 网硕互联帮助中心
网硕互联帮助中心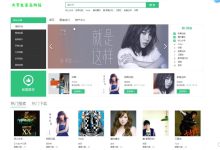
计算机毕业设计源码:基于python的青听校园音乐在线平台 Django HTML-CSS-JS 数据预处理 模型训练(建议收藏)✅
1、项目介绍 技术栈 本系统采用Python语言进行开发,基于Django框架搭建web应用,使用MySQL数据库存储音乐信息和用户...
1、项目介绍 技术栈 本系统采用Python语言进行开发,基于Django框架搭建web应用,使用MySQL数据库存储音乐信息和用户...
Hadoop 3.x实战:基于HDFSSparkFlink的实时用户行为分析平台(含Kerberos安全配置冷热数据分层...
一、问题背景与成本困境1.1 API调用成本现状随着人工智能技术的快速发展,DeepSeek等大模型API已成为企业智能化转型的核心基础设施。但在...
摘要 随着社会对大学生兼职需求的增加,大学生兼职管理系统的开发成为了提高兼职信息管理效率的重要手段。本论文介绍了基于SpringBoot框架开发的...
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心...
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang...

✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang...
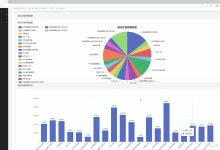
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久...
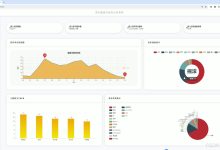
文章浏览阅读626次,点赞27次,收藏16次。本文介绍了一个基于大数据的儿童出生体重和妊娠期数据系统。该系统采用Hadoop、Spark等大数据技术,结合Pyt...

文章浏览阅读713次,点赞27次,收藏14次。2006年MapReduce推动了Hadoop批处理生态,但受限于高延迟和频繁落盘。2013年Spark以RDD内...
