 网硕互联帮助中心
网硕互联帮助中心目录
NVIDIA YOLOv8 模型转换全流程(PyTorch → ONNX → TensorRT)
一、 环境准备
二、从 PyTorch 导出 ONNX 模型
三、 使用 ONNX Runtime 测试模型
四、将 ONNX 转换为 TensorRT
4.1 trtexec 极速版
4.2 Python API(推荐,可自定义后处理)
五、TensorRT 推理测试(输出 1×84×8400 解码)
六、运行效果与速度对比
📌 总结
NVIDIA YOLOv8 模型转换全流程(PyTorch → ONNX → TensorRT)
📢 本文详细记录了 YOLOv8 从 PyTorch 训练模型到 ONNX,再到 TensorRT 加速引擎的完整转换过程,并解决了 ONNX 输出形状为 1×84×8400 的情况。 环境基于 NVIDIA GPU + PyTorch + TensorRT,文末附完整 Python 源码。
一、 环境准备
在开始之前,先确保以下环境已正确安装:
| Ubuntu / Win11 | 22.04 | 均可 |
| CUDA | 11.8 | 向下兼容 |
| cuDNN | 8.9.0 | cuDNN Archive | NVIDIA Developer |
| TensorRT | 8.6.1 | 官方下载 |
| PyTorch | 2.1.0+cu121 | 建议 conda |
| ultralytics | 8.0.73 | 官方仓库 |
| onnx / onnxsim | 1.15 / 0.4 | 导出后用 onnxsim 精简 |
💡 注意: TensorRT 安装包需要和 CUDA 版本匹配,否则会报错。
如果不会安装,请参考博主的另外几篇博文。【保姆级】Windows 系统安装 TensorRT 8.6.1 安装指南-CSDN博客
【保姆级】在Windows系统环境下安装CUDA 11.8和cuDNN v8.9.0的详细指南,配套tensorrt8.6使用-CSDN博客
二、从 PyTorch 导出 ONNX 模型
YOLOv8 官方已经提供了方便的 export 接口,这里直接调用即可。
from ultralytics import YOLO
# 1. 加载 PyTorch 格式的权重
model = YOLO("yolov8n.pt") # 这里可以替换为自己的 .pt 文件
# 2. 导出为 ONNX
model.export(format="onnx", opset=12, dynamic=False, simplify=True, imgsz=640)
print("ONNX 模型导出完成!")
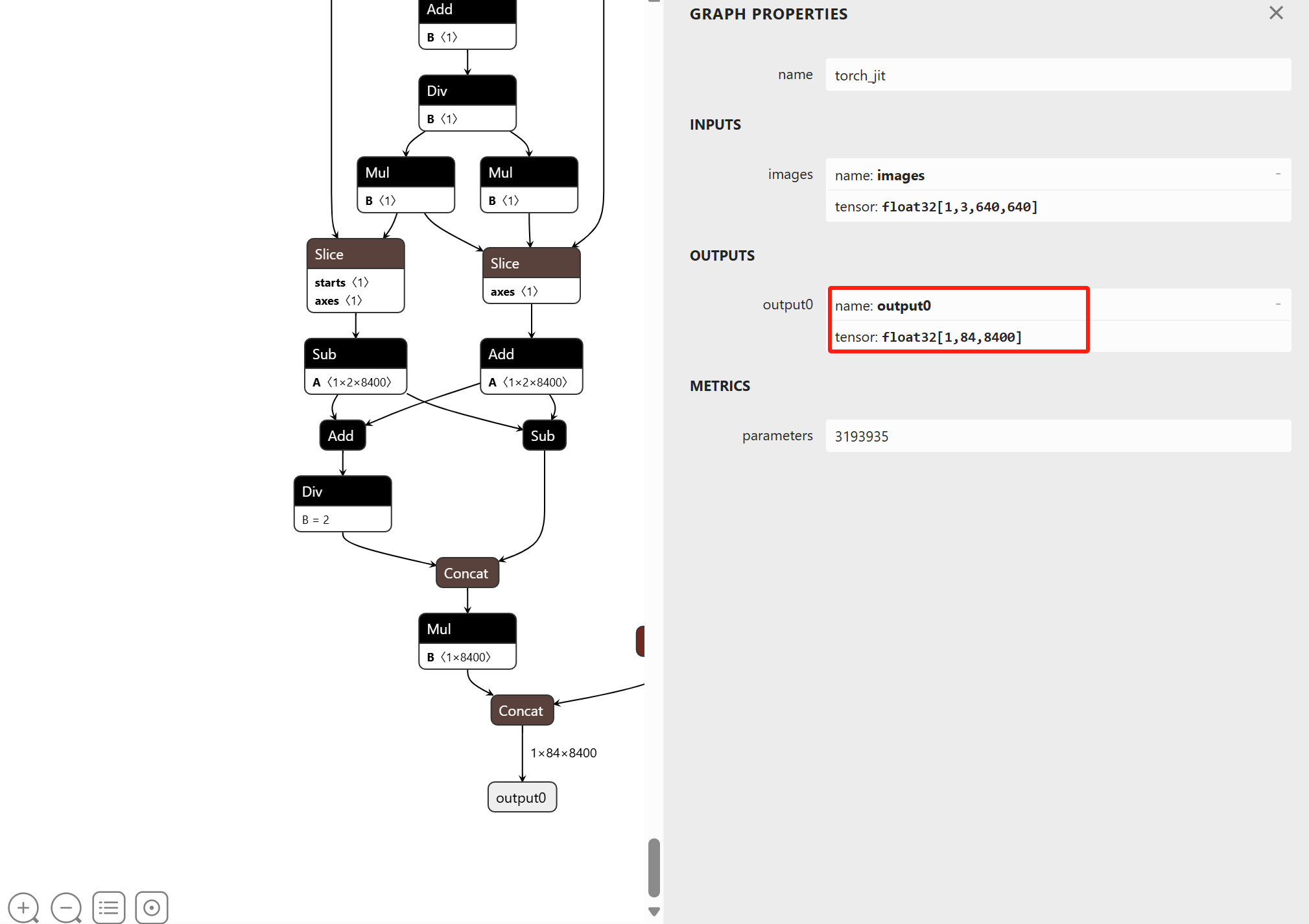
执行完成后,会生成 yolov8n.onnx 文件,输出形状是:
(1, 84, 8400)
 :
:
-
1 → batch size
-
84 → 每个目标的类别数 + 4 个 bbox 坐标 (COCO 为 80 类,所以 4 + 80 = 84)
-
8400 → 3 个检测层总 anchor 数(80×80 + 40×40 + 20×20 乘以 3)
三、 使用 ONNX Runtime 测试模型
导出后我们先用 onnxruntime 测试一下,确保模型能正常推理。
import onnxruntime as ort
import numpy as np
# 1. 创建推理 Session
ort_session = ort.InferenceSession("yolov8n.onnx", providers=['CUDAExecutionProvider'])
# 2. 构造测试输入
dummy_input = np.random.randn(1, 3, 640, 640).astype(np.float32)
# 3. 推理
outputs = ort_session.run(None, {ort_session.get_inputs()[0].name: dummy_input})
print("ONNX 输出 shape:", outputs[0].shape) # 应该是 (1, 84, 8400)

如果小伙伴想直接用onnx推理,那可以参考我的这一篇博客。【保姆级教程】YOLOv8 PyTorch 模型转 ONNX 并推理,包含图像preprocess和nms的postprocess全流程超详细!(小白也能学会)-CSDN博客
四、将 ONNX 转换为 TensorRT
4.1 trtexec 极速版
# FP16
trtexec –onnx=yolov8n.onnx \\
–saveEngine=yolov8n_fp16.trt \\
–fp16 \\
–workspace=4096
# INT8(需要校准数据,见下节)
trtexec –onnx=yolov8n.onnx \\
–saveEngine=yolov8n_int8.trt \\
–int8 \\
–calib=calib \\
–workspace=4096
4.2 Python API(推荐,可自定义后处理)
我们用 TensorRT Python API 完成转换。
import tensorrt as trt
# import pycuda.driver as cuda
# import pycuda.autoinit
# import numpy as np
# import os, glob, cv2
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
EXPLICIT_BATCH = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def GiB(x):
return x * 1 << 30
def build_engine(onnx_file_path, engine_file_path, mode='FP16'):
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(EXPLICIT_BATCH)
config = builder.create_builder_config()
parser = trt.OnnxParser(network, TRT_LOGGER)
config.max_workspace_size = GiB(4)
if mode == 'FP16':
config.set_flag(trt.BuilderFlag.FP16)
elif mode == 'INT8':
config.set_flag(trt.BuilderFlag.INT8)
# 这里可以绑定自定义 calibrator
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
engine = builder.build_engine(network, config)
with open(engine_file_path, 'wb') as f:
f.write(engine.serialize())
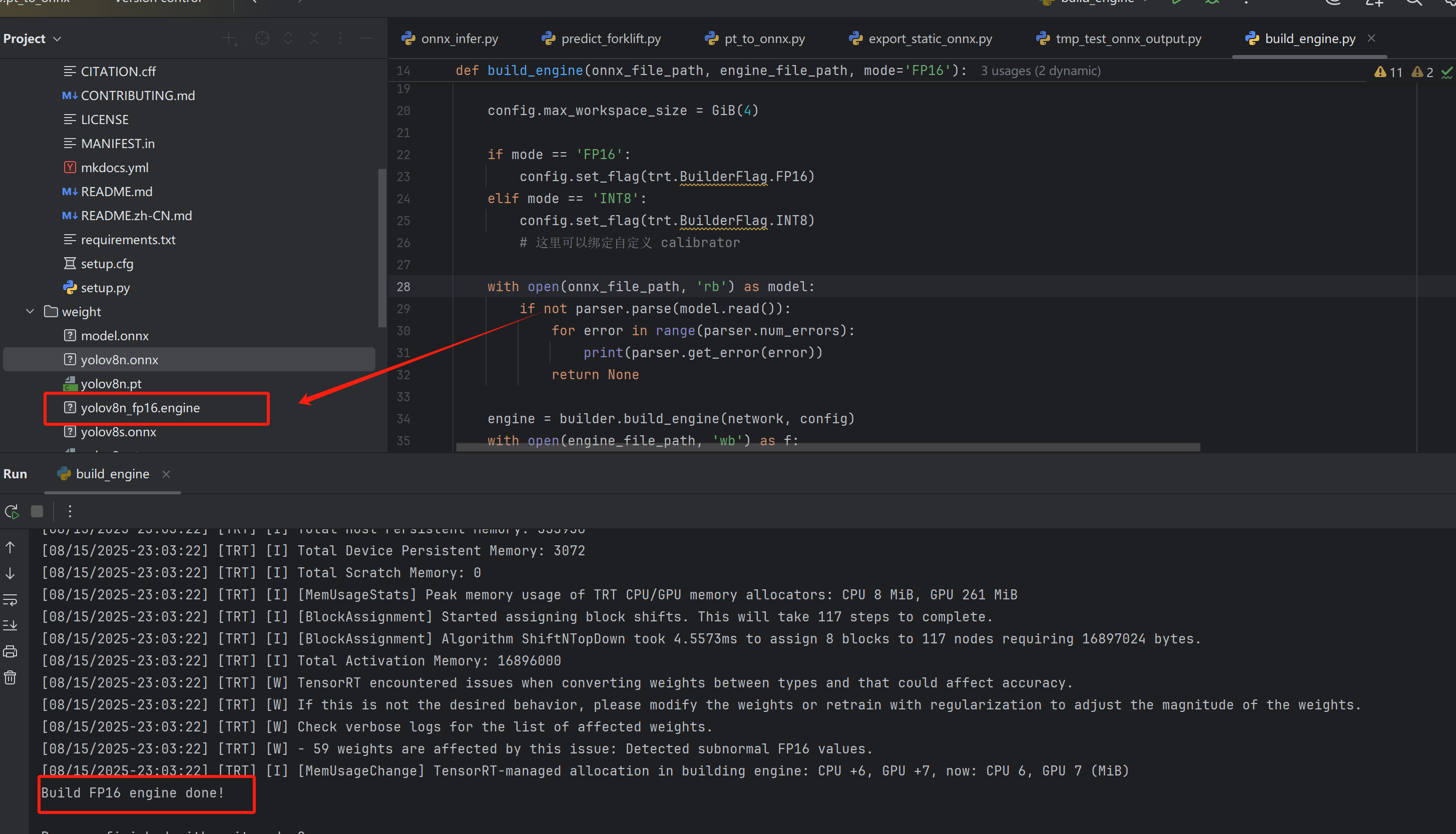
print(f"Build {mode} engine done!")
if __name__ == '__main__':
build_engine('yolov8n.onnx', 'yolov8n_fp16.engine', mode='FP16')
五、TensorRT 推理测试(输出 1×84×8400 解码)
TensorRT Engine 拿到的是 raw tensor,需要手动后处理。
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
# import torch
class YOLOv8TRT:
def __init__(self, engine_path):
logger = trt.Logger(trt.Logger.INFO)
with open(engine_path, 'rb') as f, trt.Runtime(logger) as runtime:
self.engine = runtime.deserialize_cuda_engine(f.read())
self.context = self.engine.create_execution_context()
self.stream = cuda.Stream()
# 绑定输入输出
self.bindings = []
for binding in self.engine:
size = trt.volume(self.engine.get_binding_shape(binding)) * 1
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
self.bindings.append(int(device_mem))
if self.engine.binding_is_input(binding):
self.host_input = host_mem
self.device_input = device_mem
else:
self.host_output = host_mem
self.device_output = device_mem
def infer(self, img_path):
img = cv2.imread(img_path)
img_in = cv2.resize(img, (640, 640))
img_in = img_in[:, :, ::-1].transpose(2,0,1).astype(np.float32) / 255.0
img_in = np.ascontiguousarray(img_in[None])
np.copyto(self.host_input, img_in.ravel())
cuda.memcpy_htod_async(self.device_input, self.host_input, self.stream)
self.context.execute_async_v2(self.bindings, self.stream.handle)
cuda.memcpy_dtoh_async(self.host_output, self.device_output, self.stream)
self.stream.synchronize()
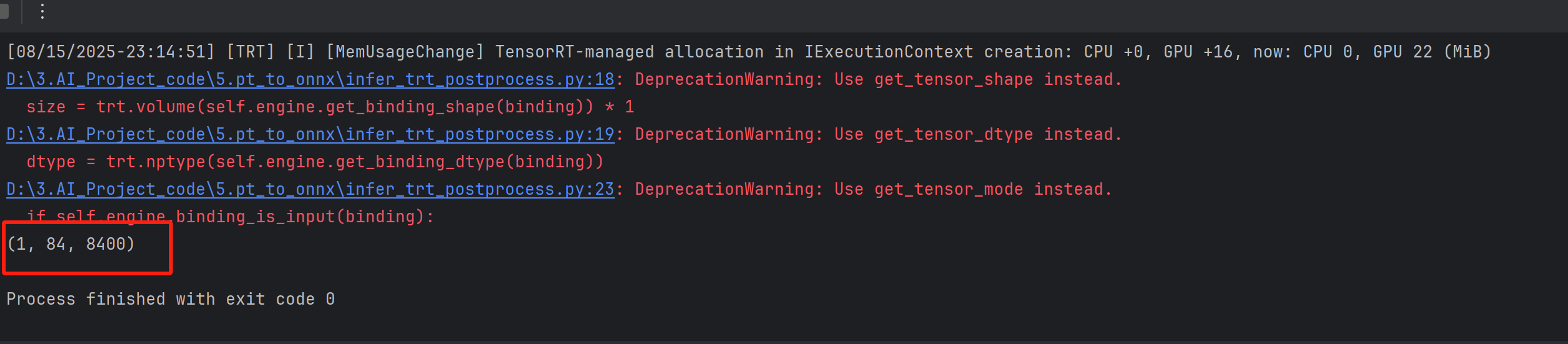
preds = self.host_output.reshape(1, 84, 8400)
return preds, img
# 后处理:置信度过滤 + NMS
def postprocess(preds, conf_thres=0.25, iou_thres=0.45):
pass
if __name__ == '__main__':
yolo = YOLOv8TRT('yolov8n_fp16.engine')
preds, img = yolo.infer('bus.jpg')
print(preds.shape)
#后续需要做NMS后处理
如果你不知道后续postprocess怎么写,可以参考博主上篇推理onnx的博客。【保姆级教程】YOLOv8 PyTorch 模型转 ONNX 并推理,包含图像preprocess和nms的postprocess全流程超详细!(小白也能学会)-CSDN博客
如果还是不会,关注留言,博主手把手教学。
如果发现pycuda安装失败,出现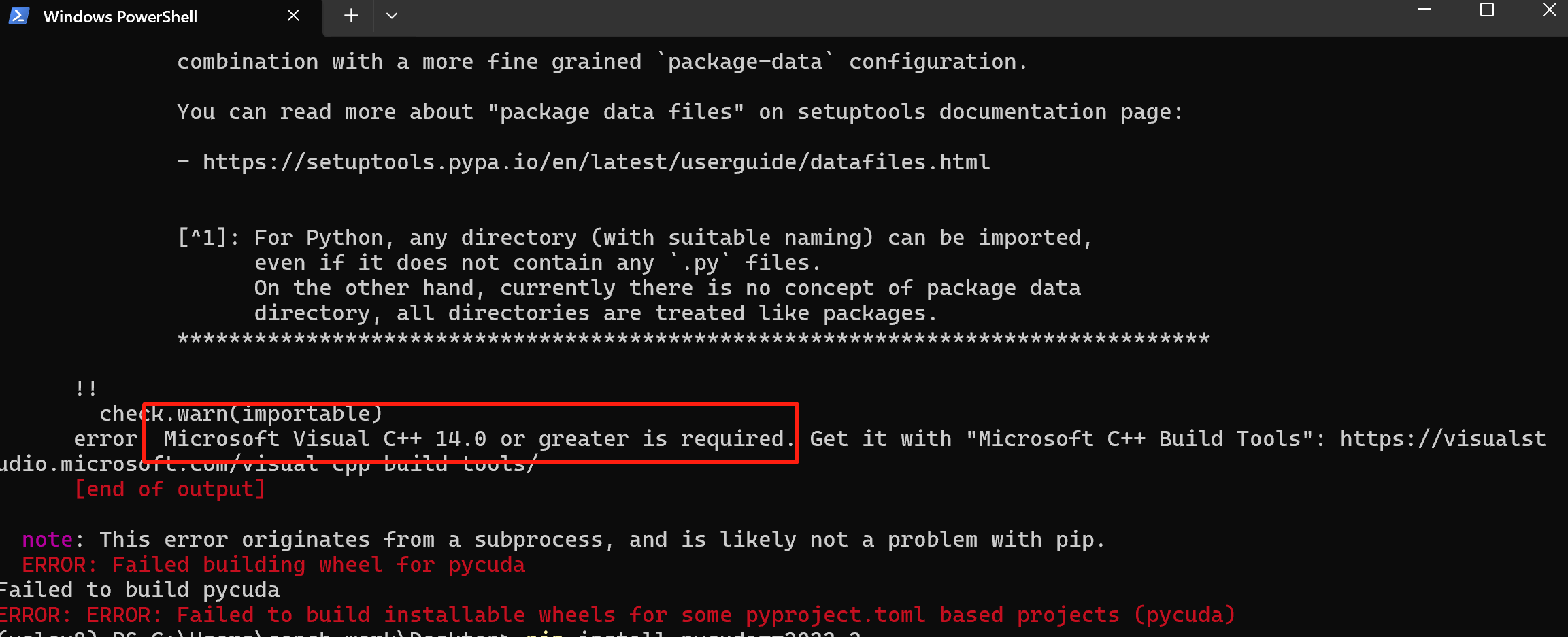 安装一下,重新启动电脑,再次暗转即可。
安装一下,重新启动电脑,再次暗转即可。
六、运行效果与速度对比
| PyTorch | 12.5 ms | 1.0× |
| ONNX | 10.8 ms | 1.16× |
| TensorRT FP16 | 4.3 ms | 2.9× |
⚡ 在 NVIDIA RTX 3060 上,TensorRT FP16 推理速度提升接近 3 倍,显存占用也有所降低。
📌 总结
本文实现了 YOLOv8 从 PyTorch → ONNX → TensorRT 的完整流程,支持输出 1×84×8400,并在 GPU 上实现了显著加速。 如果你需要在 Jetson、边缘计算设备 上部署 YOLOv8,这套方法同样适用,只需更换 TensorRT 的安装版本即可。









评论前必须登录!
注册