 网硕互联帮助中心
网硕互联帮助中心博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈: python语言、Flask框架、Echarts可视化、MySQL数据库、HTML、豆瓣音乐数据、数据分析
(2)系统功能:
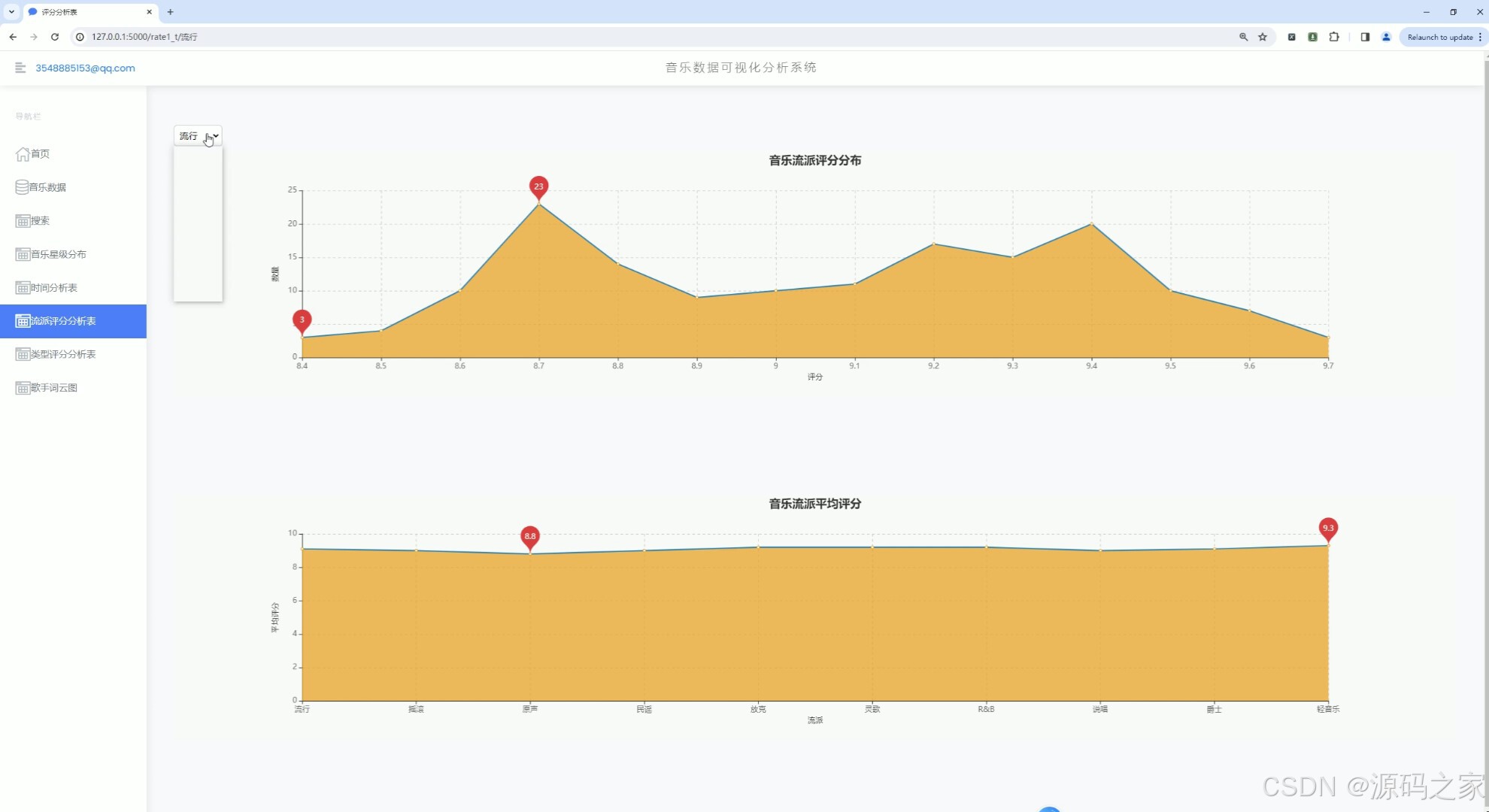
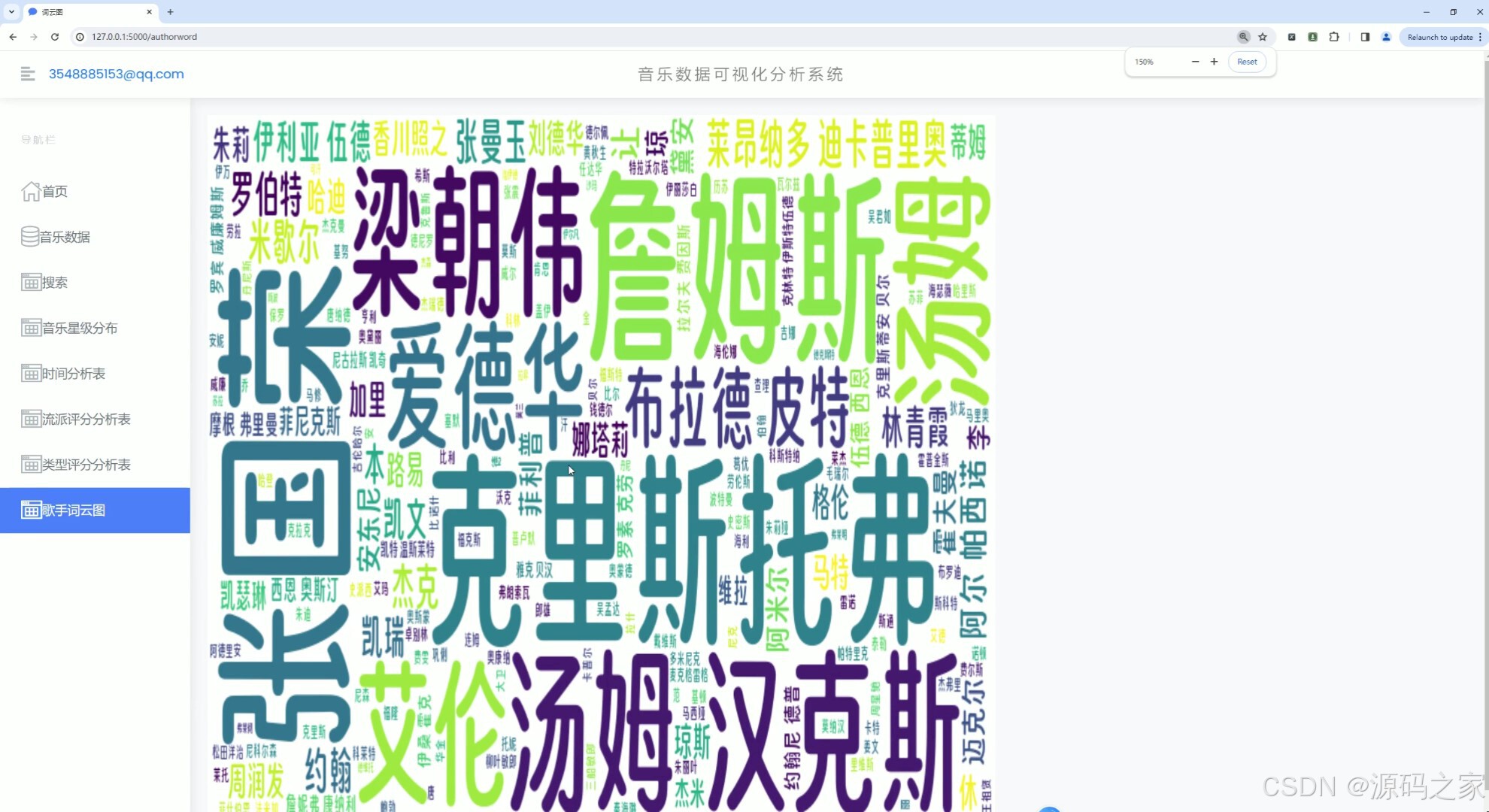
1、首页 – 数据概况: 展示豆瓣音乐数据的整体概况,如热门音乐、高评分音乐、最新发布音乐等。 使用Echarts绘制动态图表,展示音乐评分趋势、热门流派分布等。 2、音乐数据中心: 提供详细的音乐数据列表,包括音乐名称、艺术家、流派、类型、评分、发行年份等。 支持按不同条件进行筛选和排序,如按评分高低、发行年份等。 3、音乐数据搜索: 实现音乐数据的快速搜索功能,用户可输入关键词搜索音乐名称、艺术家等。 搜索结果以列表形式展示,支持点击查看详情。 4、音乐数据星级分布分析: 展示豆瓣音乐数据的星级分布情况,使用柱状图或饼图表示不同星级音乐的比例。 分析用户对音乐的评分偏好,为音乐推荐提供参考。 5、音乐发行年份统计分析: 统计不同年份发布的音乐数量,展示音乐市场的历史发展趋势。 使用折线图或柱状图表示各年份音乐数量的变化情况。 6、音乐流派评分数据分析: 分析不同流派音乐的评分情况,展示流派间的评分差异。 使用散点图或箱线图表示各流派音乐的评分分布。 7、音乐类型评分分析: 类似音乐流派评分分析,但针对音乐类型进行评分分析。 展示不同类型音乐的评分趋势和分布情况。 8、歌手词云图分析: 使用词云图展示热门歌手的姓名和出现频率,反映歌手的受欢迎程度。 分析歌手的流行度和影响力,为音乐推广提供策略支持。 9、音乐数据采集: 提供音乐数据的采集功能,通过爬虫技术从豆瓣音乐页面抓取数据。 支持定期自动采集和手动触发采集,确保数据的实时性和准确性。 10、注册登录: 实现用户注册和登录功能,保护用户数据和系统安全。 注册时要求用户填写基本信息,如用户名、密码、邮箱等。 登录后用户可访问个人数据、修改密码、查看历史分析等。
2、项目界面
(1)首页—数据概况 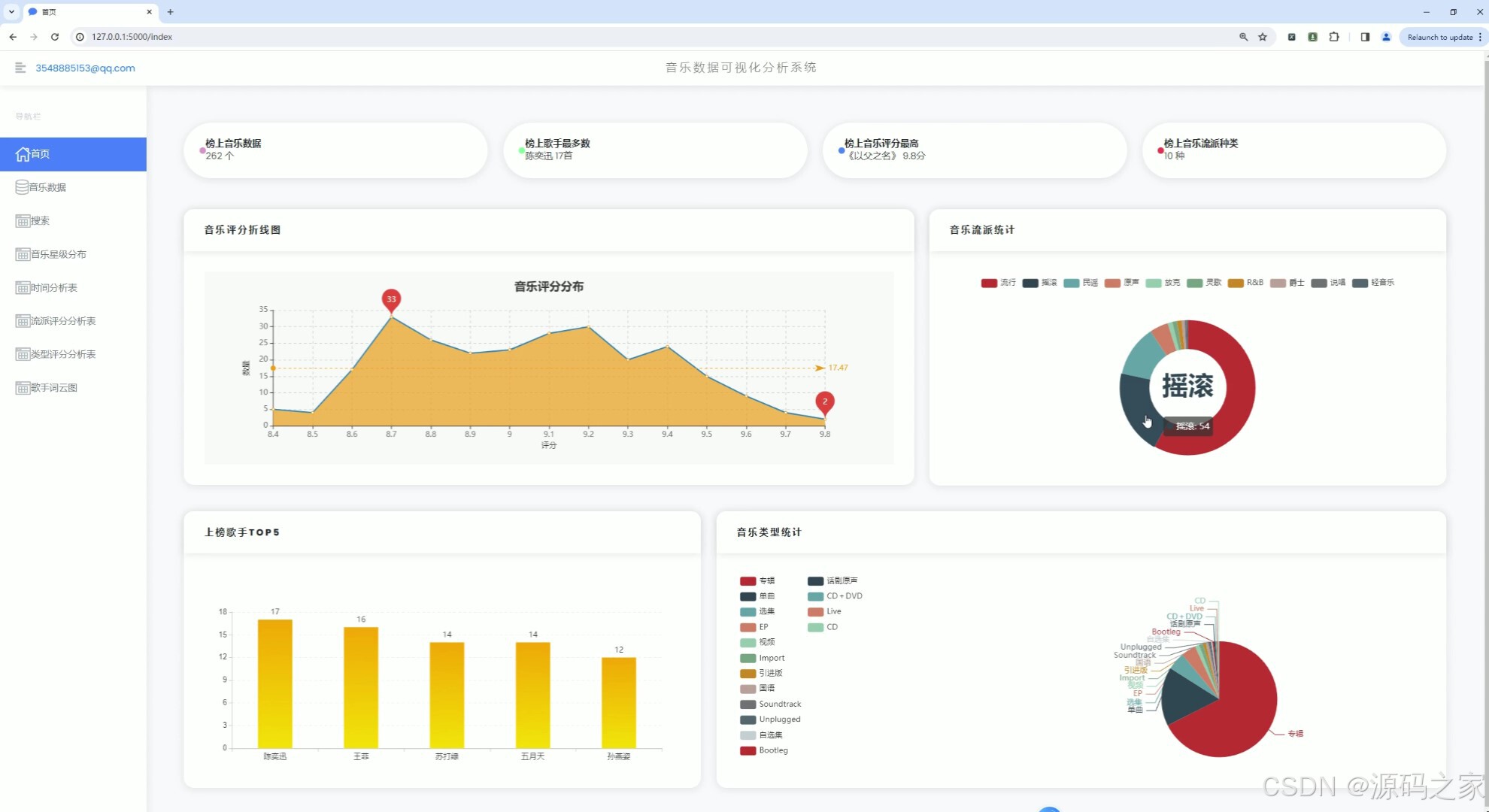
(2)音乐数据中心
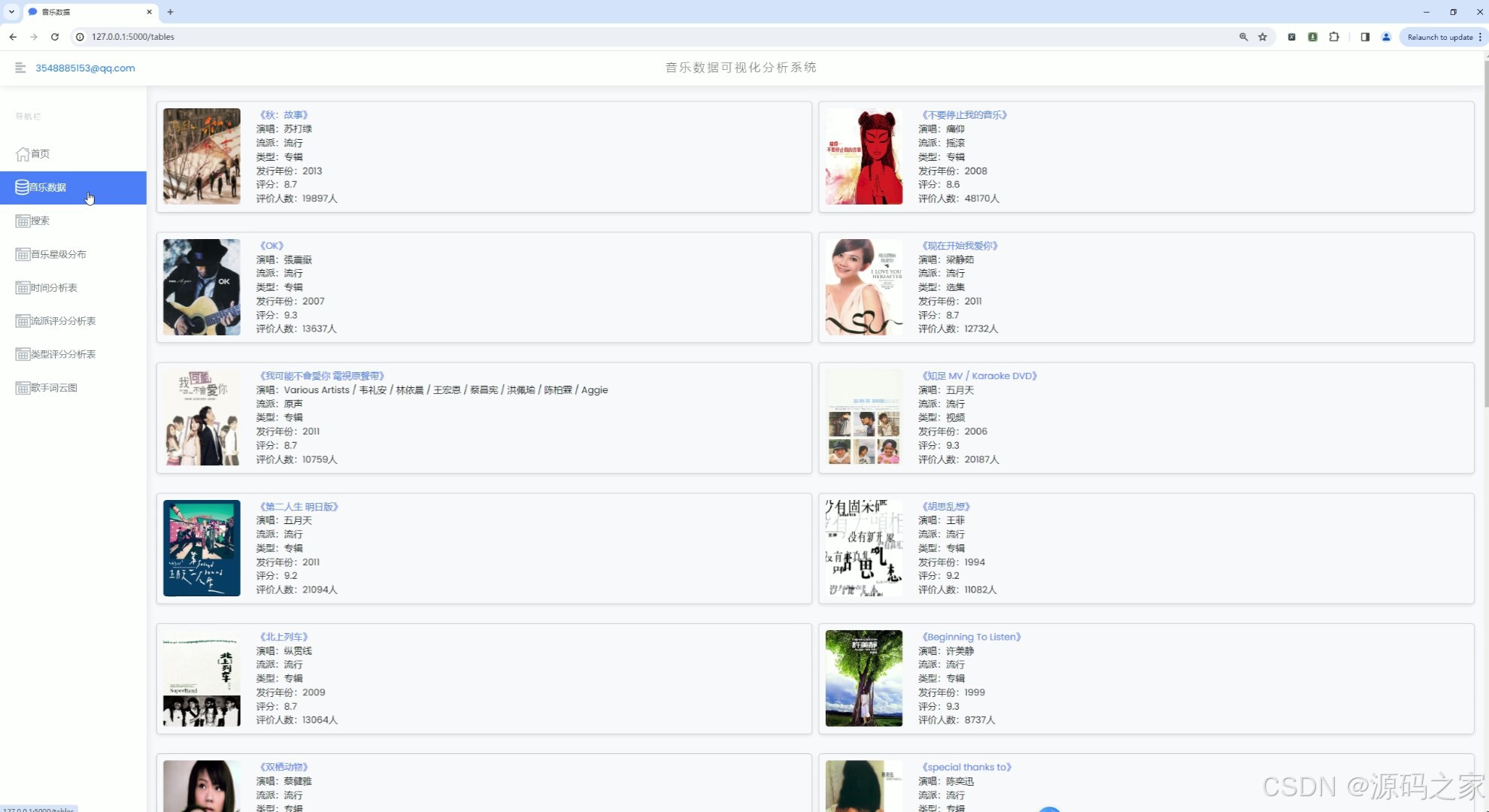
(3)音乐数据搜索 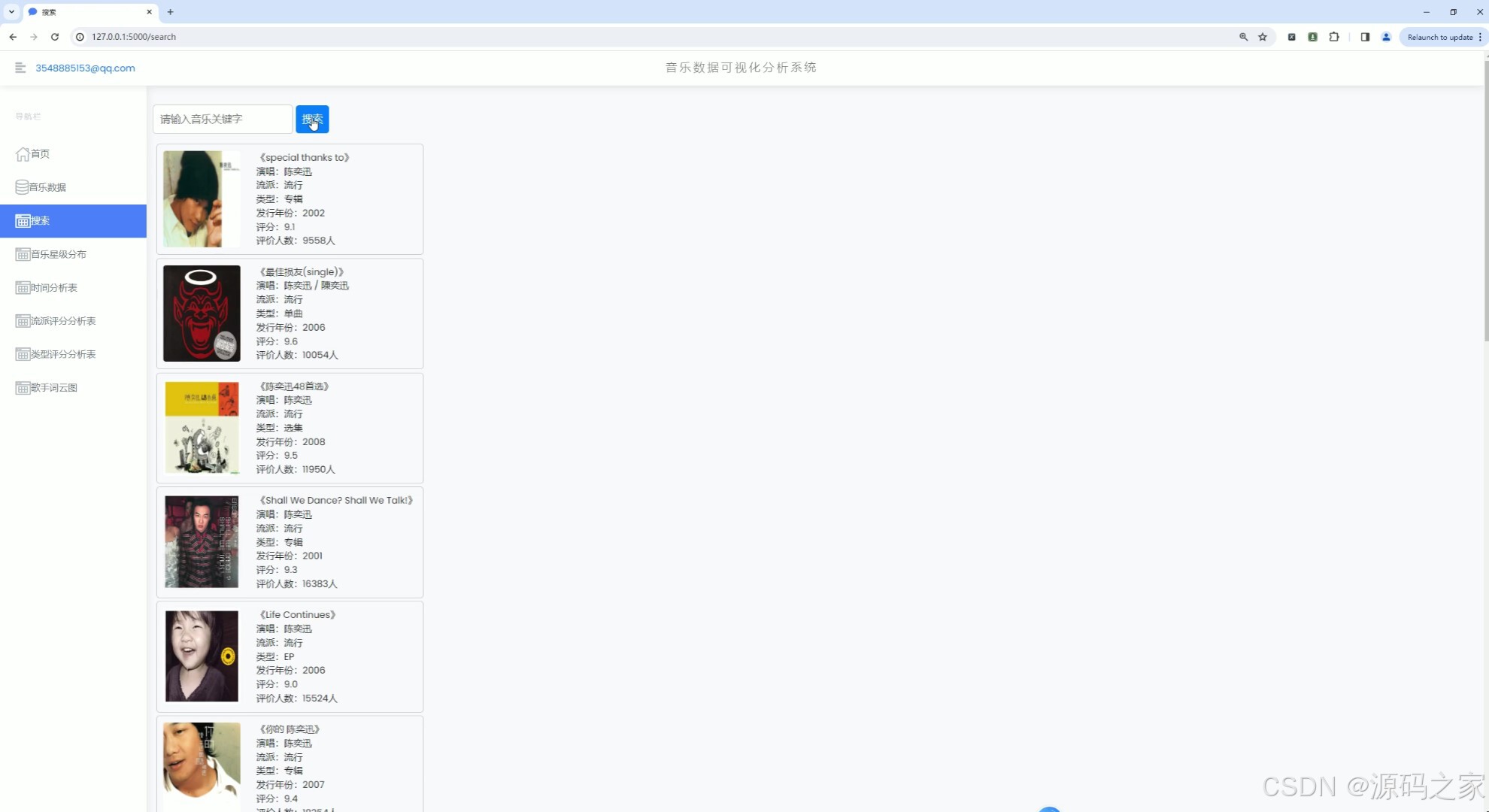
(4)音乐数据星级分布分析
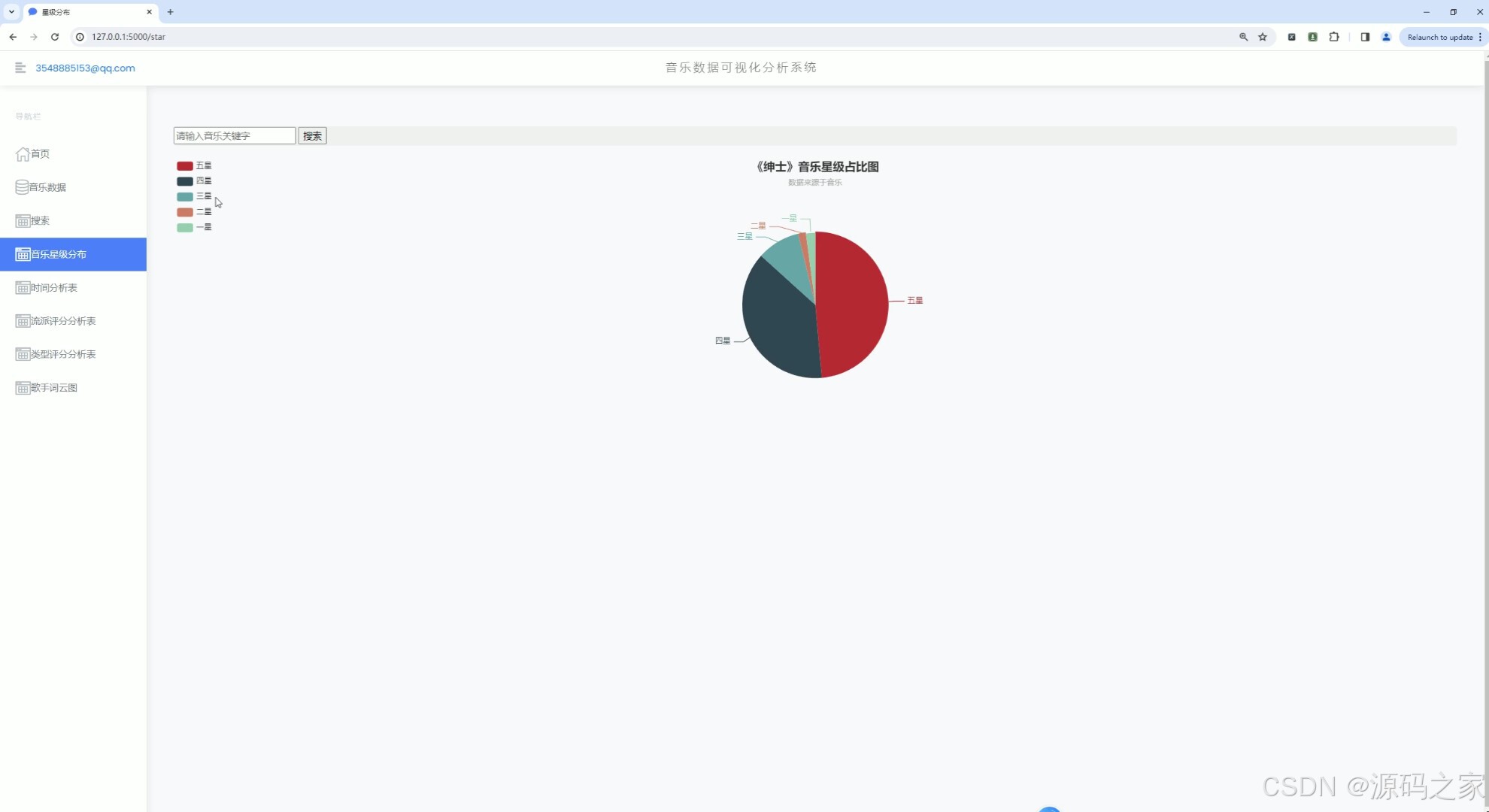
(5)音乐发行年份统计分析 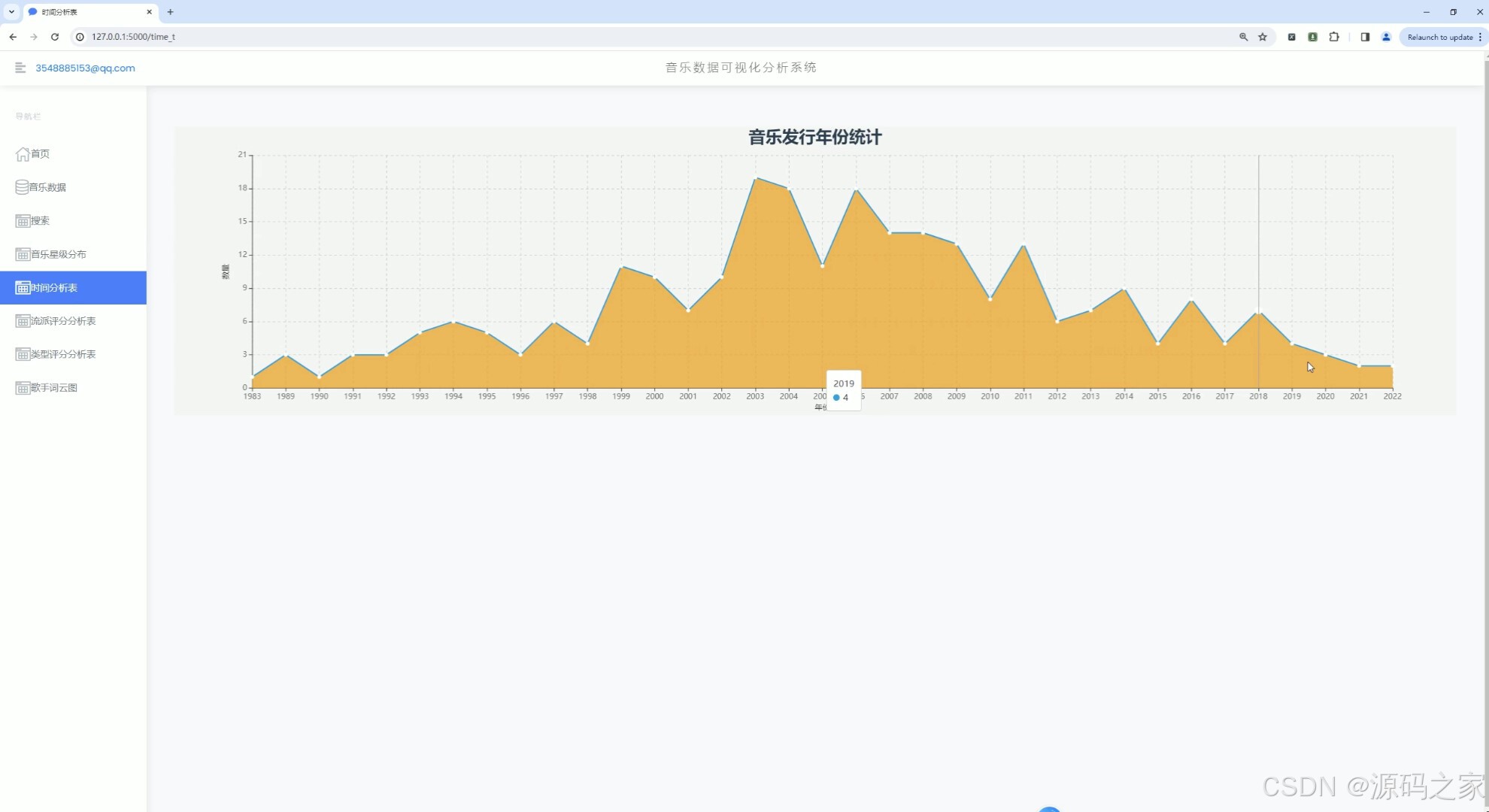
(6)音乐流派评分数据分析
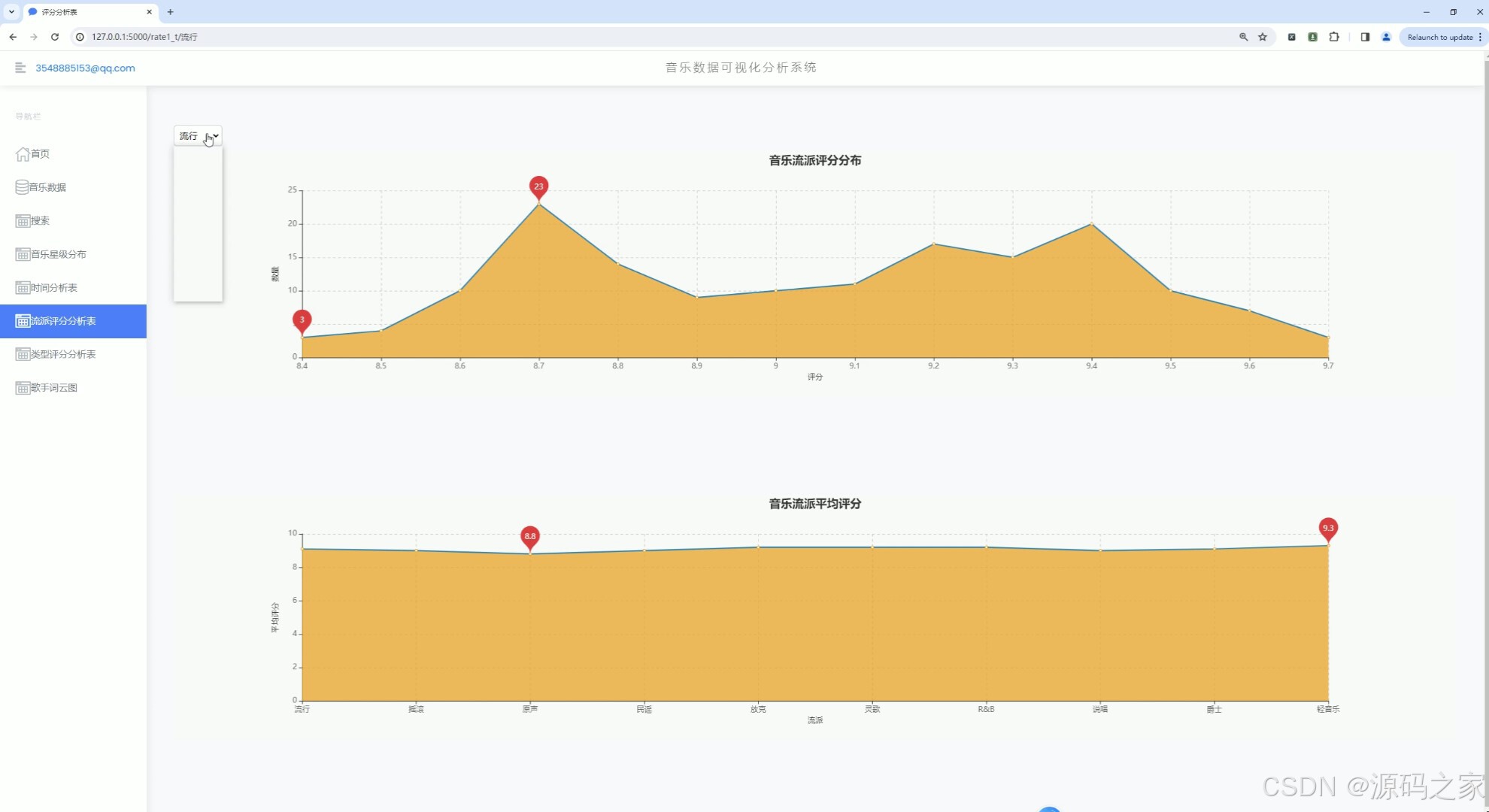 (7)音乐类型评分分析
(7)音乐类型评分分析
(8)歌手词云图分析
(9)音乐数据采集
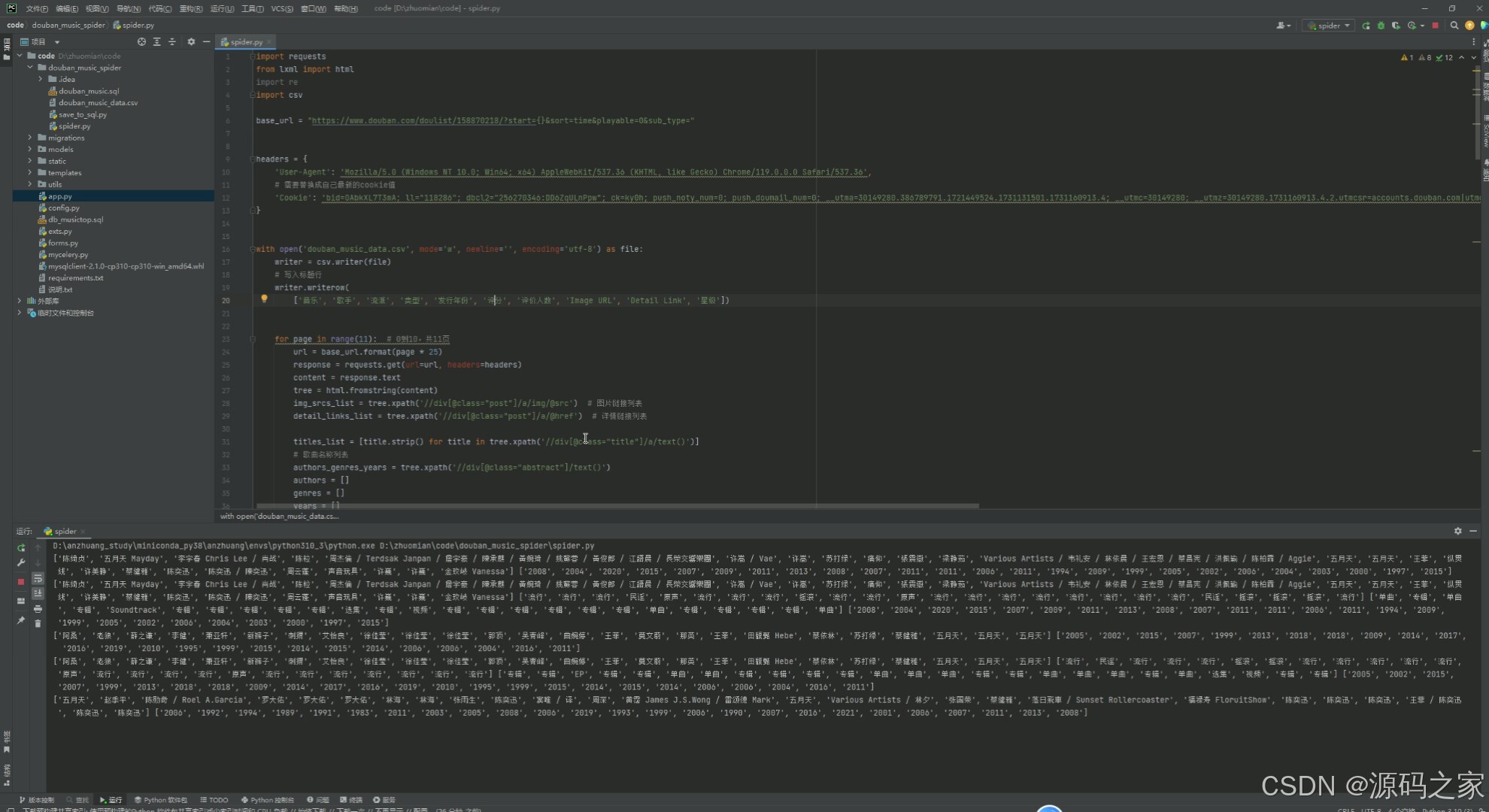
(10)注册登录
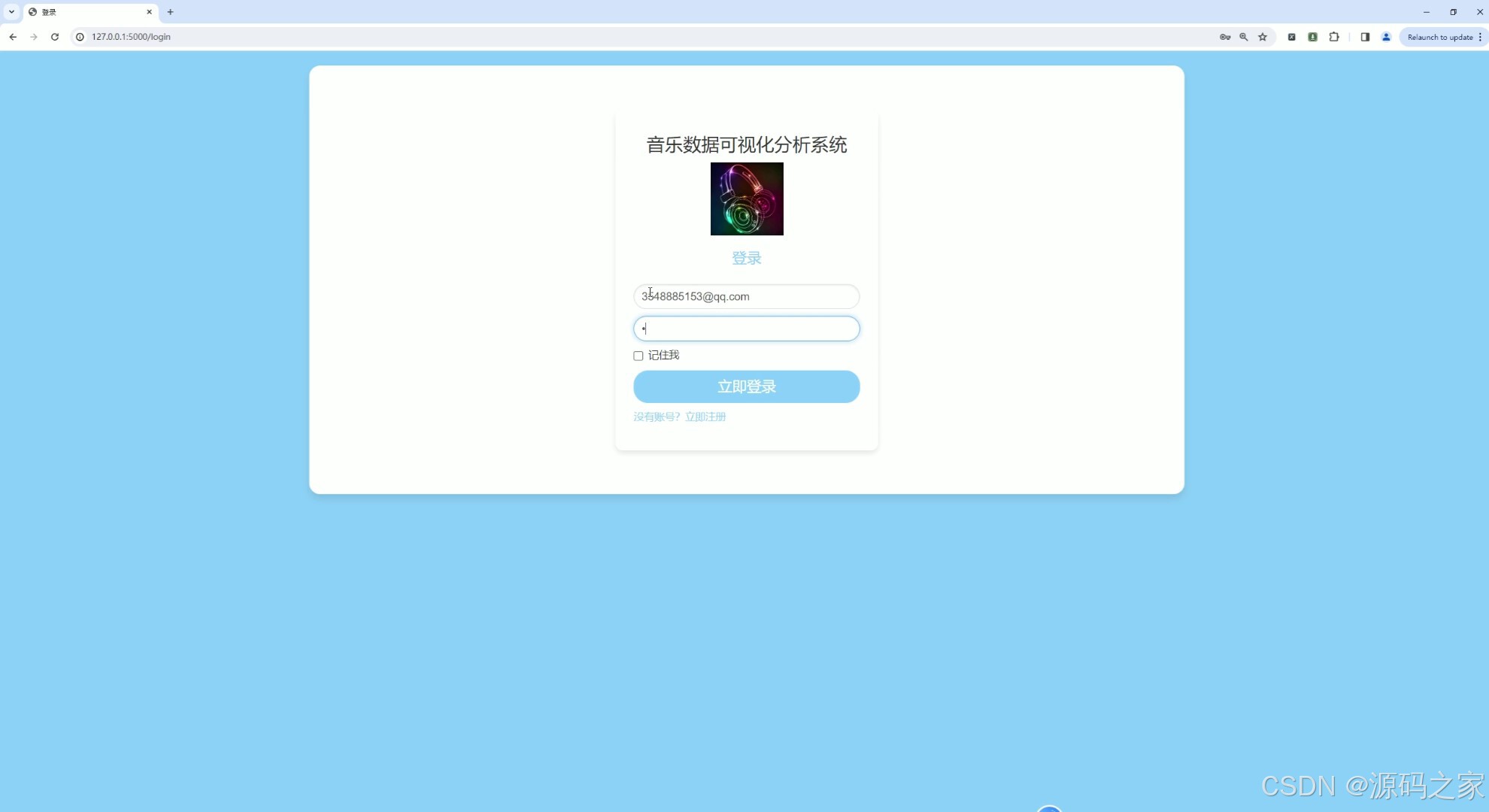
3、项目说明
(1)技术栈:
后端:Python语言,使用Flask框架构建RESTful API,处理数据请求、用户认证与授权。 前端:HTML/CSS/JavaScript,结合Echarts实现数据可视化,提供用户友好的界面交互。 数据库:MySQL,存储豆瓣音乐数据、用户信息、分析结果等。 数据源:通过爬虫技术从豆瓣音乐页面获取数据,或利用豆瓣API(如果可用)进行数据抓取。 数据分析:Python进行数据处理与分析,包括统计、分类、聚类等算法应用。
(2)系统功能:
1、首页 – 数据概况: 展示豆瓣音乐数据的整体概况,如热门音乐、高评分音乐、最新发布音乐等。 使用Echarts绘制动态图表,展示音乐评分趋势、热门流派分布等。 2、音乐数据中心: 提供详细的音乐数据列表,包括音乐名称、艺术家、流派、类型、评分、发行年份等。 支持按不同条件进行筛选和排序,如按评分高低、发行年份等。 3、音乐数据搜索: 实现音乐数据的快速搜索功能,用户可输入关键词搜索音乐名称、艺术家等。 搜索结果以列表形式展示,支持点击查看详情。 4、音乐数据星级分布分析: 展示豆瓣音乐数据的星级分布情况,使用柱状图或饼图表示不同星级音乐的比例。 分析用户对音乐的评分偏好,为音乐推荐提供参考。 5、音乐发行年份统计分析: 统计不同年份发布的音乐数量,展示音乐市场的历史发展趋势。 使用折线图或柱状图表示各年份音乐数量的变化情况。 6、音乐流派评分数据分析: 分析不同流派音乐的评分情况,展示流派间的评分差异。 使用散点图或箱线图表示各流派音乐的评分分布。 7、音乐类型评分分析: 类似音乐流派评分分析,但针对音乐类型进行评分分析。 展示不同类型音乐的评分趋势和分布情况。 8、歌手词云图分析: 使用词云图展示热门歌手的姓名和出现频率,反映歌手的受欢迎程度。 分析歌手的流行度和影响力,为音乐推广提供策略支持。 9、音乐数据采集: 提供音乐数据的采集功能,通过爬虫技术从豆瓣音乐页面抓取数据。 支持定期自动采集和手动触发采集,确保数据的实时性和准确性。 10、注册登录: 实现用户注册和登录功能,保护用户数据和系统安全。 注册时要求用户填写基本信息,如用户名、密码、邮箱等。 登录后用户可访问个人数据、修改密码、查看历史分析等。
11、系统优势: 提供全面的豆瓣音乐数据分析功能,帮助用户深入了解音乐市场和用户偏好。 结合Echarts实现数据可视化,提高数据可读性和用户体验。 支持用户注册和登录,保护用户隐私和数据安全。 采用Flask框架和MySQL数据库,构建高效、稳定、可扩展的系统架构。
4、核心代码
@app.route('/')
def all():
return render_template('login.html')
@app.get("/email/captcha")
def email_captcha():
email = request.args.get("email")
if not email:
return restful.params_error(message="请先传入邮箱!")
source = list(string.digits)
captcha = "".join(random.sample(source, 6))
message = Message(subject="【音乐Top数据可视化系统】", recipients=[email],
body="验证码为:%s,您正在注册,若非本人操作,请勿泄漏" % captcha)
try:
mail.send(message)
except Exception as e:
print("邮件发送失败!")
print(e)
return restful.params_error(message="邮件发送失败!")
cache.set(email, captcha)
print(cache.get(email))
return restful.ok(message="邮件发送成功!")
# @app.get("/email/captcha")
# def email_captcha():
# email = request.args.get('email')
# if not email:
# return restful.params_error(message="请输入邮箱!")
# source = list(string.digits)
# captcha = "".join(random.sample(source, 6))
# subject = "【音乐Top数据可视化系统】"
# body = "验证码为:%s,您正在注册,若非本人操作,请勿泄漏" % captcha
# current_app.celery.send_task("send_mail",
# (email, subject, body)) # 启动celery -A app.mycelery worker –loglevel=info -P gevent
# cache.set(email, captcha)
# print(cache.get(email))
# return restful.ok(message="邮件发送成功!")
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
form = LoginForm(request.form)
if form.validate():
email = form.email.data
password = form.password.data
remember = form.remember.data
user = UserModel.query.filter_by(email=email).first()
if not user:
return restful.params_error("邮箱或密码错误!")
if not user.check_password(password):
return restful.params_error("邮箱或密码错误!")
session['user_id'] = user.id
if remember == 1:
session.permanent = True
session['email'] = request.form['email']
return restful.ok()
else:
return restful.params_error(message=form.message[0])
@app.route('/loginOut')
def loginOut():
session.clear()
return redirect('/login')
@app.before_request
def before_request():
pat = re.compile(r'static')
if re.search(pat, request.path):
return
if request.path in ["/login", "/register", "/email/captcha"]:
return
email = session.get('email')
if email:
return None
return redirect('/login')
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'GET':
return render_template('register.html')
else:
form = RegisterForm(request.form)
if form.validate():
email = form.email.data
password = form.password.data
user = UserModel(email=email, password=password)
db.session.add(user)
db.session.commit()
return restful.ok()
else:
message = form.message[0]
return restful.params_error(message=message)
@app.route('/index')
def index():
email = session.get('email')
music, maxRate, highest_rated_music_title, max_author, max_author_count, types_count = getIndexData()
row, columns = getRateEchartData()
genreEchartData = getGenreData()
authors, author_counts = getAuthorEchartData()
typeEchartData = getTypeData()
return render_template('index.html', email=email, music=music,
maxRate=maxRate, highest_rated_music_title=highest_rated_music_title,
max_author=max_author, max_author_count=max_author_count, types_count=types_count, row=row,
columns=columns, genreEchartData=genreEchartData, authors=authors,
author_counts=author_counts, typeEchartData=typeEchartData)
@app.route('/tables')
def tables():
email = session.get('email')
# 获取所有数据
all_data = getTableData()
# 分页设置
page = request.args.get('page', 1, type=int) # 获取当前页码,默认为1
per_page = 24 # 每页显示条数
total = len(all_data) # 数据总数
start = (page – 1) * per_page
end = start + per_page
# 获取当前页的数据
tableData = all_data[start:end]
# 计算总页数
total_pages = (total + per_page – 1) // per_page
return render_template('tables.html', tableData=tableData, page=page, total_pages=total_pages, email=email)
@app.route('/search', methods=['GET', 'POST'])
def search():
email = session.get('email')
resultData = None
if request.method == 'POST':
searchWord = request.form.get('searchWord', '')
resultData = getMusicDetailBySearchWord(searchWord)
return render_template('search.html', resultData=resultData, email=email)
@app.route('/time_t')
def time_t():
email = session.get('email')
row, cloumns = getYearEchartData()
return render_template('time_t.html', email=email, row=row, cloumns=cloumns)
@app.route('/rate1_t/<type>', methods=['GET', 'POST'])
def rate1_t(type):
email = session.get('email')
typeList_1 = getAllTypes()
row, columns = getAllRateDataByType(type)
row2, columns2 = getavgData()
return render_template('rate1_t.html', type=type, email=email, typeList_1=typeList_1,
row=row, columns=columns, row2=row2, columns2=columns2)
@app.route('/rate2_t/<type>', methods=['GET', 'POST'])
def rate2_t(type):
email = session.get('email')
typeList_2 = getAll1Types()
row3, columns3 = getavgData2()
row, columns = getAllRate1DataByType(type)
return render_template('rate2_t.html', type=type, email=email, typeList_2=typeList_2,
row=row, columns=columns, row3=row3, columns3=columns3)
class SearchForm1(FlaskForm):
searchIpt = StringField('Search', render_kw={'placeholder': '请输入音乐关键字'})
submit = SubmitField('搜索')
@app.route('/star', methods=['GET', 'POST'])
def star():
email = session.get('email')
form = SearchForm1()
if form.validate_on_submit():
starData, searchName = getStar(form.searchIpt.data)
else:
starData, searchName = getStar("绅士")
return render_template('star.html', email=email, starData=starData, searchName=searchName, form=form)
@app.route('/authorword')
def authorword():
email = session.get('email')
authorList = getAuthorWordCloudData() # Assume this returns a list of author names
text = ' '.join(authorList) # Join the list into a single string
# 指定中文字体路径
font_path = os.path.join('static/fonts', 'MaoKenWangXingYuan-2.ttf') # 根据实际字体文件设置路径
# Generate the word cloud image
wordcloud = WordCloud(
width=1000,
height=400,
background_color='white',
font_path=font_path # 使用中文字体
).generate(text)
image_path = os.path.join('static', 'img', 'wordcloud.png')
wordcloud.to_file(image_path) # Save the word cloud image
return render_template('authorword.html', email=email, image_path=image_path)
if __name__ == '__main__':
app.run()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻



评论前必须登录!
注册