解读与说明 + YOLO虚拟环境安装+训练教程 + 训练参数设置+验证教程+推理教程+参数解析说明等一些有关YOLOv13的内容!
目录
一、YOLOv13简介
YOLOv13的背景和挑战:
YOLOv13的核心创新:
YOLOv13实验结果与表现:
YOLOv13的优势:
二、YOLOv13的网络结构分析
1.Backbone部分
2.Neck部分
3.Head 部分
三、yolov13.yaml配置文件进行详细讲解
3.1 参数部分【Parameters】
3.2 主干部分【backbone】
3.3 头部【head】
四、YOLOv13虚拟环境配置
创健YOLOv13的虚拟环境:
五、YOLOv13模型训练参数详细解析
5.1 YOLOv13模型训练代码
5.2 YOLOv13模型验证代码
5.3 YOLOv13模型推理代码
5.4模型大小选择
5.5 训练参数设置
5.6 训练参数说明
六、本文总结
一、YOLOv13简介
YOLOv13的背景和挑战:
YOLOv13 是 YOLO 系列的最新版本,旨在提升实时目标检测的性能,尤其在复杂场景中进行目标检测时表现更加优越。YOLO 系列模型一贯以其实时性和准确性而著称,但早期的 YOLO 模型(如 YOLOv11 和 YOLOv12)在局部信息聚合和关联建模上存在一定的限制。这些模型在处理复杂场景时的表现受到局部特征提取和自注意力机制计算复杂度的影响。
-
局部关联限制:早期的 YOLO 模型(如 YOLOv11)通过卷积层进行局部信息的聚合,但是卷积层的感受野受限,难以捕捉到全局的语义关联。
-
自注意力机制的局限性:YOLOv12 引入了基于区域的自注意力机制,尝试扩展感受野,但该机制仍然受限于计算资源,无法有效建模高阶的全局关联。
YOLOv13 的目标就是解决这些问题,通过新颖的机制来捕获更加复杂的全局和高阶语义关联。
YOLOv13的核心创新:
Hypergraph-based Adaptive Correlation Enhancement (HyperACE):
-
YOLOv13 通过引入 HyperACE机制,使用 超图 来建模视觉特征的高阶关联。传统的 YOLO 模型主要依赖局部特征的关联建模,而 HyperACE 能够捕捉多对多的高阶全局关联,尤其在复杂场景中表现出色。
-
与传统的图或自注意力机制相比,HyperACE 通过自适应的超边计算,提高了特征关联建模的灵活性和准确性。
Full-Pipeline Aggregation-and-Distribution (FullPAD):
-
为了优化信息流动,YOLOv13 引入了 FullPAD范式,通过全管道特征聚合和分配来提高网络各层之间的协同效应。增强的特征能够在网络的不同阶段(如 backbone、neck、detection head)之间流动,从而提高梯度传播和检测性能。
轻量化设计:深度可分卷积(DSConv):
-
YOLOv13 使用 深度可分卷积 来替代传统的大卷积核卷积操作,显著减少了模型的参数和计算复杂度。这样设计不仅保持了模型的检测能力,还加快了推理速度,使其在性能和效率之间取得了更好的平衡。
高效的超图计算:
-
YOLOv13 的超图计算与传统方法不同,它能够自适应地生成超边,并动态估算每个像素的参与度。这使得 YOLOv13 更加灵活,能够根据图像的不同特点和需求动态调整计算方式,提高了模型对复杂场景的适应能力。
YOLOv13实验结果与表现:
-
在广泛的实验中,YOLOv13 相比 YOLOv11 和 YOLOv12 提高了 3.0% 的 mAP(mean Average Precision),且模型更加轻量,计算复杂度更低。
-
在 MS COCO 数据集上,YOLOv13 提供了更高的检测准确度,尤其在复杂背景和多个物体共存的场景下,能够显著提升检测效果。
YOLOv13的优势:
-
高精度与低延迟:通过引入高效的超图计算和信息分配机制,YOLOv13 在复杂场景中取得了更高的检测精度,同时保持了低延迟和高推理速度。
-
轻量化与高效计算:得益于深度可分卷积的使用,YOLOv13 显著降低了模型的参数量和计算量,在保证高精度的同时,提升了处理速度和模型的实时性。
-
全局关联建模:通过HyperACE机制,YOLOv13 能够捕捉更复杂的多物体间的空间和语义关联,这对于检测多个物体或遮挡物体尤其重要。
本文详细介绍YOLOv13的网络结构,YOLOv13网络主要包含Backbone、Neck和Head 3个部分。
-
Backbone采用DSC3k2、A2C2f和DSConv模块,提升特征提取能力。
-
Neck颈部网络位于主干网络和头部网络之间(Neck中的核心模块包含:DSC3k2、HyperACE、FullPAD_Tunnel、nn.Upsample、Concat),它的作用是进行特征融合和增强。
-
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。
二、YOLOv13的网络结构分析
YOLOv13整体网络结构图
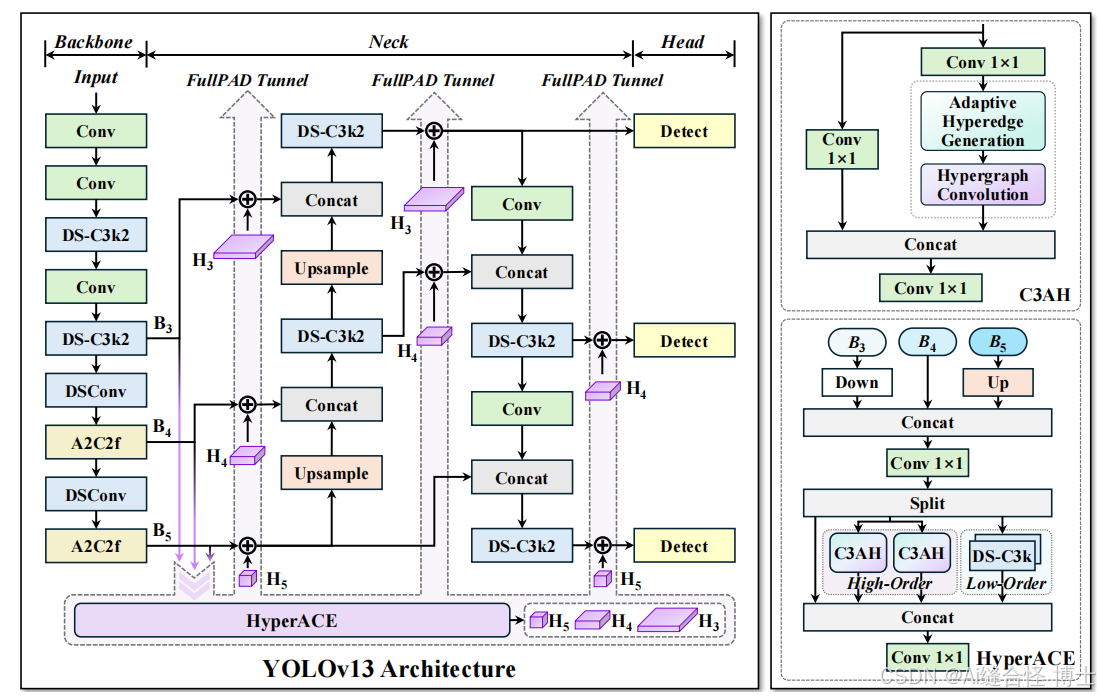
YOLOv13整体网络结构主要由以下三个大部分组成:
1.Backbone部分
Backbone部分负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。YOLOv13使用DSC3k2、A2C2f和DSConv块来处理主干不同阶段的特征提取。为了在保证性能的前提下降低计算开销,YOLOv13 引入了深度可分卷积(DSConv),替代了传统的大卷积核卷积操作。
DSConv深度可分卷积的优势如下:
-
深度可分卷积通过将卷积操作分解为深度卷积和逐点卷积,显著减少了模型的参数量和计算量。相较于传统的卷积操作,深度可分卷积不仅保持了良好的特征提取能力,同时也提高了效率。
-
这种设计使得 YOLOv13 在运行时可以实现更高的推理速度,并且能够在低延迟和低计算复杂度下完成高精度的目标检测。
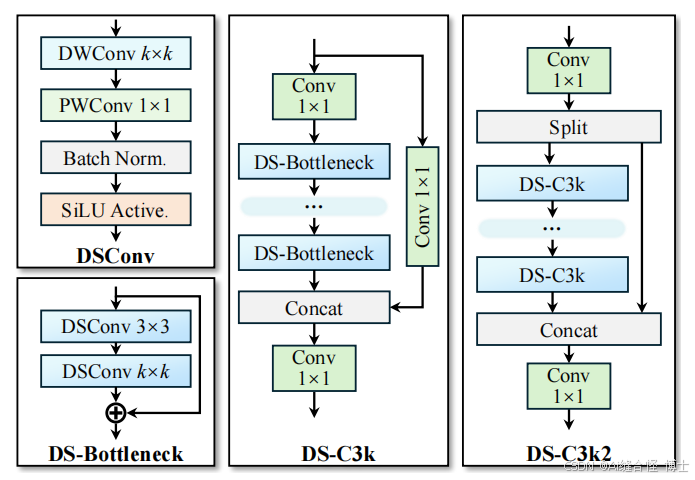
YOLOv13通过轻量化设计,采用深度可分卷积优化C3k2模块,DSC3k2模块与YOLOv11的C3k2模块相比,使用更少的参数来改进特征表示。
此外,Backbone部分还包括一些常见的改进技术,如优化改进和DSC3k2和A2C2f模块、缝合一些卷积模块,注意力模块,替换主干网络等改进,以进一步增强特征提取的能力。后续会更新大量相关部分改进点。
2.Neck部分
Neck颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。后续会更新大量相关部分改进点。
YOLOv13在Neck部分包含两种核心创新点:
第一种创新:基于超图的自适应关联增强(HyperACE)机制
YOLOv13的核心创新是HyperACE机制,它通过超图替代了传统的成对关联建模。与早期版本依赖局部信息或简单自注意力机制不同,HyperACE能够学习多对多的高阶关联,通过跨空间位置和尺度捕捉全局语义信息,特别适用于复杂场景中的物体交互和紧密关系。
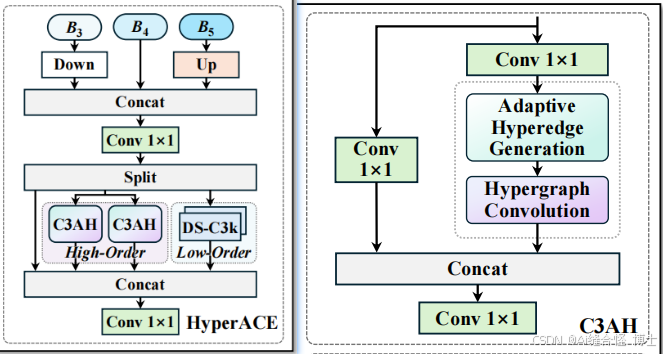
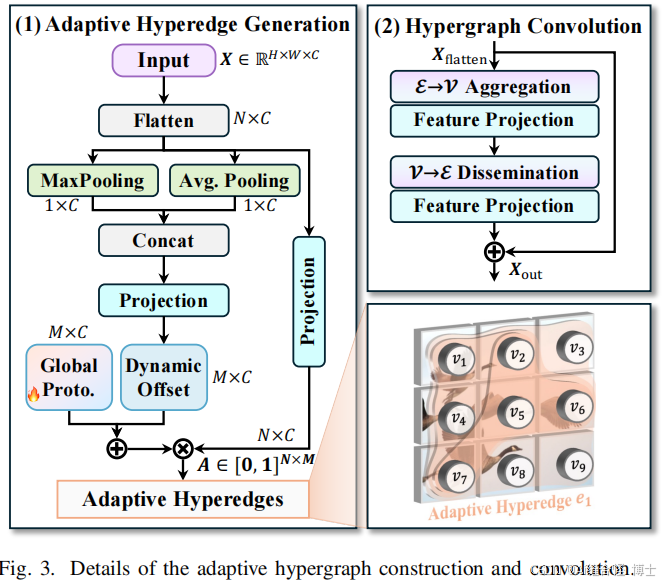
自适应超图计算与传统的固定阈值超图不同,YOLOv13中的自适应超图计算动态学习每个像素在超边中的参与程度,使得高阶关联建模更加灵活、精确,并能在不同尺度和位置之间有效建模视觉特征的关系。后续会更新大量相关部分改进点。
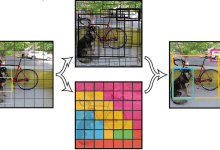
自适应超边的可视化呈现。第一、第二列中的超边主要聚焦于前景物体间的高阶交互关系,第三列则着重展现背景与前景目标之间的互动模式。这些自适应超边的可视化结果,能够直观呈现我们YOLOv13模型所建模的高阶视觉关联特征。后续会更新大量相关部分改进点。

第二种创新:全管道聚合与分配(FullPAD)范式
FullPAD范式旨在提高整个网络的信息流动,确保特征在backbone、neck和head之间的细粒度协同。通过在全管道中分配增强的特征,它有效改善了梯度传播,从而提高了检测精度。后续会更新大量相关部分改进点。
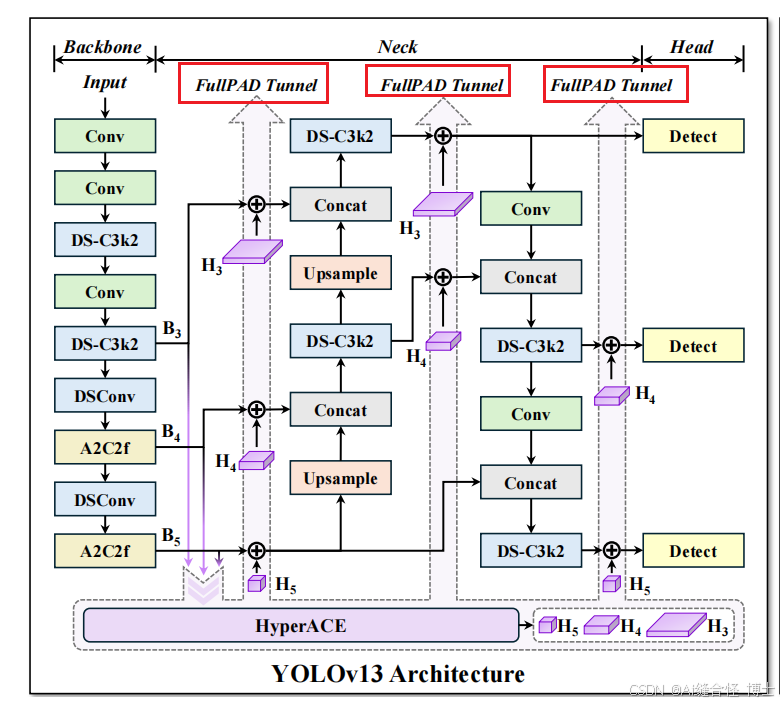
3.Head 部分
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。后续会更新大量相关部分改进点。
三、yolov13.yaml配置文件进行详细讲解
配置文件主要分为三个部分: 参数部分【Parameters】,主干部分【backone】,头部部分【head】。下面分别对这几个部分进行详细说明。
关于YOLOv13网络的配置文件yolov13.yaml的详细内容如下:
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov13n.yaml' will call yolov13.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # Nano
s: [0.50, 0.50, 1024] # Small
l: [1.00, 1.00, 512] # Large
x: [1.00, 1.50, 512] # Extra Large
backbone:
# [from, repeats, module, args]
– [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
– [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4
– [-1, 2, DSC3k2, [256, False, 0.25]]
– [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8
– [-1, 2, DSC3k2, [512, False, 0.25]]
– [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
– [-1, 4, A2C2f, [512, True, 4]]
– [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
– [-1, 4, A2C2f, [1024, True, 1]] # 8
head:
– [[4, 6, 8], 2, HyperACE, [512, 8, True, True, 0.5, 1, "both"]]
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [ 9, 1, DownsampleConv, []]
– [[6, 9], 1, FullPAD_Tunnel, []] #12
– [[4, 10], 1, FullPAD_Tunnel, []] #13
– [[8, 11], 1, FullPAD_Tunnel, []] #14
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 12], 1, Concat, [1]] # cat backbone P4
– [-1, 2, DSC3k2, [512, True]] # 17
– [[-1, 9], 1, FullPAD_Tunnel, []] #18
– [17, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 13], 1, Concat, [1]] # cat backbone P3
– [-1, 2, DSC3k2, [256, True]] # 21
– [10, 1, Conv, [256, 1, 1]]
– [[21, 22], 1, FullPAD_Tunnel, []] #23
– [-1, 1, Conv, [256, 3, 2]]
– [[-1, 18], 1, Concat, [1]] # cat head P4
– [-1, 2, DSC3k2, [512, True]] # 26
– [[-1, 9], 1, FullPAD_Tunnel, []]
– [26, 1, Conv, [512, 3, 2]]
– [[-1, 14], 1, Concat, [1]] # cat head P5
– [-1, 2, DSC3k2, [1024,True]] # 30 (P5/32-large)
– [[-1, 11], 1, FullPAD_Tunnel, []]
– [[23, 27, 31], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.1 参数部分【Parameters】
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov13n.yaml' will call yolov13.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # Nano
s: [0.50, 0.50, 1024] # Small
l: [1.00, 1.00, 512] # Large
x: [1.00, 1.50, 512] # Extra Large
-
nc: 80 指的是数据集中的类别数量。
-
scales: 代表模型尺寸,分了n,s,l,x这5个不同大小的尺寸,参数量依次从小到大。
-
[depth, width, max_channels]:分别表示网络模型的深度因子、网络模型的宽度因子、最大通道数。
-
depth深度因子的作用:表示模型中重复模块的数量或层数的缩放比例。这里主要用来调整DSC3k2模块中的子模块DSBottleneck重复次数。比如主干中第一个DSC3k2模块的number系数是2,我们使用0.5×2并且向上取整就等于1了,这就代表第一个DSC3k2模块中DSBottleneck只重复一次;
-
width宽度因子的作用:表示模型中通道数(即特征图的深度)的缩放比例,如果某个层原本有64个通道,而width设置为0.5,则该层的通道数变为32。举例:比如使用yolov13n.yaml文件,参数为[0.50, 0.25, 1024]。第一个Conv模块的输出通道数写的是64,但是实际上这个通道数并不是64,而是使用宽度因子 0.25×64得到的最终结果16;同理,DSC3k2模块的输出通道虽然在yaml文件上写的是256,但是在实际使用时依然要乘上宽度因子0.25,那么第一个DSC3k2模块最终的到实际通道数就是0.25×256 = 64。如下图所示,其他的依次类推。
-
max-channels: 表示每层最大通道数。每层的通道数会与这个参数进行一个对比,如果特征图通道数大于这个数,那就取 max_channels的值。
3.2 主干部分【backbone】
# YOLO13 backbone
backbone:
# [from, repeats, module, args]
– [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
– [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4
– [-1, 2, DSC3k2, [256, False, 0.25]]
– [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8
– [-1, 2, DSC3k2, [512, False, 0.25]]
– [-1, 1, DSConv, [512, 3, 2]] # 5-P4/16
– [-1, 4, A2C2f, [512, True, 4]]
– [-1, 1, DSConv, [1024, 3, 2]] # 7-P5/32
– [-1, 4, A2C2f, [1024, True, 1]] # 8
主干部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。
-
repeats:这个参数表示模块重复的次数,如果为2则表示该模块重复2次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于DSC3k2模块来说,这个repeats就代表DSC3k2中DSBottelneck或是DSC3k模块重复的次数。
-
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了DSC3k2模块。
-
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
其他说明:各层注释中的P1/2表示该层特征图缩放为输入图像尺寸的1/2,是第1特征层;P2/4表示该层特征图缩放为输入图像尺寸的1/4,是第2特征层;其他的依次类推。
3.3 头部【head】
# YOLO13 head
head:
# [from, repeats, module, args]
– [[4, 6, 8], 2, HyperACE, [512, 8, True, True, 0.5, 1, "both"]]
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [ 9, 1, DownsampleConv, []]
– [[6, 9], 1, FullPAD_Tunnel, []] #12
– [[4, 10], 1, FullPAD_Tunnel, []] #13
– [[8, 11], 1, FullPAD_Tunnel, []] #14
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 12], 1, Concat, [1]] # cat backbone P4
– [-1, 2, DSC3k2, [512, True]] # 17
– [[-1, 9], 1, FullPAD_Tunnel, []] #18
– [17, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 13], 1, Concat, [1]] # cat backbone P3
– [-1, 2, DSC3k2, [256, True]] # 21
– [10, 1, Conv, [256, 1, 1]]
– [[21, 22], 1, FullPAD_Tunnel, []] #23
– [-1, 1, Conv, [256, 3, 2]]
– [[-1, 18], 1, Concat, [1]] # cat head P4
– [-1, 2, DSC3k2, [512, True]] # 26
– [[-1, 9], 1, FullPAD_Tunnel, []]
– [26, 1, Conv, [512, 3, 2]]
– [[-1, 14], 1, Concat, [1]] # cat head P5
– [-1, 2, DSC3k2, [1024,True]] # 30 (P5/32-large)
– [[-1, 11], 1, FullPAD_Tunnel, []]
– [[23, 27, 31], 1, Detect, [nc]] # Detect(P3, P4, P5)
头部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。
-
repeats:这个参数表示模块重复的次数,如果为2则表示该模块重复2次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于DSC3k2模块来说,这个repeats就代表DSC3k2中DSBottelneck或是DSC3k模块重复的次数。
-
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了DSC3k2模块。
-
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
-
这部分主要多出4个操作HyperACE、FullPAD_Tunnel,nn.Upsample、Concat、Detect,解释如下:
-
HyperACE: 这是一个用于增强特征的模块,使用了 HyperACE,它处理来自不同位置(P3、P4、P5)的特征,输出的通道数为 512,深度为 8,使用全局和局部高阶关联建模("both")。参数表示如何进行增强和特征融合。
-
FullPAD_Tunnel: FullPAD_Tunnel 模块,它用于进一步分配和融合特征,以提升检测的准确性。
-
nn.Upsample:表示上采样,将特征图大小进行翻倍操作。比如将大小为20X20的特征图,变为40X40的特征图大小。
-
Concat:代表拼接操作,将相同大小的特征图,通道进行拼接,要求是特征图大小一致,通道数可以不相同。例如[-1, 6]:-1代表上一层,6代表第六层(从第0层开始数),将上一层与第6层进行concat拼接操作。
-
Detect的from有三个数: [23,27,31],这三个就是最终网络的输出特征图,分别对应P3,P4,P5。
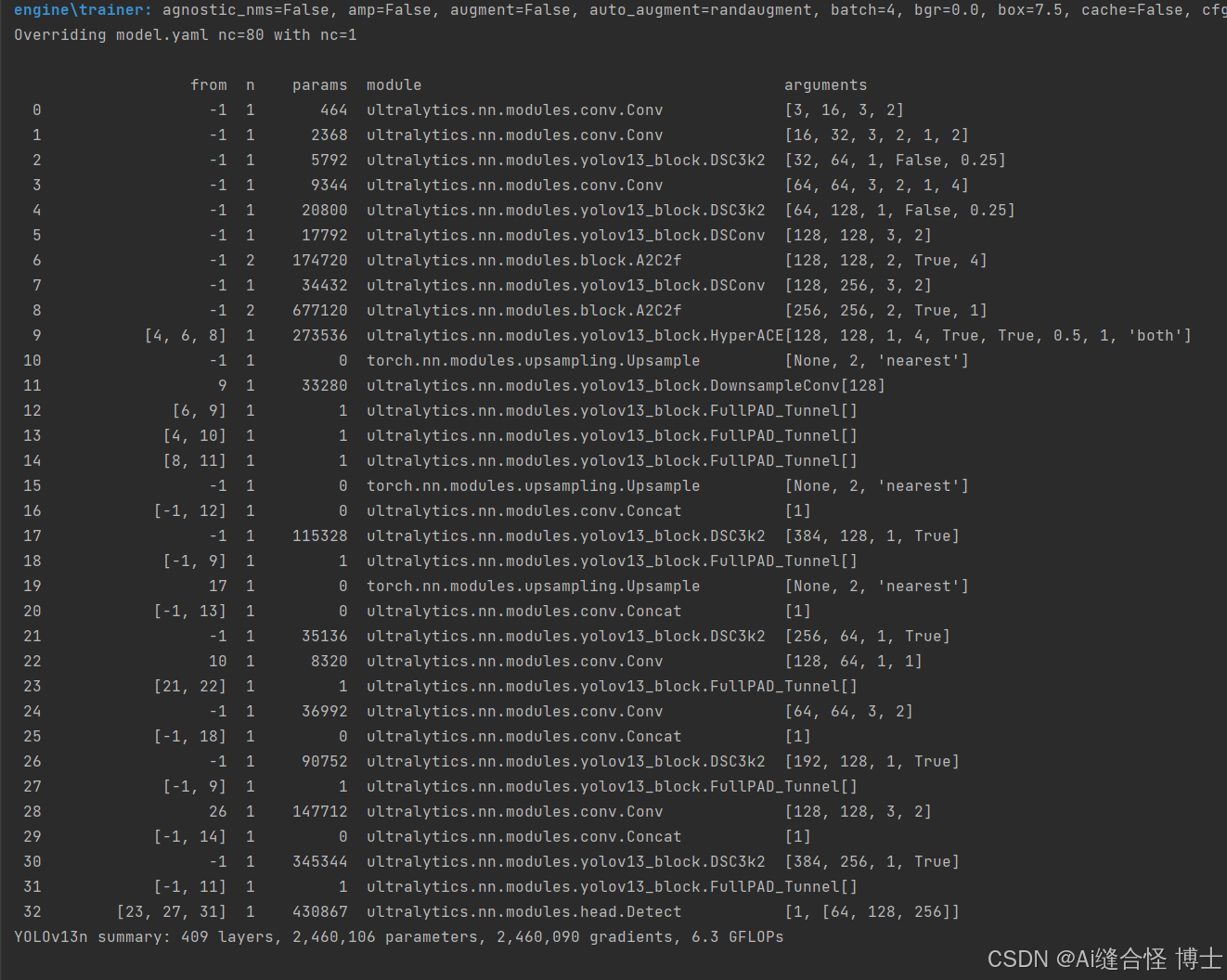
模型训练时打印出的结构参数如下,下图为yolov13n.yaml打印信息:
四、YOLOv13虚拟环境配置
创健YOLOv13的虚拟环境:
首先下载YOLOv13项目源码,点击链接即可跳转
YOLOv13官方源码链接,点击即可跳转!
# 在终端使用如下命令安装YOLOv13的虚拟环境
# 第一步创建一个自己的虚拟环境:
conda create -n yolov13 python=3.11
# 第二步进入到自己的虚拟环境:
conda activate yolov13
# 第三步安装项目需要的包:
pip install -r requirements.txt
YOLOv13官方源码链接,点击即可跳转!
提示!如果之前订阅过我项目的小伙伴,之前的环境是可以直接运行yolov13。如果订阅专栏的小伙伴,不会创建虚拟环境,可以咨询博主,提供Windows系统下的环境包。如果不会配置环境,也可以远程控制帮忙配置环境几分钟就可以配好去跑实验。
五、YOLOv13模型训练参数详细解析
关于yolov13的训练参数该如何设置。接下来对yolov13的相关训练参数和使用方法进行了详细说明。希望对大家有所帮助!
5.1 YOLOv13模型训练代码
YOLOv13目标检测模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolov13n.pt",task="detect")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)
YOLOv13图像分割模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolov13n.pt",task="segment")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)
YOLOv13模型训练脚本train.py代码如下:
from ultralytics import YOLO # 导入 YOLO 类,从 ultralytics 库中加载 YOLO 模型
model = YOLO('yolov13n.yaml') # 创建一个 YOLO 模型实例,加载 yolov13n.yaml 配置文件(Nano 版本)
# Train the model # 注释:开始训练模型
results = model.train(
data='coco.yaml', # 指定数据集的配置文件,这里使用的是 coco.yaml 配置文件,包含 COCO 数据集的信息
epochs=600, # 训练的轮数,模型将训练 600 个周期
batch=256, # 每次训练的批次大小,每次训练会用到 256 张图像
imgsz=640, # 输入图像的尺寸,所有输入图像将被缩放到 640×640 像素
scale=0.5, # 模型缩放因子,用于调整模型的复杂度。S:0.9; L:0.9; X:0.9,对应于不同规模模型的缩放因子。此处的 0.5 适用于 Nano版本
mosaic=1.0, # 是否启用马赛克数据增强方法,1.0表示启用,马赛克增强有助于增强数据多样性
mixup=0.0, # 是否使用 mixup 数据增强,mixup 会将两张图像按一定比例混合。0.0 表示不使用该增强方法。S:0.05; L:0.15; X:0.2
copy_paste=0.1, # 启用复制-粘贴增强,0.1 表示增强强度为 10%,会将一个物体从一张图片复制并粘贴到另一张图像中。S:0.15; L:0.5; X:0.6
device="0", # device="0,1,2,3"训练时使用的 GPU 设备编号,这里使用编号为 0、1、2 和 3 的四个 GPU 进行训练。通常设置为0
)
5.2 YOLOv13模型验证代码
自己创建一个val.py脚本文件,把代码粘贴进去就好了:
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
# 模型配置文件
model_yaml_path = r"E:\\yolo\\yolov13\\runs\\V13train\\exp\\weights\\best.pt"
#数据集配置文件
data_yaml_path = r'E:\\yolo\\yolov13\\datasets\\data.yaml' #这个就是数据集的yaml文件的路径
if __name__ == '__main__':
model = YOLO(model_yaml_path)
model.val(data=data_yaml_path,
split='val',
imgsz=640,
batch=4,
project='runs/val',
name='exp'
)
5.3 YOLOv13模型推理代码
自己创建一个predict.py脚本文件,把代码粘贴进去就好了:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'E:\\yolo\\yolov13\\runs\\V11train\\exp43\\weights\\best.pt')#训练好的模型
model.predict(source=r'E:\\yolo\\yolov13\\datasets\\demo\\images\\val',#可以是单个图片,也可以是图片文件夹
project='runs/detect',
rect=False,
name='exp',
save=True,
)
5.4模型大小选择
model = YOLO("yolov13n.pt") 表示使用的是v13n模型来训练, 因为我们自己需要改进创新发论文,通常都不会使用这种训练好的模型继续训练,可以选择性的加载官方模型的预训练权重,如果改动比较大建议大家自己重新训练。如果想使用其他大小的模型,只需要把n改为其他大小的对应字母即可。例如:
model = YOLO("yolov13n.pt")
model = YOLO("yolov13s.pt")
model = YOLO("yolov13l.pt")
model = YOLO("yolov13x.pt")
加载官方预训练权重去训练方法:
from ultralytics import YOLO # 导入 YOLO 类,从 ultralytics 库中加载 YOLO 模型
model = YOLO('yolov13n.yaml') # 创建一个 YOLO 模型实例,加载 yolov13n.yaml 配置文件(Nano 版本)
# Train the model # 注释:开始训练模型
model.load("yolov13n.pt") # 加载预训练权重
results = model.train(
data='coco.yaml', # 指定数据集的配置文件,这里使用的是 coco.yaml 配置文件,包含 COCO 数据集的信息
epochs=600, # 训练的轮数,模型将训练 600 个周期
batch=256, # 每次训练的批次大小,每次训练会用到 256 张图像
imgsz=640, # 输入图像的尺寸,所有输入图像将被缩放到 640×640 像素
scale=0.5, # 模型缩放因子,用于调整模型的复杂度。S:0.9; L:0.9; X:0.9,对应于不同规模模型的缩放因子。此处的 0.5 适用于 Nano版本
mosaic=1.0, # 是否启用马赛克数据增强方法,1.0表示启用,马赛克增强有助于增强数据多样性
mixup=0.0, # 是否使用 mixup 数据增强,mixup 会将两张图像按一定比例混合。0.0 表示不使用该增强方法。S:0.05; L:0.15; X:0.2
copy_paste=0.1, # 启用复制-粘贴增强,0.1 表示增强强度为 10%,会将一个物体从一张图片复制并粘贴到另一张图像中。S:0.15; L:0.5; X:0.6
device="0", # device="0,1,2,3"训练时使用的 GPU 设备编号,这里使用编号为 0、1、2 和 3 的四个 GPU 进行训练。通常设置为0
)
不同模型参数大小如下,v13
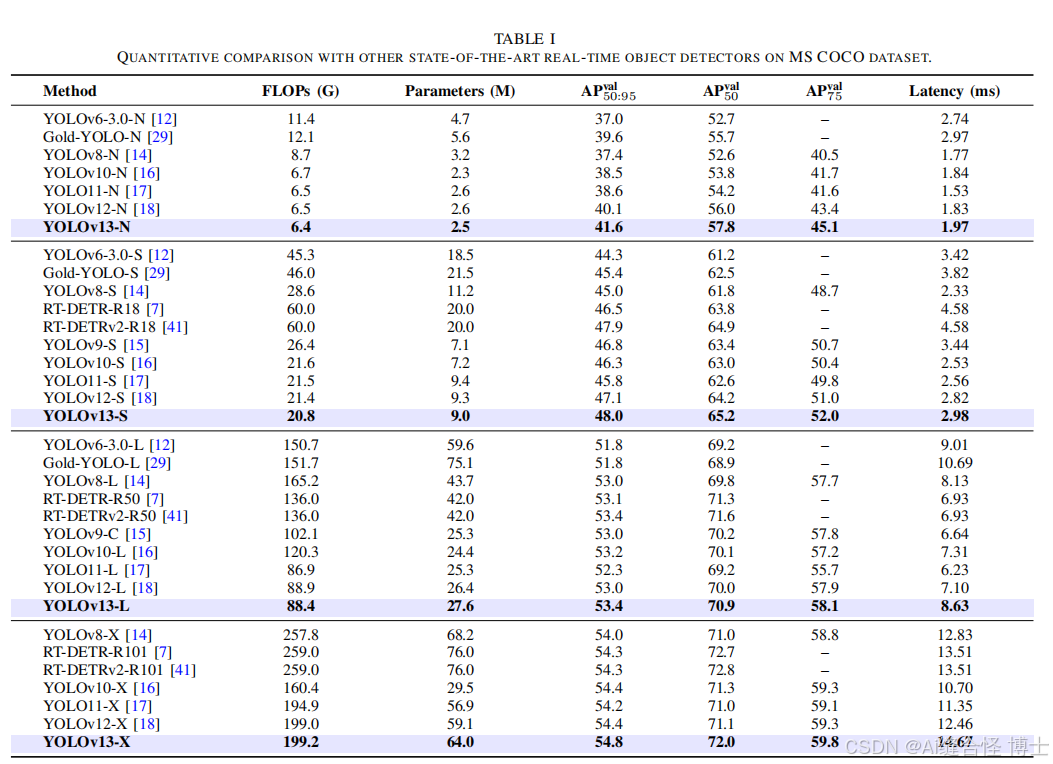
n是参数量最小的模型。一般情况下,模型越大,最终模型的性能效果也会越好。可根据自己实际需求选择相应的模型大小进行训练。
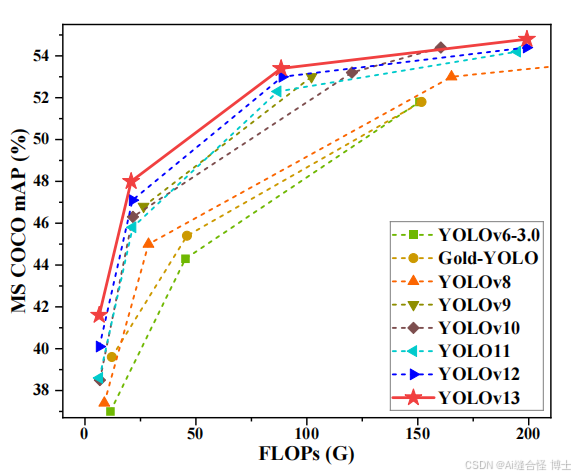
5.5 训练参数设置
通过运行model.train(data="data.yaml", epochs=100, batch=4)训练v13模型,其中(data="data.yaml", epochs=100, batch=4)是训练设置的参数,没有添加的训练参数都是使用的默认值。官方其实给出了很多其他相关参数,详细说明见下文。
如果我们需要自己修改其他训练参数,只需要在train后面的括号中加入相应的参数和具体值即可。
例如加上模型训练优化器参数optimizer,其默认值是auto。
可设置的值为:SGD, Adam, AdamW, NAdam, RAdam, RMSProp。常用SGD或者AdamW。
我们可以直接将其设置为SGD,写法如下:
# 模型训练,添加模型优化器设置
results = model.train(data="data.yaml", epochs=100, batch=4, optimizer='SGD')
5.6 训练参数说明
YOLOv13 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。以下是官方给出了训练可设置参数和说明:
| model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
| epochs | 100 | 训练总轮数。每个epoch代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
| time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
| patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的epoch数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
| batch | 16 | 批量大小,有三种模式:设置为整数(例如,' Batch =16 '), 60% GPU内存利用率的自动模式(' Batch =-1 '),或指定利用率分数的自动模式(' Batch =0.70 ')。 |
| imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
| save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
| cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
| device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
| workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
| project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
| exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
| pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
| optimizer | 'auto' | 为训练模型选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
| verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
| seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
| deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
| single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
| rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
| cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
| close_mosaic | 10 | 在训练完成前禁用最后 N 个epoch的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
| resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
| amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
| fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
| profile | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
| freeze | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
| lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
| lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
| momentum | 0.937 | 用于 SGD 的动量因子,或用于 Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
| weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚,以防止过度拟合。 |
| warmup_epochs | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
| warmup_momentum | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
| warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
| box | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
| cls | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
| dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
| pose | 12.0 | 姿态损失在姿态估计模型中的权重,影响着准确预测姿态关键点的重点。 |
| kobj | 2.0 | 姿态估计模型中关键点对象性损失的权重,平衡检测可信度与姿态精度。 |
| label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签和标签均匀分布的混合标签,可以提高泛化效果。 |
| nbs | 64 | 用于损耗正常化的标称批量大小。 |
| overlap_mask | True | 决定在训练过程中分割掩码是否应该重叠,适用于实例分割任务。 |
| mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
| dropout | 0.0 | 分类任务中正则化的丢弃率,通过在训练过程中随机省略单元来防止过拟合。 |
| val | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
| plots | False | 生成并保存训练和验证指标图以及预测示例图,以便直观地了解模型性能和学习进度。 |
常用的几个训练参数是: 数据集配置文件data、训练轮数epochs、训练批次大小batch、训练使用的设备device,模型优化器optimizer、初始学习率lr0。
以上便是关于YOLOv13模型详细说明,看到这里的小伙伴,相信你一定对yolov13模型有了一定的认识啦。
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv13改进有效涨点专栏,本专栏后期我会根据2026、2025、2024近几年各种最新的前沿顶会顶刊论文复现,也会对一些老的改进机制进行补充,本专栏会持续至少更新500+创新改进点,限时享优惠,大家尽早关注有效涨点专栏,带着大家快速高效发论文!如果大家觉得本文能帮助到你了,订阅本专栏,关注后续更多的更新~






评论前必须登录!
注册