 网硕互联帮助中心
网硕互联帮助中心博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈 Python、Django框架、MySQL/SQLite数据库、协同过滤推荐算法、requests爬虫、bootstrap3、js、jquery、django-rest-framework
功能模块
- 数据采集
- 电影信息展示与管理
- 用户交互(登录、注册、评分、收藏等)
- 电影推荐
- 后台数据管理
项目介绍 本电影推荐系统采用分层模型设计,前端基于bootstrap3、js、jquery实现页面展示,后端以Python+Django框架搭建,结合协同过滤推荐算法为核心,通过requests爬虫抓取豆瓣3000条电影数据存入数据库。系统支持电影多维度展示、分类排序、搜索,用户可完成登录、注册、评分、收藏等操作,后台可统一管控各类数据,同时针对冷启动问题优化推荐逻辑,能根据用户行为精准推荐电影,推荐准确率约75%,整体实现了预期的核心功能。
2、项目界面
(1)电影信息详情页面 展示电影的名称、海报、导演、主演等基础信息及剧情介绍,支持用户对电影进行评分、收藏,还设有 “前往观看”“点击收藏” 等操作按钮,同时呈现基于物品和用户的电影推荐内容,右侧还有最近更新的电影列表。 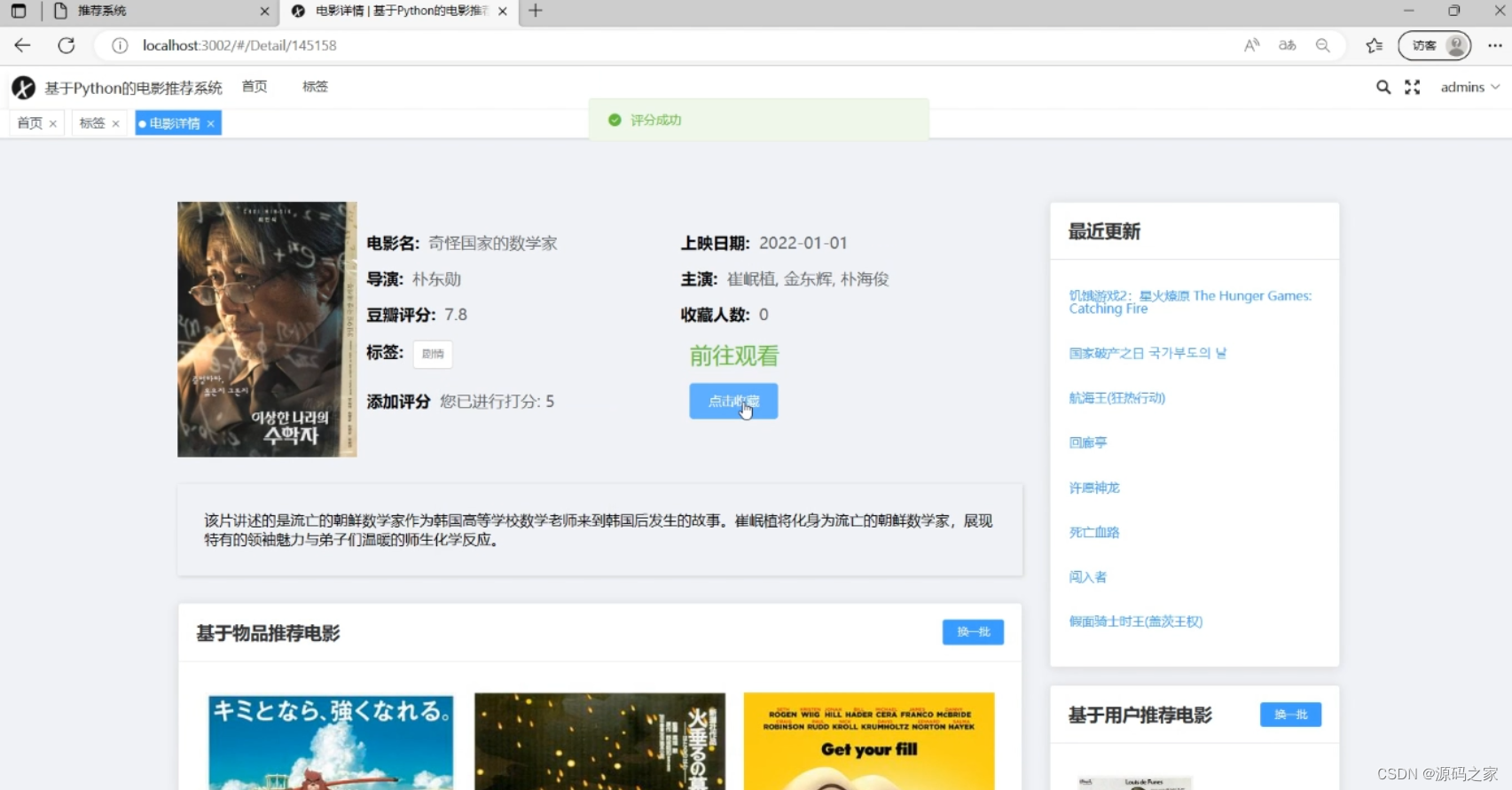
(2)系统首页,电影信息排序 支持按电影标签筛选及热度排序展示电影列表,呈现电影海报、名称与上映时间等信息,同时设有最近更新的电影列表区域,还提供基于用户的电影推荐板块及 “换一批” 功能,辅助用户快速浏览不同分类的电影内容。 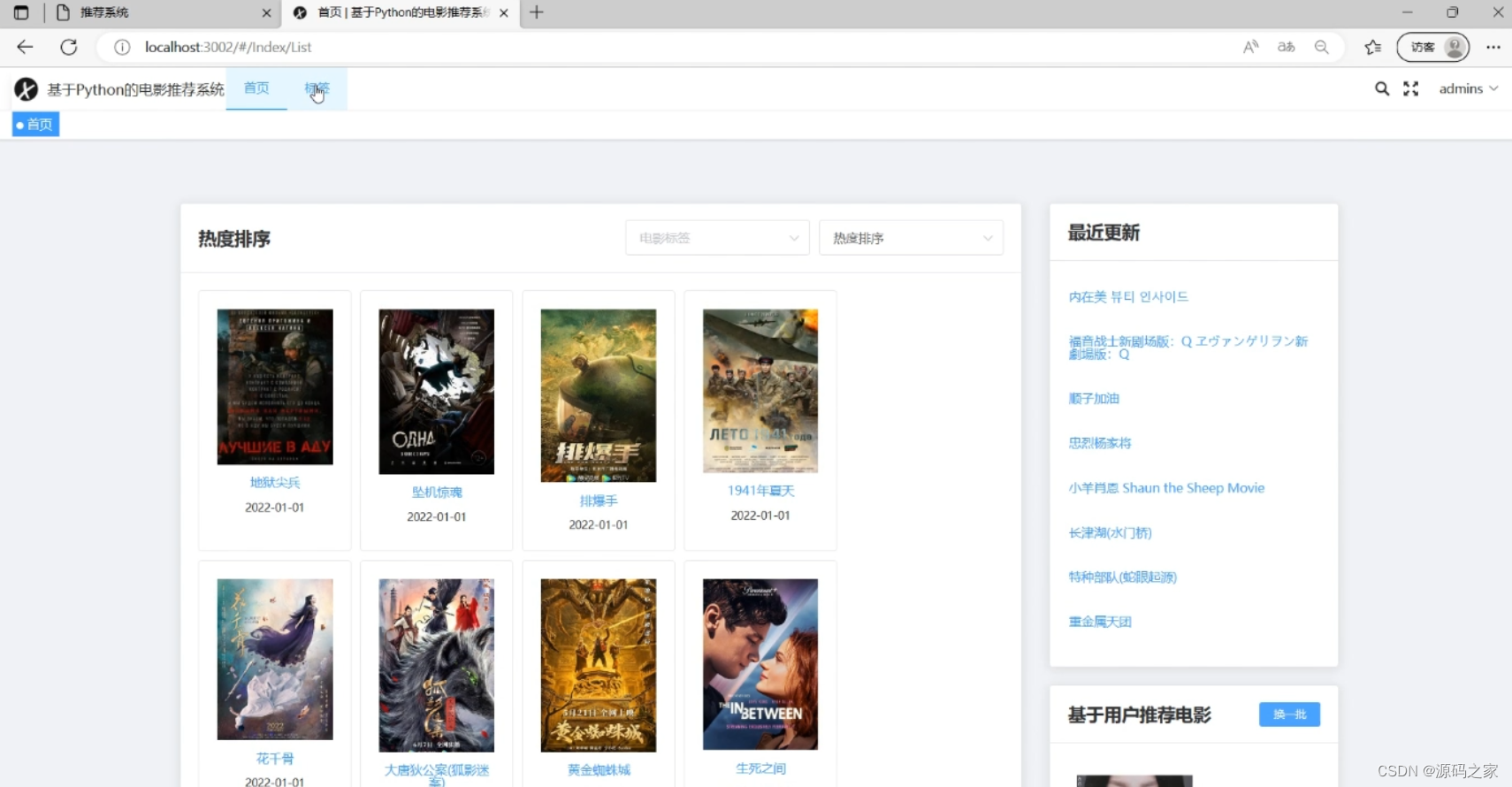
(3)我的收藏电影 展示用户收藏的电影列表,呈现电影名、导演、对应标签等信息,同时页面右侧设有最近更新的电影列表及基于用户的电影推荐板块,还支持 “换一批” 推荐功能,方便用户管理收藏内容与获取新推荐。 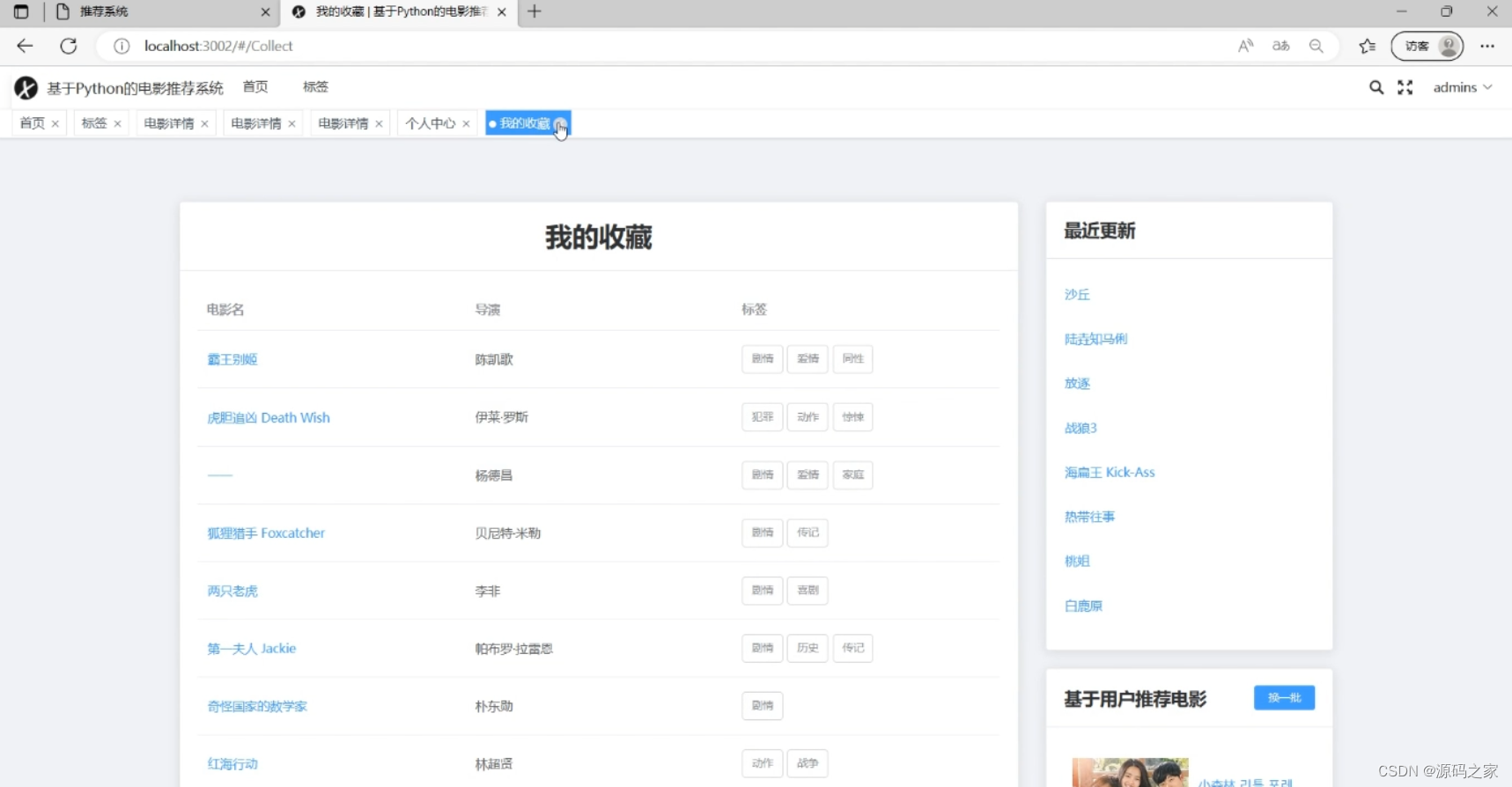
(4)后台数据管理 提供快捷操作入口,可对偏好、前台用户、标签、电影、评分信息等内容进行管理,还能处理权限、用户组相关设置,同时展示最近操作记录,辅助管理员统一管控系统内的各类数据与功能模块。 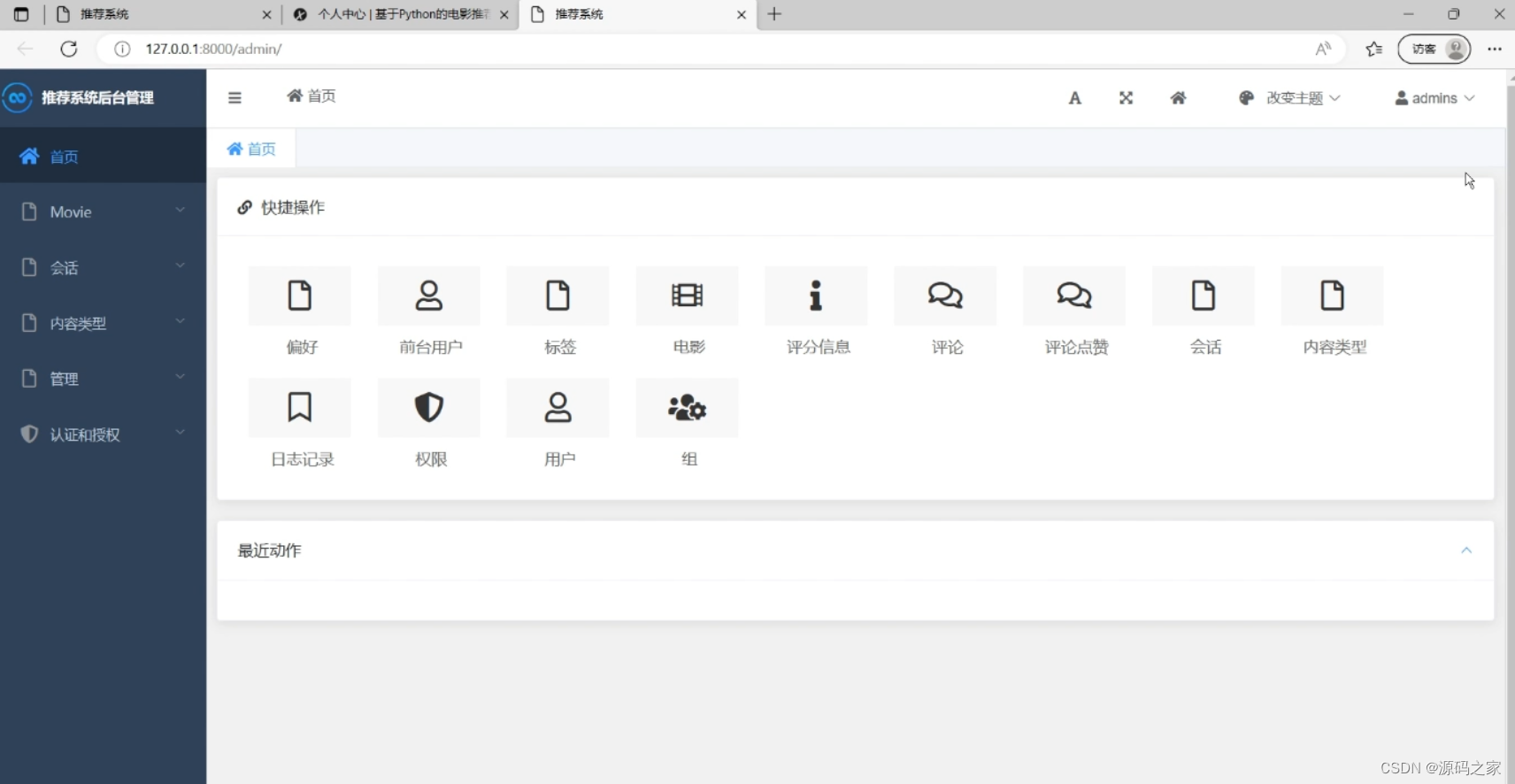
(5)电影信息管理 支持通过电影名称、导演、上映日期等条件搜索电影,可对电影信息执行增加、删除操作,同时展示电影的封面、名称、导演、国家、上映日期等详情内容,辅助管理员管理系统内的电影数据。 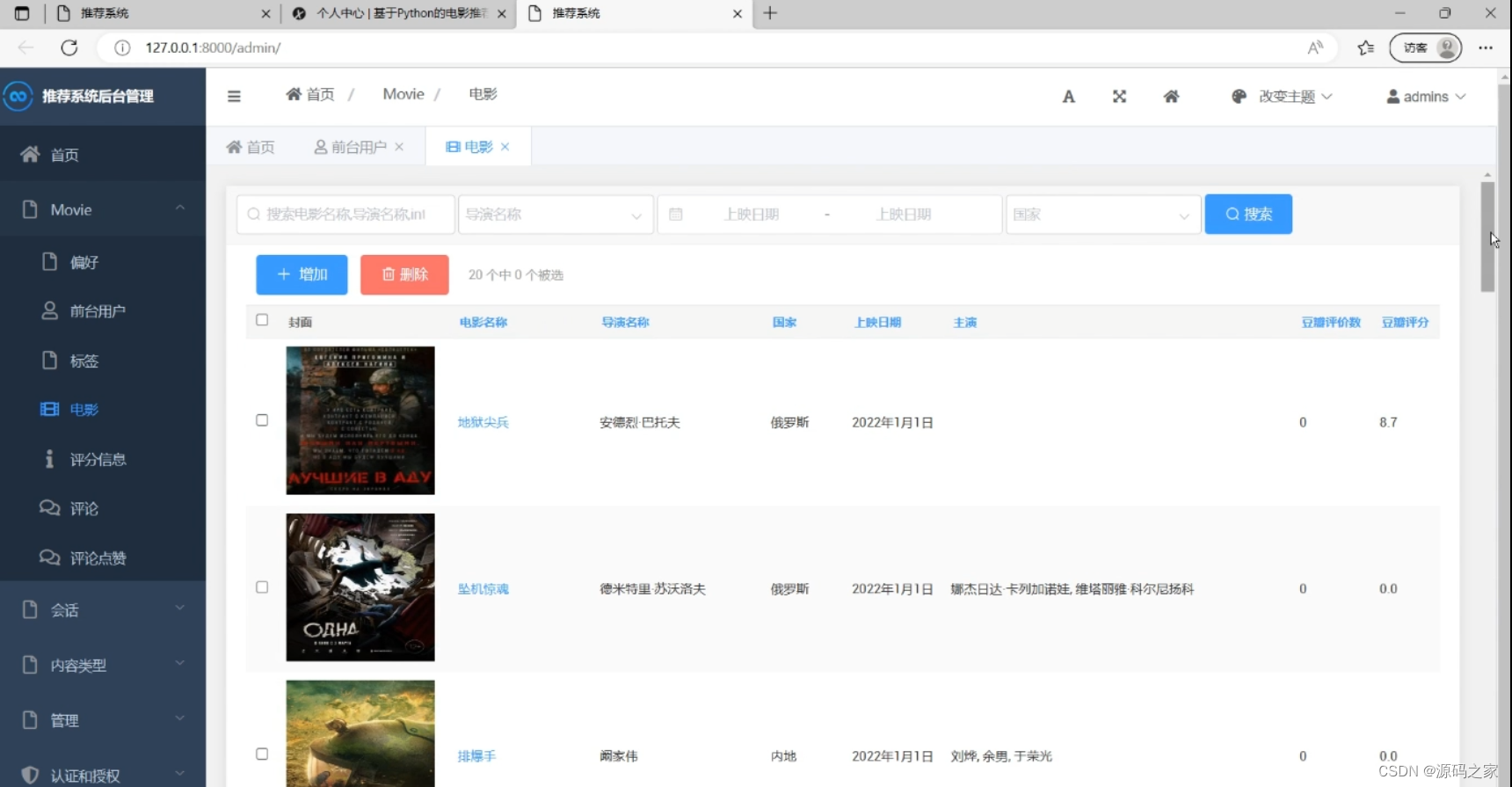
(6)数据采集页面 通过 Python 脚本配置请求头与目标 URL,设置多页链接范围后启动爬虫,抓取电影相关数据,过程中会显示数据抓取状态及电影信息,同时将采集到的内容同步记录,为系统提供数据支撑。 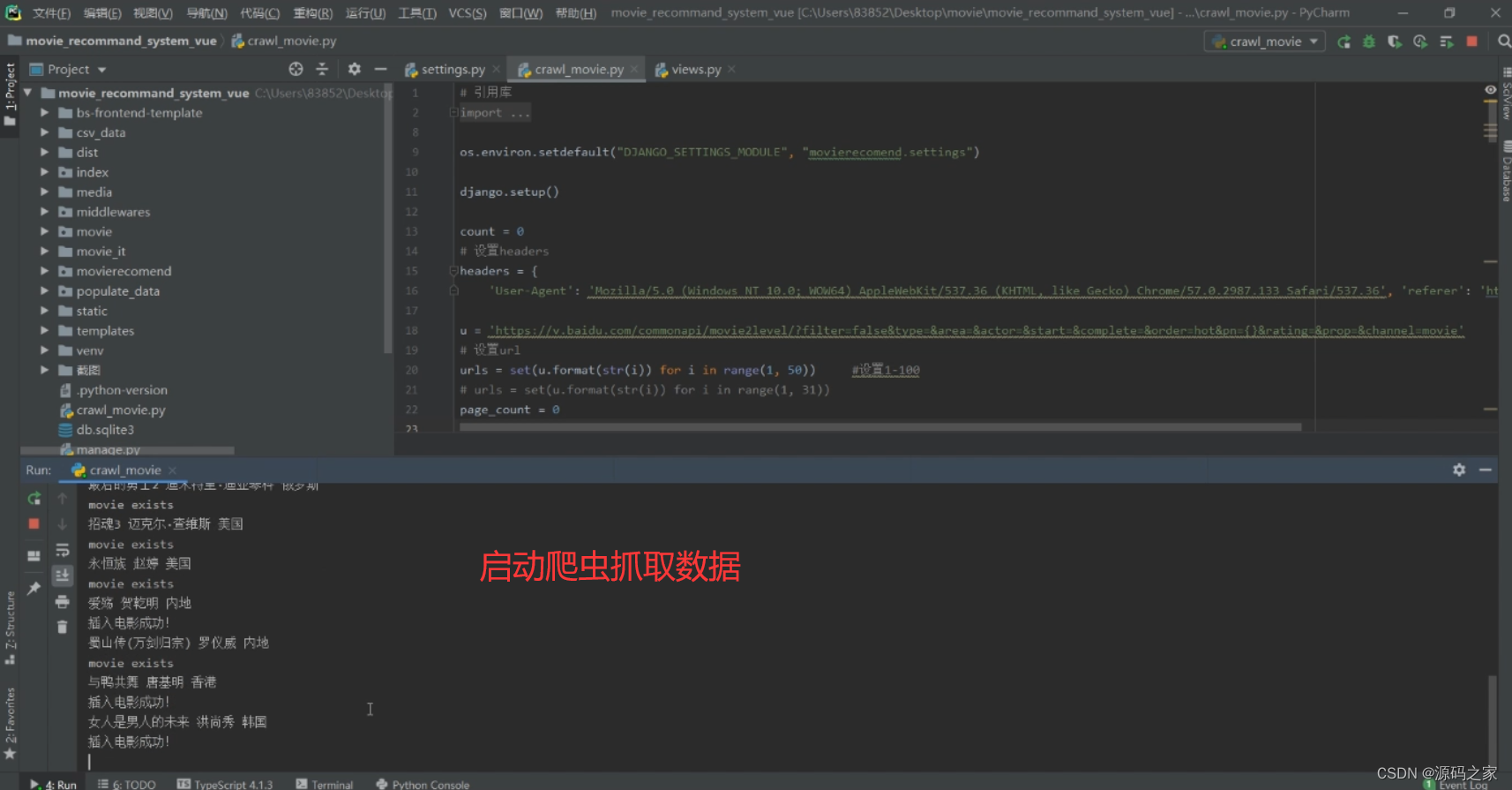
3、项目说明
一、技术栈 本项目以Python为核心开发语言,后端基于Django框架搭配django-rest-framework搭建MVC架构,前端采用bootstrap3、js、jquery实现页面交互;数据库支持SQLite3/MySQL,结合requests爬虫抓取豆瓣电影数据,核心运用协同过滤推荐算法实现电影智能推荐,整体构建起功能完整的电影推荐系统。
二、功能模块
- 数据采集:通过Python脚本配置请求头与目标URL,设定多页链接范围启动爬虫,抓取豆瓣电影的名称、海报、导演、上映信息等3000条数据,抓取过程实时展示状态并同步记录数据,为系统提供充足的数据源支撑。
- 电影信息展示与管理:前台支持按标签筛选、热度/时间/评分排序展示电影列表,详情页呈现电影海报、剧情介绍等完整信息;后台可通过名称、导演等条件搜索电影,执行增删操作,统一管控电影基础数据。
- 用户交互(登录、注册、评分、收藏等):提供用户注册、登录及信息修改功能,用户可对电影进行评分、收藏、评论,收藏页面可查看已收藏影片列表,满足用户个性化的观影交互需求。
- 电影推荐:基于用户和物品的协同过滤算法实现推荐,针对冷启动问题优化逻辑,以“相似度*评分”计算推荐值,根据用户点赞、收藏等行为推荐感兴趣的电影,推荐准确率约75%,还支持“换一批”刷新推荐内容。
- 后台数据管理:提供快捷操作入口,可管理用户偏好、前台用户、电影标签、评分信息等内容,处理权限与用户组设置,展示最近操作记录,实现系统数据的全维度管控。
三、项目总结 本电影推荐系统采用分层模型设计,从数据采集到智能推荐形成完整闭环。前端侧重用户体验,实现电影多维度展示与交互操作;后端依托Django框架保障系统稳定性,结合协同过滤算法解决智能推荐核心需求,还针对冷启动问题优化推荐逻辑。系统不仅能抓取并管理海量豆瓣电影数据,还能基于用户行为精准推荐影片,推荐准确率达75%,同时通过后台实现数据全生命周期管控,整体功能覆盖用户与管理员的核心需求,完成了预期的电影推荐与管理目标。
4、核心代码
# -*-coding:utf-8-*-
import os
os.environ["DJANGO_SETTINGS_MODULE"] = "movie.settings"
import django
django.setup()
from movie.models import *
from math import sqrt, pow
import operator
from django.db.models import Subquery,Q,Count
# from django.shortcuts import render,render_to_response
class UserCf:
# 获得初始化数据
def __init__(self, all_user):
self.all_user = all_user
# 通过用户名获得列表,仅调试使用
def getItems(self, username1, username2):
return self.all_user[username1], self.all_user[username2]
# 计算两个用户的皮尔逊相关系数
def pearson(self, user1, user2): # 数据格式为:物品id,浏览
sum_xy = 0.0 # user1,user2 每项打分的的累加
n = 0 # 公共浏览次数
sum_x = 0.0 # user1 的打分总和
sum_y = 0.0 # user2 的打分总和
sumX2 = 0.0 # user1每项打分平方的累加
sumY2 = 0.0 # user2每项打分平方的累加
for movie1, score1 in user1.items():
if movie1 in user2.keys(): # 计算公共的浏览次数
n += 1
sum_xy += score1 * user2[movie1]
sum_x += score1
sum_y += user2[movie1]
sumX2 += pow(score1, 2)
sumY2 += pow(user2[movie1], 2)
if n == 0:
# print("p氏距离为0")
return 0
molecule = sum_xy – (sum_x * sum_y) / n # 分子
denominator = sqrt((sumX2 – pow(sum_x, 2) / n) * (sumY2 – pow(sum_y, 2) / n)) # 分母
if denominator == 0:
return 0
r = molecule / denominator
return r
# 计算与当前用户的距离,获得最临近的用户
def nearest_user(self, current_user, n=1):
distances = {}
# 用户,相似度
# 遍历整个数据集
for user, rate_set in self.all_user.items():
# 非当前的用户
if user != current_user:
distance = self.pearson(self.all_user[current_user], self.all_user[user])
# 计算两个用户的相似度
distances[user] = distance
closest_distance = sorted(
distances.items(), key=operator.itemgetter(1), reverse=True
)
# 最相似的N个用户
print("closest user:", closest_distance[:n])
return closest_distance[:n]
# 给用户推荐电影
def recommend(self, username, n=3):
recommend = {}
nearest_user = self.nearest_user(username, n)
for user, score in dict(nearest_user).items(): # 最相近的n个用户
for movies, scores in self.all_user[user].items(): # 推荐的用户的电影列表
if movies not in self.all_user[username].keys(): # 当前username没有看过
if movies not in recommend.keys(): # 添加到推荐列表中
recommend[movies] = scores*score
# 对推荐的结果按照电影
# 浏览次数排序
return sorted(recommend.items(), key=operator.itemgetter(1), reverse=True)
# 基于用户的推荐
def recommend_by_user_id(user_id):
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
movie_list = Movie.objects.filter(tags__in=user_prefer)[:15]
else:
movie_list = Movie.objects.order_by("-num")[:15]
return movie_list
# 选取评分最多的10个用户
users_rate = Rate.objects.values('user').annotate(mark_num=Count('user')).order_by('-mark_num')
user_ids = [user_rate['user'] for user_rate in users_rate]
user_ids.append(user_id)
users = User.objects.filter(id__in=user_ids)#users 为评分最多的10个用户
all_user = {}
for user in users:
rates = user.rate_set.all()#查出10名用户的数据
rate = {}
# 用户有给电影打分 在rate和all_user中进行设置
if rates:
for i in rates:
rate.setdefault(str(i.movie.id), i.mark)#填充电影数据
all_user.setdefault(user.username, rate)
else:
# 用户没有为电影打过分,设为0
all_user.setdefault(user.username, {})
user_cf = UserCf(all_user=all_user)
recommend_list = [each[0] for each in user_cf.recommend(current_user.username, 15)]
movie_list = list(Movie.objects.filter(id__in=recommend_list).order_by("-num")[:15])
other_length = 15 – len(movie_list)
if other_length > 0:
fix_list = Movie.objects.filter(~Q(rate__user_id=user_id)).order_by('-collect')
for fix in fix_list:
if fix not in movie_list:
movie_list.append(fix)
if len(movie_list) >= 15:
break
return movie_list
# 计算相似度
def similarity(movie1_id, movie2_id):
movie1_set = Rate.objects.filter(movie_id=movie1_id)
# movie1的打分用户数
movie1_sum = movie1_set.count()
# movie_2的打分用户数
movie2_sum = Rate.objects.filter(movie_id=movie2_id).count()
# 两者的交集
common = Rate.objects.filter(user_id__in=Subquery(movie1_set.values('user_id')), movie=movie2_id).values('user_id').count()
# 没有人给当前电影打分
if movie1_sum == 0 or movie2_sum == 0:
return 0
similar_value = common / sqrt(movie1_sum * movie2_sum)#余弦计算相似度
return similar_value
#基于物品
def recommend_by_item_id(user_id, k=15):
# 前三的tag,用户评分前三的电影
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
user_prefer = list(user_prefer)[:3]
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
movie_list = Movie.objects.filter(tags__in=user_prefer)[:15]
else:
movie_list = Movie.objects.order_by("-num")[:15]
print('from here')
return movie_list
# most_tags = Tags.objects.annotate(tags_sum=Count('name')).order_by('-tags_sum').filter(movie__rate__user_id=user_id).order_by('-tags_sum')
# 选用户最喜欢的标签中的电影,用户没看过的30部,对这30部电影,计算距离最近
un_watched = Movie.objects.filter(~Q(rate__user_id=user_id), tags__in=user_prefer).order_by('?')[:30] # 看过的电影
watched = Rate.objects.filter(user_id=user_id).values_list('movie_id', 'mark')
distances = []
names = []
# 在未看过的电影中找到
for un_watched_movie in un_watched:
for watched_movie in watched:
if un_watched_movie not in names:
names.append(un_watched_movie)
distances.append((similarity(un_watched_movie.id, watched_movie[0]) * watched_movie[1], un_watched_movie))#加入相似的电影
distances.sort(key=lambda x: x[0], reverse=True)
print('this is distances', distances[:15])
recommend_list = []
for mark, movie in distances:
if len(recommend_list) >= k:
break
if movie not in recommend_list:
recommend_list.append(movie)
# print('this is recommend list', recommend_list)
# 如果得不到有效数量的推荐 按照未看过的电影中的热度进行填充
print('recommend list', recommend_list)
return recommend_list
if __name__ == '__main__':
similarity(2003, 2008)
recommend_by_item_id(1)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻









评论前必须登录!
注册