 网硕互联帮助中心
网硕互联帮助中心今天遇到有人咨询FAD(Functional attribute diversity)应该怎么计算,说在网上查不到相关资料。这个指数是Walkeret et al.在1999年提出的,它的定义也非常简单:
F
A
D
=
∑
i
S
∑
j
S
d
i
j
FAD=∑_i^S∑_j^Sd_{ij }
FAD=i∑Sj∑Sdij 其中
d
i
j
d_{ij }
dij是物种
i
i
i与物种
j
j
j之间的功能距离。简单来说FAD就是所有物种队之间功能距离的总和。
在R中的计算也十分简单,sum(dist(data))就可以直接得出结果。 这个指标不会讲物种多度考虑进来,所以已经不怎么单拎出来用了。
下面结合其他的功能多样性指数讲一讲在R中如何计算功能多样性指数以及数据应该整理成什么样的格式。
首先是数据的整理,我们需要两组数据,一组是功能性状,一组是群落物种多度数据。 功能性状整理成行是物种,列是功能性状,数值为原始测量值的格式
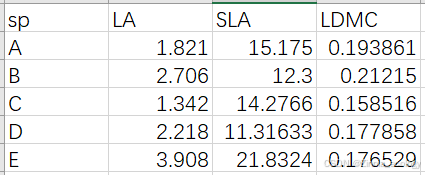 群落数据整理成行是样方,列是物种,数值为多度的格式。
群落数据整理成行是样方,列是物种,数值为多度的格式。
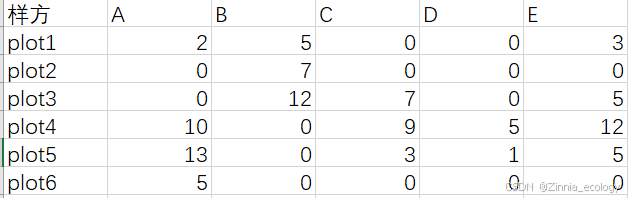
随后将数据导入R中
com<-read.csv("site-sp-abundance.csv",header = TRUE,row.names=1)
trait<-read.csv("trait.csv",header = TRUE,row.names = 1)
FAD的计算为:
FAD<-sum(dist(trait))
如果性状数据有分类变量,一定要提前用数值代替分类指标。
功能多样性的计算通过FD包完成。
我们使用FD包中的dbFD函数结合物种的多度计算功能多样性丰富度(Functional Richness, FRic),功能多样性均匀度(Functional Evenness,FEve)以及功能分异度(Functional Divergence,FDiv)以及功能离散度(Rao’s Quadratic Entropy,RaoQ)。
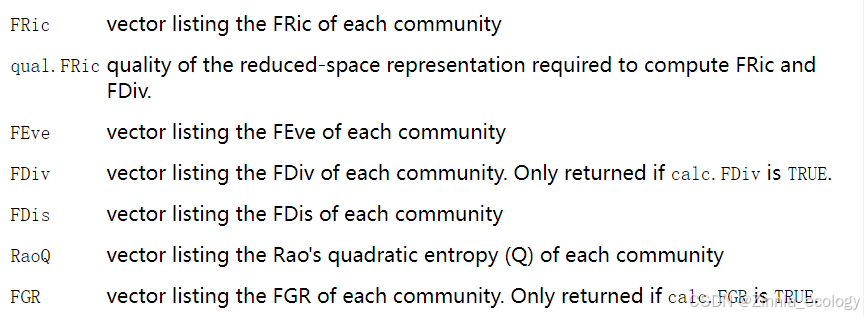
在R中运行dbFD函数,即可获得以上功能多样性指标
library(FD)
dbfd_result <- dbFD(trait,com)
write.csv(dbfd_result,"dbfd_result.csv")






评论前必须登录!
注册