 网硕互联帮助中心
网硕互联帮助中心大家读完觉得有帮助记得关注和点赞!!!
摘要
随着可编程网络硬件的出现,越来越多的功能可以从运行在通用CPU上的软件转移到网卡。早期的网卡只允许卸载固定功能,如校验和计算。近期的网卡,如Nvidia Bluefield-3,允许完全可编程的数据平面。在本文中,我们介绍了我们在Bluefield-3上运行名为XenoFlow的负载均衡器的初步步骤。此外,我们展示了Bluefield-3 eSwitch的能力和局限性。我们的结果表明,在流管道中仅有2个条目时,Bluefield-3无法达到线速。然而,我们也展示了在网卡上进行硬件卸载以及更靠近网络的优势。使用XenoFlow,与在主机上运行的可比eBPF负载均衡器相比,我们实现了延迟降低44%。此外,XenoFlow即使在高负载下也能实现这种低延迟。
1 引言
负载均衡器是现代数据中心的核心组件。它们将流量分发到多个服务器,这使得服务可以扩展到超出单个节点容量的范围。负载均衡器可以根据OSI模型不同层的信息来分发流量。在这项工作中,我们专注于第3层/第4层负载均衡器,它们基于IP和TCP/UDP头部来分发流量。由于大多数服务存储有状态信息,每连接一致性 [1] 是负载均衡器的一个核心要求。
历史上,L4负载均衡器是在用户空间 [2] 或内核空间 [3] 的软件中实现的。由于通用的Linux网络栈限制了负载均衡器的性能,先前的工作已使用DPDK [4] 或类似技术 [5, 6] 绕过Linux网络栈,将负载均衡器移至用户空间。随着eBPF & XDP [7] 的引入,可以在数据包被Linux网络栈处理之前实现L4负载均衡器。Katran [8] 是这种基于eBPF的L4负载均衡器的一个著名例子,它在Linux内核eBPF虚拟机中用几百行C代码实现。虽然这种方法非常高效,但它仍然使用CPU处理数据包,并将数据包复制到主内存并返回到网卡。
为了实现更高的吞吐量,SilkRoad [9] 项目将L4负载均衡器移至更靠近网络的位置,并将负载均衡器卸载到网络路径中的可编程交换机上。作者证明,这仍然需要数据中心中的软件组件来实现每连接一致性。
本文研究了在Nvidia Bluefield-3智能网卡上运行名为XenoFlow的L3负载均衡器的初步步骤。虽然有工作在Bluefield-3上实现L7和L4负载均衡器 [10, 11, 12],但据我们所知,所有这些工作仍然部分运行在Bluefield-3的通用ARM核心上,从而限制了性能。
Nvidia将Bluefield-3宣传为400 Gbit/s的基础设施计算平台,其NIC子系统(DPA + eSwitch)以线速加速数据路径 [13, 14]。虽然Chen等人 [15] 已经表明,对于仅发送或接收64字节数据包的情况,Bluefield-3 DPA无法达到线速,但这尚未针对eSwitch进行研究。
在此,我们展示在Bluefield-3上初步步骤的结果,以回答以下研究问题:
RQ1:我们能否使用Bluefield DOCA Flow API实现一个简单的负载均衡器?
RQ2:DOCA Flow应用程序是否以零开销处理,即在最大吞吐量以下是否没有数据包被丢弃?
RQ3:使用DOCA Flow API实现的负载均衡器,BlueField-3能否达到线速?
RQ4:我们的负载均衡器如何影响端到端延迟?
RQ5:负载如何影响负载均衡器的性能?
本文组织如下:首先我们回顾相关工作,接着描述Bluefield-3的相关硬件组件和软件栈。然后我们在第4节介绍XenoFlow的设计和实现,并在第5节展示我们的初步性能结果。最后,我们讨论开放的挑战和未来的工作。
2 相关工作
本节讨论与Bluefield智能网卡相关的工作。
Liu等人 [16] 比较了BlueField-2 ARM核心与12个不同x86服务器和2个ARM服务器的性能。所有服务器具有相似的核心数量和时钟速度。他们发现,BlueField-2的性能能力落后于x86服务器,除了BlueField-2有针对其加速器的工作负载,例如Linux加密API af-alg。此外,他们发现使用pktgen时,ARM核心无法饱和100 Gbit/s网卡的带宽。
Michalowicz等人 [11] 从HPC的角度比较了Bluefield-2和Bluefield-3。作者测量了在DPU上运行利用MVAPICH MPI库的OSU-Benchmarks时的DPU间延迟和带宽。DPU间基准测试显示,与Bluefield-2相比,Bluefield-3的延迟提高了1.78倍,网络带宽提高了1.5倍。作者将此归因于Bluefield 3增加的带宽。然而,即使对于16KiB的消息,达到的带宽也低于10 GB/s。
在使用支持DPU的MPI库的应用程序上下文中,作者展示了与主机系统相比,修改后的P3DFFT应用程序有较小的改进。
随着Bluefield-3的推出,Nvidia引入了数据路径加速器(DPA),他们将其描述为"拥有许多可以并行工作的执行单元,以克服延迟问题(例如访问主机内存)并提供整体更高的吞吐量" [14]。然而,Chen等人 [15] 表明DPA核心比ARM和主机核心弱得多。此外,如果数据包大小超过1KB,DPA必须依赖较慢的ARM/主机内存才能达到线速。在实验中,对于任何数据包大小,DPA都没有达到ARM或主机核心的网络吞吐量。然而,在像时钟同步这样的延迟关键型应用中,DPA实现了比ARM/主机核心低2倍的时间不确定界限。此外,作者从他们的实验中得出了如何改进DPA设计的建议:"为DPA直接附加一个内存"和"为DPA配备更强大的缓存"。
Cui等人 [12, 17] 提出了一个用于BlueField-2的名为Laconic的L7负载均衡器。请求解析逻辑在DPU的ARM核心上执行。因为作者测量到高达305微秒的规则插入延迟,他们决定仅将大流的回复数据包重写卸载到eSwitch。较小的流完全在ARM核心上处理,限制了小流的性能。对于4 MB或更大的流,Laconic优于基于x86的nginx负载均衡器。这显示了Bluefield eSwitch在数据包重写方面的强大能力。
3 Bluefield-3
在此,我们介绍Bluefield-3的硬件特性和软件API,特别是那些对实现XenoFlow有趣的部分。
3.1 硬件特性
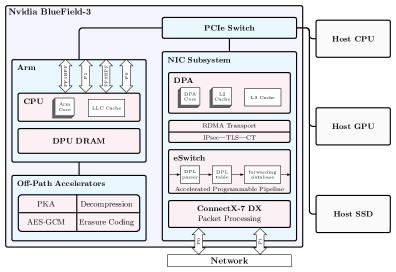
图1:Nvidia Bluefield-3 DPU的架构。
Bluefield-3由以下组件组成,如图1所示:
16个运行Linux的ARM核心(路径外),
路径外加速器,有时也称为旁路加速器:AES-GCM、解压缩等,
加速可编程管道(APP),由64–128个数据包处理核心组成(路径上),以及
数据路径加速器(DPA),由16个超线程的I/O和数据包处理核心 [18] 组成(路径上)。
虽然APP和DPA核心是路径上的,意味着它们在默认数据路径中处理每个数据包,但ARM核心和旁路加速器是路径外的。只有当数据平面将数据包转发给它们时,它们才处理数据包。
如第2节所述,已有多个工作将负载均衡器部署到Bluefield-3 ARM核心和DPA上。这项工作侧重于使用DOCA Flow API在加速可编程管道(APP)上实现负载均衡器(见第3.2节)。
虽然Nvidia文档说明APP由64–128个数据包处理核心组成,但没有更多细节描述这些核心的类型或能力。然而,Nvidia的营销材料承诺以线速进行数据包处理 [13, 14]。此外,在查看物理Bluefield-3硬件时,只能看到ARM核心和DPA的芯片。这使得有必要依赖基准测试来确定数据包处理核心的能力。
尽管DOCA Flow API文档从未提及APP,但它指出创建的规则在eSwitch上执行。由于"现代网络控制器具有复杂的嵌入式交换机" [19],eSwitch很可能就是由64–128个数据包处理核心组成的加速可编程管道(APP)。eSwitch由以太网控制器上每个端口的物理功能驱动程序(PF驱动)配置和控制 [19]。
此外,DOCA Flow API从未清楚说明图1中描述的eSwitch的能力。我们假设ASAP2 [20, 21] 的限制(例如15个组,每个组256K条目)(用于将Open vSwitch(OVS)规则硬件卸载到eSwitch)可能也适用于DOCA Flow API。规则和管道通过来自主机的GRPC卸载到eSwitch。
我们系统中ARM、DPA和主机核心的计算组件概述见表1。
表1:Bluefield-3 DPU的计算组件。
| CPU | 2 × Intel Xeon Silver 4514Y | ARMv8.2+ A78 Hercules | RISC-V RV64IMAC(B)-USM |
| 核心数 | 2 × 16 | 16 | 16 |
| 线程数 | 2 × 32 | 32 | 256 |
| 频率 | 3.4 GHz | 2.0 GHz1 | 1.8 GHz |
| RAM | 128 GB | 32 GB | |
| L1D 缓存 | 2 × 16 × 48 KB | 16 × 64 KB | 256 × 1 KB |
| L1I 缓存 | 2 × 16 × 32 KB | 16 × 64 KB | 8 KB |
| L2 缓存 | 2 × 16 × 2 MB | 16 × 512 KB | 1.5 MB |
| L3 缓存 | 2 × 30 MB | 16 MB | 3 MB |
3.2 APP的软件栈
DOCA是一组用于访问Bluefield生态系统硬件功能的库和API。在这个生态系统中,eSwitch可通过多个API进行编程:
DOCA Flow API:这是配置eSwitch并将规则卸载到其上的主要API。它用于创建管道、表和规则。
OVS:Open vSwitch(OVS)是一个软件交换机,可用于管理eSwitch。它使用DOCA Flow API将规则卸载到eSwitch。
对于这项工作,我们需要结合使用DOCA Flow API和OVS来控制eSwitch。
DOCA Flow API的核心构建块是管道。一个流管道是流表的软件模板。2 有一个根管道作为每个数据包的入口点。管道指定要匹配哪些数据包,可以对它们执行哪些操作,以及数据包可以转发到哪里。对于每个管道,如果数据包匹配,可以定义多个转发,如果数据包不匹配过滤器,则定义一个转发。转发可以包括将数据包转发到其他管道,允许人们构建管道树。此外,数据包可以使用接收端缩放(RSS)转发到ARM核心3,转发到不同的端口,或者可以被丢弃。然而,管道只是指定其条目能力的模板。条目是实际卸载到eSwitch的规则。有两种方法可以定义管道及其条目的匹配和操作:
常量:匹配条件和操作由管道本身定义,并且对于管道的所有条目都是常量。
变量:匹配条件和操作由管道的每个条目定义,并且可以在条目之间不同。这要求管道匹配值设置为全1。
此外,两者都可以被定义
显式:匹配条件和操作定义一个掩码,将应该比较或更改的位设置为1。然后匹配值定义这些位的值。
隐式:掩码设置为NULL,字段的所有位都与该值比较或设置为该值。
例如,如果希望基于源IP地址的最后一位将数据包分发到两个后端,则需要将匹配定义为显式变量匹配。源IP地址的管道匹配值需要设置为0xFFFFFFFF,匹配掩码需要设置为0x00000001。而第一个条目的值设置为0x00000000,第二个条目的值设置为0x00000001。这样,第一个条目匹配所有具有偶数源IP地址的数据包,第二个条目匹配所有具有奇数源IP地址的数据包。相同的概念适用于操作。
在DOCA Flow API初始化期间,可以选择以下管道模式 [22] 之一:vnf、switch 或 remote-vnf 模式。这些模式设置数据包可以转发到的能力,并预定义未命中转发。在虚拟网络功能(vnf)模式中,到达一个端口的数据包被处理,并且可以发送到另一个端口。此外,未匹配过滤器的数据包被发送到ARM3。switch 模式用于内部交换,仅允许转发到上行链路代表端口。在 remote-vnf 模式中,DOCA Flow应用程序在主机上执行。未命中过滤器的数据包被转发到主机,主机随后可以通过GRPC在Bluefield上设置新规则。
对于我们的用例,我们使用 vnf 模式,因为我们想要修改数据包,根据后端改变其目的地,并将其发送到另一个端口。
不支持超出L4头部的数据包修改,以及对这些头部的任意写入。所有修改必须在一个操作内静态定义。然而,由于管道可以链接,可以通过在数据包元数据中存储中间结果来实现更复杂的修改。此外,DOCA Flow通过专门的管道提供额外功能,例如校验和计算。如果需要进一步处理,必须将数据包转发到ARM或DPA核心以继续处理。
4 XenoFlow的设计与实现
在我们使用eSwitch实现L3负载均衡器的方法中,我们首先专注于一个名为XenoFlow的基本原型。该原型通过使用DOCA Flow重写目标MAC地址来转发数据包。由于DOCA Flow文档有限,我们首先探索了Nvidia提供的示例应用程序 [23]。所有其他未记录的功能都是通过试错来探索的。
4.1 XenoFlow 0.1
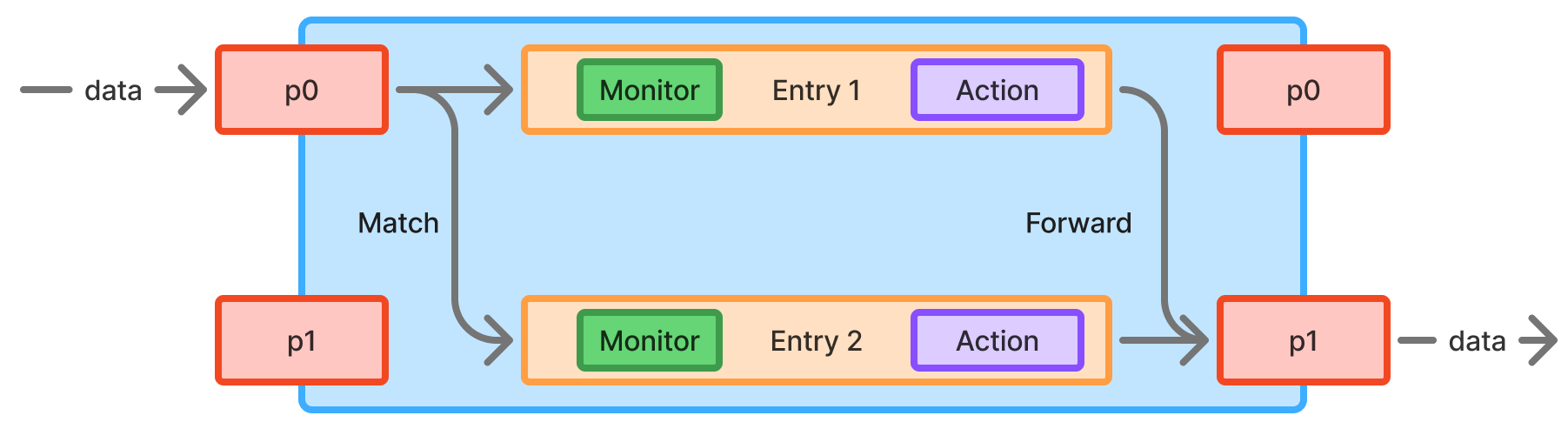
图2:XenoFlow根管道
XenoFlow的主要分类标准是来自传入IP数据包头部的IPv4源地址。该源地址,如果未被修改,则是实际发送方的相应地址。在我们的原型中,我们假设IP地址空间表现出足够的随机性,使得源IP地址可以作为将流划分为大小相等的类的分类标准,随后这些类被分布在预定义数量的后端上。此分类标准也与eSwitch的能力相对应,eSwitch只允许对数据包的固定长度部分进行匹配和修改。这归结为大多数硬件加速器大量使用ASIC的事实。
对于我们在第5节中的评估,我们使用了两个后端。因此,负载均衡算法简化为决定IPv4地址是偶数还是奇数。
4.2 使用DOCA Flow实现
DOCA Flow库由头文件和一个闭源的共享库对象组成。头文件声明了用于定义规则的数据结构,实际的硬件可以将这些规则应用于传入的数据。这些数据结构然后通过C函数应用,这些函数映射到ASIC的相应硬件函数。
XenoFlow使用一个根管道,根据定义,它始终是应用程序的第一个管道,其中包含一组条目,这些条目直接对应于配置为处理传入流量的后端数量。条目根据其匹配规则从管道中获取数据包,如图2所示。这些匹配规则使用隐式匹配范式(见第3.2节)评估每个数据包IP源地址字段的最后几位。这些条目中的每一个都将数据包的目标MAC地址更改为特定后端的MAC地址。此外,该条目将硬件输出端口更改为第二个BlueField连接器。为了接收关于XenoFlow当前处理速度和已处理数据量的信息,我们对每个条目应用了一个监控数据结构。这些允许收集关于硬件当前处理指标的信息。可以获得两个数据点:
已处理的数据包数量
已处理的数据量(以字节为单位)
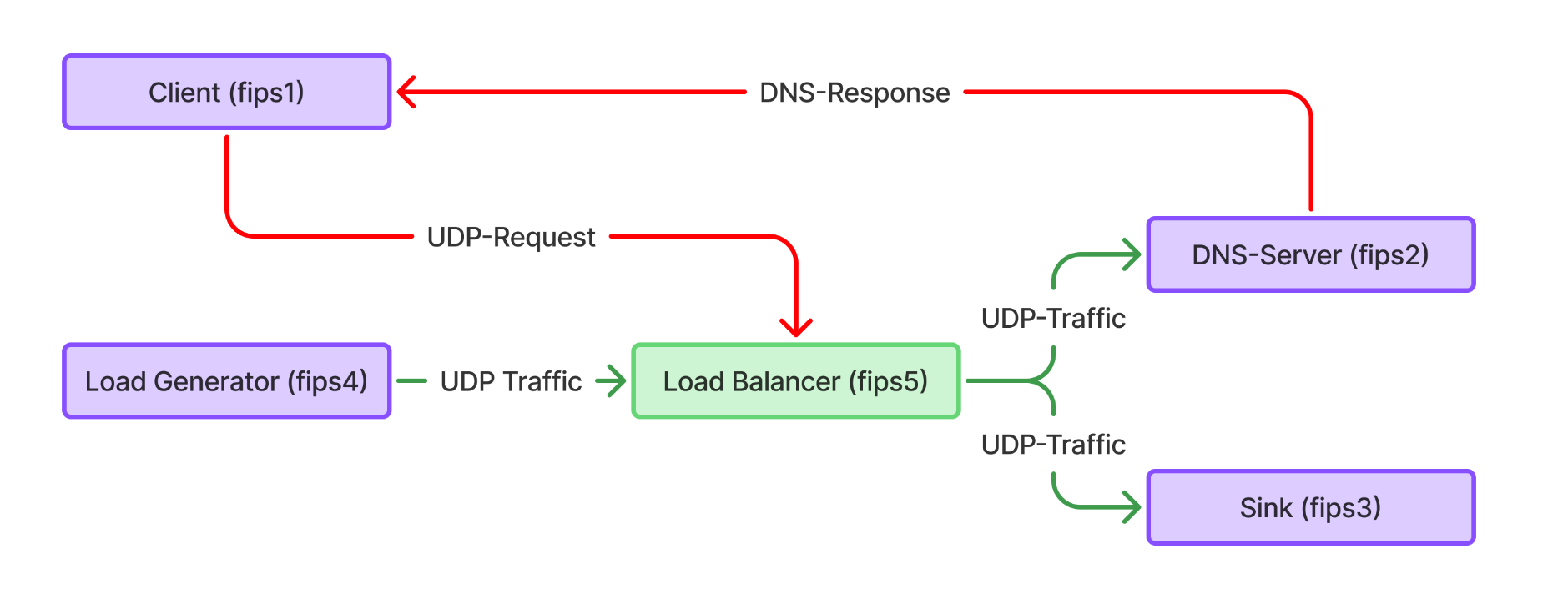
图3:负载均衡器设置
从这些指标中,我们通过以下公式计算实际处理带宽:
带宽(以比特/秒为单位)= pps ∗ 数据量(字节)∗ 8
在我们的实验中,我们观察到,即使我们对Bluefield应用了简单的输入-输出转发规则,流量也极其有限,大约为每秒100,000个数据包,带宽约为1 Gbit/s。此外,我们注意到数据包被路由到Bluefield CPU的一个ARM核心。这是出乎意料的,因为它从未声明在CPU上处理数据包。经过深入调查,发现需要配置Open vSwitch,以便物理功能(pf1hpf)上的流量需要手动路由到端口-1。这是使用 ovs-ctl 命令行工具完成的,参数如下:
ovs-ofctl -O OpenFlow12 add-flow ovsbr2 \\ ip,in_port=pf1hpf,actions=output:p1
5 评估
我们进行了三个不同的实验来评估具有简单DNS负载均衡服务的Bluefield架构的性能。核心思想是建立一个高流量DNS服务,其中入口需要均匀分布在定义的一组运行DNS服务器的后端上。
5.1 测试平台描述
为了确保测试不受实际DNS服务器实现的性能限制,我们决定创建自己的具有简化功能集的DNS服务器。我们测试平台的详细概述见图3。节点fips2和fips3被用作后端。Fips5是配备Bluefield-3的负载均衡器。请求在fips4上生成,它作为运行T-Rex [24] 的负载生成器。对于延迟实验,使用另一个客户端(fips1)来发送和接收DNS请求,以便可以在没有CPU上其他负载干扰的情况下测量实际延迟。Fips1–4的硬件规格见表2,fips5和Bluefield-3的规格先前在表1中描述。
主机通过一个100 Gbit/s的Nvidia MSN2100-CB2F交换机连接。
所有测量至少重复三次,下图显示了中位数值。除图7外,所有测量的观测变异系数低于0.08%。对于所有测量,我们还使用接口的硬件计数器4验证了流量生成器请求的负载确实达到了。
表2:服务器fips1–4的计算组件。
| CPU | Intel Xeon Silver 4314 |
| 核心数 | 16 |
| 线程数 | 32 |
| 频率 | 2.4 GHz |
| RAM | 128 GB |
| L1D 缓存 | 16 × 48 KB |
| L1I 缓存 | 16 × 32 KB |
| L2 缓存 | 16 × 1.25 MB |
| L3 缓存 | 24 MB |
5.2 RQ2:DOCA Flow应用程序是否以零开销处理,即在最大吞吐量以下是否没有数据包被丢弃?
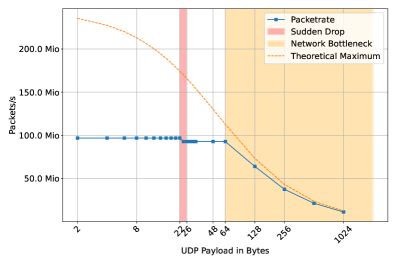
图4:XenoFlow的吞吐量(pps)测量
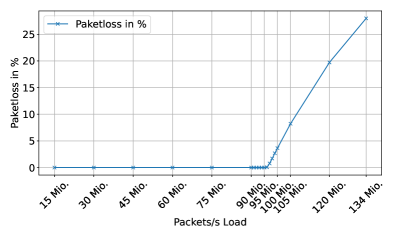
图5:UDP有效载荷大小为22字节时XenoFlow的数据包丢失测量。
如图4所示,对于小数据包大小,Bluefield-3的最大每秒数据包数约为9670万。应当注意,在UDP有效载荷大小恰好为及超过23字节时,最大吞吐量突然下降到9280万数据包/秒。23字节UDP有效载荷相当于65字节以太网数据包大小(不含帧校验和)。这可能暗示Bluefield-3 eSwitch在64字节处有内部限制。所有超过较小数据包(小于23字节)可能达到的9670万数据包/秒的流量都会被丢弃,如图5所示。因此,对RQ2的回答是:不,Bluefield-3在达到最大吞吐量之前会丢弃小数据包。
5.3 RQ3:使用DOCA Flow API实现的负载均衡器,BlueField-3能否达到线速?
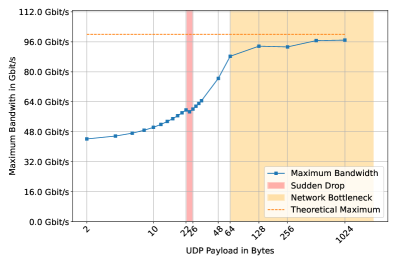
图6:XenoFlow的带宽测量
正如Nvidia所述,Bluefield-3能够以线速(400 Gbit/s)处理数据包 [14]。尽管用于此评估的Bluefield-3有两个100 Gbit/s端口,但据我们所知,加速可编程管道的数据包处理核心与400 Gbit/s版本中的相同。因此,我们期望达到100 Gbit/s。图6说明,对于超过1024字节的UDP有效载荷,XenoFlow几乎达不到线速。鉴于当前版本的XenoFlow仅在根管道中插入两个条目,该图实际上也量化了Bluefield-3与宣传的线速(由虚线红线表示)相差的程度。也就是说,无论数据包的实际大小如何,Bluefield 3都无法达到线速。
5.4 RQ4:我们的负载均衡器如何影响端到端延迟?
为了测量负载均衡器XenoFlow在服务前面引入的延迟,我们测量了DNS请求的往返时间。由于我们在没有负载均衡器且使用bind9作为DNS服务器的基础测量显示出35微秒的标准偏差,因此需要一个具有更低方差和延迟的更稳定的后端。一个重写客户端请求目标MAC地址的DOCA Flow程序被用作后端。结果见图7。我们展示了总共2700次测量的中位数和标准偏差。我们将XenoFlow增加的延迟与同等简单的eBPF变体进行了比较,显示了硬件卸载和更靠近网络的优势。虽然XenoFlow仅增加了约5.2微秒的延迟,但eBPF变体增加了约9.3微秒的延迟。这相当于延迟减少了44%。与在Ubuntu 24.04上查询本地区域文件、往返时间约为102微秒的默认bind9安装相比,XenoFlow负载均衡器的额外开销可以忽略不计。
5.5 RQ5:负载如何影响负载均衡器的性能?
为了研究负载对延迟的影响,我们进行了四个具有不同流量分布的实验。在这些实验中,使用T-Rex在fips4上生成高达90 Mpps的背景负载。Fips1被用作测量节点,记录RTT。由fips1发送的数据包由负载均衡器分发到fips2,然后由第5.4节介绍的eBPF服务转发回fips1(见图3)。结果如图8所示。在单端点实验中,我们只使用一个后端(fips2)。在其他实验中,使用了两个后端(fips2和fips3)。标记x/y表示x%的流量发送到fips2,y%发送到fips3。对于所有低于90 Mpps的测量,延迟保持恒定。仅在90 Mpps时,观察到所有流量都发送到fips3的实验延迟增加。然而,对于其他分布,可以观察到轻微的延迟增加,这表明DOCA Flow API并非完全如Nvidia所声称的那样零开销 [14]。总体而言,XenoFlow即使在高负载下也保持了近乎恒定且低延迟的性能。
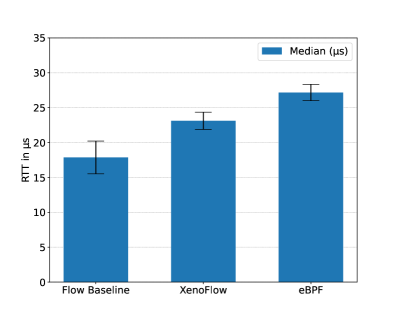
图7:延迟比较
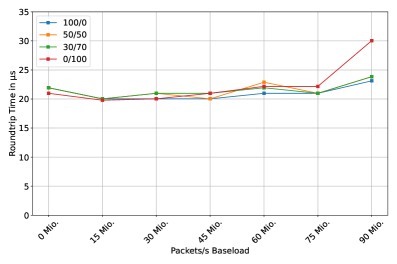
图8:负载下的延迟
6 讨论
接下来,我们讨论研究问题RQ1:我们能否使用Bluefield DOCA Flow API实现一个简单的负载均衡器?
我们的原型XenoFlow清楚地展示了Bluefield-3的潜力。尽管Bluefield-3对于小数据包无法达到线速,但它仍然优于主机上可比的eBPF实现。XenoFlow预期的简单性使其目前无法与例如Katran等其他负载均衡器相媲美。在未来的工作中,我们计划将XenoFlow扩展为一个功能更完整的负载均衡器。
我们成功实现了一个基本的L3负载均衡器,能够将UDP流量分发给预定义的一组后端。通过添加更多具有指定过滤器掩码和MAC地址重写操作的条目,XenoFlow原型可以轻松扩展到更多后端。为了解决IPv4源地址流量分布不均的问题,可以通过使用DOCA Flow API的预定义哈希函数,实现基于哈希的分布。然而,更复杂的转发策略需要更复杂的哈希函数,如Maglev哈希 [6] 或存储客户端到后端当前映射的表 [1]。尽管管道中的条目可以用来存储这样的映射,但有限的条目数(可能为256K)和缓慢的更新延迟(305微秒)[12] 可能使这种方法不切实际。然而,需要更多的研究来验证这一假设。
Bluefield-3还包括DPA。可以在DPA核心上实现更复杂的负载均衡策略,以克服eSwitch的限制。
作为DOCA Flow API的替代方案,可以使用DOCA Pipeline Language(DPL)[25] 来实现负载均衡器。DPL是一种基于P4-16语言的领域特定编程语言,同时引入了Nvidia特定的语义和架构,专为BlueField平台量身定制。有一个DPL示例,它对数据包的五元组进行哈希处理,并将结果哈希用作源端口 [26]。然而,DPL实现受到与DOCA Flow API相同的eSwitch能力的限制。此外,DPL编译器仅支持P4-16语言的一个子集 [25]。
7 结论
在本文中,我们介绍了XenoFlow,一个使用Bluefield-3 DPU上的DOCA Flow API实现的简单L3负载均衡器。我们展示了Bluefield-3和DOCA Flow API当前的性能能力和局限性。我们的评估表明,Bluefield-3无法实现小数据包的线速。然而,凭借低44%的延迟,XenoFlow仍然优于主机上可比的eBPF实现。此外,XenoFlow即使在高负载下也能实现这种低延迟。Bluefield-3的混合架构使其成为一个有前景的平台,可以将更多功能集成到DPU中,例如入侵检测系统或防火墙。然而,需要更多的研究来确定Bluefield-3在真实场景中的能力。
Nvidia DOCA文档稀少,很少提供实质性帮助。此外,公开可用的文档反复引用内部API规范5,外部开发人员无法访问。代码级文档(仅限于头文件,因为实现是闭源的)也缺乏实质性内容,并且似乎是自动生成的。因此,依赖示例应用程序未涵盖的功能的开发是缓慢且容易出错的。




评论前必须登录!
注册