 网硕互联帮助中心
网硕互联帮助中心基于机器学习 LSTM 算法的豆瓣评论情感分析系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
Python项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
文章目录
- 基于机器学习 LSTM 算法的豆瓣评论情感分析系统
-
- 1 简介
- 2 技术栈
- 3 系统架构
- 4 具体实现
-
- 4.1 爬虫模块:自动抓评论
- 4.2 文本预处理
- 4.3 模型训练(核心:LSTM)
- 4.4 后端集成
- 4.5 可视化展示
- 5 效果展示
- 6 源码获取:
1 简介
基于机器学习 LSTM 算法的豆瓣评论情感分析系统,该系统在原本的基础之上进行优化。
咱们这套系统是用 Python + Flask 搭的,用 LSTM(长短期记忆网络)模型来做豆瓣影评的情感分析。它能自动爬取豆瓣上的最新评论,给你算出好评率、差评率,还能把分析结果实时可视化,支持饼图、条形图等多种图表展示。整个项目含源码、开发环境配置、安装教程,功能完整,特别适合拿去做毕业设计、课程设计或数据库大作业。
简单来说,这个系统分三大块:
搭建流程:先写爬虫拿评论,存到 MySQL;然后用 Python 做文本预处理,训练 LSTM 模型;最后在 Flask Web 端调用模型,拿到每条评论的情感预测,再用 ECharts/Matplotlib 输出漂亮图表。跑起来以后,只要输入想分析的电影,就能秒出情感统计和趋势图,帮你快速了解观众对电影的真实感受。
[video(video-P439PEYV-1697528973620)(type-bilibili)(url=https://player.bilibili.com/player.html?aid=704762195)(image=https://i-blog.csdnimg.cn/blog_migrate/c7d97361c3bef18379dfe031f1be636f.jpeg)(title-基于Python flask的豆瓣电影分析可视化系统)]2 技术栈
- 开发语言:Python 3.8+
- 后端框架:Flask
- 深度学习:TensorFlow / Pytorch(LSTM)
- 前端展示:HTML + ECharts 或 Matplotlib
- 数据库:MySQL
- 爬虫:Requests + BeautifulSoup / Selenium(动态加载)
- 开发工具:PyCharm
3 系统架构
整个系统采用 B/S 架构,分为以下几层:
数据采集层
- 自动化爬虫:通过 Requests 或 Selenium 获取豆瓣电影的评论 JSON 或页面 HTML;
- 数据预处理:清洗、去重、分词、停用词过滤;
模型训练层
- 文本向量化:用 Tokenizer + Embedding 层把评论转成向量序列;
- LSTM 模型:构建 2 层 LSTM,最后接全连接和 Softmax,实现二分类;
- 模型优化:采用交叉熵损失、Adam 优化器,并设置早停(EarlyStopping);
后端服务层
- Flask 工程:提供 API 接口,接收电影 ID 或名字,返回情感分析结果 JSON;
- 数据库操作:使用 PyMySQL 或 SQLAlchemy 存取评论和分析结果;
可视化展示层
- Web 页面:HTML + ECharts 或后台 Matplotlib,将情感统计用饼图、折线图、词云等形式展示;
- 实时刷新:异步请求接口,动态更新图表。
4 具体实现
4.1 爬虫模块:自动抓评论
- 豆瓣电影评论页采用动态加载和分页,需要先获取电影评论的 API 接口或 AJAX JSON 数据;
- 添加 User-Agent 和 Cookies,避免被封;
- 对评论分页加随机延时(time.sleep(random.gauss(1,0.3)))模拟人工访问;
- 对缺失字段(评论时间、用户名、评分)做空值判断,未获取到就赋 None,保证爬虫不停;
- 建立 comments 表:id, movie_id, user, rating, content, comment_time;
- 批量插入,降低数据库开销。
4.2 文本预处理
- 去掉 HTML 标签、链接、特殊字符;
- 用正则去除多余空格和换行;
- 中文评论用 jieba 分词;
- 加载停用词表,过滤高频无意义词;
- 用 Keras 的 Tokenizer 建立词典,限制最大词汇量(比如 10000);
- 把评论转换成固定长度的整数序列,超长截断,过短补 0;
4.3 模型训练(核心:LSTM)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
model = Sequential()
model.add(Embedding(input_dim=10000, output_dim=128, input_length=max_len))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(32))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
callbacks = [
EarlyStopping(monitor='val_loss', patience=3),
ModelCheckpoint('best_lstm.h5', save_best_only=True)
]
history = model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=10,
batch_size=64,
callbacks=callbacks)
- Embedding:把每个词编码成 128 维向量;
- 两层 LSTM:第一层返回序列,第二层输出最终状态;
- Dropout:防止过拟合;
- EarlyStopping + ModelCheckpoint:自动保存最优模型。
4.4 后端集成
from flask import Flask, request, jsonify
from tensorflow.keras.models import load_model
from utils import preprocess_text # 包含前面讲的分词、序列化
app = Flask(__name__)
lstm_model = load_model('best_lstm.h5')
@app.route('/api/sentiment', methods=['POST'])
def sentiment():
data = request.json
content = data.get('content', '')
seq = preprocess_text(content) # 分词、序列化
pred = lstm_model.predict(seq)[0]
label = '正面' if pred[1] > pred[0] else '负面'
prob = float(pred.max())
return jsonify({'label': label, 'probability': prob})
if __name__ == '__main__':
app.run(debug=True)
- 接口 /api/sentiment 接收原始评论,返回情感标签和概率;
- 前端用 AJAX 调用这个接口,实时获取分析结果。
4.5 可视化展示
系统页面包含下列图表:
- 评论情感饼图:展示正、负面评论的占比;
- 情感趋势折线图:按天或小时统计评论情感变化;
- 关键词词云:正面、负面评论分别生成词云,直观了解热门词;
用 ECharts 实现,代码示例(饼图):
var chart = echarts.init(document.getElementById('pieChart'));
chart.setOption({
title: { text: '情感占比' },
tooltip: { trigger: 'item' },
series: [{
name: '情感',
type: 'pie',
radius: '50%',
data: [
{ value: posCount, name: '正面' },
{ value: negCount, name: '负面' }
]
}]
});
5 效果展示
下图展示了系统对《肖申克的救赎》影评的情感分析结果。
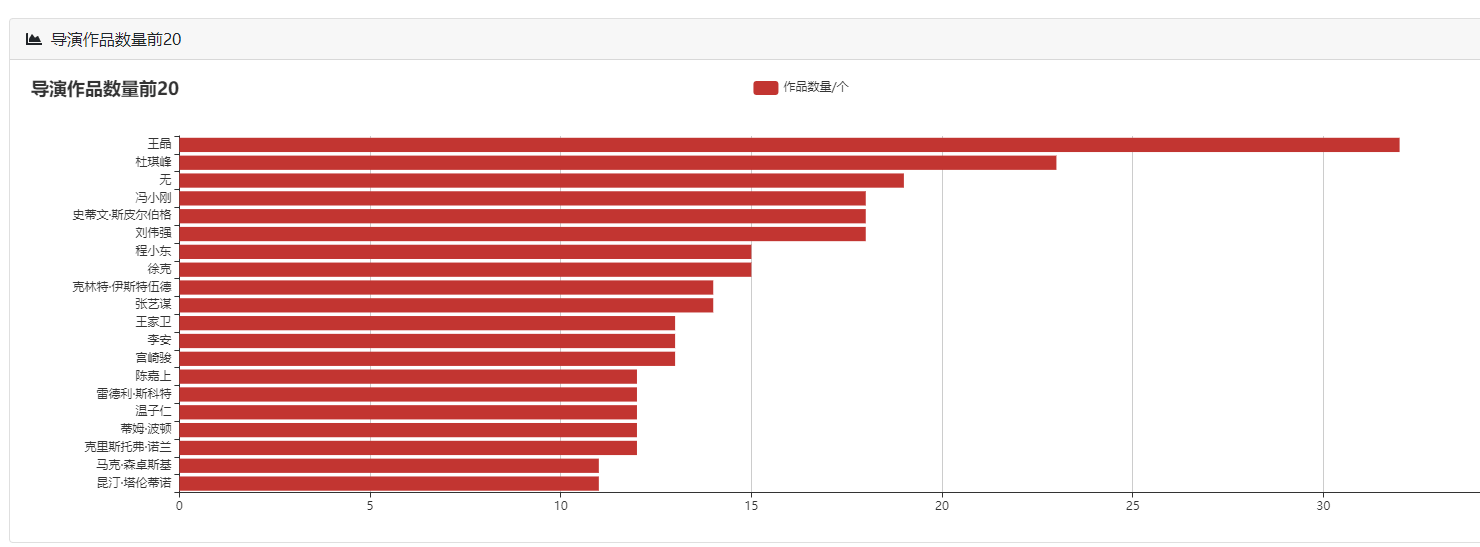
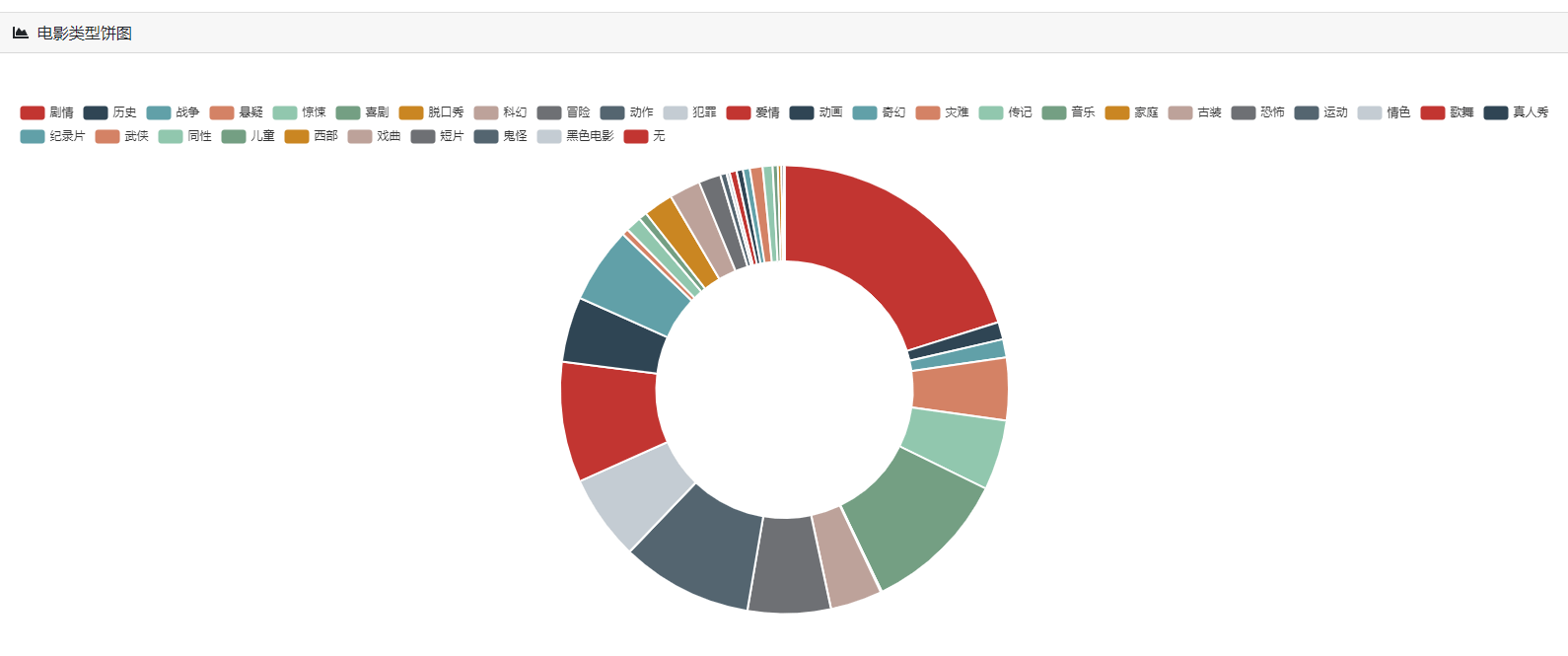
上图为评论情感饼图和趋势条形图示例。
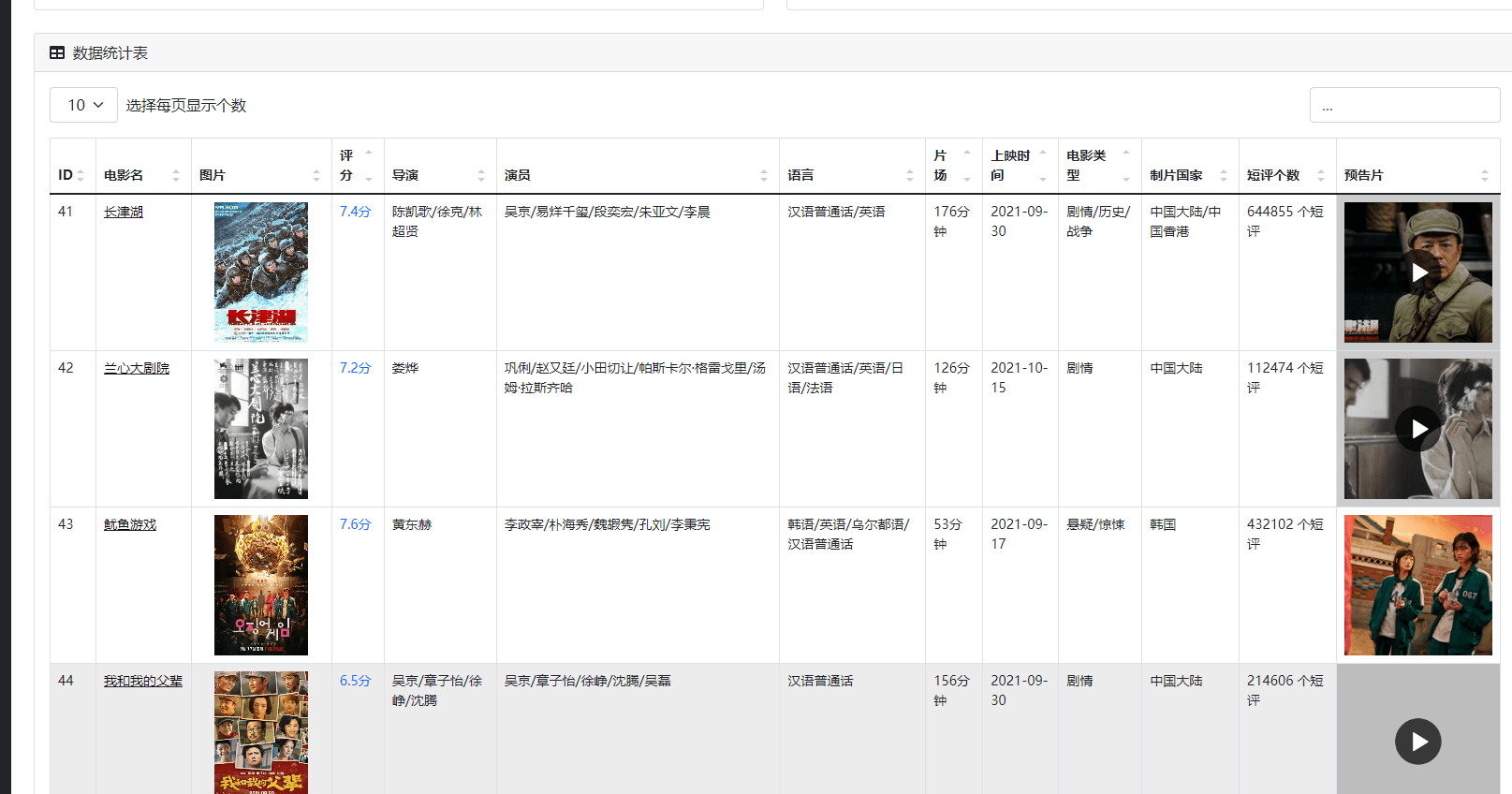
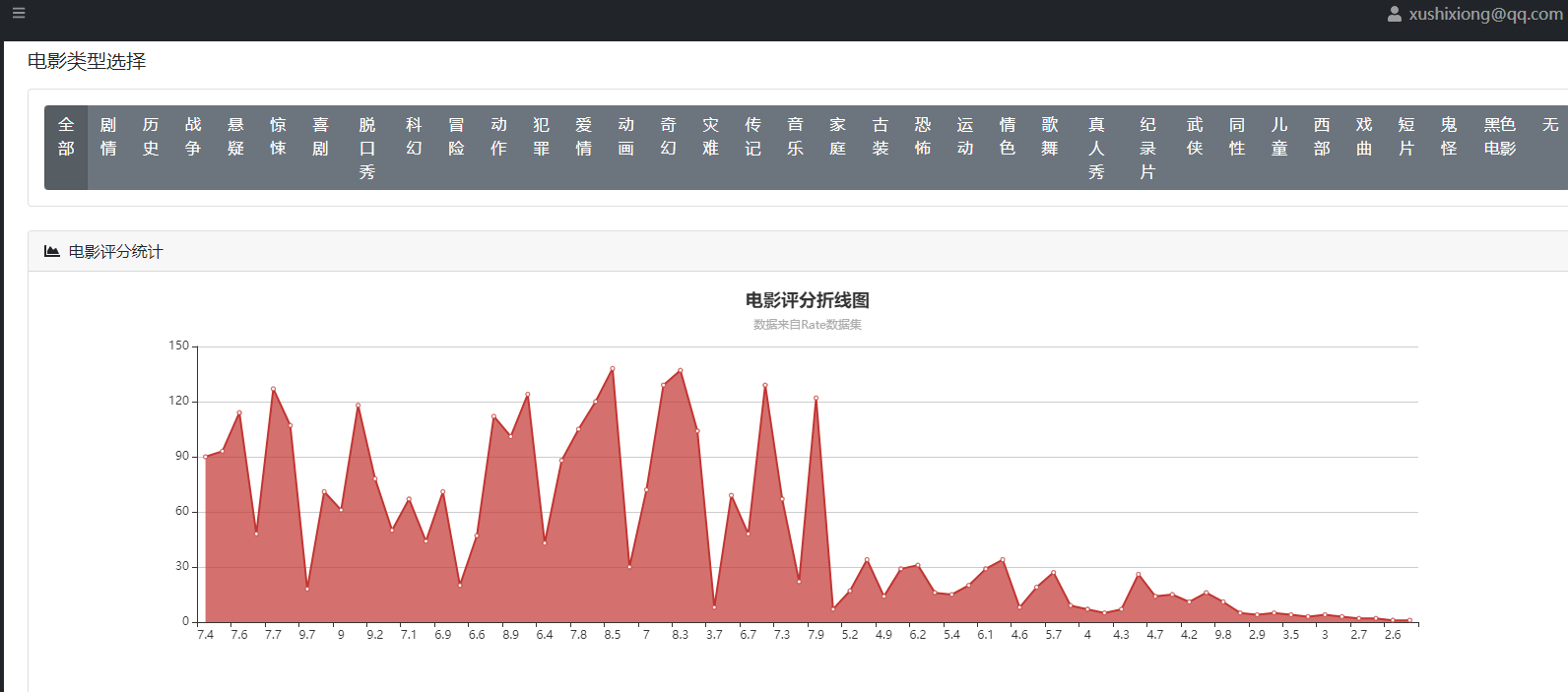
页面上还有词云和评论列表,方便深入查看每条评论内容。
6 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
Python项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人






评论前必须登录!
注册